
 起点课堂会员权益
起点课堂会员权益数据仓库学习笔记:修炼数据产品经理

好的数据仓库的建立能够适应业务的多变,并且能够为企业提供坚实的数据基础以辅助业务决策。
随着企业业务的发展,企业自身的业务系统及其中所存储的数据会变的越来越多,同时业务及运营人员对于日常的指标及数据分析需求也会越来越明显。
这时为了企业能够拥有更好的数据基础来支撑常规的BI系统以便辅助业务决策,一些企业会选择建立企业级的数据仓储系统对公司全部或部分的数据进行统一存储及管理。
一、数据仓库系统与操作型系统的区别
传统操作性系统更注重对实际业务的处理(如电商交易系统),一般采用传统关系型数据库对数据进行存储(如mysql)。数据仓库系统更偏向于复杂的分析操作,侧重决策支持,一般采用多维数据库对数据进行存储和管理,又称OLAP(联机分析处理)。
二、数据仓库的特点
1、数据仓库是面向主题的
操作型数据库的数据组织是面向独立事务的处理任务,各个业务系统之间是分隔独立的。而数据仓库的数据是面向主题的,通过一个个主题域将多个业务系统的数据加载到一起。
2、数据仓库是集成的
数据仓库系统需要将多处的数据源通过一定的规则进行抽取和清洗,并最终加载到数据仓库中。过程中必须消除数据的不一致性。
3、数据仓库的数据是相对稳定的
操作型数据库事实上并不过于注重历史数据,但数据仓库的数据是为企业数据分析而建立,所以数据被加载后一般情况下将被长期保留。
4、数据仓库更注重读
数据仓库中的数据一般仅执行查询操作,很少会有删除和更新。需定期加载和刷新数据。
5、持续的项目
数据仓库并不会像一个独立项目一样的由始至终完结,它从开始建立起就需要不断的维护。很多企业会选择先面向某个主题建立数据集市,在通过一个个数据集市组成完整的数据仓库。
三、数据仓库的多维数据建模
对于现实世界中的某个事务其实完全可以抽象成维度和事实。
例如“小明今天在商场吃了一顿饭”
维度可抽象为:“时间维 => 今天” ,“地点维=>商场”,“产品维 => 饭” ,“用户维 => 小明”。
事实量度:一顿
实际粒度:天、商业综合体
数据仓库的建模方法有很多,当前所知较为主流的建模方式有两种,分别为kimball和immon。前者更敏捷,是站在业务分析者的角度以最快的方式满足分析者的分析需求。后者更系统,是站在公司的角度在面向各个主题进行建模,并满足第三范式。
不过现在更多采用的是前者,并且在学习数据仓库的这本书也是同样推荐使用Kimball进行建模。因为相对于目前互联网公司的唯快不破,Immon的周期会拉的很长,同时需要建模人员全面了解公司的业务场景。
kimball建模开始维度建模前需先要了解业务场景并挖掘业务需求,同时考虑自身数据源的实际情况。
4步骤维度设计过程
1、选择业务过程
该阶段需要建模人员深入到实际业务流程当中,从中建立性能度量,并转化为事实表中的事实。一旦事实表被建立,则对应的粒度及维度也会相对定义。所以这一步骤还是比较重要的。
2、声明粒度
粒度声明是维度设计的重要步骤,通常选用最低级别的原子粒度,因为原子粒度能够承受无法预期的用户查询。
3、确认维度
因为维度可以描述事实的属性,维度表有时会被称为数据仓库的灵魂。它是数据仓库系统能够被用作业务分析的入口和描述性标识。
4、确认事实
事实表为实际业务过程中的度量,大部分以数值表示。一个事实表对应一个现实中的某项事务。
kimball的三种建模模式
1、星型模型
星型模型是面向主题的常用模式,主要由一个事实表及多个维表构成,不存在二级维表。

2、雪花模型
雪花模型是在星型模型基础上将维表再次扩展,好处是耦合性低,冗余小。缺点是需要跨多表查询时性能低。
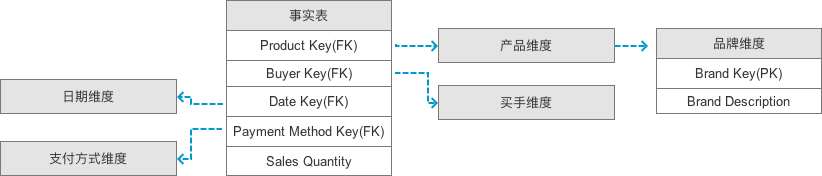
3、星座模型
星座模型其时是星型模型的集合,存在多个事实表且可共用同一个维表。

