
 起点课堂会员权益
起点课堂会员权益两个步骤,解析滴滴如何为你找到司机的
文章对派单策略的思考、叙述围绕一两个特定角度展开。而出行场景业务复杂,针对特定问题制定对策,很多时候只能是脚痛医脚头痛医脚;解决系统性的问题,人工智能、机器学习方法可能会更加高效。

抽象、简化问题的能力比解决问题的方法更重要,几乎很少有问题是人类星球首次出现的,绝大多数问题总能在前人的经历、总结中找到相似解。但是在按图索骥之前,你必须得知道这是个什么问题;如若不然,千百次的擦肩而过也换不来一次回眸一笑。
这就是最近我在思考如何提高司乘匹配效率问题时一些感触。
当你觉得在自己所在领域遇到特别棘手的问题时,说不定在千百年前,在另外一个跟当前相似场景的行业里,也遇到过类似的问题,而且已经有高人给出了不止一种解。
所以遇到问题,不要一上来就想要靠自己的能力做个翻天覆地的创新。先搞清问题是什么,再想想有没有现成的方法,或者其他行业学科有没有类似的场景。去研究别人是怎么做的,把别人的方法理解透彻后,再来结合自己的业务,进行异域迁移或者拆解重构。
出行行业对司乘匹配效率的追求永无止境,每一位乘客都希望以最快的速度叫到车,让司机能在最短的时间到达自己面前;而对于司机,高效的匹配能提高司机的人效,赚到更多收入。
司乘匹配一般来说,分为两步完成:第一步是为乘客找到合适的司机,第二步是将订单指派给系统认为最优的司机。
第一步
为乘客找到合适的司机本质是一个搜索问题。既然是搜索问题,我们可以枚举多个成熟的案例:传统的图书馆找书,Google、百度搜索引擎,地图的搜索。
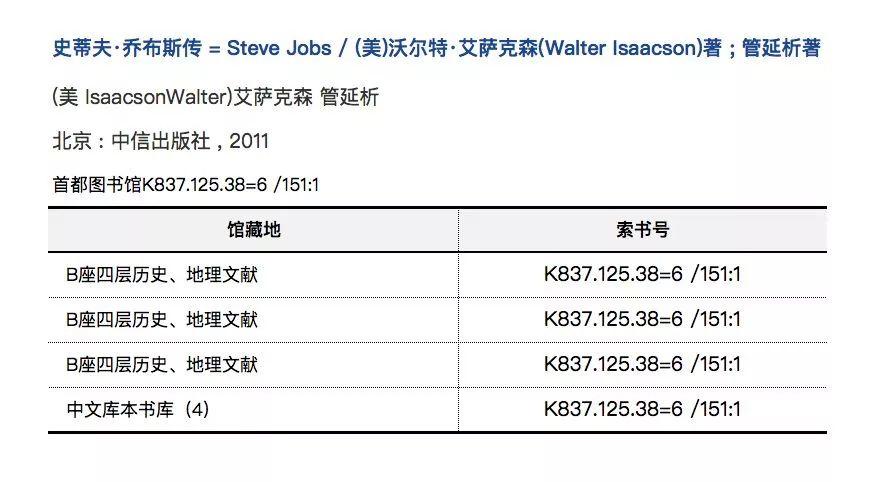
图书馆找书,大家应该都很熟悉:我们在大学校园图书馆见到的书,书脊上都贴有一个标签,标签上印刷的是该书的索书号,索书号上有该书的分类信息代码。
一般图书馆都有多层,每一层又有多个书架,书架又分多层。而书架的管理跟索书号类似——书架本身的位置可以用楼层、区域来锁定,而每一个书架上又都定义了存放图书类别,并贴有该类图书的分类大号。
例如:要去首都图书馆借阅《史蒂夫·乔布斯传》这本书,我们先去检索系统里查找有没有这本书。检索结果告诉我们,这本书存放在B座四层历史、地理文献去(K837)。这样就能很容易找到这本书。
