
 起点课堂会员权益
起点课堂会员权益防忽悠指南!数据造假的九个方法
做数据分析的时候,有数据可以做分析,但要如何确保数据是真实有效的呢?本文总结了九个防止数据造假的方法,希望对您有所启发。

做数据分析,有数据才能分析如果数据是不真实的呢?如果数据是人为扭曲的呢?如果数据被人为扭曲,还要求你接受呢? 今天我们就来讨论这个话题。
以下是最常见的九大手段,大家先牢记于心。你将会在年终总结、年度规划、活动评估等场合遇到它们。提前了解,也好早早应对。
段位一:虚报数据
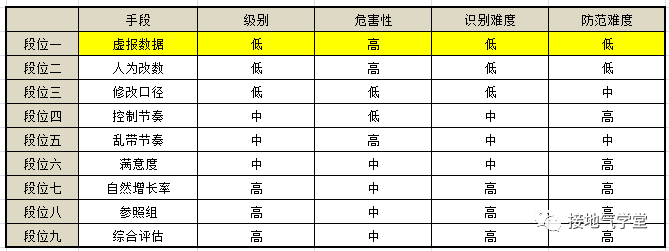
业务方故意虚报、谎报、不报数据,导致基础数据缺失,错误频发。这种情况在用纸质单张的年代很常见。不过随着数据系统的普及,此问题已经越来越少。
如果现在还有使用纸质单张的场景,比如用户纸质申请表、调查问卷等,此问题依然会存在。解决方案也很简单:上微信卡包呀!啥年代了注册个会员还写纸质单。
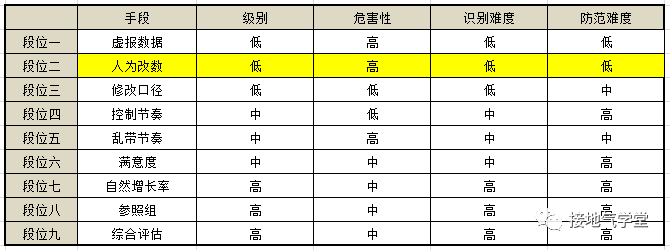
段位二:人为改数
参见:

系统是死的,可人是活的。想解决,只能加强考核,对违规操作的人严惩不贷。这些操作的规律性很强,且和具体人的行为高度绑定,通过分析是可以识别的。
段位三:修改口径
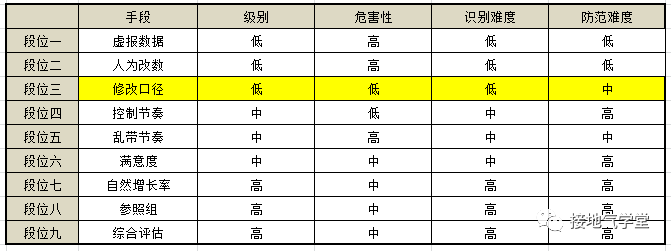
数据不好看了,怎么办?直接改统计口径!本质上讲,数据指标是为了计算方便而设的,作为使用方业务方想咋改就咋改。但是因为改动口径,导致前后数据不一致,就是大问题。
只改统计口径、不改指标名字,更是鱼目混珠的大问题。所以改口径可以,把过往数据报告,按新口径一口气刷了才成。
段位四:控制节奏

参考:

注意,和段位2不同,段位2是伪造数据欺骗公司,性质恶劣。段位4本质上没有伪造数据,而是利用了销售、运营、奖励的规则,谋取个人利益最大化而已。
实际上,是个人都会这么干,这属于业务潜规则。我们常说“水至清则无鱼”,你不可能要求一个人不为自己着想。如果真的管得太死,一线业务绝对会跳槽跑路。
作为数据分析,需要有能力识别这些具体问题,把它们控制在可接受的范围内。如果问题太过泛滥,再看如何推动制度层面优化调整(如下图所示)。
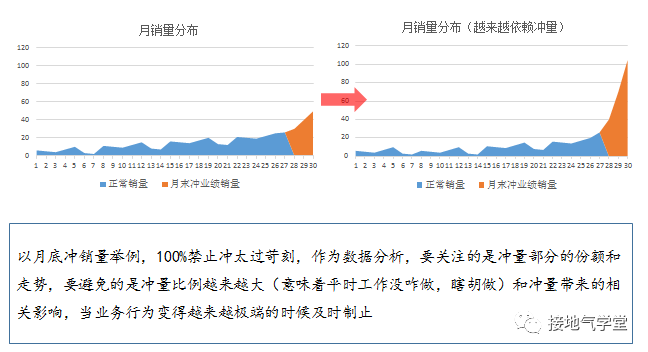
注意,从这个问题开始,我们进入中级难度,因为后边的问题,对数据分析师个人的分析能力要求会越来越高。就比如区分哪些是合理潜规则,哪些是恶意改数,是需要一定分析经验积累的。
段位五:乱带节奏
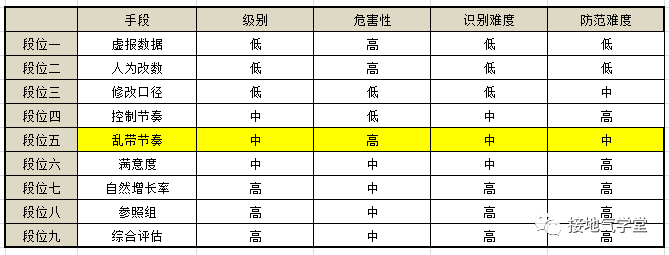
做数据分析时你一定经常听这种问题:
- “最近活跃率下降了?分析下原因”
- “最近销售表现不如人意,?分析下原因”
- “为什么我们的产品那么差?”
然而你辛辛苦苦扒了一堆数据,发现:没啥毛病啊?恭喜,你中了乱带节奏的全套。业务口中的“下降”“不好”“不满意”很有可能是个伪命题!

