
 起点课堂会员权益
起点课堂会员权益
用数据预测未来:时间序列分析
 技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估
技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估
对于本文内容,小编只知道作者介绍了一种用数据预测未来的方法——时间序列分析。……嗯,内容灰常灰常灰常烧脑,各位看官enjoy~
应用背景:
通过分析序列进行合理预测,做到提前掌握未来的发展趋势,为业务决策提供依据,这也是决策科学化的前提。
时间序列分析:
时间序列就是按时间顺序排列的一组数据序列。
时间序列分析就是发现这组数据的变动规律并用于预测的统计技术。
分析工具:
SPSS(数据分析的重量级应用,与SAS二选一)
实践案例:通过历史数据预测未来数据,所涉及的都是最简单的实践,抛砖引玉,重在方法,不论多复杂的数据,方法是一样的。
如已知前几年每月的销售量,预测未来的销售量。
一、时间序列分析简介
时间序列分析有三个基本特点:
- 假设事物发展趋势会延伸到未来
- 预测所依据的数据具有不规则性
- 不考虑事物发展之间的因果关系

并不是所有的时间序列都一定包含四种因素,如以年为单位的诗句就可能不包含季节变动因素。
四种因素通常有两种组合方式:
- 四种因素相互独立,即时间序列是四种因素直接叠加而成的,可用加法模型表示: Y=T+S+C+I
- 四种因素相互影响。即时间序列是四种因素相互综合的结果,可用乘法模型表示:Y=T*S*C*I
其中,原始时间序列值和长期趋势可用绝对数表示;季节变动、循环变动、不规则变动可用相对数(变动百分比)表示。
二、季节分解法
当我们对一个时间序列进行预测时,应该考虑将上述四种因素从时间序列中分解出来。
为什么要分解这四种因素?
- 分解之后,能够克服其他因素的影响,仅仅考量一种因素对时间序列的影响。
- 分解之后,也可以分析他们之间的相互作用,以及他们对时间序列的综合影响。
- 当去掉这些因素后,就可以更好的进行时间序列之间的比较,从而更加客观的反映事物变化发展规律。
- 分解之后,序列可以用来建立回归模型,从而提高预测精度。
所有的时间序列都要分解这四种因素吗?
通常情况下,我们考虑进行季节因素的分解,也就是将季节变动因素从原时间序列中去除,并生成由剩余三种因素构成的序列来满足后续分析需求。
为什么只进行季节因素的分解?
- 时间序列中的长期趋势反映了事物发展规律,是重点研究的对象;
- 循环变动由于周期长,可以看做是长期趋势的反映;
- 不规则变动由于不容易测量,通常也不单独分析。
- 季节变动有时会让预测模型误判其为不规则变动,从而降低模型的预测精度
综上所述:当一个时间序列具有季节变动特征时,在预测值钱会先将季节因素进行分解。
步骤:
- 定义日期标示变量:即先将序列的时间定义好,才能分析其时间特征。
- 了解序列发展趋势:即序列图,确定乘性还是加性
- 进行季节因素分解
- 建模
- 分析结果解读
- 预测
1、定义日期标示变量
时间序列的特点就是数据根据时间点的顺序进行排列,因此分析之前,SPSS需要知道序列的时间定义,然后才能进行分析时间特征。
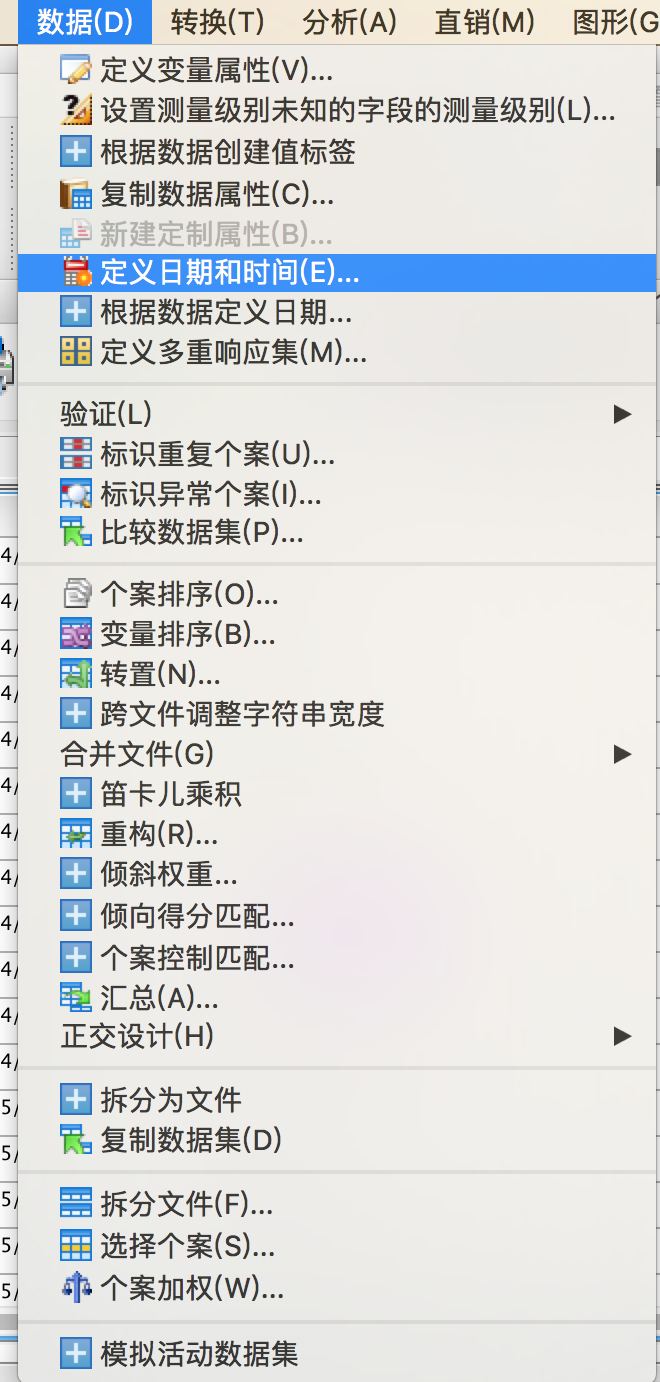

根据源数据的格式进行选择,并输入第一个个案的具体数值。

此时会在源文件中生成三个新的变量。
2、了解序列发展趋势
完成日期标示变量的定义之后,需要先对时间序列的变化趋势有所了解,便于选择合适的模型。即通过序列图,确定模型是乘性还是加性。
变量为”销售数据“,时间轴标签为”DATE–“,也就是我们自定义的时间。
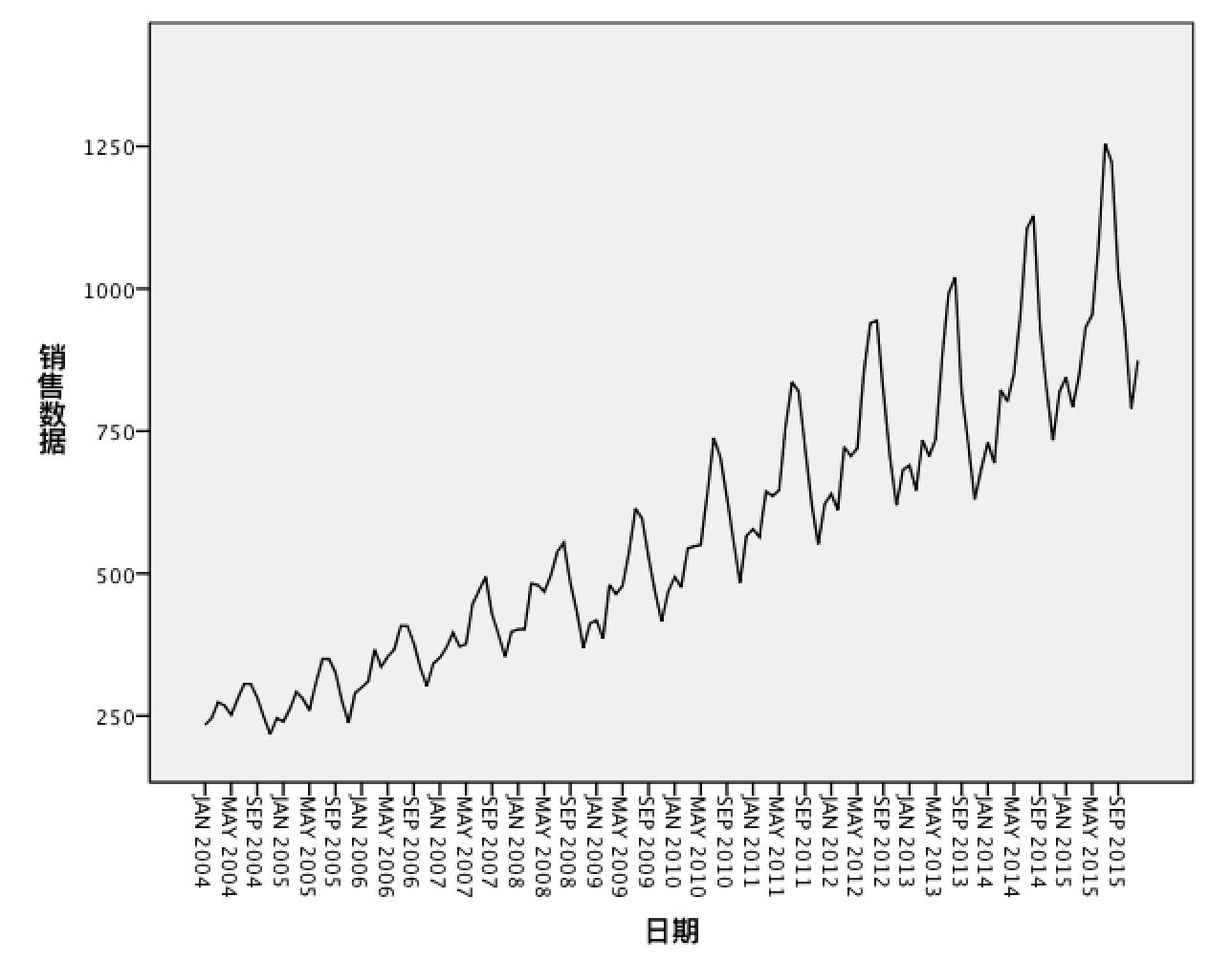
数据销量序列图
如何根据序列图来判断模型的乘性或加性?
