
 起点课堂会员权益
起点课堂会员权益不会机器学习,你照样可以预测用户流失

即使不会高深莫测的机器学习,你照样可以利用统计学来预测用户流失。
什么是用户流失率?我们为什么需要关注用户流失率?
简单来说,用户流失率是指用户的流失数量与全部使用/消费产品(或服务)用户的数量的比例,是用户流失的定量表述,以及判断用户流失的主要指标,直接反映了产品的市场接受程度如何,以及运营工作的好坏。

一般来说,这个指标用在“订阅型产品”的情形居多,如信息订阅类App“锤子阅读”、绝大多数的在线SaaS产品,甚至传统的牛奶订购。由于留住当前的用户要比获取新用户来的划算,所以预测流失率的目标在于:
预测用户将会在哪个时间点离开(在订阅期结束前),在合适的时间点对这些用户施加影响,挽留他们,如通过短信、邮件或APP,利用超低价商品吸引回访或者专属优惠券等,这些策略对于一些流失用户是很有效的!
接下来,笔者将利用简单的统计学知识,介绍一种基于用户不活跃记录的用户流失预测模型。该模型在不使用机器学习算法的情况下,可以给出一个容易理解的用户流失预测,以便我们对将要离开的用户有一个相当准确的洞察。
废话不多说,进入正题吧~
1 用户活跃的操作性定义
在我们正式开始预测用户流失率之前,我们需要记录用户的历史活跃情况。做这个的目的在于,了解用户是否在使用我们的产品或服务。那么,问题就来了,用户的“活跃”该做怎样的操作性定义(即根据可观察、可测量、可操作的特征来界定变量含义的方法)?实际上,“用户活跃”的定义取决于你的业务背景,跟产品或者服务具体场景密切相关,不同类型的产品对“用户活跃”有不同的定义。
以xxx的“信息监测”为例,它是一款订阅型的社会化大数据产品,用户通过设置各种关键词组合来检索相关信息,然后选择邮件或者客户端订阅,通过自定义的接收频次来准时收取订阅信息。