注意,业务方在不经意间扭曲数据判断,很多数据分析新人会直接一脚踩进去。很多新人做分析,不是先问是不是,而是直接研究为什么。按用户群、注册时间、产品类型等把数据拆得七零八落,最后屁都解读不出来。过两天回来一看,人家问题已经不存在了。
应对此类问题,切记:
遇到“大小、多少、高低、快慢、好坏”先问标准。
听到具体问题,先问怎么知道这个问题的。
听到人议论数据,先问原始数据源。 然而,难就难在,这三个“先问”是违背人本能的。听风就是雨才是人们最习惯的思考模式,所以这个看似简单的三个问题,需要大量、反复、强化训练才能习得,不然就经常被绕进去。
段位六:满意度
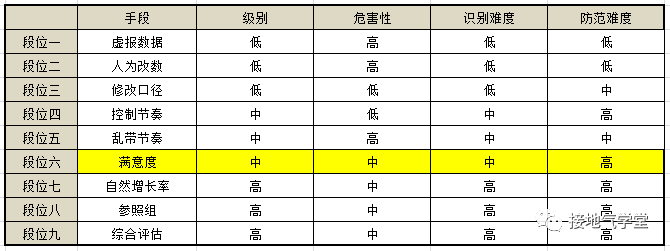
此处满意度,指的是那些业务部门口头高挂,却很难用系统直接记录数据的指标。类似的有满意度、品牌影响力、产品力、行业地位、NPS等等玩意。因为缺少直接记录,所以会引发很多幺蛾子。
段位七:自然增长率
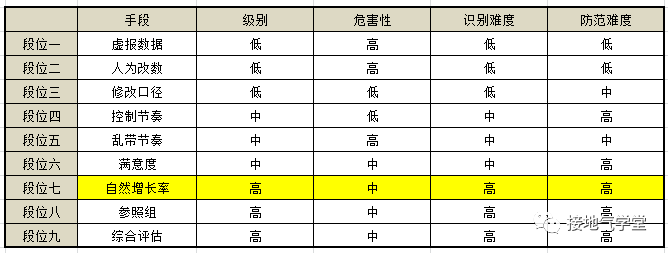
最后想操纵数据,只要不停地改“自然增长率”数据就好了,实在不行了还能把丫改成负数嘛(如下图)。
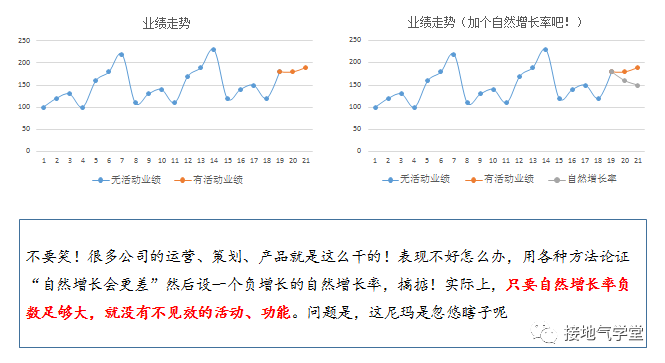
应对这种办法,最好的手段就是:不理他。活动实际参与量是很容易算清楚的,如果要定自然增长率,可以事先说好,免得事后啰嗦。
段位八:参照组
参照组和自然增长率是一对难兄难弟。都很容易被人立着“科学评估”的牌坊,实际上随意更换,改改改,改到业务满意为止。
如果业务方想纠结,他会一直说你设置的参照组不科学,样本都是特例,不够随机,不具有代表性。
实际上,只要不是全量统计,就永远能扣一个“不科学、不随机、不代表”的帽子(你真全量统计,他们又说:没有剔除自然增长,啦啦啦啦,反正总有理)。
最好的应对方法就是:不回应。只要分组方法是事先说清的,出啥结果就认啥结果,有啥好叽叽歪歪的。本身设参照组,只在做限定渠道精准推送的时候才能用。
本身设参照组,只是ABtest一种检验手段。本身Abtest,也只是检验工具之一,不是权威法则。难道没有ABtest业务部门就一点判断能力都没有了?你们的业务能力呢!要你们何用!好爽,终于能骂回去了!
段位九:综合评估
评价一个问题,用单一指标最清晰。然而人们偏偏喜欢用复合指标,以显得“思考全面”。
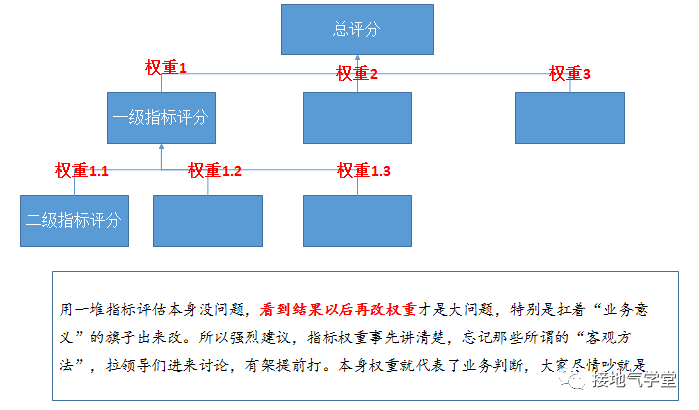
指标一多,势必设计权重分配。于是骚操作来了,如果评价出来,某人对结果不满意,便会祭出:“这个权重不合理,不能反映业务实际”的大旗,然后逼着你改。