- 如果随着时间的推移,序列的季节波动变得越来越大,则建议使用乘法模型。
- 如果序列的季节波动能够基本维持恒定,则建议使用加法模型。
本例很明显:随着时间变化,销售数据的季节波动越来越大,那么使用乘法模型会更精确。
3、进行季节因素分解
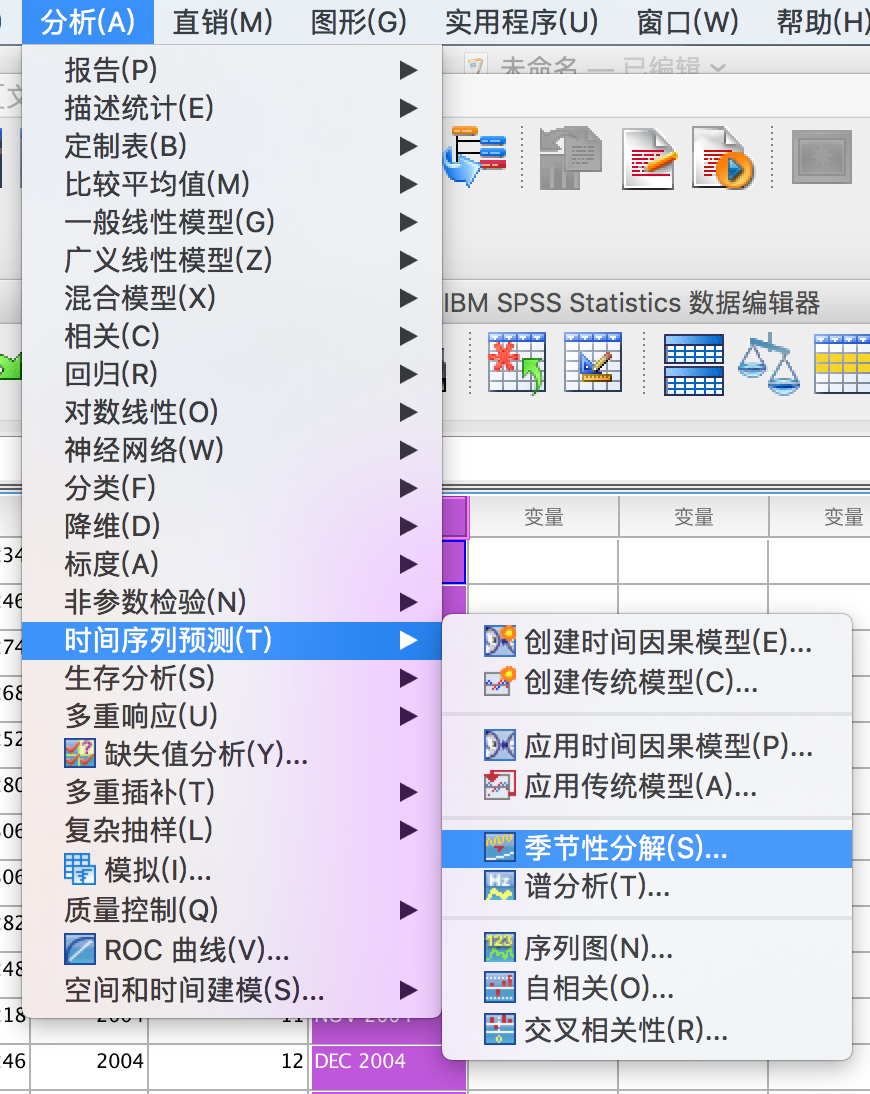
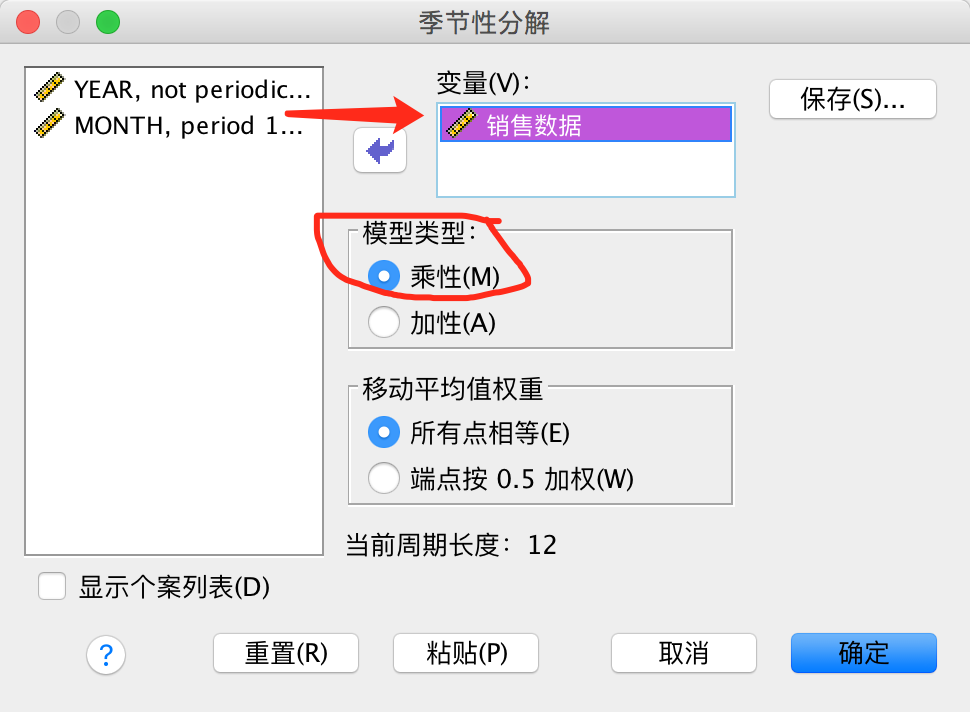
变量为”销售数据“,且根据序列图我们知道时间序列模型为乘性。
 提示您会新生成四个变量
提示您会新生成四个变量
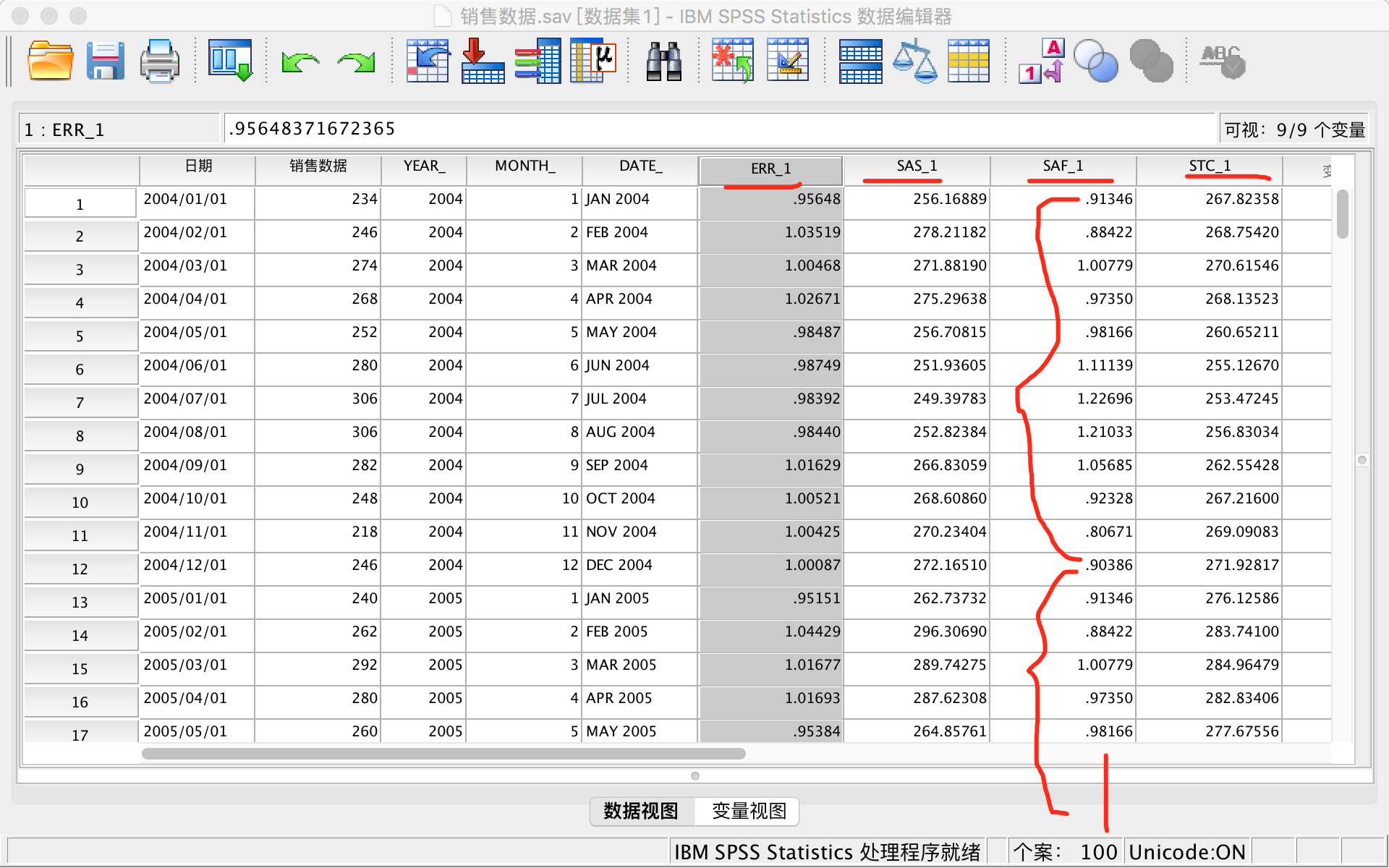
- ERR(误差序列):从时间序列中移除季节因素、长期趋势、和循环变动之后留下的序列,也就是原始序列中的不规则变动构成的序列。
- SAS(季节因素校正后序列):是移除原始序列中的季节因素后的校正序列。
