
 起点课堂会员权益
起点课堂会员权益独家!如何玩转数据分析?
编辑导语:产品的完成离不开数据分析这一步,作为一名产品设计师必须具备根据实际情况去建立模型的能力。这篇文章介绍了如何玩转数据分析,推荐想要了解数据建模的童鞋阅读。

作为产品设计师,数据分析不仅仅简单的根据产品给的数据去分析,而是要根据实际情况去建立模型。(为便于理解,文中所示代码不是特别规范,不影响使用,望包涵)
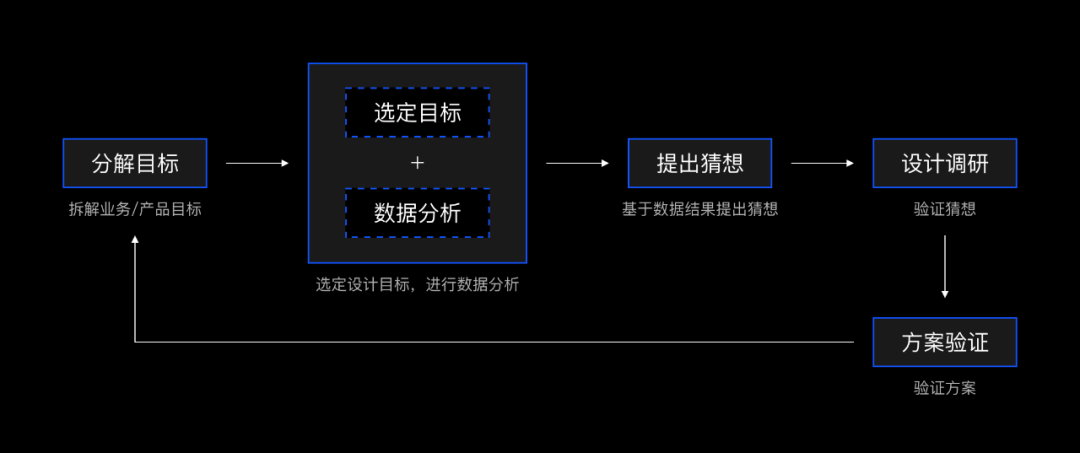
数据驱动设计流程
一、数据化决策——数据化决策的过程就是量化的过程
数据化决策就是通过量化的数据来辅助我们进行决策,从而提升决策的科学性和准确性。
1. 了解量化
历史上最早的科学家曾经不承认实验可以有误差,认为所有的测量都必须是精确的,把任何误差都归于错误,直到后来人们才慢慢意识到误差永远存在,不可消除。量化也是如此,量化是为了减少不确定性、估算风险,从而辅助决策,因此量化的过程也不需要无限精确,不需要完全消除不确定性,只要能够支持我们决策即可。
2. 置信区间——量化的一种方式
因为量化并不一定都是一个精确的数字,并且在现实中,我们经常会遇到数据不完善、数据量过于庞大短时间内难以处理,因此我们引入统计学概念——置信区间,用于辅助我们决策。置信区间是指:以特定的概率表示一个正确答案的范围。
一般情况下,我们要求置信区间要足够窄,且信心要在80%以上。信心过低意味着这个数据区间错误的可能性很大,区间过大意味着这个区间缺乏参考意义。
例如:本次考试的成绩有100%的信心在[0,100],这个区间等于什么都没说,缺乏了参考意义;本次考试的成绩有5%的信心在[95,100],这意味着本次考试成绩有95%的信心在[0,95],因此[95,100]这个区间很有可能是错误的。本次考试的成绩有80%的信心在[85,100],这意味着这个区间很有可能是对的,能够反应真实情况,甚至我们可以认为班级平均分是92.5左右。

置信区间示例
二、数据拆解
1. 确定目标——目标必须可量化
每个项目都有一定的目标,因此我们在做之前,必须要了解我们的目标是什么,有些时候,业务或者产品直接会告诉我们目标是什么,例如提升留存率、提升转化率,此时目标非常清晰,我们直接进行目标拆解就可以了,当然有些时候目标会比较模糊,例如提升用户体验,此时我们需要通过澄清链的方式让目标变的可量化。
2. 澄清链——让目标可量化
澄清链就是把某物想象为无形之物再到有形之物的一系列短的链接过程。例如有些时候我们的目标是提升用户体验,这个目标是不符合「SMART原则」中可衡量这一条,此时我们没法直接开始做,我们需要将这个目标变成量化的。这个目标我们可以感知到吗,通过哪些方面感知呢?