最后结果,自然是让人家心满意足,才会说你分析深入合理。不然就继续来纠结。 最过分的,我还见过业务方领导手写了一个分公司评分排名,然后告诉我:你用大数据人工智能方法,把各个指标综合计算出这个排名,做得滴水不漏,明年合同还跟你签……
此时能说什么,当然是:好的。签单要紧,科学性算个屁,不就是改权重吗,搞得跟读研的时候没整过一样。
应对方法:每一个指标单独评分多指标的权重让领导定放弃业务解释度低的神经网络方法业务意见不一致,打完架告诉数据怎么定。
以上三个是高段位操纵数据的办法。之所以段位高,是因为自然增长率,参照组,综合评估本身就是数据分析常讨论的话题。很多新入行没吃过苦头的数据分析师,自己都很爱倒腾这些东西,以为做得越复杂就越高级。
最后结果是,做得越复杂,业务含义越难讲清楚,越是被业务方各种质疑,最后被牵着鼻子走,变成:“结果对业务有利就是客观全面,结果对业务不利就是缺少深入分析”,自讨苦吃。 小结 我们会发现:不同部门用的手段不一样。
销售、推广、供应链这些一线部门,数据本身就是他们工作的直接产物,因此最容易篡改数据源。运营、策划、产品等部门则最喜欢搞难以量化的指标,喜欢谈“深远影响”,喜欢设一堆“自然增长率”“参照组用户”然后剔除来剔除去,篡改的是基于数据的判断。
为啥销售、推广、供应链不折腾?因为人家面对的是结结实实的销售收钱,推广进人、仓库出货的问题,一个人头一分钱很清晰,没得扯皮。但是像运营、策划、产品这些大家一起干一件事的时候,就总想突出自己的功劳。
于是便开始了无休止的扯。 “剔除自然增长,我的活动带来多少效益”“剔除自然增长、活动拉动,我的产品改版带来多少效益”“剔除自然增长,活动拉动,产品改版,我的文案带来多少效益”…… 如果一定要对比两种危害,肯定是篡改数据源的危害更大。
如果数据是假的,那分析就无从谈起了。篡改数据源背后,代表着公司管理混乱,渠道控制软弱无力。有意思的是:总部的各职能部门都对这种软弱无力深恶痛绝,所以在这个问题上,往往总部部门是枪口一致对外的。 但在数据判断上,往往是乱自上做。
总部的运营、产品、策划们出于一己私利乱改标准,对于实现真正的数据驱动是非常有害的。不敢面对事实,拿数据粉饰太平,最后的结果就是业务部门自己越来越丧失判断能力,又回到拍脑袋决策,拍屁股走人的原始状态,这是我们不希望看到的。
理想的状态,是数据源真实丰富,数据判断简单清晰,数据分析深入立体。把精力多放在找原因、做预测、测试效果上,这样才能输出更好的成果。
本文由人人都是产品经理作者【接地气的陈老师】,微信公众号:【接地气的陈老师】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









真相是残酷的,人们更喜欢接受对自己有利的事实,不然怎么那么多美颜呢。最好的BI系统就是能自动数据美颜的系统!