对于这款大数据产品来说,“用户活跃”可以这样定义—如果一个用户是活跃的,那么,ta在指定时间段内(分析的时间单位取决于分析者对业务的理解,可以是天、周、月、季度或年),应该包含如下付费、使用或者互动行为:
- 该用户对“信息监测”的订阅尚未过期;
- 该用户在web端或者移动端登录产品页面;
- 该用户使用了产品的部分或全部功能,如基于信息源或者地域的定向监测功能;
- 该用户在此期间产生了一定消费,如文本数据下载、订阅续费、定制报告等;
- 该用户在此期间对该产品有各种反馈,包括投诉。
…
对于这款产品来说,以月份为单位来分析用户行为是很有意义的—因为该产品最短的订阅期是一个月,最长的订阅期是一年。
一旦清晰的界定了“用户活跃”的定义,我们就可以用这些操作性定义来对每个月份的用户(不)活跃情况进行编码,利用二进制值(0,1)—假如在X月份,用户是活跃的,将ta的活跃值设定为1,否则设定为0。
2 建立“用户不活跃档案”
现在,对于每位用户,我们有了一个以月为单位的“活跃标记”,接下来我们以此为基础,建立起“用户不活跃档案”。这意味着,对于每个用户,笔者想对他们连续不活跃的月份数进行计数统计。
在这里,笔者选择了一年的“分析窗口”(也就是把12个月作为分析的时间范围),将“活跃档案”和“不活跃档案”以表格的形式呈现—蓝色表单显示每位用户在各个月份上的活跃记录,绿色表单则显示用户的不活跃记录。根据用户在此时间段内可能出现的活跃情形,笔者枚举出3种典型用户,如下表所示:


用户A:该用户在刚进入“分析窗口”时是活跃的,然而在5月变得不活跃(也就是说,5月份是第一个不活跃的月份)。接下来,这个用户的不活跃状态持续到了12月,也就一直持续到了“分析窗口”的末尾。因此,从5月到12月,“用户不活跃档案”对用户连续不活跃的月份进行逐月累加的计数统计。