这些可感知的方面是可以衡量的吗?那么我们要通过其他数据来衡量?此时我们要反问,为什么要提升用户体验?提升用户体验用户会有哪些行为?那可能用户更愿意逛我们的平台,那就可以用停留时长、浏览的屏数来衡量体验是否真的提升了。
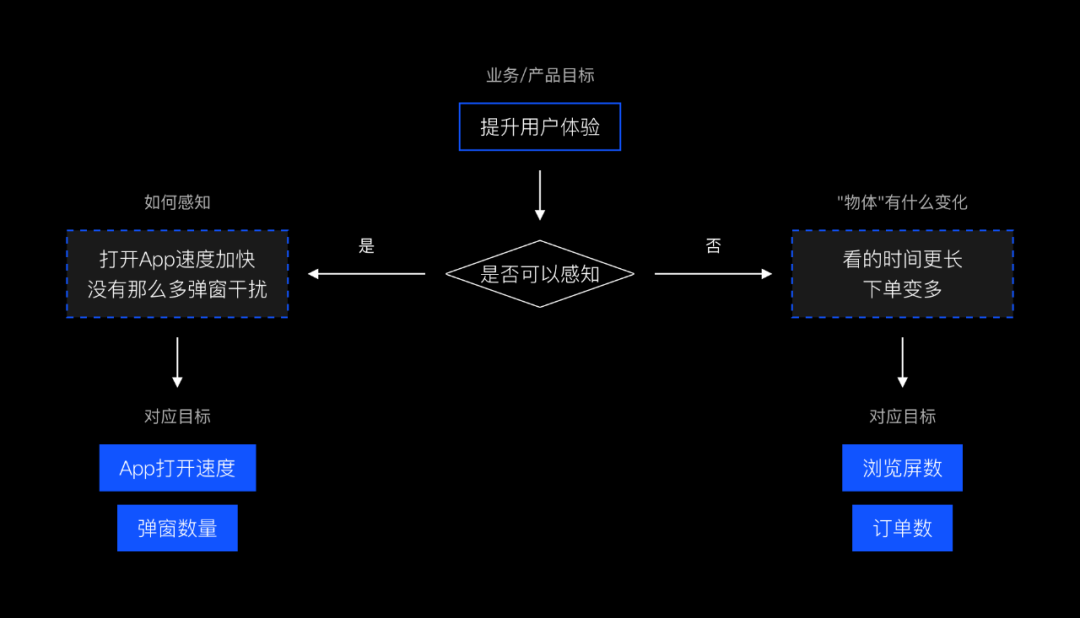
澄清链示例
3. 目标拆解——把业务目标变成设计目标
确定好目标后,此时的目标可能更偏向于业务侧/产品侧,较为抽象,难以直接通过设计达到,因此需要将目标拆解成不同数据指标的组合,从中选取设计可以触达的数据从而达到目标。
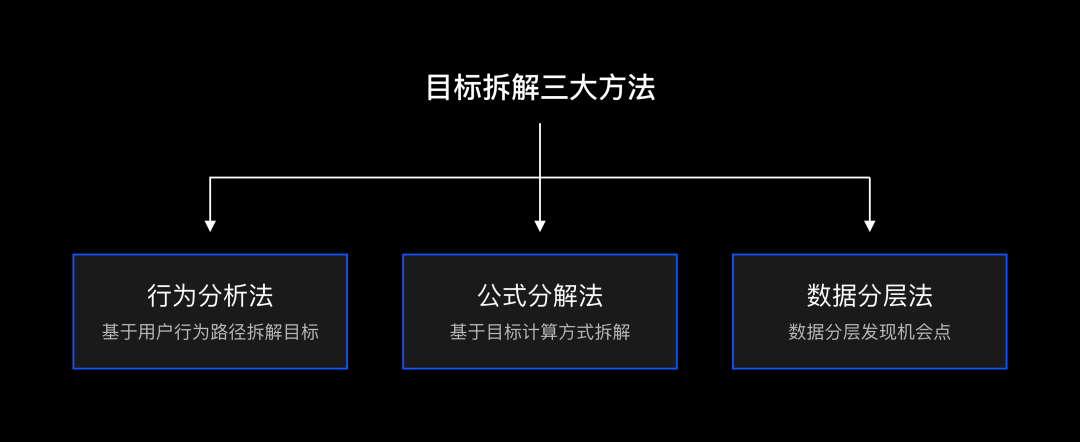
4. 行为路径分析法——研究用户行为数据
基于用户的行为路径(用户行为路径即将用户点击浏览的数据可视化而成)来拆解目标,找到设计可发力的环节从而达到目标。
这个方法的难点在于要对业务非常熟悉,需要详细的了解用户所有的路径,通常也可以采用“抓大放小”的方式,整理出用户主路径,对主路径进行研究,暂时放弃子路径。例如用户完成目标G可能需要经历A-B-C-D-E-F这些,整理出每个页面的UV,从而找到中间的漏损最严重的点进行优化。
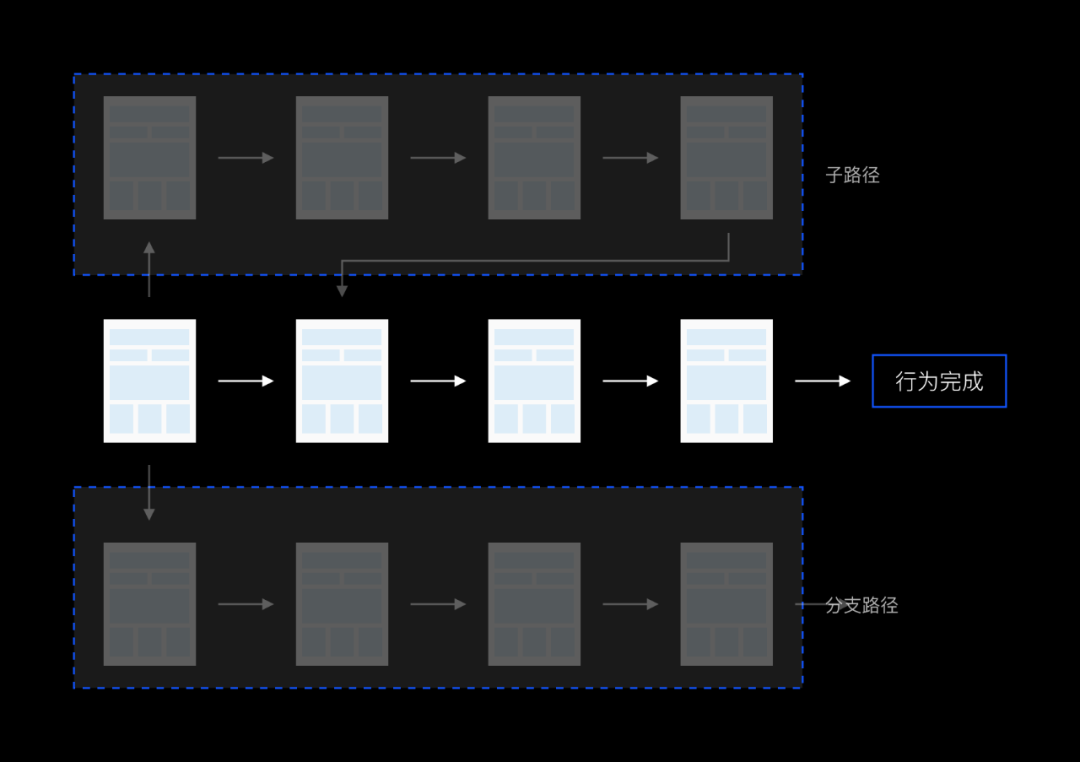
用户行为路径一览图(示例)
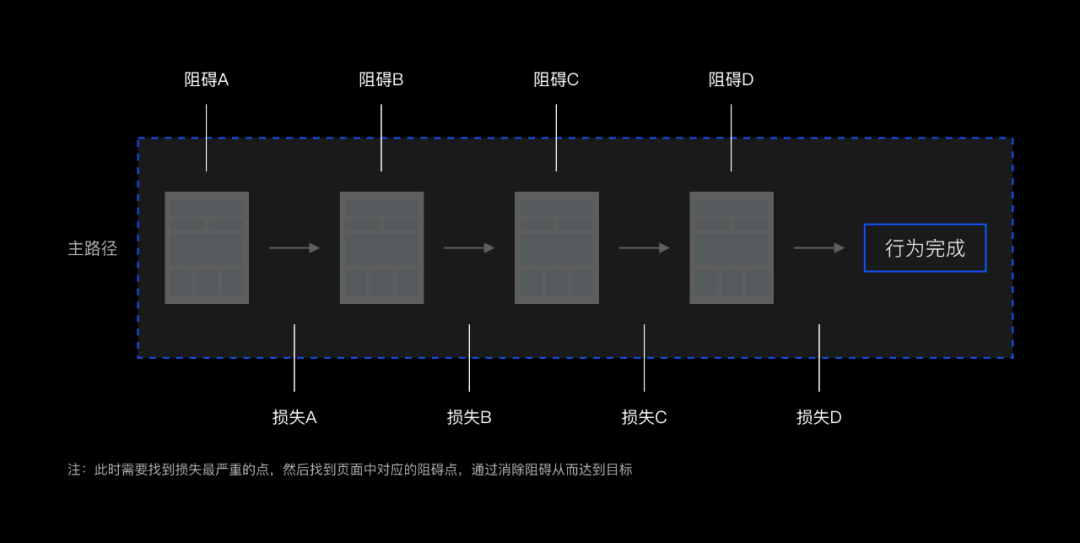