- SAF(季节因子):是从序列中分解出的季节因素。其中的变量值根据季节周期的变动进行重复,如本例中季节周期为12个月,所以这些季节因子没12个月重复一次。
- STC(长期趋势和循环变动趋势):这是原始序列中长期趋势和循环变动构成的序列。
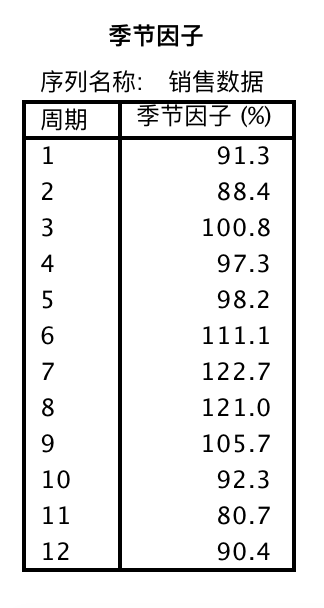
如图,周期为12个月,季节因子12个月循环一次。
完成季节因素分解后的序列和原始序列之间有什么差异?
通过回执序列图的方法把原始序列和除去季节因子的三个序列(误差序列、季节因素校正后序列、长期无视和循环变动序列)进行比较。
要做四个序列图,会有四个变量:
- 原始序列:使用变量”销售数据“;
- 误差序列:使用变量”ERR“;
- 季节因素校场后序列:使用变量”SAS“
- 长期趋势和循环变动序列:使用变量”STC“
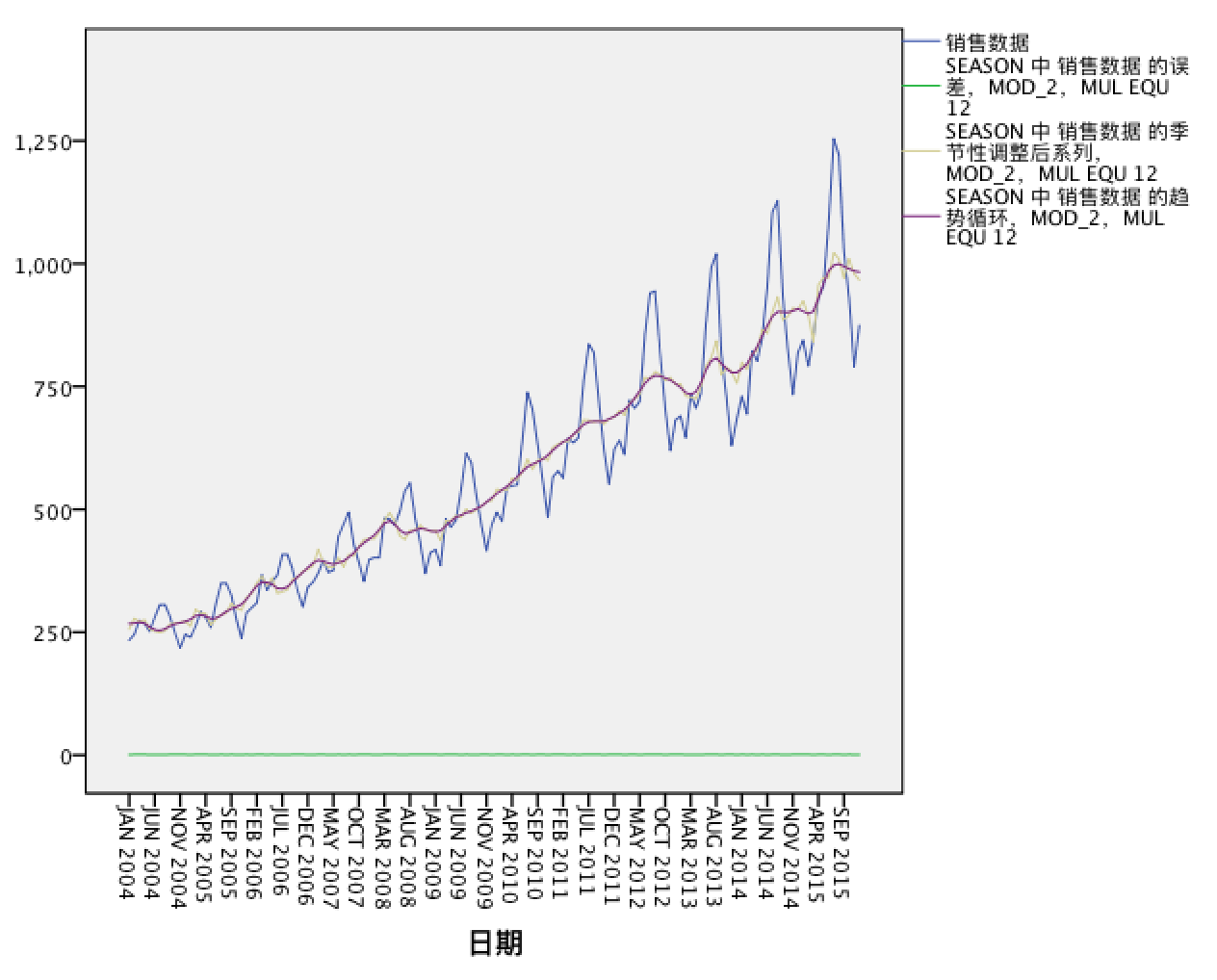
- 蓝色线:原始序列
- 紫色线:长期趋势和循环变动序列
