
 起点课堂会员权益
起点课堂会员权益「定量 + 定性」,通过用户分析实现0成本内生增长

数据分析之上是用户分析,应该通过定量 + 定性结合的方法,用数据搭成的框架去了解用户,了解整个产品运转的情况,才能更好地做增长。
一开始大家眼里的数据分析,就是一些数据和一些率,增长率或者变化率……我后来慢慢发现,分析这些规整的数据没什么意义。我把研究转移到单个的用户上。相同行为的用户会放被在一起,组成一个用户群。不同特征的用户群会有什么用法,会做什么转化,这些比单纯的数据分析,要有价值多。
作为最早把数据分析应用到互联网产品的数据分析师之一,张弦认为数据分析之上是用户分析,应该通过定量 + 定性结合的方法,用数据搭成的框架去了解用户,了解整个产品运转的情况,才能更好地做增长。
在分享会上,张弦结合实际案例,围绕「用户分析和内生增长」两个话题,分享活跃用户增长、用户与产品的关系、用户迁移、留存优化方面的独家经验。
用活跃用户池来控制流失
增长有很多种方式,比如说增加渠道的投放去获取用户。但张弦主张「如何让用户不那么快走」比渠道投放更重要,因为:
产品上线的第一天,流失就开始发生了。
我把 30 天以内的所有用户想象成一个池子,这一天新来用户都会进入这个池子。如果用户后来没有使用我们的产品,他们就会一层层蒸发,30 天以后他们就从池子里蒸发走了。
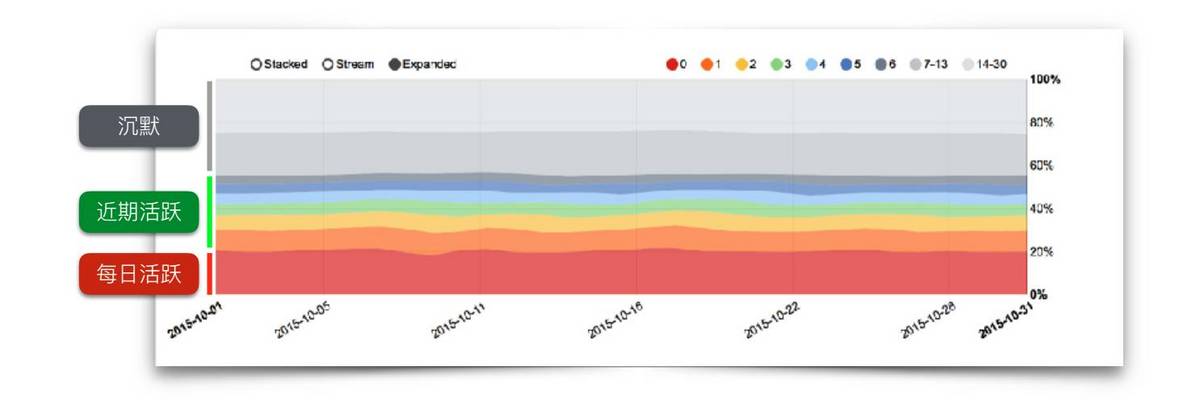
「活跃用户池」模型,按照用户下载 App 后的使用情况,分级为每日活跃、近期活跃、沉默。右上角的数字代表上次使用距离今天的日期。0 代表用户今天使用过 App。
活跃用户池的概念就像是一个水与大气的生态圈。最底下的一层是每日活跃用户,而中间层就是近期活跃用户。用户有两个方向,不活跃的往上走,蒸发流失;活跃的用户往下走,变成黏性用户。活跃用户的面积和走势,可以很好反应一个产品的受欢迎程度。而如果一个产品优化做得好,那么正在蒸发的用户可能会变成「雨」,又回到到了下层。用「池子」的概念,就把用户活跃管理起来了。
所谓的增长,是一件「开源节流」的事情。现在获客成本已经非常高,应该把注意力放在控制用户流失上。这件事对活跃用户池的增益就是阻止池子里的用户往上走,让用户不断往下翻滚、轮转,形成对产品的依赖。用户对产品的依赖程度不同,生命周期长度也不同。一个月或者几小时,都是有可能的。用户超过 30 天没有来,我们就定义为「流失」。
已经流失的用户就没有意义了么?
我会观察这些用户的特征,都走过哪些路径,有哪些痛点还未解决,跟 PM 一起讨论目前产品可以改进的点。对于流失,还有一个重要场景,找到 30天用户最后一次使用的行为,看他最后一个 session 都干了什么事情,我称它为死亡现场,这个场景会给 PM 提供一个直观的认识。这些是我的控制流失的方法,哪些地方需要维护,都一目了然。
如何做不花钱的内生增长?
内生增长是不花钱的,靠的是自身的资源和传播。
如何怎样刺激用户去做主动的传播呢?
缩短决策时间。张弦举例说 Keep 在每次用户完成训练以后的打卡界面都设置了分享,用户不需要在决策的时候花费时间,这就增加用户自发传播的可能性。
找到合适的出口。也就用户为什么要做分享。以 Keep 为例,用户的分享出口可能是由于工具(训练的成就感、自我激励、表明态度),内容(分享快乐、传递知识、收藏),社交(陪伴、自我实现)这几个特性,在不同的使用场景下都为用户设计了快捷的分享出口。