用户主路径一览图(示例)
5. 公式分析法——较为开放式的方法
即通过数据的计算公式进行拆解。例如:GMV=UV*客单价*转化率,此时我们就知道,我们可以通过提升UV、提升客单价或者提升转化率的方式来提升我们的目标。公式法还可以嵌套使用,例如转化率=下单用户数/首页UV,下单用户数=页面A UV*页面A转化率*页面B转化率*···*页面N转化率。
也可以和行为路径法结合使用。使用公式法要注意,当遇到一些比率的指标时,分子和分母不能同时变大或者同时缩小,否则难以实现总的数据指标的成长。这种方法适用于对于目标非常明确的。
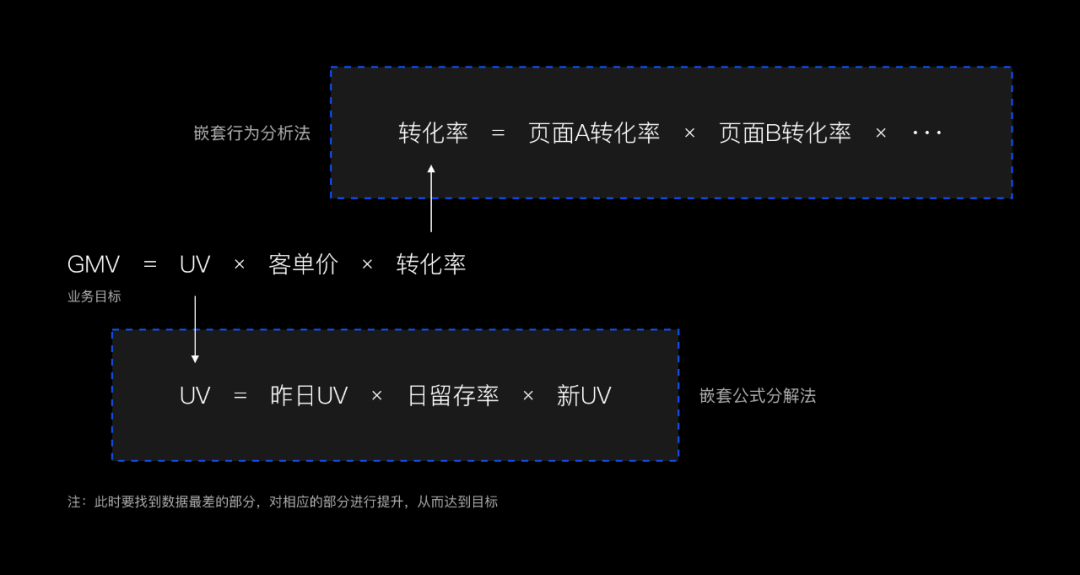
公式分析法示例
6. 数据分层法——较为发散式的方法
寻找创新型解法或数据体系不够完善时使用。我们将数据按一些维度进行分层归类,发现数据间的共性和联系,从而找到设计发力的点。需要注意的是,数据的每一次分层都需要保证维度是统一的,一般是用户路径数据、用户画像数据、产品数据这三个维度进行分层:
一,用户路径数据:用户在这个页面之后有多少用户没有按照既定的设计进入下一个页面,他们去了哪些页面,分别占比是多少?去了这些页面之后又去了哪里,分别占比是多少,整理出用户的路径寻找共性。
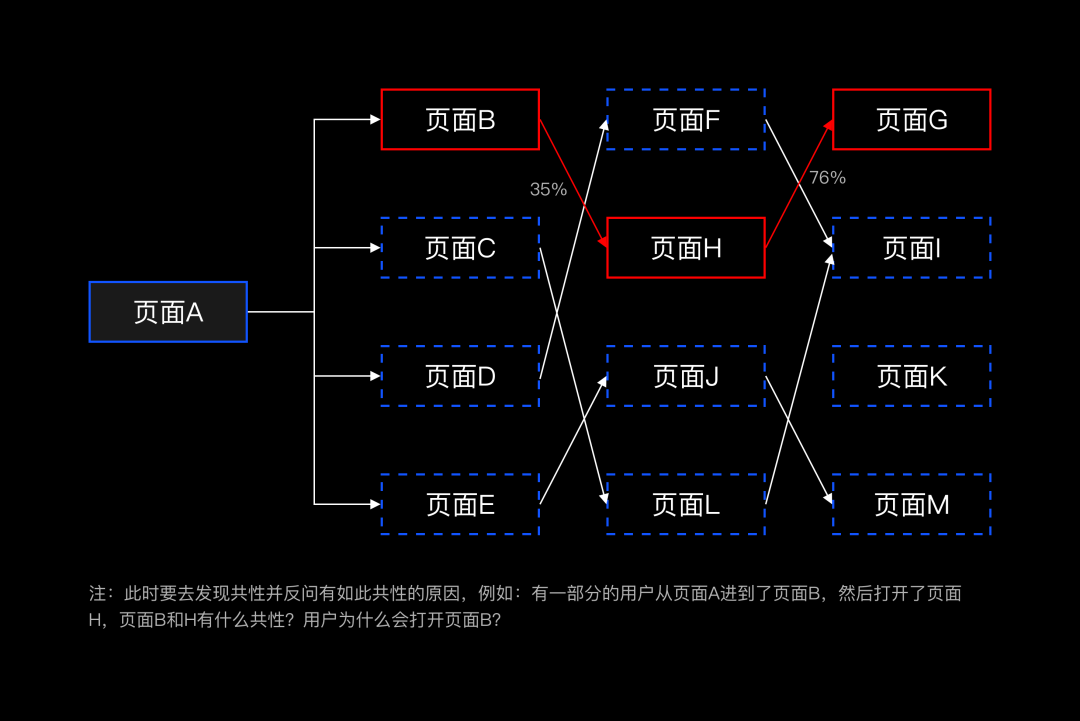