- 浅棕色:季节因素校正后序列
- 绿色线:误差序列(不规则变动)
因为误差序列数值非常小,所以长期趋势和循环变动序列(长期趋势+循环变动)与季节因素校正后序列(长期趋势+循环变动+不规则变动,即误差)能够基本重合。
在单独做”季节因子SAF“的序列图:
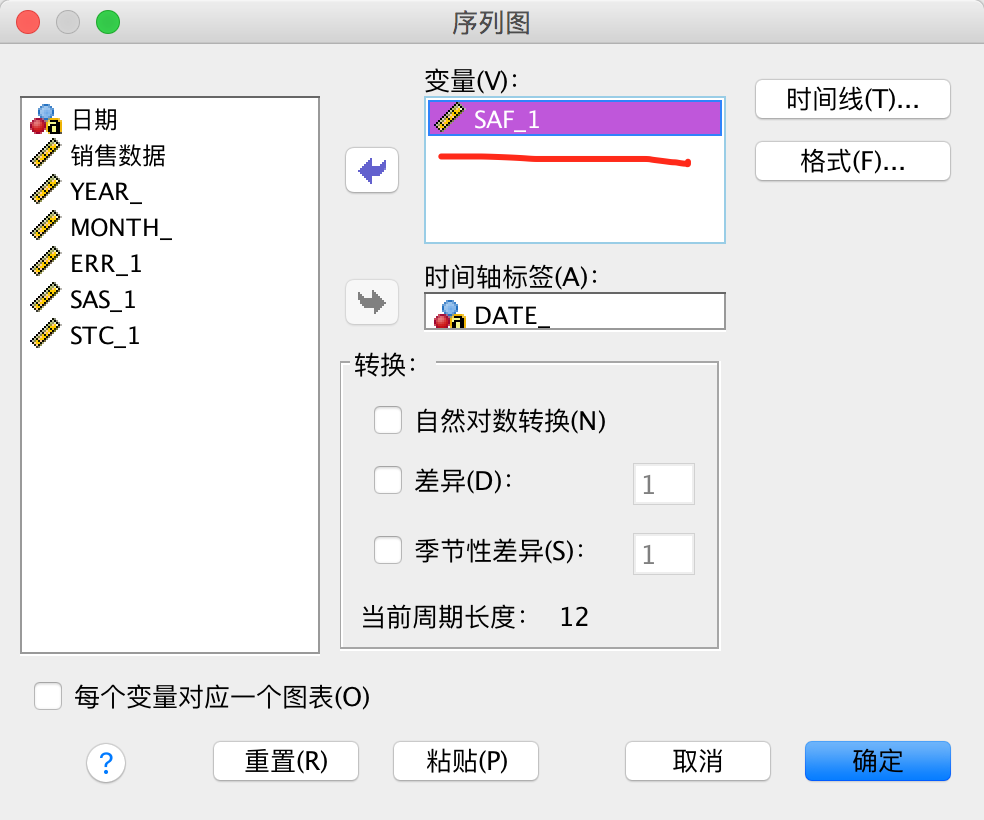
因为是做”季节因子“的序列图,所以只有一个变量”季节因子SAF“
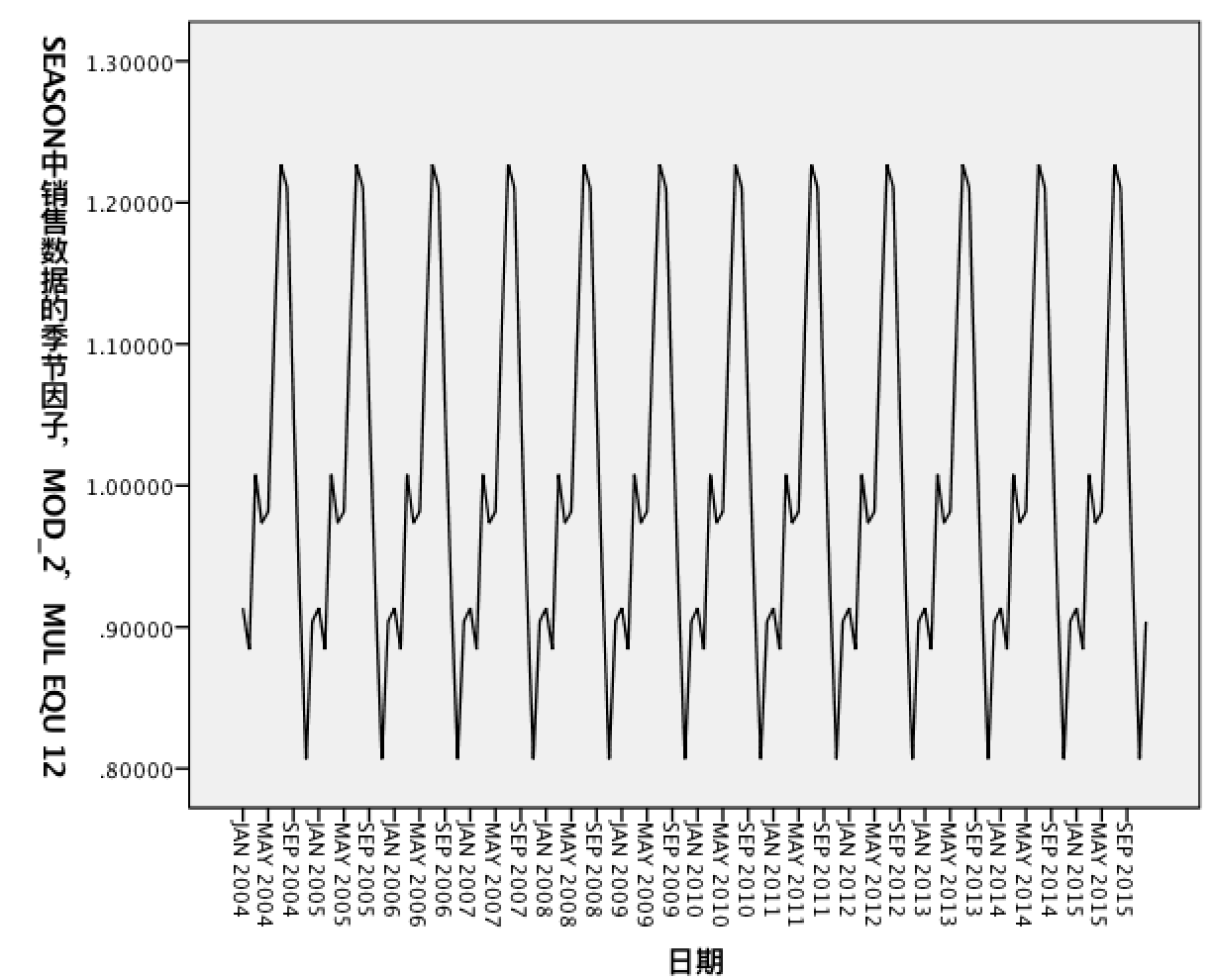
我们看出:季节因素的周期是12个月,先下降,然后上升到第一个顶点,再有略微的下降后,出现明显的上升趋势,到第七个月时达到峰值,然后一路下跌,直到最后一个月份有所回升,之后进入第二个循环周期。
通过对原始序列的季节分解,我们更好的掌握了原始序列所包含的时间特征,从而选用适当的模型进行预测。
三、专家建模法
时间序列的预测步骤有四步:
