
 起点课堂会员权益
起点课堂会员权益数据仓库,为什么需要分层建设和管理?
数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合,为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。作者提出,数据仓库需要做好分层建设和管理,原因是什么,又有什么分层方法,欢迎感兴趣的伙伴们阅读。

数据仓库是数据化运营和数字化转型的底层基础设施,数据仓库不完善或者建设质量差,再好的上层建筑(数据应用产品或工具)也很难牢固地生存下去。在数据仓库建设时,绕不开的话题就是数仓分层。
一、为什么要进行数据分层
1. 降低数据开发成本
基于数据模型的开箱即用的开发成本要远小于每一次的case by case的按需开发。例如要计算产品的DAU指标,直接从加工好的数据表中select一下指标值,不管是SQL代码的复杂程度还是查询性能、耗时都要远比再从源表重新清洗一遍业务逻辑要简单的多。
通过分层建设,把通用的业务逻辑加工好,后续的开发任务可以基于模型快速使用,数据需求的响应速度也会更快。

2. 降低任务运维成本
业务发展过程中,数据指标口径、统计逻辑变化是常态,任务失败也屡见不鲜。如果每一次调整都需要对所有的数据任务进行修改,再去回溯数据,那数据开发大部分时间都在填坑中度过了,而且还会经常出错。
我们知道,管理一棵大树,只要花时间聚焦把主干和重要分支维护好,树就可以正常生长,而管理一片稻田,则需要对每一棵禾苗进行保养。
数仓分层就是希望通过对最基础的、常用的数据进行抽象,找出数据的主干,对主干进行修复后,下游的叶子节点就可以最小变动。例如,当产品改版后,涉及流量统计指标口径需要调整,通过数据分层,只修改最底层的源表的逻辑就可以实现整个链路的数据更新。
3. 方便共享复用,减少重复建设
不同的开发人员、不同时期开发的模型,如果没有分层管理规范,往往导致后期使用时找不到,不是不想复用,而是数据找不到或者需要花费很长时间沟通、翻代码确认,最终耗时反而没有重新写一套逻辑来的快,长此以往,导致大家都不敢用别人的模型,数据复用度低,带来存储和计算资源的浪费。
通过数据分层,将数据有序的管理起来,就像图书馆的书架导航,可以快速帮助使用者找到所需要的书籍在那一层书架中,能找到现成的,相信都不愿意做冤大头重新做一份吧。

4. 统一数据口径
同一个指标在数据加工处理时,复用的是同一个数据模型表,这样很大程度可以规避数据统计不统一的问题,毕竟本是同根生嘛。
二、数据仓库的分层方法
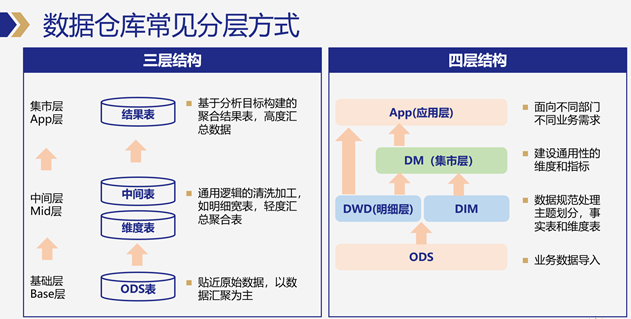
ODS层:贴源数据层,一般是从各种业务系统、日志数据库将数据汇集到数据仓库中,作为原始数据存储和备份,一是数据仓库建设不会直接查业务的关系型数据库,而是通过数据同步的方式,将业务从库数据同步到HDFS(Hive)等,适合海量数据存储和加工处理的介质中。
DWD层:数据明细层,对ODS层数据进行规范化处理,例如脏数据过滤、数据格式化等,但仍以数据明细方式存储,且将数据进行主题、层级划分。
DIM层:维度表,在维度建模理论中,可以通过业务主题宽表关联维度表方式,快速输出直观的数据分析结果。
DM层:数据集市层,基于对业务的需求的理解和抽象,建立通用的指标和分析维度模型,数据仍以明细为主,部分可以直接加和汇总的数据指标,可以采用聚合结果的方式呈现,但如DAU等涉及去重的指标,一般以明细存储。
APP层:数据应用层,面向不同业务部门、不同产品需求提供具体业务场景的结果表,通过数据同步方式再从数仓同步到MySQL、Greenplum等查询引擎,供前端数据产品输出使用。定制化程度高。
三、数据仓库分层管理规范
数据仓库分层管理中,通过不同层级的数据使用情况指标的构建,对数仓建设完善度和复用度进行指标化管理。
1. 完善度
数仓模型对业务的支撑和覆盖情况,完善度越高的数仓体系,业务获取和使用数据的成本就越低。即当业务需要数据时,已经相应的模型在哪里等着使用了,而不是再去对接业务沟通需求,排期开发。
例如当管理者问数仓负责人,你们天天搞数仓建设,现在到底建设到什么程度了呢?有了完善度评价标准,可以量化数仓建设成熟度。
通过数据血缘及查询日志,可以对数据加工任务以及Adhoc查询进行统计分析。例如,在数据查询中,直接查询ODS的任务占比,占比越高说明有大量任务基于原始数据加工,中间模型DWD、DWT、DWA复用性很差。
在技术上,直接查询底层表,查询扫描的数据量会越大,查询时间会越长,查询的资源消耗也越大,使用数据的人满意度会低。可以跨层引用率来衡量支持完善度,
DWD层:看ODS层有多少表被DWT/DWA/APP 层引用,占所有活跃的ODS 层表比例。
DWT/DWA/APP层完善度:主要看汇总数据能直接满足多少查询需求,也就是用汇总层数据的查询比例,如果汇总数据无法满足需求,使用数据的人就必须使用明细数据,甚至是原始数据。汇总数据查询比例:DWT/DWA/APP层的查询占所有查询的比例。
跨层引用率越低越好,在数据中台模型设计规范中,一般不允许出现跨层引用,例如ODS层数据只能被 DWD引用。
2. 复用度
复用度顾名思义,资产建设完成后,被不同业务或用户复用的情况,复用才会减少重复开发。可以用引用系数作为数据中台资产复用度评价指标。引用系数越高,说明复用性越好。
引用系数:数据表被读取,产出下游模型的平均数量。例如一张DWD 层表被8张 DWS层表引用,这个表的引用系数就是8,把拥有下游的DWD 层表(有下游表的)引用系数取平均值,则为DWD 层的平均引用系数。
四、小结
数据仓库建设以及分层管理,回归到最初的目的,就是降本提效,通过各种规范、手段、流程,来保障数据输出效率最高,可以快速响应业务发展的数据需求,用数据来驱动决策或赋能业务。同时,也要从成本角度考虑,不断降低数据开发成本、存储成本、计算成本。用最少的人和资源,覆盖更多的业务数据需求。
专栏作家
数据干饭人,微信号公众号:数据干饭人,人人都是产品经理专栏作家。专注数据中台产品领域,覆盖开发套件,数据资产与数据治理,BI与数据可视化,精准营销平台等数据产品。擅长大数据解决方案规划与产品方案设计。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