用户路径数示例
二,用户画像数据:访问这一页面的有哪些用户,这些用户有哪些共性,例如都是女性、都是18-25岁的女性、都是18-25岁研究生学历的女性。
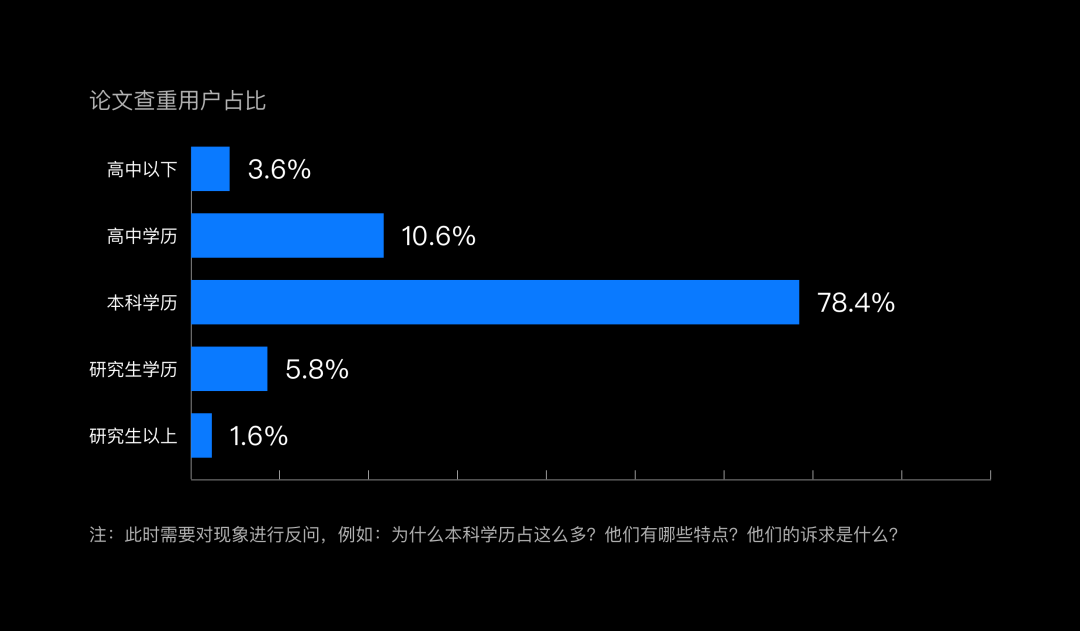
用户画像数据示例
三,产品数据:产品数据进行排序、分层。例如:优惠券领取页UV、优惠券领取数量、优惠券使用数量。那么优惠券的领取率和使用率是多少?领一、二、三张优惠券的用户占总体的比率分别是多少?优惠券使用一、二、三张的用户占总体比率是多少?当页面UV为0-1000时,优惠券领取数量、优惠券使用数量是多少,其领取率和领取使用率如何,当UV为1001-2000时,优惠券领取数量、优惠券使用数量是多少,其领取率和领取使用率如何,以此类推:
产品数据分层示例
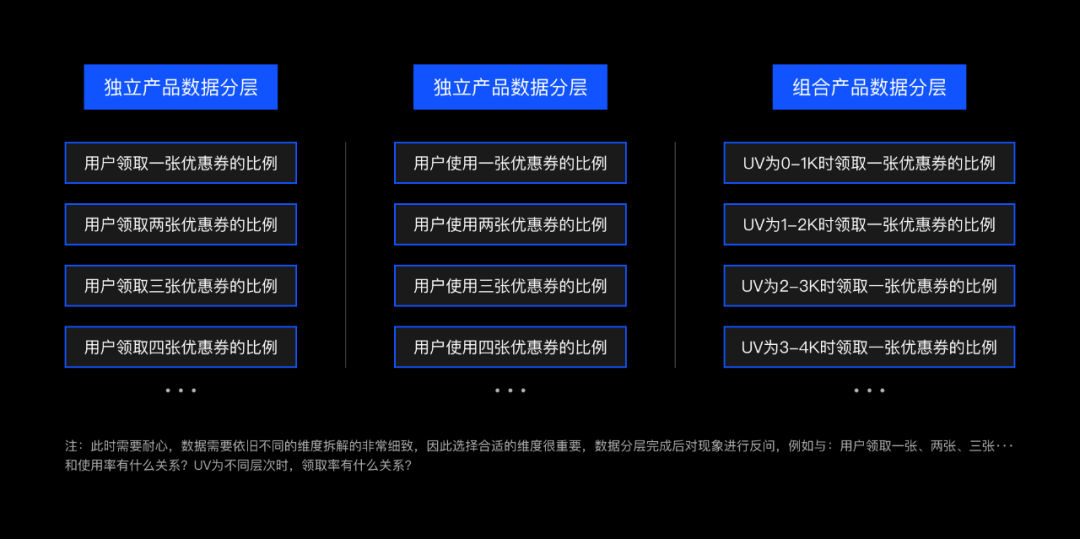
产品数据分层示例
数据分层后还可以嵌套分层,例如先将用户画像数据分了A、B、C层,那么我们可以去研究A层用户行为数据分层情况如何,B层用户行为数据分层情况如何,C层用户行为数据分层情况如何。当数据分层后,就可以寻找关联:
- 寻找关联:此时建议使用饼状图和折线图,饼状图用于查看分布情况,折线图用于查看趋势情况,例如用饼状图可以查看用户领取优惠券数量的占比,我们能找到哪个部分的数量最多,用折线图可以查看领取数和使用率的关联性。