- 绘制时间序列图观察趋势
- 分析序列平稳性并进行平稳化
- 时间序列建模分析
- 模型评估与预测
平稳性主要是指时间序列的所有统计性质都不会随着时间的推移而发生变化。
对于一个平稳的时间序列,具备以下特征:
- 均数和方差不随时间变化
- 自相关系数只与时间间隔有关,与所处的时间无关
自相关系数是研究序列中不同时期的相关系数,也就是对时间序列计算其当前和不同滞后期的一系列相关系数。
平稳化的方法——差分。
差分就是指序列中相邻的两期数据之差。
- 一次差分=Yt-Yt-1
- 二次差分=(Yt-Yt-1)-(Yt-1-Yt-2)
具体的平稳化操作过程会有专家建模法自动处理,我们只需要哼根据模型结果独处序列经过了几阶差分即可。
时间序列分析操作:
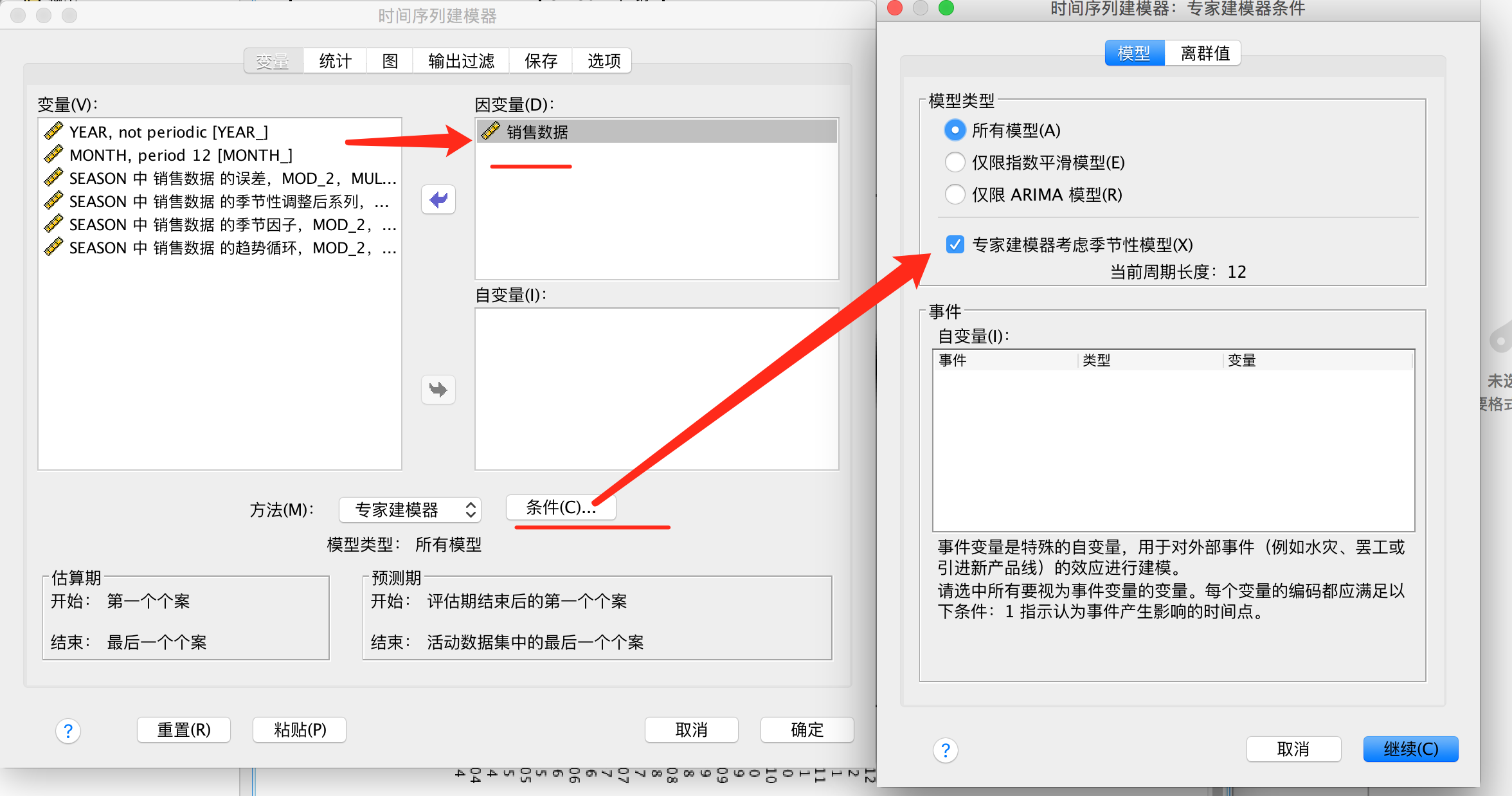
要分析所有变量,所以选择”销售数据“。
【专家建模器】–【条件】,勾选”专家建模器考虑季节性模型“。
