
 起点课堂会员权益
起点课堂会员权益如何七周成为数据分析师19:Python的数据结构

本文是《如何七周成为数据分析师》的第十九篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉Python,大可不必再看这篇文章,或只挑选部分。
Python一共有三大数据结构,它是Python进行数据分析的基础,分别是tuple元组,list数组以及dict字典。本文通过这三者的学习,打下数据分析的基础。
数组
数组是一个有序的集合,他用方括号表示。
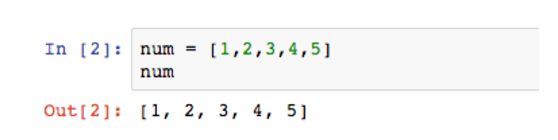
num就是一个典型的数组。数组不限定其中的数据类型,可以是整数也可以是字符串,或者是混合型。
数组可以直接用特定的函数,函数名和Excel相近。
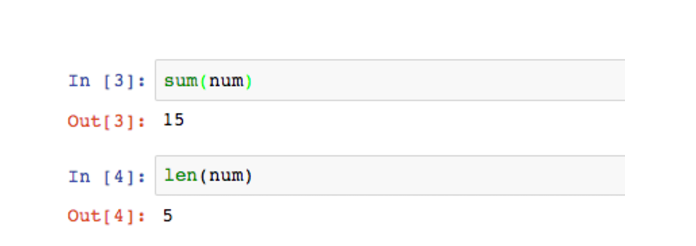
sum是求和,len则是统计数组中的元素个数。
上述列举的函数是数组内整体元素的应用,如果我只想针对单一的元素呢?比如查找,这里就要用到数组的特性,索引。索引和SQL中的索引差不多,都是用来指示数据所在位置的逻辑指针。数组的索引便是元素所在的序列位置。

注意,索引位置是从0开始算起,这是编程语言的默认特色了。num[0]指数组的第一个元素,num[1]指数组的第二个元素。
我们用len()计算出了数组元素个数是5,那么它最后一个元素的索引是4。若是数组内的元素特别多呢?此时查找数组最后一位的元素会有点麻烦。Python有一个简易的方法,可以用负数表示,意为从最后一个数字计算索引。

这里的num[4]等价于num[-1],num[-2]则指倒数第二个的元素。
再来一个新问题,如何一次性选择多个元素?例如筛选出数组前三个元素。在Python中,用:表示范围。
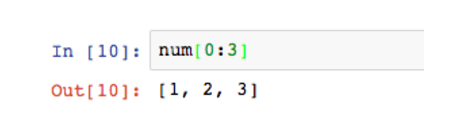
num[0:3]筛选了前三个元素,方括号左边是闭区间,右边是开区间,所以这里是num[0],num[1]和num[2],并不包含num[3]。这个方法叫做切片。

上述是索引的特殊用法,[0:]表示从第0个索引开始,直到最后一个元素。[:3]表示从第一个元素开始,直到第3个索引。

负数当然也有特殊用法。[-1:]表示从最后一个元素开始,因为它已经是最后一个元素了,所以只返回它本身。[:-1]表示从第一个元素开始到最后一个元素。num[-2:-1]和num[-3:-1]大同小异。
数组的增删查
我们已经了解数组的基本概念,不过仍旧停留在查找,它不涉及数据的变化。工作中,更多需要操纵数组,对数组的元素进行添加,删除,更改。
数组通过insert函数插入,函数的第一个参数表示插入的索引位置,第二个表示插入的值。

另外一种方式是append,直接在数组末尾添加上元素。它在之后讲到迭代和循环时应用较多。

如果要删除特定位置的元素,用pop函数。如果函数没有选择数值,默认删除最后一个元素,如果有,则删除数值对应索引的元素。

更改元素不需要用到函数,直接选取元素重新赋值即可。

到这里,数组增删改查已经讲完,但这只是一维数组,一维数组之上还有多维数组。如果现在有一份数据是关于学生信息,一共有三个学生,要求包含学生的姓名,年龄,和性别,应该怎么用数组表示呢?
有两种思路,一种是用三个一维数组分别表示学生的姓名,年龄和性别。
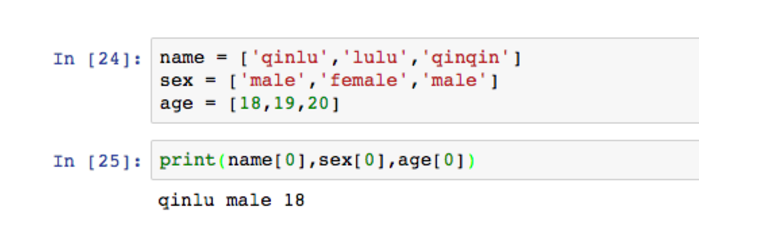
学生属性被拆分成多个数组,利用索引来表示其信息,这里的索引有些类似SQL的主键,通过索引查找到信息。但是这种方法并不直观,实际应用会比较麻烦,更好的方法是表示成多维数组。