提升运转效率。张弦给运转效率定义了一个公式。其中,sr 代表分享率,ar 代表激活率。后面的累乘就是优化的目标,也就是要不然每次优化的效果足够好使 △sr 和△ar 值变大,或者相等时间内做更多次优化累乘后更大。
用户在使用产品是付出的是时间或者金钱,而产品需要持续给用户提供价值,同时为自己积累 Credit。Credit 可以用来消费,比如日后增加了可能产生伤害用户体验的行为时,比如说广告、改版,Credit 高的产品对应用户的留存率会更高。
观察高留存用户或者路径是无意义
用户分析体系由属性 (Profile),偏好 (Tag),用法 (Preference) 和生命周期四个维度组成。属性包括人口学特征(性别、年龄等)、通过机器记录下来的东西,例如渠道、机型等。偏好则是在用户使用产品之后表现出来的特性。用法要比前两层更深入一些,是用户使用产品足够长后产生的数据,比如是喜欢训练、喜欢看视频。生命周期则是更长远的问题,是用户从激活到流失的整个过程的特征,要关注用户在生命周期中产生的价值与获客成本之间的关系。
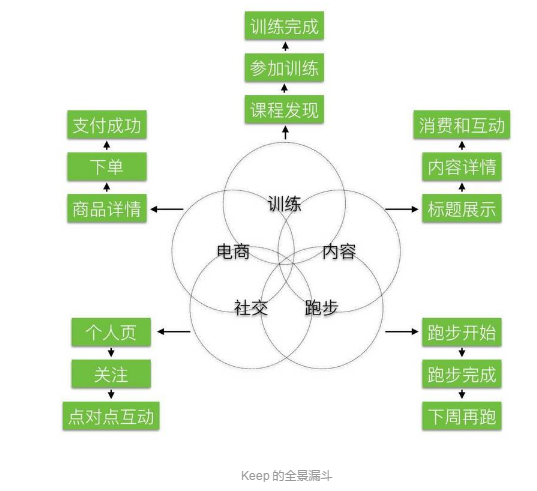
全景漏斗是更好观察用户体系的方式,把产品的核心用法进行梳理,建立每个核心用法的转化率漏斗。全景漏斗有两个维度,横向是各类用法平行分布,用户在用法之间迁移。用户要有两次来访才能被定义为真正使用某个「用法」,通过这样清洗一些脏数据。纵向是各类用法核心流程的转化。每一个用法都有自己的漏斗,漏斗里面每一步都是可以执行的。
观察用法迁移时,需要选定观察周期,一般是周。在同一个观察周期内,我们研究用户在各用法的重合度。在两个观察周期间,我们研究各用法的迁移情况。
单找高留存的用户或者是他们的路径是没意义的,这是回答不了如何让产品留存率高的问题。找出留存优化空间才更重要。
每个产品中都会存在一些「Ranger」。这些 Ranger 不存在于任何用法中,只具备「属性」和「偏好」两种特质,甚至甚至连「偏好」都没有。这样的用户比例有多大呢?张弦的经验数字是 20-30%。这些用户虽然是活跃的,但他们没有真正在用产品。就是所谓的来访游客。「Ranger 的生命周期都很短,我们要做的优化就是避免用户迁移到 Ranger上去。」
留存优化的空间在哪?
关于留存的优化空间,张弦给出了三个方向:
1.解决掉阻现有阻碍
例如 Keep 关于运动能力测试的调整,本来想希望通过引导新用户进行体能测试,快速找到练习课程,但其实很多用户首次注册启动后并不具备这样的测试环境,但又比较难找到关闭的「入口」,导致新用户流失,调整之后留存率有明显上升。
2.场景化和个性化(推送、推荐、模块),提高留存率
例如根据用户的网络环境情况来做不同的 Push,Keep 对新用户的首周推送套餐。
3.引导和激励,把用户激活
做留存优化的第一步要关注正确的指标。张弦认为选择的关注指标与留存率的关系应该是两步以内的。影响留存率的因素会有很多,所以留存率是可以往下拆的。与留存率直接相关的显然对留存影响更大。
下一步是做 A/B 测试。A/B 测试是有顺序的。A/B 测试需要去研究转化漏斗,从上游和下游的关系去想。开始要先对上游的指标去做测试,因为上游的指标被优化后,下游的指标也会改变。
A/B 测试最容易遇到的坑就是误差被低估。在做 A/B 测试时很重要的点在于控制唯一的变量,其他的变量上的变化应该是均匀的。这一步的变量检验一定不能忽略,实现的手段可以是逐步分组。另外一个容易犯的错是,同时分析多个因素对某个指标的影响。这样的测试是没有意义的,因为测试结果不能表明是由什么因素造成的。
作者:张弦,曾负责豆瓣所有产品线的数据分析工作,2016 年加入移动健身类应用 Keep,担任数据团队负责人。
来源:http://36kr.com/p/5063894.html
版权:人人都是产品经理遵循行业规范,任何转载的稿件都会明确标注作者和来源,若标注有误,请联系主编QQ:419297645






- 目前还没评论,等你发挥!