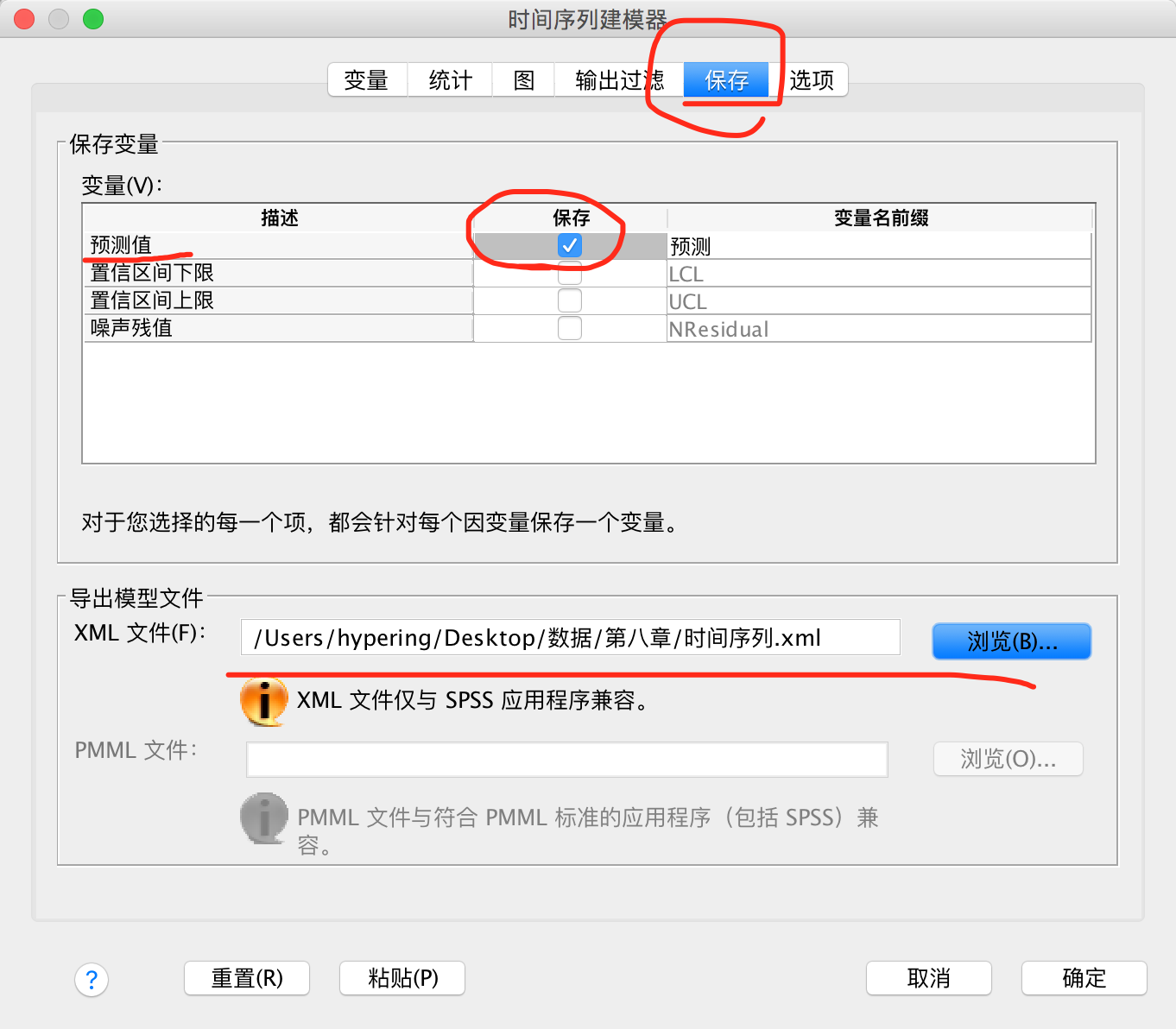
勾选”预测值“,目的是生成预测值,并保存模型。
时间序列分析结果解读
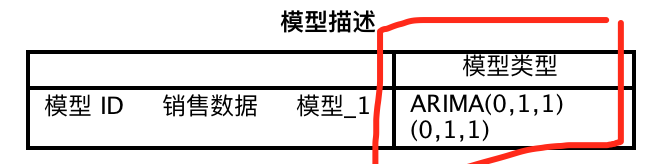
该表显示了经过分析得到的最优时间序列模型及其参数,最优时间U型猎魔性为ARIMA(0,1,1)(0,1,1)
求和自回归移动平均模型ARIMA(p,d,q)(P,D,Q)
- p:出去季节性变化之后的序列所滞后的p期,通常为0或1,大于1的情况很少;
- d:除去季节性变化之后的序列进行了d阶差分,通常取值为0,1或2;
- q:除去季节性变化之后的序列进行了q次移动平均,通常取值0或1,很少会超过2;
P,D,Q分别表示包含季节性变化的序列所做的事情。
因此本例可解读为:对除去季节性变化的序列和包含季节性变化的序列分别进行了一阶差分和一次移动平均,综合两个模型而建立出来的时间序列模型。