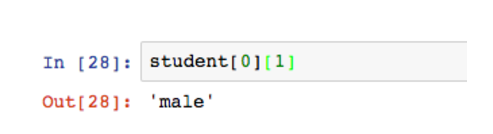
所谓多维数组,是数组内再嵌套数组,图中表示的是一个宽度为3,高度为3的二维数组。此时student[0]返回的是数组而不是单一值。这种方法将学生信息合并在一起,比第一个案例更容易使用。
如果想选择第一个学生的性别,应该怎么办呢?很简单,后面再加一个索引即可。
现在尝试快速创建一个多维数组。
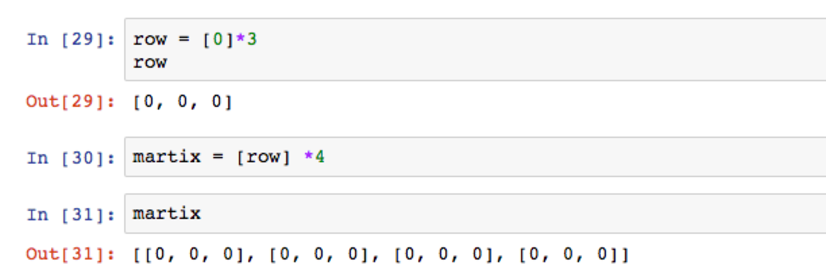
[0]*3将快速生成3个元素值为0的数组,这是一种快捷操作,而[row]*4则将其扩展成二维数据,因为是4,所以是3*4的结构。
这里有一个注意点,当我们想更改多维数组中的某一个元素而不是数组时,这种方式会错误。
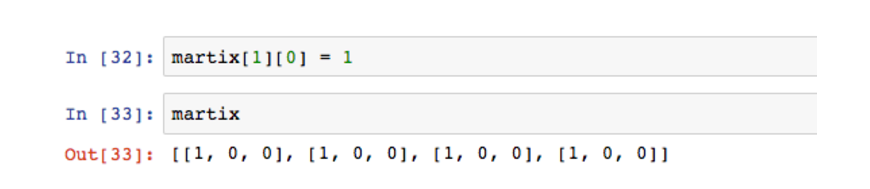
按照正常的想法,martix[1][0]将会改变第二个数组中的第一个值为1,但是结果是所有数组的第一个值都变成1。这是因为在matrix = [row] * 4操作中,只是创建3个指向row的引用,可以简单理解成四个数组是一体的。一旦其中一个改变,所有的都会变。
比较稳妥的方式是直接定义多维数组,或者用循环间接定义。多维数组是一个挺重要的概念,它也能直接表示成矩阵,是后续很多算法和分析的基础(不过在pandas中,它是另外一种形式了)。
元组
tuple叫做元组,它和数组非常相似,不过用圆括号表示。但是它最大的特点是不能修改。