用户B:跟用户A一样,该用户刚开始也是活跃的。不同的是,该用户在3~6月期间是不活跃的,在7月仅维持了一个月的活跃状态, 接着在8月和9月又进入不活跃状态,最后在“分析窗口”的10月,11月和12月又回到活跃状态。在这种情况下,每当用户由不活跃状态返回活跃状态时,前面的不活跃月份计数需要重置。也就是说,当我们再次对该用户的连续不活跃月份进行计数时,需要重新从1开始计数,前面的不活跃月份计数不再累加。
用户C:与上述提及的两类用户不同,该用户刚进入“分析窗口”时,是不活跃的状态。这种情形的发生,可能是用户的订阅早已过期(最好在正式分析前排除这种情形,因为很难处理),或者该用户在“分析窗口”开始前就是不活跃的。因为我们看不到“分析窗口”前的用户活跃情况,所以用户在此之前的活跃状态,我们是不了解的。鉴于此状况,我们对这些月份进行特殊的标记—使用-1标记用户C头几个不活跃的月份。该用户其他的不活跃情形,可以参照前面两类用户方式进行计数。
Note:后面绿色的表单,也就是“用户不活跃档案”,才是我们接下来建立用户流失模型的数据基础。
3 构建用户流失模型
有了上述的关于用户不活跃的操作性定义,我们就可以在“分析窗口”内(1月份到12月份)以月份为单位,对从0到12的连续不活跃月份数上的用户数量进行计数统计。
这个步骤可以通过数据透视表实现—通过聚合每个月、每个不活跃级别的用户数量。 如下表所示:
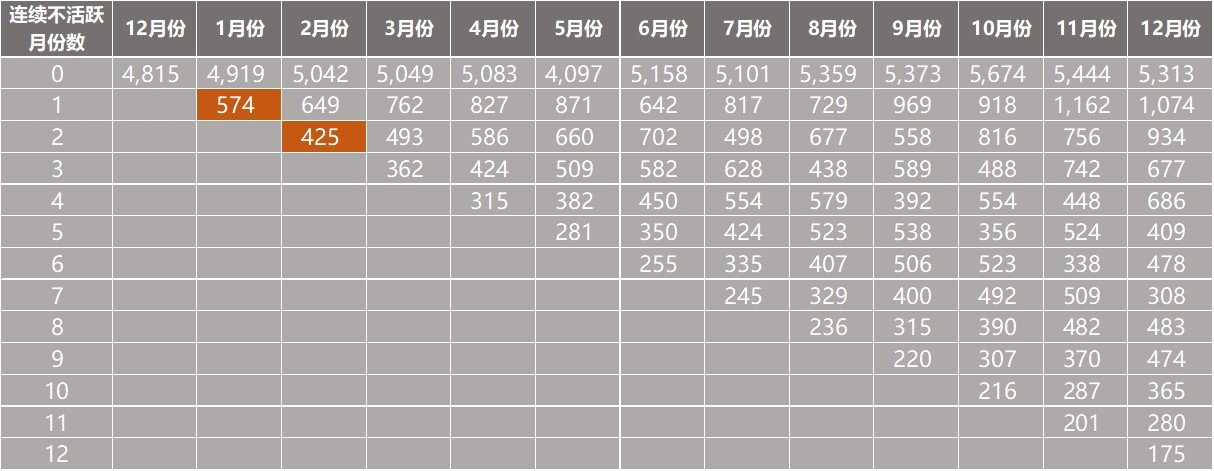