一般在面向数据集市主题建模的时候会采用星型模型,如果是企业级数据仓库的建立则采用星座模式较多。数据建模的的根本目的是避免冗余,尽可能提升查询性能,建模方式没有最好只有最优。
kimball结构图
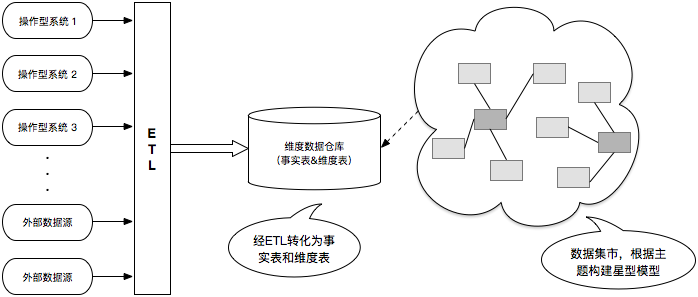
四、ETL数据处理
ETL的工作将贯穿于整个数据仓库的建立过程。ETL是对数据的抽取、转换、加载的简称。它是指将关系型数据库中的数据抽取出来,并将不同数据源的数据按规则进行转化和整合,最终加载到数据仓库中。
在这一系列的操作中将会对元数据的数据格式,拼写错误,多余字段等进行处理,使数据达到允许加载到数据仓库的标准。
五、数据仓库与BI系统
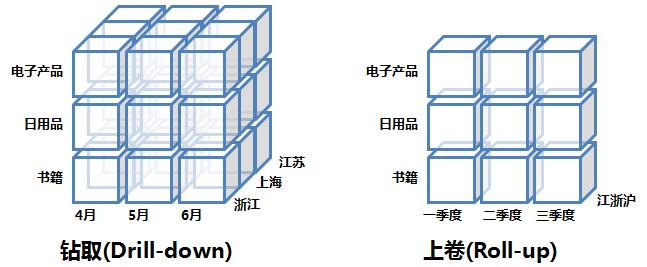
当我们的数据仓库通过以上的流程建立好之后,则在应用层一般会选择采购或自建BI系统。一般的BI系统均会支持对数据立方进行上卷、下钻、切片、切块等操作,强大的BI系统会同时具有基础的ETL及SQL编写的功能。另外简洁的操作流程和直观的图形报表也是BI系统必不可少的。
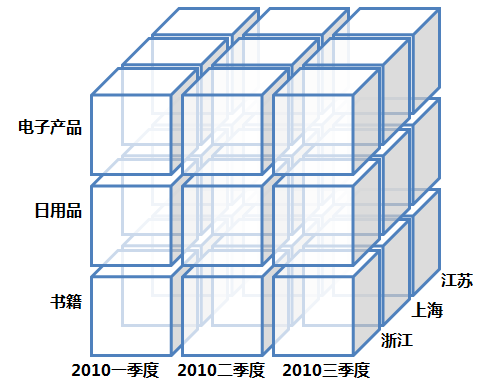
数据立方
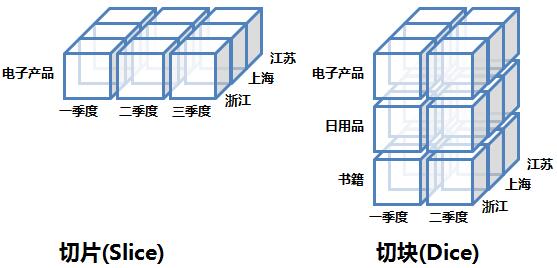
在日常分析者对数据进行透视等分析操作时,往往需要同时多维度的数据分析。数据立方实际上就是对于多维数据分析的一种立体表达。将每个维度作为一个立方体的一个轴,一个立方体最多只能承载三个维度,但实际分析过程中可能有多个维。然后我们可以对数据立方进行上卷、下钻、切片、切块、旋转等操作。
切片、切块
上卷、下钻操作
大数据的应用越来越广泛,无论是AI还是传统的BI都需要数据的支撑。好的数据仓库的建立能够适应业务的多变,并且能够为企业提供坚实的数据基础以辅助业务决策。以上为近期个人对数据仓库及建模相关技术的学习和理解,若存在理解错的地方还望大神们指正。
感谢浏览!
本文由 @宗瀚zone 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Pixabay,基于CC0协议









大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!
怎么一年没写文章了
请问下产品经理在数仓搭建中的角色是什么,主要的工作是什么,因为感觉大部分都是工程师的活呀
了解工作原理
怎么一年没写文章了?
学习了,但是这里kimball的结构感觉表述的不够清晰,自己又去找了下inmom和kimball的比对文章,感觉https://segmentfault.com/a/1190000006255954这里的比对图感觉会更好一些
受教了!感谢大神!
文中的immon是不是错了,inmon?
什么阶段的企业适合做数据仓库 💡
个人感觉主要看上游的数据应用情况。
博主,你提到的书,书名是什么呢?
“在学习数据仓库的这本书也是同样推荐使用Kimball进行建模。”
叫《数据仓库工具箱》
环球黑卡听起来很牛逼
😯