
 起点课堂会员权益
起点课堂会员权益三范式建模和维度建模,到底该选哪一个?
编辑导语:当你需要从头开始设计数据仓库时,你会选择哪种建模方式?也许,你会从三范式建模和维度建模二者中选择。但是这二者有其各自的适用范围,具体选择哪种方法,还需要回归至业务层。本篇文章里,作者对Inmon 方法和Kimball 方法做了对比分析,一起来看一下。

一、两种建模方式的背景
在如何构建数据仓库方面,这两种截然不同的思想流派:Inmon 方法和 Kimball 方法。他们的关键区别在于数据结构如何建模、加载和存储在数据仓库中。这种差异会影响数据仓库的交付时间以及适应 ETL 设计未来变化的能力。
当数据架构师被要求从头开始设计和实现数据仓库时,他或她应该选择哪种架构风格来构建数据仓库?如何帮助架构师在 Inmon 或 Kimball 架构之间做出选择?
Inmon的三范式建模经常被和Kimball 是维度数据经常会被拿来对比,两位大神也一直在秉持着自己的数据建模观点。两位大神有过非常有趣的观点是, Kimball 曾经说过: “数据仓库只不过是所有数据集市的联合体”,对此 Inmon 的回应是:“你可以捕获海洋中的所有小鱼并将它们聚在在一起——但是它们仍然不能成为鲸鱼”。
在典型的数据仓库中,我们从一组 OLTP 数据源开始(关于OLTP的说明可见《秒懂数仓的前世今生:DBMS、DW、OLTP、OLAP到底是啥?(上篇)》)。这些可以是Excel 表格、ERP 系统、文件或基本上任何其他数据源。数据存储在目标环境后,使用 ETL 工具对数据进行处理和转换,然后将其馈入数据仓库。
Inmon 认为数据应该在 ETL 过程之后直接送入数据仓库。Kimball 则坚持认为,在 ETL 过程之后,数据应该被加载到数据集市中,所有这些数据集市的联合创建一个概念性的数据仓库。
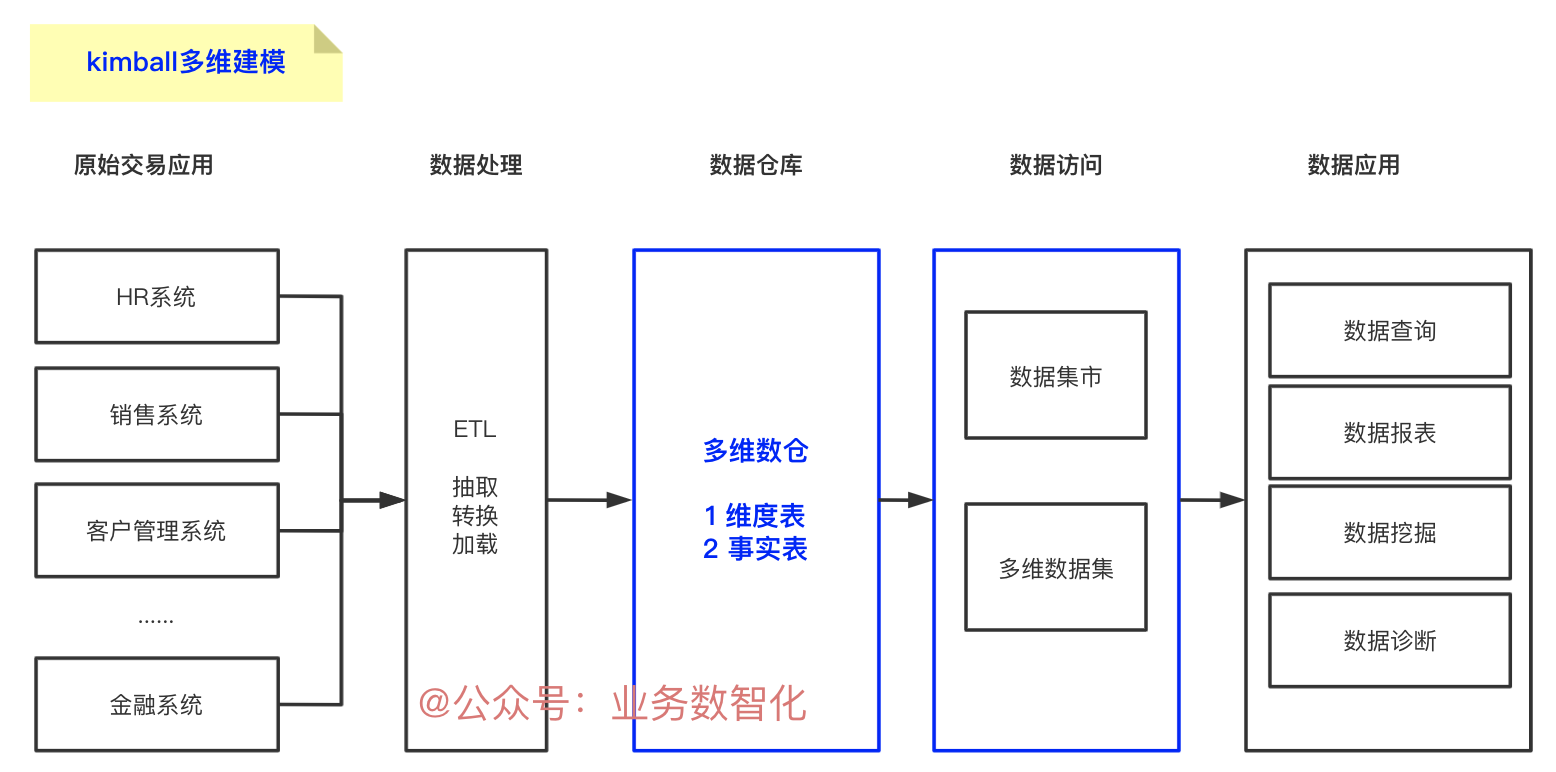
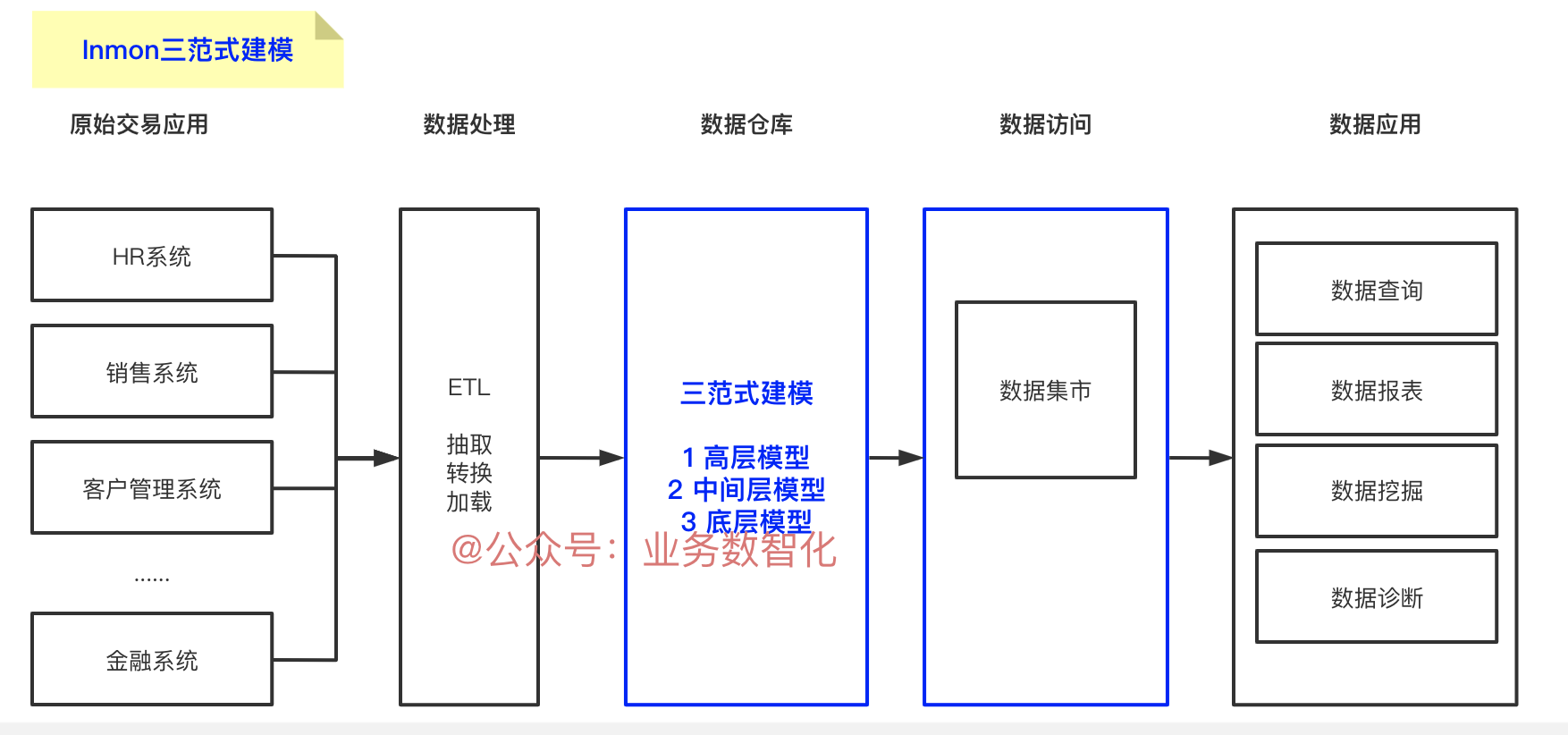
二、两种建模方式的定义
从定义上来说,Inmon 构建数据仓库的方法始于企业级别的数据模型。该模型确定了关键主题领域,最关键的是构建业务运营和关心的关键实体,如客户、产品、供应商等。