上表中,从列的方向上来看,每个单元格的数值表示每个月的连续不活跃X个月的用户的数量。举个例子来说,上表中第一个高亮数值(574),代表1月份已经不活跃1个月的用户数量,该数值来自于前面12月份的4815个活跃用户。第二个高亮数值(425)表示在2月份已经连续不活跃2个月的用户数量—425来自于574(1月份不活跃1个月的用户数,它是2月份不活跃2个月的用户数的基数)。值得注意的是,第一行的0个连续不活跃月份数,其实表示的是基数中活跃用户的数量。
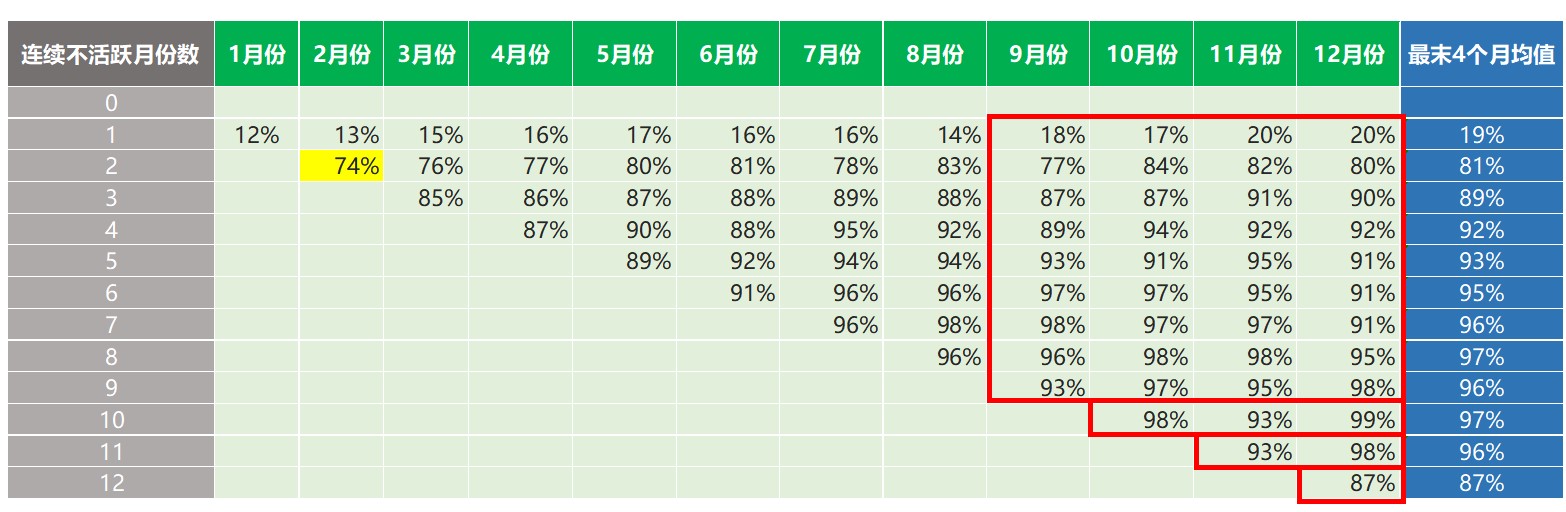
使用这些数据,我们可以计算出在“分析窗口”内,每个月连续不活跃月份数的用户占比情况。如下面的绿色表格所示:

上表中,高亮的数值(74%)表示2月份已经连续2个月不活跃的用户占比。该百分比是这样计算得到的:

笔者想获得最具代表性的数值,由此可以对“分析窗口”的最末4个月(9月,10月,11月和12月)取平均值。我们可能没有足够的数据去计算这些平均值(比如10月份,11月份和12月份)—在这种情况下,我们取所有可用数值的平均值(用于计算平均值的数值区域以红色线框标记):
4 计算用户流失概率
哈哈,如果你还在看这篇文章,那么恭喜你!我们将要探讨最激动人心的部分…在这部分,我们将用上一点统计学的小知识。
让我们回顾一下本文的终极目标—计算各个连续不活跃月份数(0-12)下的用户流失概率。
也就是说,如果某个用户已经连续X个月不活跃,那么这个用户接下来将要流失的可能性有多大?从数学上来说,我们可以使出贝叶斯公式这个大杀器来计算用户流失率。贝叶斯公式尽管是一个数学公式,但它的原理不要数字也能明了。如果,你看到一个人总是做一些好事,则那个人多半会是一个好人。该数学公式包含着朴素的真理:
当你不能准确知悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。