- 匹配目标:我们绘图之后我们会很容易发现规律,例如,我们会发现领取的优惠券数量越多,用户的使用率越低,结合公式法我们知道,使用率=使用的优惠券数量/领取的优惠券数量,如果要提升领取率,我们可以提高使用的优惠券数量也可以减少领取的优惠券数量,但是如果我们减少领取的优惠券数量,虽然使用率提高了,但是对于业务并没有帮助,只是虚假的繁荣,因此我们应该提升优惠券的使用数量。
- 合理推测:当我们找到发力点之后,可以进行脑暴,推测数据不理想的原因,后续可以通过用户调研进行验证。例如,我们可以猜测用户领取那么多的优惠券其实并不知道这些优惠券到底是哪些,使用门槛是什么,只是看到就领了。
三、数据分析
数据分析分为三个部分,分别为数据清洗、数据处理、机会点排序。
1. 数据清洗
数据清洗包括了无效数据清洗、重复数据清洗、无关联数据清洗。一方面是为了将垃圾数据剔除,以免影响数据结果,另一方面是为了减少数据干扰,提升处理效率。
2. 数据处理
由于我们想要的数据可能并不是标准常见的数据指标,因此我们拿到原始数据之后需要根据我们的需求将原始数据处理成我们想要的数据,例如领取一张优惠券的用户占总用户数的比例,领取两张优惠券的用户占总用户数的比例。
3. Python教程
推荐使用Python,简单易学且数据处理更为高效以下代码也可以复用。
4. 头文件