首先,从这个模型中,为每个主要实体创建了一个详细的逻辑模型。例如,将客户构建一个逻辑模型,其中包含与该实体相关的所有详细信息。
其次,客户下可能有十个不同的实体。实体之间的对应关系是如何建立的,在这一步骤中有很多的体现。包括业务键、属性、依赖关系、参与和关系在内的所有细节都将在详细的逻辑模型中捕获。这里的关键点是实体结构是以规范化形式构建的。尽可能避免数据冗余。这导致业务概念的清晰识别并避免数据更新异常。
最后,是构建物理模型。数据仓库的物理实现也被规范化。这就是 Inmon 所说的“数据仓库”,这里是管理企业真实数据的地方。这种规范化模型使得加载数据不那么复杂,但是使用这种结构进行查询很困难,因为它涉及许多表和连接。
因此,Inmon 构建特定于部门的数据集市。数据集市将专门为财务、销售等设计,数据集市可以包含非规范化数据以帮助报告。任何进入数据仓库的数据都是集成的,数据仓库是不同数据集市的唯一数据源。这可确保数据的完整性和一致性在整个组织中保持完整。(详细内容可参考《数仓界的大神之Inmon数据仓库建设(3范式建模)》)
接着,咱们来看下Kimball。
从定义上来看,Kmiball是维度建模的拥护者,提供一种方法去建立数仓,“对于数据的查询和分析提供一种更为明确的数据结构”。再经过数据处理ETL后,就开始进行核心建模,维度建模中最关注的有两项。
事实表的建设:经常也被成为度量,事实是可以体现业务流程中真实表现的数据。例如:对于销售业务流程,最核心的体现是季度销售金额;对于招聘流程,最核心的体现是招聘人数;对于技术团队,最核心的体现是开发了多少功能。
维度表的建设:维度是经常被大家说道的一个词,其实维度更多的是一个视角,是从不同的角度去观察和分析事实的一个方法。谁在那干啥?例如:以销售流程为例,需要分析的维度有:谁买了商品——客户名称,在哪买了商品——售卖地点,买了啥商品——商品名称 (详细内容可参考《清晰易懂!用5W2H方法进行维度建模,一篇搞定!》)。
三、两个模型的多视角对比

四、两个模型的适用范围