用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。它的数学形式如下:
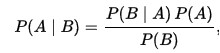
在这里,A和B都代表事件(Event),同时P(B)≠0。P(A)和P(B) 分别代表A和B的先验概率或边缘概率。之所以称为”先验”是因为它不考虑任何A(B)方面的因素。P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
在本案例中,对应的公式如下所示:
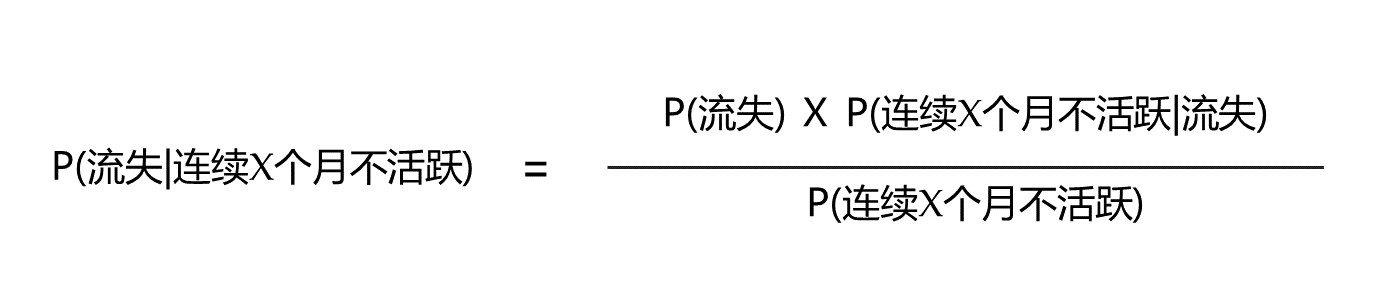
然并卵,上面公式里有一项是没啥意义的—P(连续X个月不活跃|流失),它的含义是“在已经流失的情况下,连续X个月不活跃的概率“。试想一下,假如你已经流失掉了,你不可能是一个不活跃的状态,这个概率值是么有啥业务意义的。鉴于此种情形,笔者果断抛弃这一项(谨记!)。由此,我们得到了一个终极版的流失率计算公式:
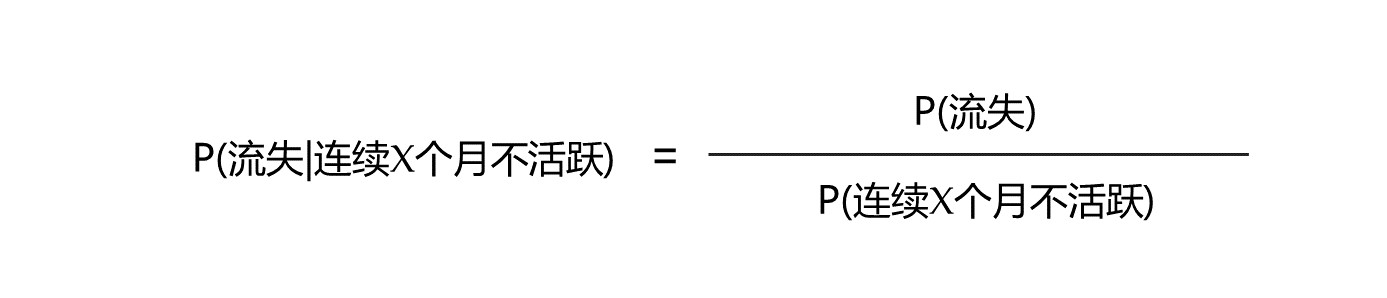
接下来,让我们看看公式右端的两项(分子和分母),然后计算它们在每个不活跃月份上的数值,进而得到我们想要的用户流失概率值(注意,它是一个条件概率值,也就是在连续不活跃X个月的情况下的用户流失概率)。
先说说分母P(连续X个月不活跃),笔者之前已经计算过它们—也就是“分析窗口”最后4个月占比平均值:
P(1) = 19%
P(2) = 81%
P(3) = 89%
P(4) = 92%
P(5) = 93%
P(6) = 95%
P(7) = 96%
P(8) = 97%
…