每个Python文件都有头文件,头文件导入了各种模块,常用的有matplotlib、pandas、numpy、openpyxl。其中matplotlib用于绘图,pandas和numpy用于数据处理,openpyxl用于支持各种数据表的格式导入。

5. 导入原始数据
在处理之前需要把原始数据导入进来,以excel文件为例,其中./newdata.xls是原始数据excel表的路径和完整的名字,source_data是用于存放原始数据的数据结构,可以根据自己需求定义为不同的名字。

6. 创建空表
我们还需要新建一个空表,用于存放我们处理好的数据,shape=(0, 3)中的0和3分别表示行数和列数,初始行数可以为0,不用管,列数就设置为我们想要的列数。其中title1、title2、title3可以自定义我们表头的名字。

7. 处理数据
数据清洗,如果某一列数据中,有某一条数据为空,则把这条数据删除掉。

根据需求将对于列表的数据进行加减乘除,需要注意的是分母不能为0。

8. 数据输出
数据处理完成后,可以将处理好的数据导出为excel等格式给其他同事。

9. 绘图
如果有需要,则可以直接绘图,从而判断各个数据之间的关系。
![]()
10. 完整代码示例
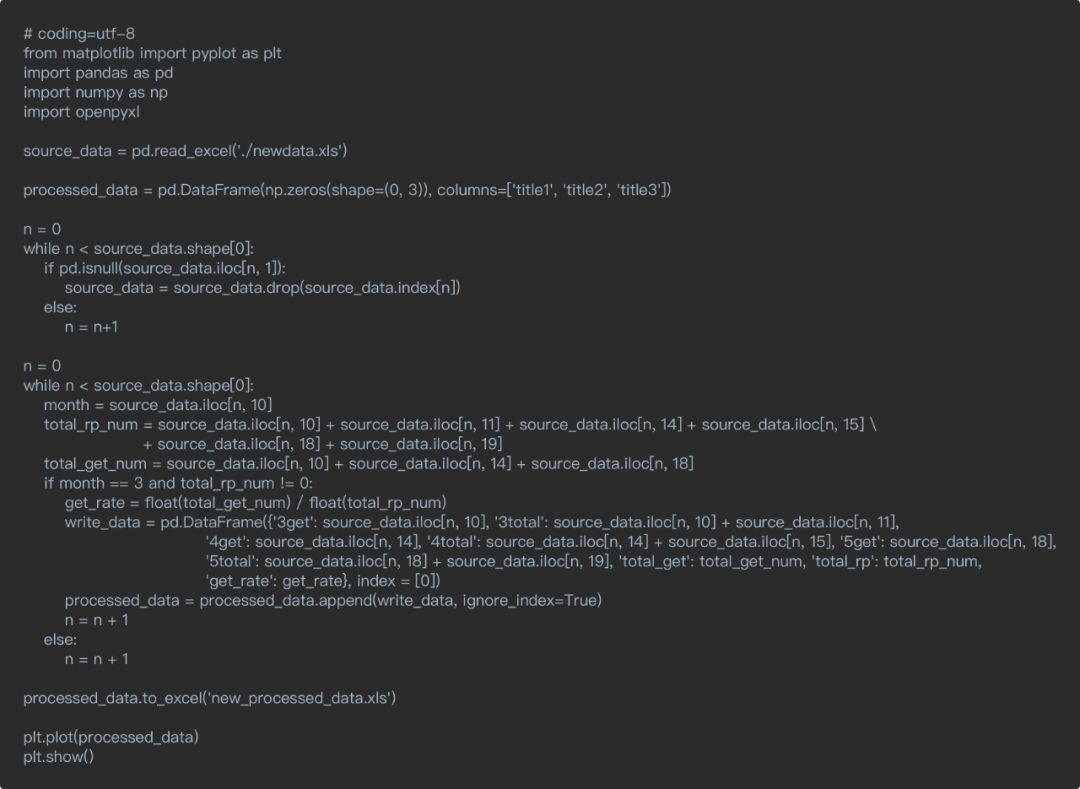
11. 机会点排序