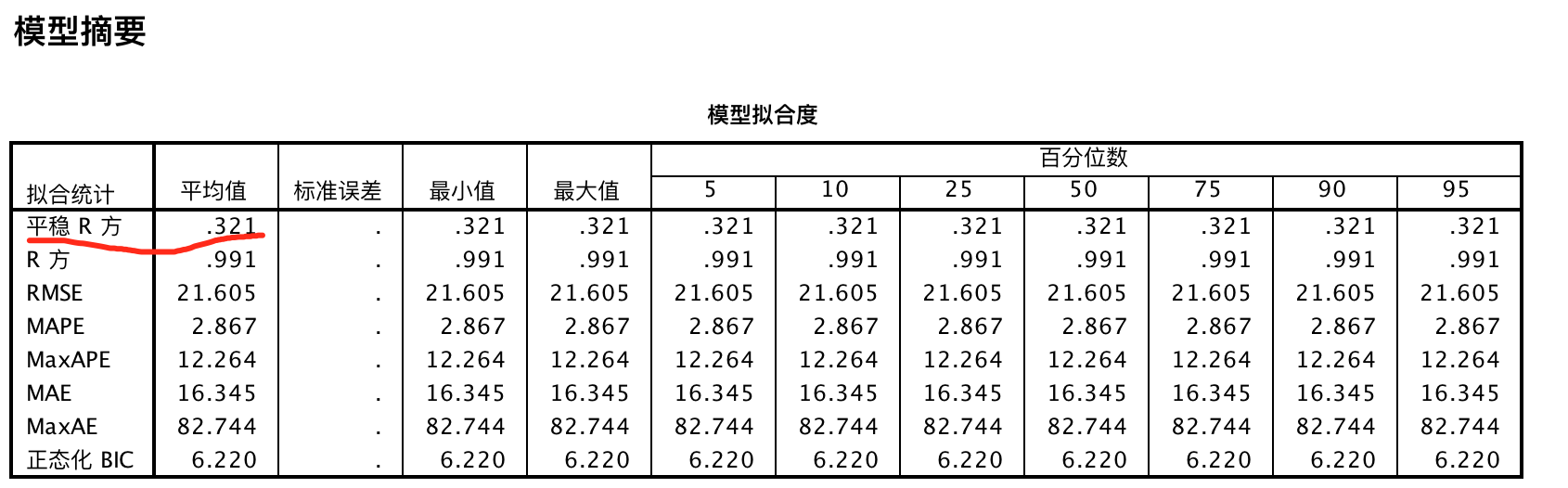
该表主要通过R方或平稳R方来评估模型拟合度,以及在多个模型时,通过比较统计量找到最优模型。
由于原始变量具有季节性变动因素,所以平稳的R方更具有参考意义,等于32.1%,拟合效果一般。
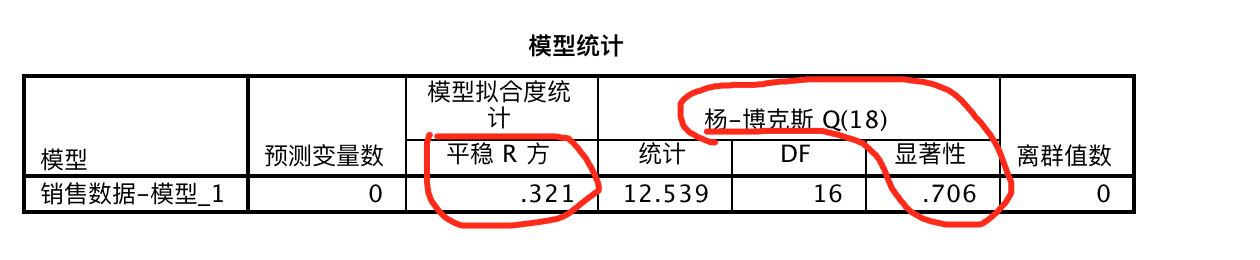
该表提供了更多的统计量可以用来评估时间序列模型的拟合效果。
虽然平稳R方仅仅是32.1%,但是”杨-博克斯Q(18)“统计量的显著性P=0.706,大于0.05(此处P>0.05是期望得到的结果),所以接受原假设,认为这个序列的残差符合随机分布,同时没有离群值出现,也都反映出数据的拟合效果还可以接受。
时间序列应用预测:
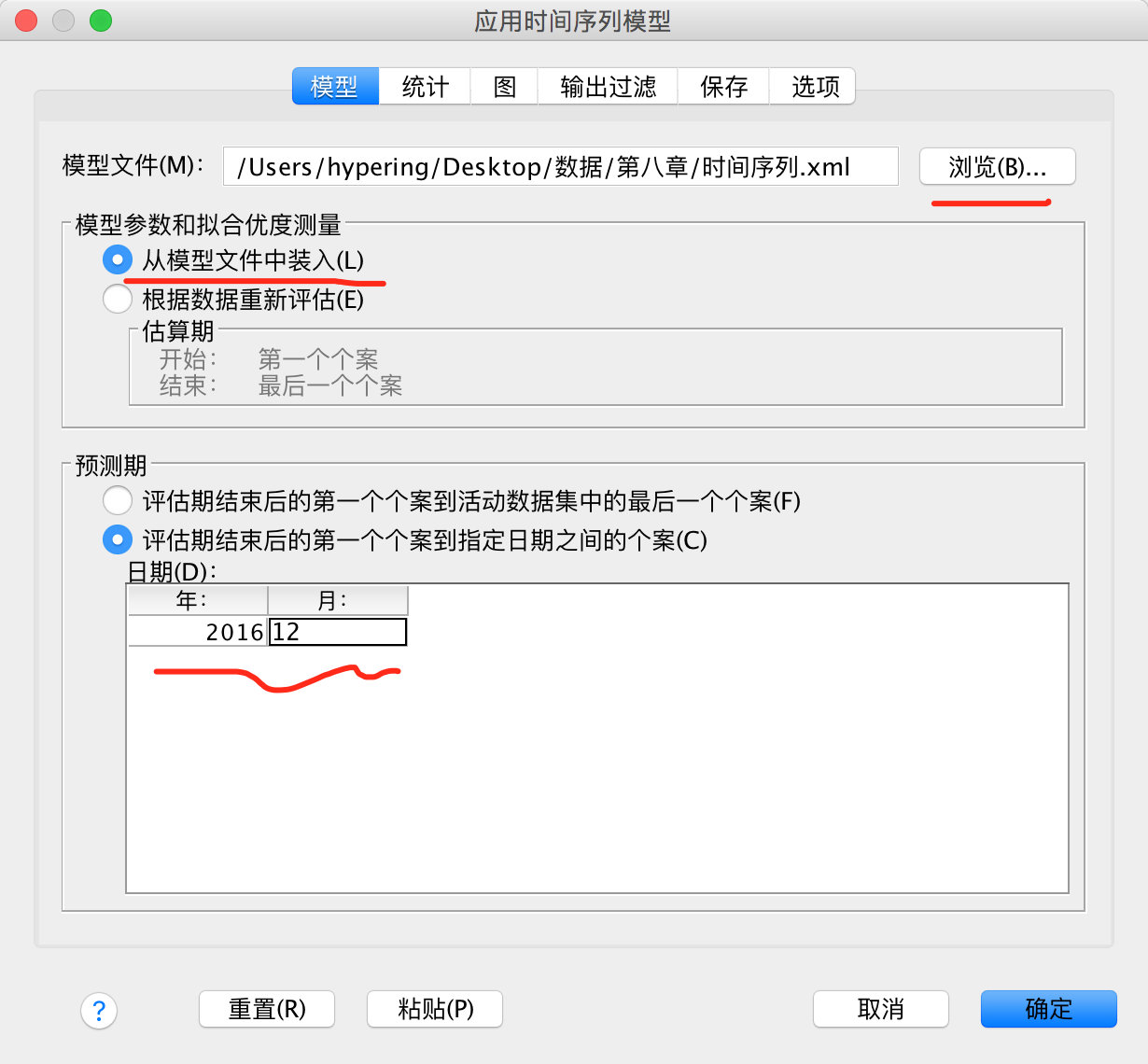
未来一年是到2016年12月,手动输入即可。