接下来,我们再来通过例子求解分子P(流失)。首先,1个月不活跃的用户的流失概率P(C1)是多少呢?对于这些将要流失的用户,他们将要连续性的不活跃的月份数已经在我们所考虑的集合之内了,换言之,这些用户将要不活跃的月份数为1个月,2个月,3个月,…,。因而,我们这样定义已经不活跃1个月的用户的流失概率P(C1):

现在, 以同样的方式, 持续2个月不活跃的用户的 P(流失) ,也就是P(C2)是多少呢?对于这些将要流失的用户,他们将要持续性的不活跃,2个月,3个月,4个月,…,12个月。因而,我们这样定义已经连续不活跃2个月的用户的流失概率P(C2):
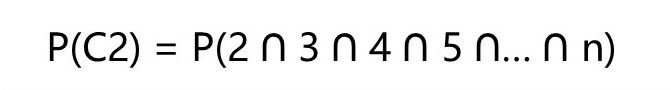
通过归纳和演绎,我们以同样的方式来计算每个不活跃月份的用户流失概率:

在这里,n是连续不活跃月份数的极限值,而我们发现,这个概率是稳定的。从上面的表单里可以到,这个发生在第7个连续的月份,这里的概率值维持在95~96%。
简化起见,我们假设,在连续月份上不活跃是相互独立的事件。此时, P(A ∩ B )= P(A)* P(B)。因而,我们可以采用如下的公式:

现在,我们已经算出了每个不活跃月份概率对应的分子和分母,那我们就可以启动最后一步—算出每个各个连续不活跃月份数的用户流失概率。先前我们已经讨论过了,n的值为7。
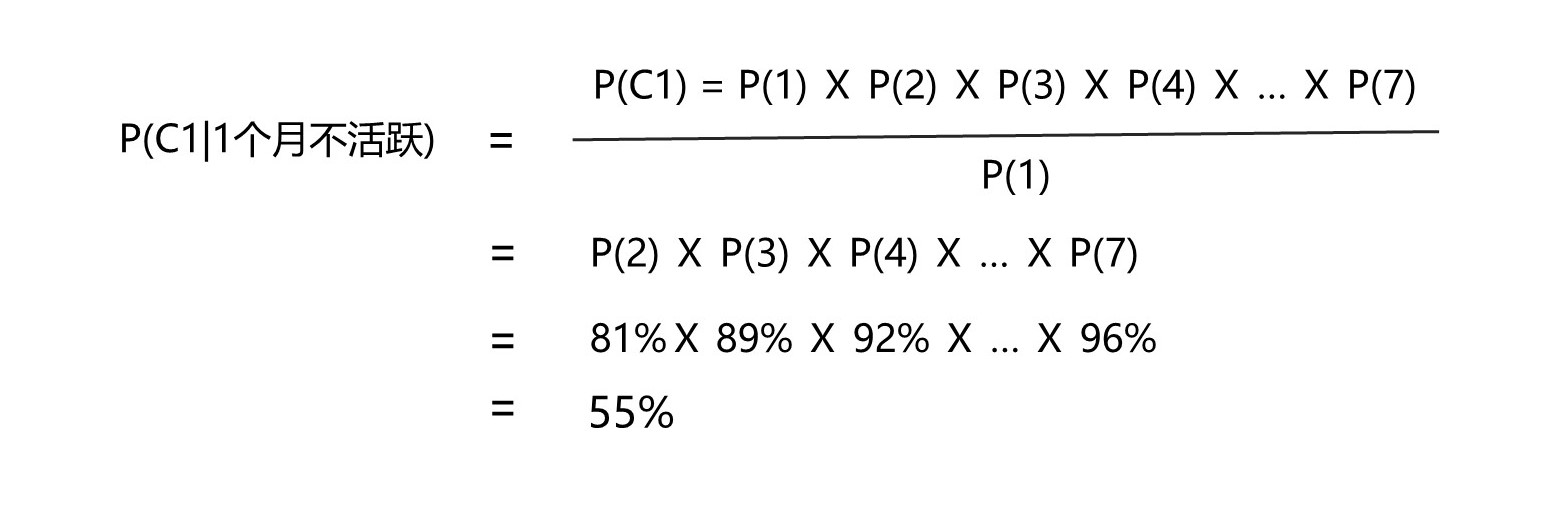
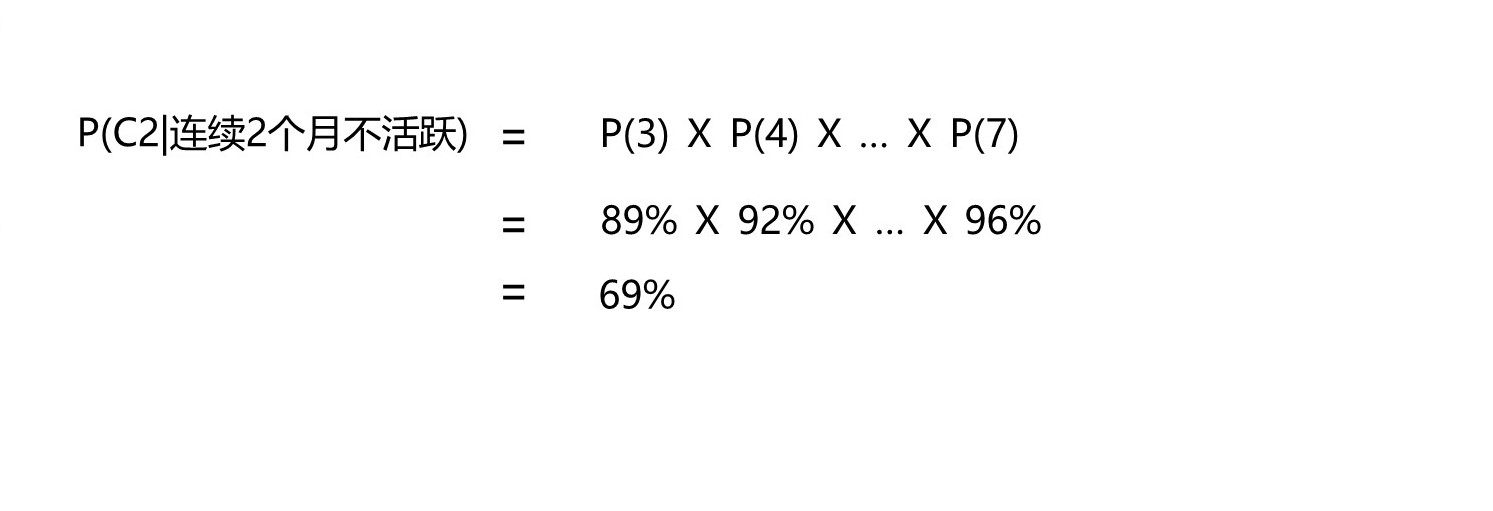

…
最终的计算结果如下表所示:
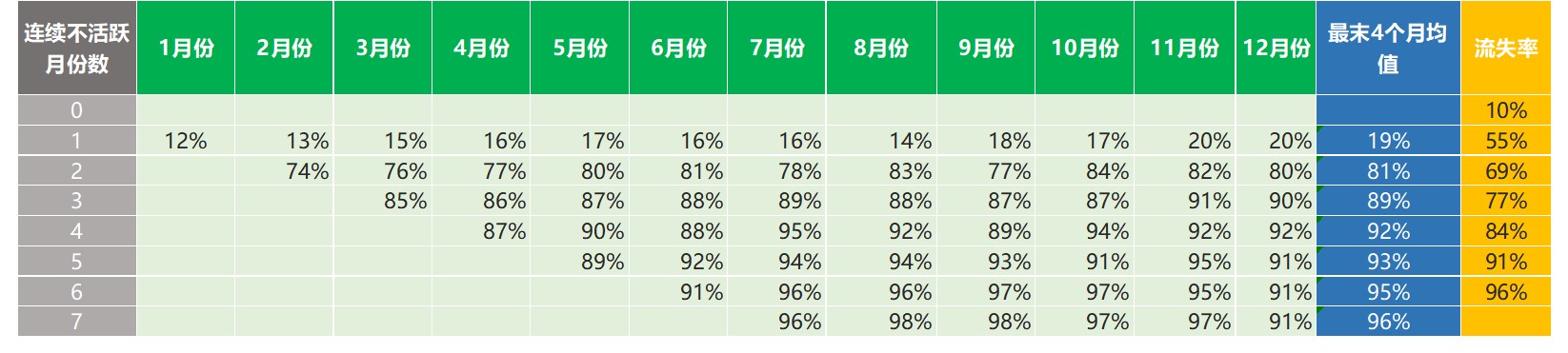
请注意,活跃用户(也就是第一行连续0个月不活跃的情形)的流失率由P(1) Ⅹ P(2) Ⅹ P(3) Ⅹ P(4) Ⅹ … Ⅹ P(7)计算得出。这里我们并没有除以任何值,这是因为—当用户处于活跃状态时, P(连续0个月不活跃)为1。