每种方法都有各自的特点,并且会适用于不同的环境中。具体选择哪种数据仓库设计方法取决于组织的业务目标、业务特性、时间、成本、不同组织单元之间的相互依赖级别。
Inmon 三范式建模的方法适合长期稳定的业务,所谓“长期稳定”是指:
“时间方面,业务整体的数据建设可以经得起长时间的打磨;成本方面,由于inmon建模需要专家团队的支持,所以需要能接受较多的支出。”
Kimball维度建模的方法更加适合快速激进的业务,所谓“快速基金”是指:
“时间方面,业务处于快速扩张要快速看到效果;成本方面,没有较多较为专业的团队来支持相关建设。”
我们可以拿两个例子来解释说明一下。
- 营销:这是一个专业领域,我们不需要为了分析的目的考虑营销的每个方面。因此,我们不需要企业仓库——几个数据集市就足够了——也就是 Kimball 方法。
- 保险:为了根据未来的预测管理风险,我们需要对所有投保人形成一个广泛的图景,由一系列数据组成,如盈利能力、历史、人口统计等。所有这些方面都是相互关联的,因此 Inmon 方法从仓库中的所有数据开始,并根据需要对其进行过滤是两者中最合适的。
- 市场:这是一个小的分支,并且业务场景较为简单,无需进行企业级数仓建设,只需要数据集市就够了。因此,Kimball的方法比较适合。
- 银行:银行类的业务对于银行产品和客户信息都是非常关注,尤其是两者的交叉分析,哪些人买了啥银行产品。这些数据会有相关的限制,例如:产品和客户的信息不可给市场和财务部门公开,部门与部门之间的数据会有限制,这种情况下只能采用Kimball的方法;如果银行中的整个流程和部门相互关联,这种情况下使用Inmon会更好一些
- 制造业:会涉及到多个组织单元,且预算比较充裕。这种情况没有系统依赖,因而需要企业模型,这时还是Inmon的方法比较理想。
在设计数据仓库时,首先要先看看业务目标——短期目标和长期目标。看看功能之间哪里有联系,什么是独立的。分析数据源的数量和质量。最后,评估你的资源级别、时间和经费。这能帮助你判断用Inmon方法还是用Kimball方法,或者是两种方法的组合。
本文由 @业务数智化 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


