
 起点课堂会员权益
起点课堂会员权益
数仓建模——维度表详细讲解

维度表是一种数据建模技术,用于存储与数据中心的各个业务领域相关的维度信息,通常于构建数据仓库、数据集市等决策支持系统,以便进行多维数据分析和报告。本文作者对维度表进行了分析讲解,一起来看一下吧。

一、维度表是什么
维度表是一种数据建模技术,用于存储与数据中心的各个业务领域相关的维度信息。它通常用于构建数据仓库、数据集市等决策支持系统,以便进行多维数据分析和报告。
在数据仓库中,维度表是与事实表相对应的表。维度表是维度建模的基础和灵魂。事实表紧紧围绕业务过程进行设计,事实表存储度量数据,如销售额、数量、收入等,而维度表则围绕业务过程所处的环境进行设计,维度表存储描述度量数据的各个方面的信息,例如时间、地理位置、产品、客户等。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
二、维度表设计要点
1. 规范化与反规范化
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。如果对其进行规范化,得到的维度模型称为雪花模型,雪花模型,比较靠近3NF,但是无法完全遵守,因为遵循3NF的性能成本太高。

反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时,如果对其进行反规范化,得到的模型称为星型模型。雪花模型与星型模型的区别主要在于维度表是否进行规范化。

数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,维度表一般反规范化的。
2. 维度变化
维度属性一般来说不是静态的,而是会随时间变化的,数据仓库的一个重要特点就是反映历史的变化,所以如何保存维度的历史状态是维度设计的重要工作之一。保存维度数据的历史状态,通常有以下两种做法,分别是全量快照表和拉链表。
1)全量快照表
离线数据仓库的计算周期通常为每天一次,所以可以每天保存一份全量的维度数据。这种方式的优点和缺点都很明显。
优点是简单而有效,开发和维护成本低,且方便理解和使用。
缺点是浪费存储空间,尤其是当数据的变化比例比较低时。
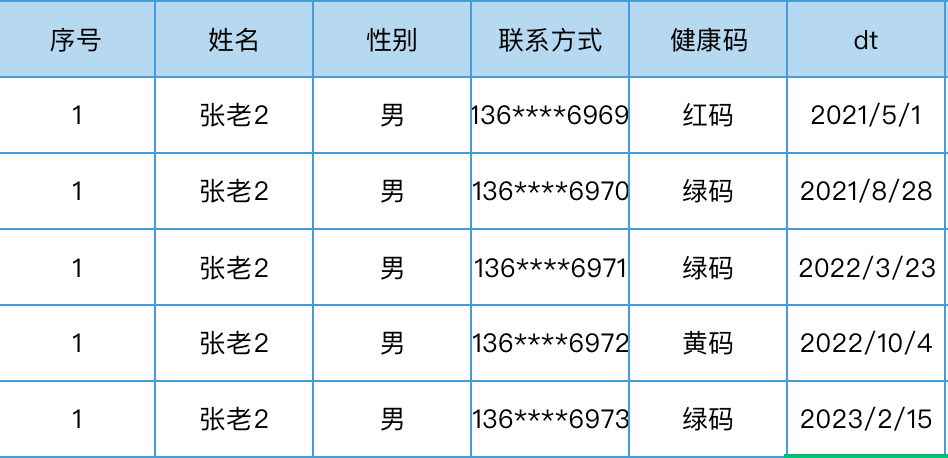
2)拉链表
①什么是拉链表
拉链表是维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的数据记录,拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期。 如果当前信息至今有效,在生效结束日期中填入一个极大值(如9999-1-1 )

拉链表适合于:数据会发生变化,但是变化频率并不高的维度(即:缓慢变化维),比如:用户信息会发生变化,但是每天变化的比例不高。如果数据量有一定规模,按照每日全量的方式保存效率很低。比如:2亿*365天,每天一份用户信息。(做每日全量效率低),拉链表的意义就在于能够更加高效的保存维度信息的历史状态。
3. 多值维度
如果事实表中一条记录在某个维度表中有多条记录与之对应,称为多值维度。例如,下单事实表中的一条记录为一个订单,一个订单可能包含多个商品,所会商品维度表中就可能有多条数据与之对应,针对这种情况,通常采用以下两种方案解决:
第一种:降低事实表的粒度,例如将订单事实表的粒度由一个订单降低为一个订单中的一个商品项。
第二种:在事实表中采用多字段保存多个维度值,每个字段保存一个维度id。这种方案只适用于多值维度个数固定的情况。建议尽量采用第一种方案解决多值维度问题。
4. 多值属性
维表中的某个属性同时有多个值,称之为“多值属性”,例如商品维度的平台属性和销售属性,每个商品均有多个属性值。
针对这种情况,通常有可以采用以下两种方案。
第一种:将多值属性放到一个字段,该字段内容为key1:value1,key2:value2的形式,例如一个手机商品的平台属性值为“品牌:华为,系统:鸿蒙,CPU:麒麟990”。
第二种:将多值属性放到多个字段,每个字段对应一个属性。这种方案只适用于多值属性个数固定的情况。
三、维度表设计步骤
1)确定维度(表)
在设计事实表时,已经确定了与每个事实表相关的维度,理论上每个相关维度均需对应一张维度表。需要注意到,可能存在多个事实表与同一个维度都相关的情况,这种情况需保证维度的唯一性,即只创建一张维度表。另外,如果某些维度表的维度属性很少,例如只有一个**名称,则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。
2)确定主维表和相关维表
此处的主维表和相关维表均指业务系统中与某维度相关的表。例如业务系统中与商品相关的表有item_info,sku_info,category,brand_info,category2,seller_info,等,其中sku_info就称为商品维度的主维表,其余表称为商品维度的相关维表。维度表的粒度通常与主维表相同。
3)确定维度属性
确定维度属性即确定维度表字段。维度属性主要来自于业务系统中与该维度对应的主维表和相关维表。维度属性可直接从主维表或相关维表中选择,也可通过进一步加工得到。
确定维度属性时,需要遵循以下要求:
①尽可能生成丰富的维度属性
维度属性是后续做分析统计时的查询约束条件、分组字段的基本来源,是数据易用性的关键。维度属性的丰富程度直接影响到数据模型能够支持的指标的丰富程度。
②尽量不使用编码,而使用明确的文字说明,一般是编码和文字共存。
③尽量沉淀出通用的维度属性
有些维度属性的获取需要进行比较复杂的逻辑处理,例如需要通过多个字段拼接得到。为避免后续每次使用时的重复处理,可将这些维度属性沉淀到维度表中。
本文由 @菜鸟数据之旅 原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