当我们想要修改时就会报错。
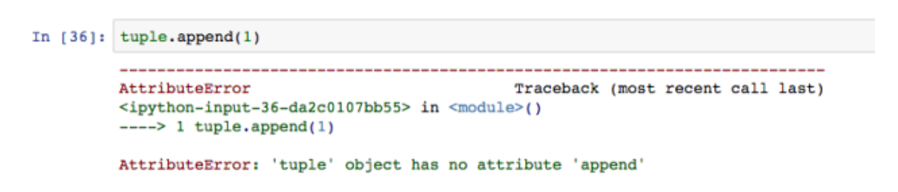
而选择和数组没有差异。
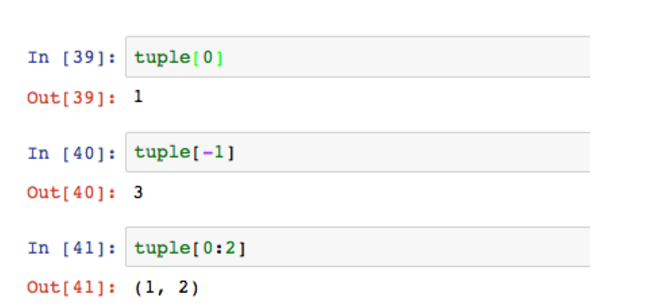
元组可以作为简化版的数组,因为它不可更改的特性,很多时候可以作为常量使用,防止被篡改。这样会更安全。
字典
字典dict全称dictionary,以键值对key-value的形式存储。所谓键值,就是将key作为索引存储。用大括号表示。
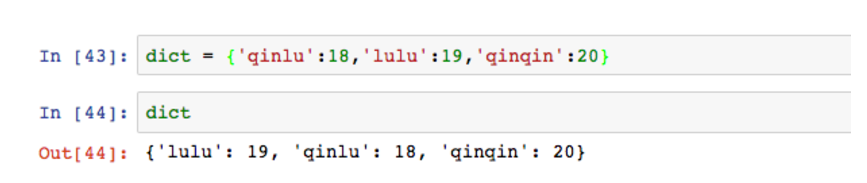
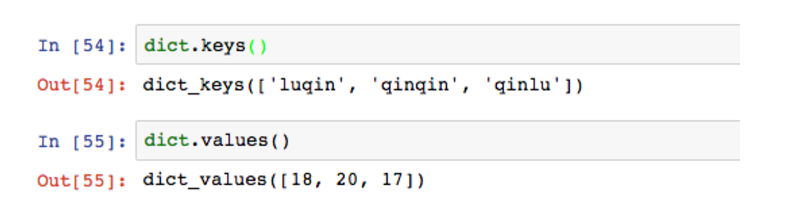
图中的’qinlu’是key,18是value值。key是唯一的,value可以对应各种数据类型。key-value的原理不妨想象成查找字典,拼音是key,对应的文字是value(当然字典的拼音不唯一)。
字典和数组的差异在于,因为字典以key的形式存储和查找,所以它的查询速度非常快,毕竟翻字典的时候你只要知道拼音就能快速定位了。对dict数据结构,10条记录和10万条记录的查找没有区别。
这种查找方式的缺点是占用内存大。数组则相反,查找速度随着元素的增加逐渐下降,这个过程想象成程序在一页页的翻一本没有拼音的字典,直到找到内容。数组的优点是占用的内存空间小。
所以数组和字典的优缺点相反,dict是空间换时间,list是时间换空间,这是编程中一个比较重要的概念。实际中,数据分析师的工作不太涉及工程化,选用数组或者字典没有太严苛的限制。
细心的读者可能已经发现,字典定义时我的输入顺序是qinlu,lulu,qinqin,而打印出来是lulu,qinlu,qinqin,顺序变了。这是因为定义时key的顺序和放在内存的key顺序没有关系,key-value通过hash算法互相确定,甚至不同Python版本的哈希算法也不同。这一点应用中要避免出错。
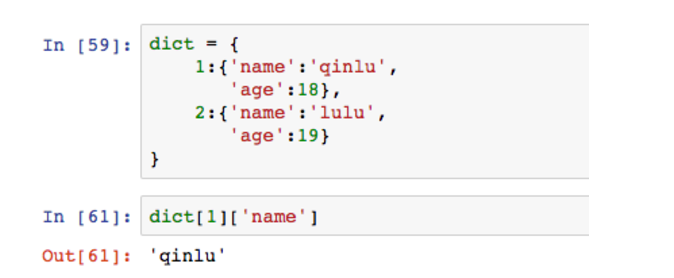
既然字典通过key-value对匹配查找,那么它自然不能不用数组的数值索引,它只能通过key值。

如果key不存在,会报错。
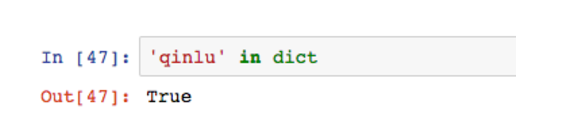
通过in方法,可以返回True或False,避免报错。
dict和list一样,直接通过赋值更改value。
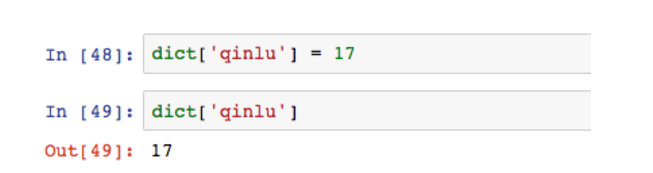
能不能更改key的名字?不能,key一旦确定,就无法再修改,好比字典定好后,你能修改字的拼音么?
dict中删除key和list一样,通过pop函数。增加key则是直接赋予一个新的键值对。

dict的keys和values两个函数直接输出所有的key值和value值。如果要转换成数组,则再外面嵌套一个list函数。
items函数,将key-value对变成tuple形式,以数组的方式输出。

字典可以通过嵌套应用更复杂的数据格式,和NoSQL与JSON差不多。
基础的数据类型差不多了,更多函数应用大家网上自行查阅文档,这块掌握了,在数据清洗过程中将会非常高效,尤其是读取Excel数据时。当然不要求滚瓜烂熟,因为后面将学习更加强大的Numpy和Pandas。
相关阅读
如何七周成为数据分析师01:常见的Excel函数全部涵盖在这里了
如何七周成为数据分析师:Excel技巧之甘特图绘制(项目管理)
#专栏作家#
秦路,微信公众号ID:tracykanc,人人都是产品经理专栏作家。
本文由 @秦路 原创发布于人人都是产品经理。未经许可,禁止转载。






- 目前还没评论,等你发挥!