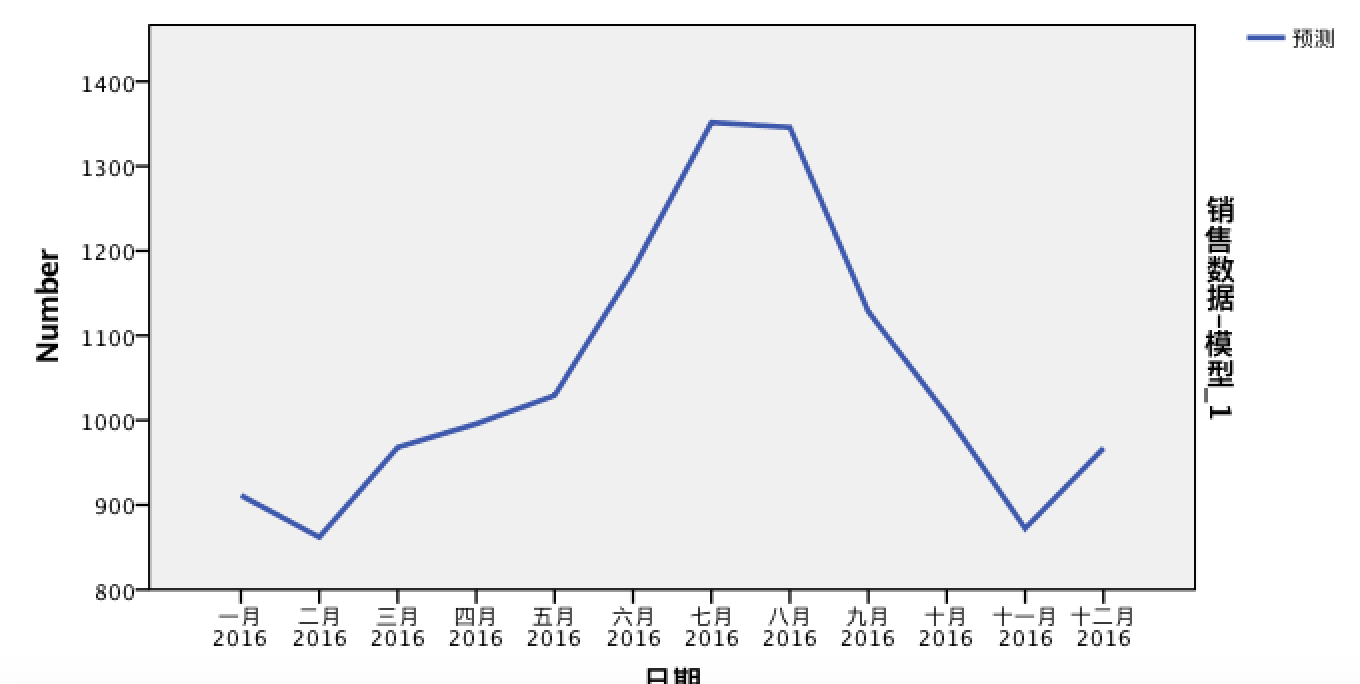
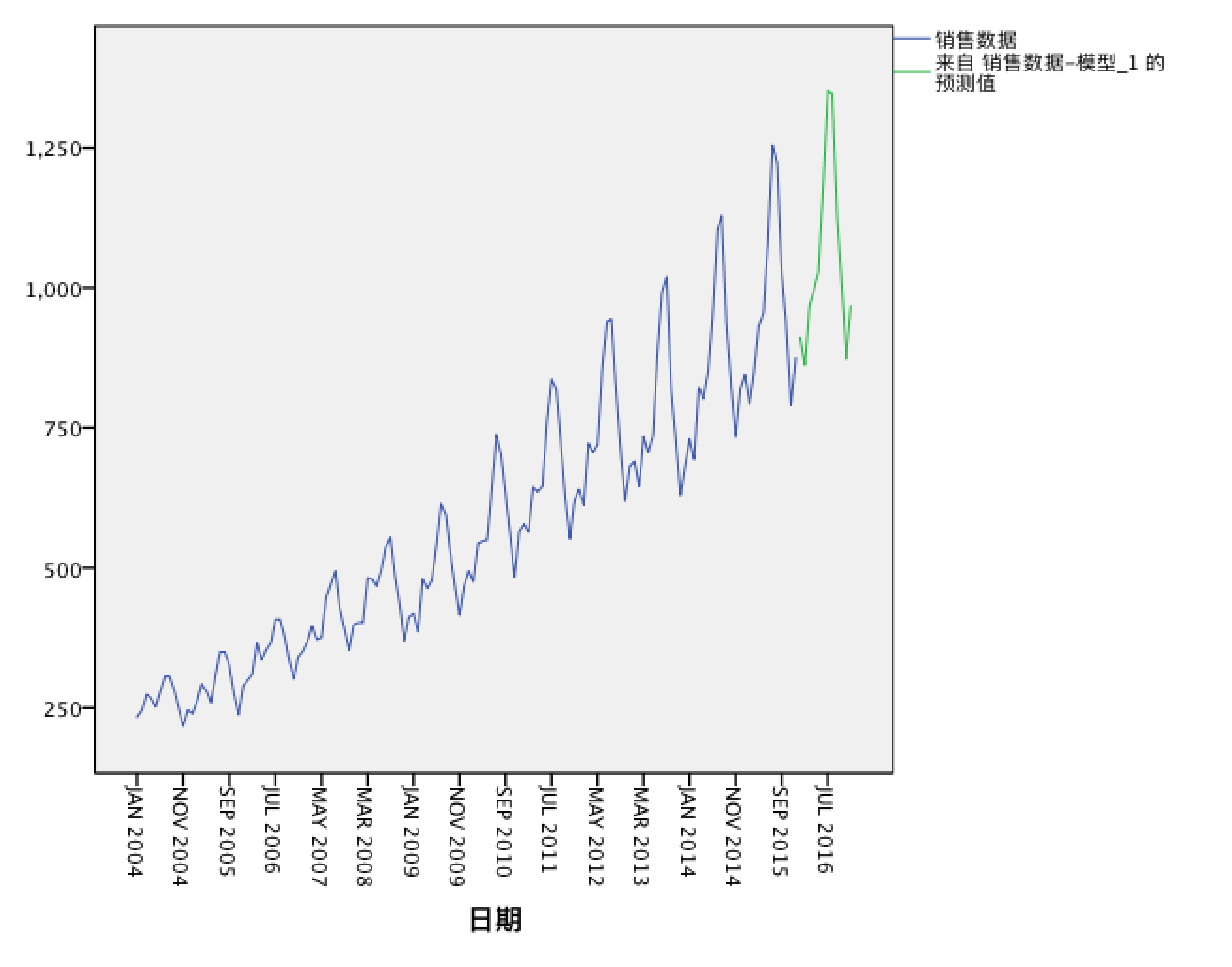
这是未来一年的销售趋势。
如果想从全局来观察预测趋势,可以在把这一年的趋势和以前的数据连接起来
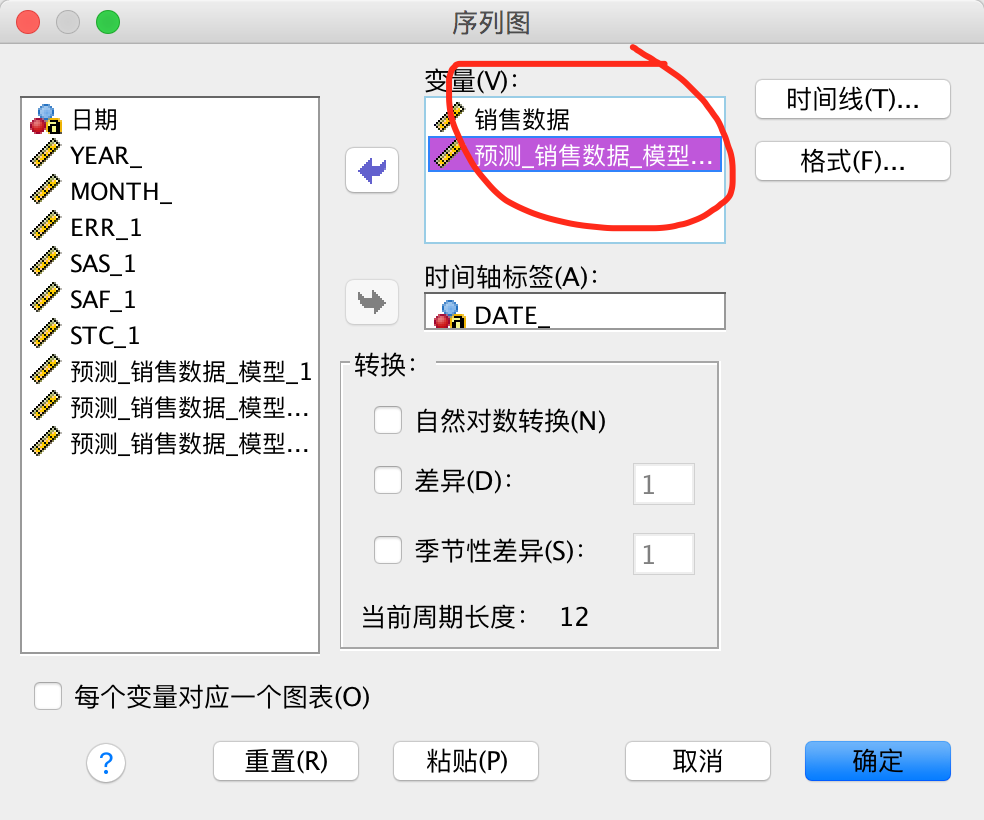
此时的变量应该是”原始的销售数量“和”2016年的预测销售数量“。
结果如下:
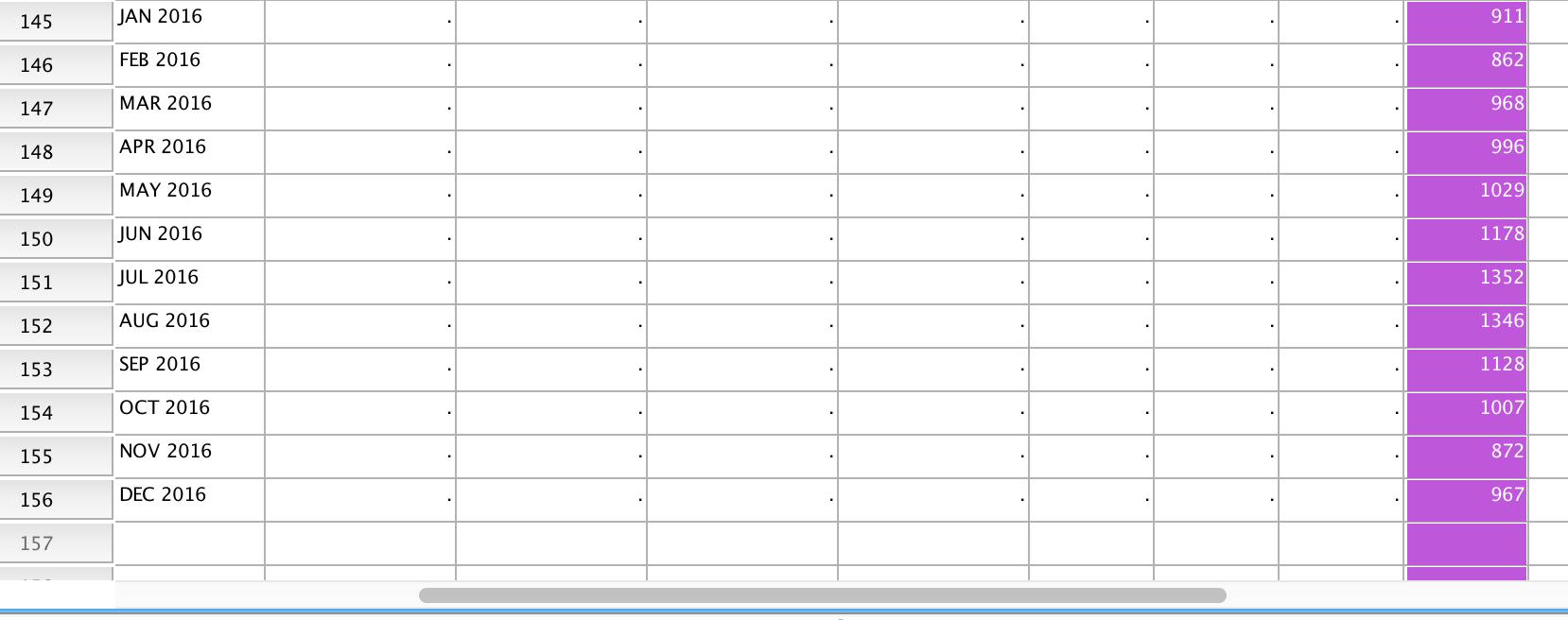
也可以在表中查看具体的数值:
作者:膝盖哥,是一枚“跪着提需求”的产品经理。常说“不用不用,真的不用了,我跪着就好!”
本文由 @膝盖哥 原创发布于人人都是产品经理。未经许可,禁止转载。
















请问如果数据是年月日这个颗粒度的,该怎么定义时间呢,默认的定义时间格式没有这样的
很棒
很清晰呀,赶紧用实际的数据来跑一跑
可以化繁为简为何多码字