通过数据分析后,我们能找到许多机会点,但是不同的机会点价值是不同的,因此我们需要根据机会点的价值进行排序。可以直接通过置信区间进行估算排序,例如当我们优化了页面A之后,页面A的流失率有80%的信心降低在[5%, 10%],当然也可以通过精细化数据计算从而判断更为精准,但是会耗费更多的精力。价值排序完成之后,我们后续还需要跟项目其他成员一起,基于可行性和实际的资源投入情况计算ROI,从而选择最适合的机会点去实现
四、设计方案
1. 设计调研
确定机会点之后,有些探索性的机会点我们可以直接通过设计方案执行,而另外一些机会点我们也进行了合理推测,在设计调研环节则是对这些推测进行验证,看是否真实出现在用户中。受制于环境的影响,我们常用的方式是就是电话访谈和问卷调查,这两个本质上还是一样的
2. 确定目标
在这里就是要确定我们验证的是哪个猜测,例如我们验证用户是,我们问卷的问题需要围绕着这个目标来
3. 筛选用户
筛选用户有两种方式,一种是我们定向发放,一种是定向选择。定向发放是指,我们从符合要求的用户中随机抽取一定数量的用户向他们投放问卷或者拨打电话。定向选择是指,我们向全量用户进行投放,然后从收集到的结果中筛选出符合我们需求的用户,当我们资源比较紧张时,可以采用少量样本,一般认为,5个用户就可以发现80%的问题
4. 设计问题
