
 起点课堂会员权益
起点课堂会员权益数据分析(2):数据分析的方法论

本文大概梳理了统计数据分析的三种方法论,即描述性数据分析、数理统计分析和数据挖掘分析。enjoy~
我们说数据分析要有目的进行分析,实际上我们在平常的工作中,没有学过数据分析也能靠直觉推断出一些数据产生的原因。那么为什么还要进行数据分析的学习呢?也就是说,数据分析,到底在学什么?
其实我认为如果是在初创团队中,确实无需使用太专业的数据分析方法,因为往往数据不足。但是,如果你掌握了数据分析的方法,就能够在产品的初期设计合理的埋点,要知道现在很多产品在早期是没有这个意识的,于是等产品成熟了再去做这件事是极其痛苦的。所以也才催生了类如诸葛IO这样的“无埋点”数据分析的产品。“无埋点”只能收集到很浅层次的数据,如点击数据,IP/PV等,业务层面就无法统计。而且存在着不稳定性,从技术上讲就是说如果用户使用了一些奇奇怪怪的浏览器(例如低版本的IE)的话,很可能无埋点的代码就无法运行,造成原始数据的偏差。说了这么多,回到话题,学习数据分析,我们能够:
- 培养数据意识,提升产品规划能力。
- 培养数据敏感性,提高洞察力。
- 能够数据中发现不容易通过直觉发现的足丝马迹,发现潜在的可能。
- 掌握一门通用的硬技能,辅助需求挖掘、业务分析。
- 等等
接下来我们进入正题:数据分析的方法论。
一般来说数据分析可以从两个学科出发,一个是数理统计学,另一个是营销理论。本文将主要从数理统计学着手介绍,因为营销理论(就是我们常见的5w2h,PEST分析等等方法论)的掌握,更多是思维框架的掌握,而真正能够通晓营销理论的,需要大量的经验积累。而数理统计学是工具,可以手到擒来,马上就用的。
上篇文章讲到,数据分析大致可以分为描述性分析、诊断性分析、预测性分析,同样的数据分析的方法论也大致分为:描述性数据分析、数理统计分析、数据挖掘分析。
本篇文章将就此展开谈谈这三种数据分析方法论(方法论没有好坏高低之分,只有合适的。根据业务场景来选择合适的分析方法。一定要以目标为导向,并不是手法越高级就越好。能用简单分析的就不需要使用大数据挖掘。)
一、描述性数据分析方法
描述性数据分析可以用一言蔽之”一句话描述数据“。我们平时说的,这个月的平均访问量是多少,环比增长了多少。用户平均付费是多少,中位数是多少,众位数是多少,四分位数是多少都属于描述性统计分析。描述数据的集中趋势还可以用方差、标准差。用一个指标,一句话概括数据特点。描述数据之间的简单关系可以用相关性分析,如转化率和用户停留时间的正相关的(距离,以实际为准。一般也是这样。)这边大家都比较熟悉,不过多介绍。
二、数理统计分析方法
数理统计涉及较多的数学知识,但是其实常用的也就是概率论和微积分,本科的知识稍微复习一下还是容易掌握的。微积分只需要用到一元积分,用于计算概率分布。统计学中有许许多多的内容,在数据分析中,并不是所有都需要掌握。因为我们不是在做实验室里科学实验的数据分析。
1. 方差分析
方差分析,又称为F检验。作用是研究因素对于数值型变量的影响。例如想要知道某次改版对于转化率是否有显著影响,可能从宏观上看增长的数值不大,看不大出来影响有多大,这时候就可以用方差分析做对于改版这个因素的单因素方差分析。
2. 回归分析
回归分析比较好理解,简单的说就是寻找到一个函数来拟合自变量和因变量的关系。例如想要做一次活动,假设优惠的价格x,销售额为y。这两者之间可能存在y=x+1(纯举例)这样的函数关系式。回归分析就是要找出这样的函数关系,来指导活动的运营,提升ROI。
3. 因子分析
因子分析即从大量的变量中寻找共性因子的统计方法,因子表现为一种表征,通常是多个变量的集合。因子分析可以简化数据,所以是一种降维的方式。常用的因子分析方法有重心法、最小平方法、最大似然法等。
三、数据挖掘分析方法