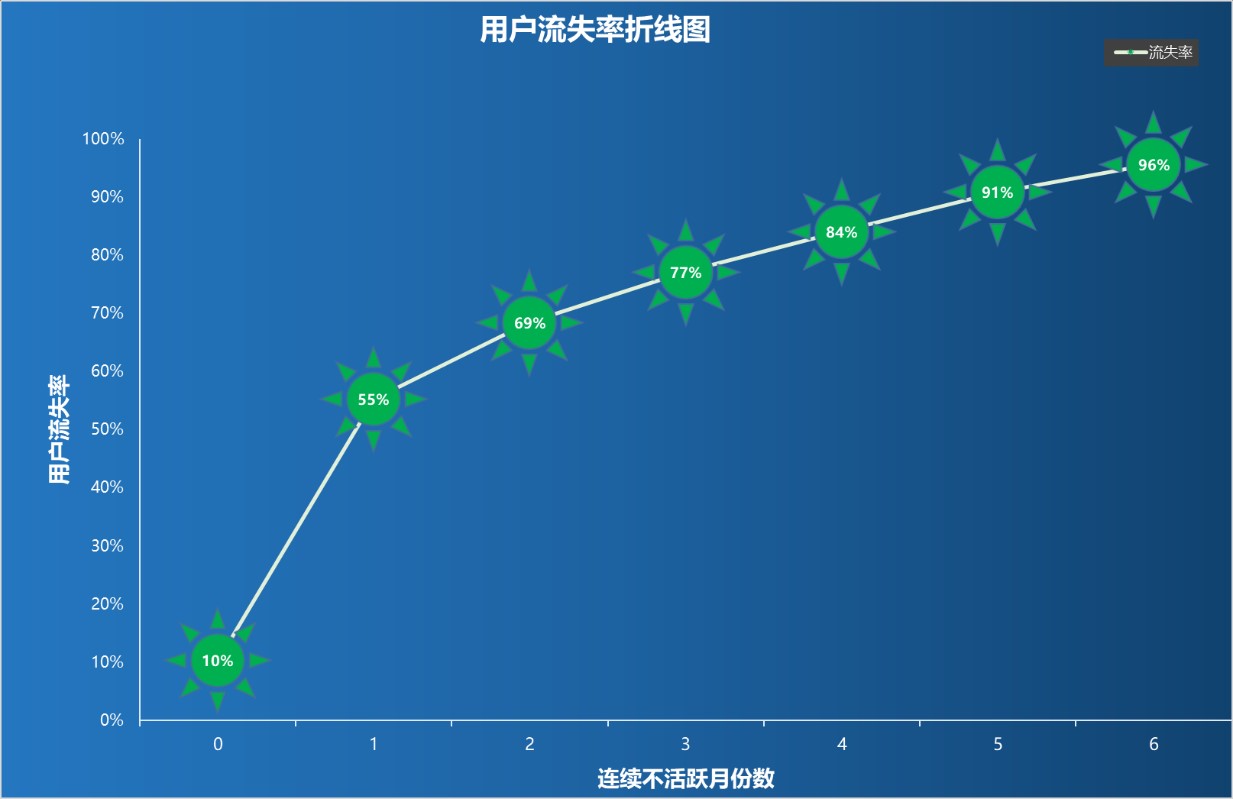
最后,我们还可用一条流失率曲线来直观的反映流失率的变化情况,由此决定对非活跃用户进行挽留操作的最佳时机,该曲线所下图所示:
5 结语
在本文中,笔者并没有提供该模型批量化使用的具体执行细节,假如你理解了这个模型构建的逻辑,那么你可以使用SQL、Python,甚至是Excel来实现它。
此外,在实践中,这个模型最好是分不同的用户群进行运行。在本文中,笔者仅仅在某一类用户上运行,然而,根据不同的标准来划分用户群体会对实际业务更有意义。比如,你可以根据用户价值进行划分,然后对每个用户子群体进行用户流失预测。
当然,笔者只是在月份的尺度上进行用户流失分析,但是,对于很多业务场景,更细粒度的分析视角可能更有意义,比如按周和按天。
最后,以《神雕侠侣》中的一段话作结,我想,感悟到数学之美、不受分析工具的限制,并能灵活运用到实际业务中的感受大抵如此:
过了良久,青衣人又将巨剑放下,去取第三柄剑,那却是一柄木剑,落在手中轻若无物,但见剑下的石刻道:
“四十岁后,不滞于物,草木竹石均可为剑。自此精修,渐进于无剑胜有剑之境!”
参考资料:
3.PredictingChurn without Machine Learning
#专栏作家#
苏格兰折耳喵,微信公众号:Social Listening与文本挖掘,人人都是产品经理专栏作家。数据PM一只,擅长数据分析和可视化表达,热衷于用数据发现洞察,指导实践。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