设计的问题需要围绕着我们的目标,由简到难,尽可能多的使用选择题的形式,主观题建议最多一题,而在电话访谈中可以在最后跟用户进行沟通。需要注意的是,在问卷最开始需要收集用户信息,以便于我们二次确认该用户确实是符合条件的用户
5. 收集反馈
结果收集后根据使用前面说的数据清洗和数据处理的方式对结果进行处理,需要注意的是,需要保留源数据,如果是电话访谈的话需要保留电话录音,以便于后续细节的确认
6. 设计方案
当我们找到目标、用户反馈之后,就可以设计我们的设计方案了。此时要围绕着用户的目标、场景,借助“福格行为模型”合理设计方案
7. 设计验证
设计方案的同时需要确定数据埋点,我们需要根据各个数据埋点的情况来确定我们的设计方案是否有效,并且通过这些数据发现更多可优化的点,并且同时,最好是可以把之前想要但是没有的数据埋点也埋上,为以后做准备
结语
以上内容写的比较多,一次性难以消化,建议大家多读几遍。中间有些内容例如设计方案、用户调研其实说的还不够细致,后面有机会的话会慢慢写出来跟大家分享。
作者:何必复杂;公众号:何必复杂(UXSimple)
本文由 @何必复杂 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









写的真好,希望后续有实际案例!
写的很详细呀,数据分析确实是很有用并且必要的,很多方面都涉及到了
写的很详细,感谢作者分享
现在什么都离不开数据分析。
特别同意
爱了爱了。非常有帮助!