数据挖掘源于统计机器学习,还有人工智能的方法。之前写过的人工智能相关的文章中有提到,AI=数据+算法=模型。数据挖掘也就是利用算法从数据中寻找规律。因为我们并不能总是能用常见的函数去拟合所有的规律,而太复杂的规律通过人工根本就是无法进行计算的。那么机器学习就可以做到。机器学习的原理其实就是定义一个损失函数,可以把损失函数简单理解为错误率。然后枚举所有的情况,找到错误率最低的模型。用在数据挖掘中,我们可以用到的机器学习算法一般有:
1. 聚类分析
俗话说,物以类聚。聚类分析是一种探索性的分析方法,由机器无监督地将样本数据进行分类,再观察其特征,从而帮助发现潜在的共性。聚类分析的方式也有很多,用不同方式进行的聚类分析结果也不尽相同。
2. 分类
分类应该是机器学习、人工智能中应用最广泛的了。例如NLP中的情感分析、文章分类,CV中的医疗影像诊断,物品识别等等。又扯远了,回到数据分析,常用于数据挖掘的分类算法有:
(1)决策树
决策树直观上的理解就是从样本建立分支规则。举个简单的例子,同事A有时候迟到有时候不迟到,你观察到如果下雨了。A就迟到。如果没有下雨,A就不迟到。主管只有在周一和周三在,如果主管在A就要挨骂了。那么用决策树来预测A是否会挨骂(以上例子纯属YY)就是:
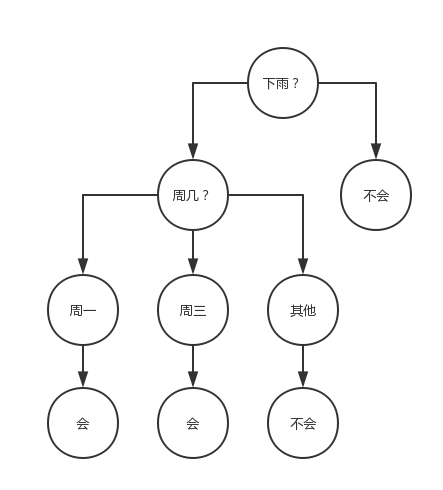
能够构造这样的决策数据的常用算法有C4.5、CART、CHAID、ID3等。
决策时擅长处理离散数据,并可以直观出其中的关键变量。决策树生成的规则也容易被人所理解。接下去要讲的神经网络就不是人可以理解的了。
(2)人工神经网络
人工神经网络是个黑箱模型,神经网络是类似于大脑神经突触连接的形式,仅仅是类似,不能把它理解得过于玄乎,本质上和脑神经的运作方式是相差很大的。人工神经网络包括输入层、输出层、隐藏层。其中隐藏层就是就是对输入层的输入进行各种加权互联,最终得出最逼近训练集的结果。理论上可以逼近任何非线性的关系。能够充分考虑到数据的各种特征。
(3)贝叶斯分类器
是否还记得贝叶斯公式
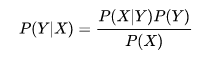
只要知道P(Y)、P(X)、P(X|Y)就能知道P(Y|X)的值了。前3个值可以通过历史数据得到先验概率,在先验概率的基础上就能对新的事件(数据)进行后验概率的计算。
(4)支持向量机
SVM,是机器学习的重大成果。SVM将非线性的数据将数据映射到一个高维空间,在新的维度上,搜索一个线性最佳超平面,两类数据总是能够被超平面分开。
(5)随机森林
随机森林有着较高的准确率,鲁棒性也好。随机森林运用bootstrap方法从原始样本中抽取样本,对每个样本进行决策树建模,然后将决策树组合,对每个决策树分类出来的结果进行一种投票统计,最终得出分类结果。这个方式很形象的被叫做随机森林。
3. 关联规则
举个例子就能明白什么是关联规则了。大家都知道的“啤酒与尿布”的例子,关联规则算法能够找出多次重复、同时出现的关系。
4. 回归分析
描述性分析中也有回归分析,这边回归和描述性分析中回归的区别主要是,这里指的是多元线性回归和逻辑斯蒂回归。典型的回归问题是运费计算的问题, 快递运费受地区、重量、物品类型、运送方式等多种因素的影响,这时候可以使用多元线性回归来分析他们之间的关系。
本次的分享就到这里,本文大概梳理了统计数据分析的方法论,接下去的系列文章将会逐个对各种方式进行介绍。
相关阅读
#专栏作家#
跹尘,人人都是产品经理专栏作家。人工智能产品经理,独立音乐人,擅长需求分析、原型设计和项目管理。喜欢阅读、思考、创作。网易云音乐主页:跹尘。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议











后续对方法论的详细介绍呢??
聚类和分类有什么区别?
分类是监督类模型,初始样本是有标签的;聚类是无监督模型,初始样本是无标签的。
这个分析用在运营上好使吗?
AI=数据+模型+算法 ?
不是。AI=数据+算法=模型。概括的描述。非官方非标准定义。