“在这里,n是连续不活跃月份数的极限值,而我们发现,这个概率是稳定的。从上面的表单里可以到,这个发生在第7个连续的月份,这里的概率值维持在95~96%。”看不懂 为何要取7 概率稳定就取7?如果取的是 最末三个月的呢?还是根据“稳定”来取 n?
最末四个月的均值(即P(1)=19%,P(2)=81%,……..),应该已经是条件概率了吧?19%是“上个月活跃的用户中,第二个月未活跃的占比”,81%是“上个月连续一个月未活跃的用户中,第二个月连续两个月未活跃的占比”。并不是文中说的“连续X个月未活跃”的概率。
道理同
在这里,n是连续不活跃月份数的极限值,而我们发现,这个概率是稳定的。从上面的表单里可以到,这个发生在第7个连续的月份,这里的概率值维持在95~96%。
这句没看懂…
感谢分享
有几点我觉得可以一起讨论
1、这个算法在工程上的实现,貌似比机器学习还要复杂。在MODELER里用决策树进行实现,也只需要完成文章所述第一步的数据准备,也就是用户行为统计这一步,就可以使用决策树算法进行建模了
2、使用决策树的方法,其实跟上述的原理类似,机器学习本身也是基于统计的。不同的点在于,本文只能说明用户连续N个月不活跃而流失的概率,而决策树可以把“不活跃”这一特征拆开了揉碎了来告诉我们客户流失的概率
机器学习不是每个人都会的,学习成本很高。我介绍的方式的主要目的在于重拾以前学的数学知识,灵活运用到工作场景中,可操作性强。
“笔者想获得最具代表性的数值,由此可以对“分析窗口”的最末4个月(9月,10月,11月和12月)取平均值。”这里不太明白,为什么要这么取呢?
取用户占比的均值,最末四个月在纵轴上的覆盖长度最长,对它们取均值具有代表性
请问,“最末四个月在纵轴上的覆盖长度最长”这个覆盖长度具体指什么呢?
“连续不活跃月份数”,你试着从纵轴方向上来看
后面的公示 我是看服了
学习了