当然,我们借阅完成,将书还回图书馆,管理员再将书放回对应的书架位置,也是按照这种方法进行的。
如果图书馆没有这一套图书管理方法,而是将成千上万册数随意堆放在馆内,那么要找到特定的一本书,就只有一本一本去找,直到发现你想要的那本书为止——运气好可能第10本就是,运气不好可能第100万本才是。
出行行业司乘匹配,就像图书馆读者找书和管理员将退还的书放回书架一样。
最容易想到的办法是:我们预先设定一个派单范围,用户叫车,平台先根据用户的上车位置,计算筛选出全城所有司机中;再以用户上车位置为中心,以派单范围为半径的圆形区域范围内的司机,然后选择距离最近的司机,将订单指派给该司机。
这种策略下,每一次呼叫系统都会去计算全城司机的位置距离,对于司机数量不大的小公司,这种策略还勉强凑合;但是像Uber、滴滴这类在一个城市拥有几十万司机的独角兽,每一次呼叫系统需要计算几十万司机的位置距离,这种策略就不现实了。
要提高司机之间匹配效率,快速找到合适的司机,我们可以借鉴图书馆图书管理的办法;与图书馆管理图书不同的是:书是固定不动的,而车辆是可移动的。
首先将地图划分成更小的固定区域,并对这些区域进行标记。对于落在这些区域的司机或乘客,向服务器上报位置数据时,都附带该区域的标记。
这样就把找到合适司机分解成两步完成:先根据乘客所在位置区域标记,去搜索数据库有相同标记(或附近区域)的司机,然后再去计算这些司机距离乘客上车点的位置。
这样就把全程搜索变成了在一个更小,更精准的区域进行搜索,降低了算法时间复杂度,提高了匹配效率。
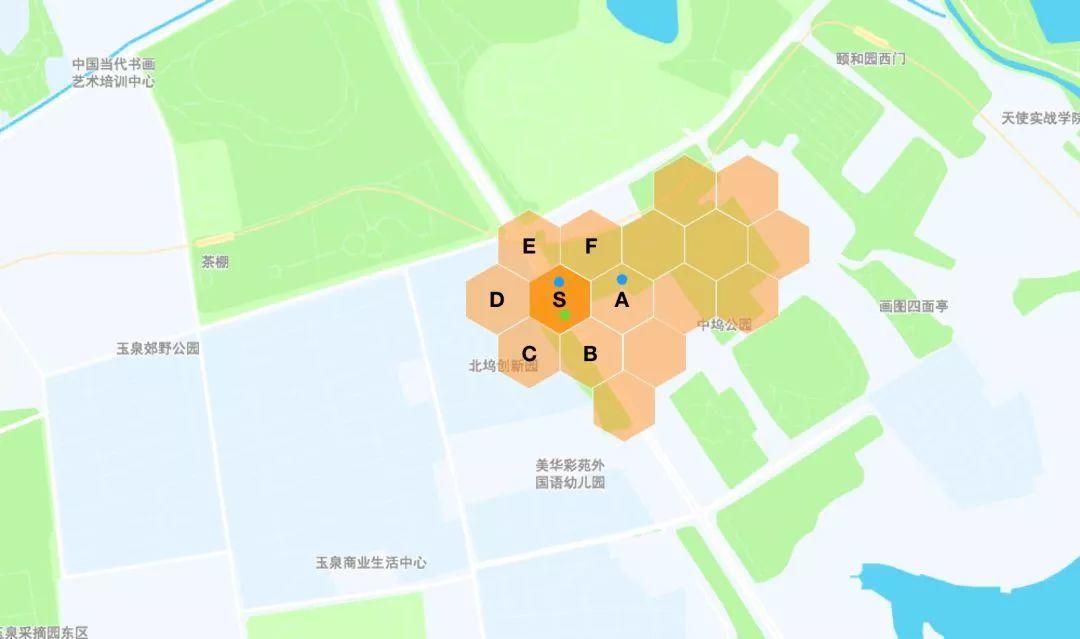
例如,图中将地图划分成了若干蜂窝状区域,并对区域进行了编号:S、A、B、C、D、E、F,绿色点为乘客呼叫位置,蓝色点为可派单范围司机。
乘客呼叫时,系统已经知道乘客在S区,这时系统只需要去检索当前在S区的司机,或S区临近的其他区域司机。就能得到当前乘客附近的可服务司机信息。
以上思考模型中,关键在于如何将地图划分成更小的区域。将地图进行区域划分,其实就是增加地图索引的过程,就像是将图书馆内分为历史、地理区、经管区一样。
但是,地图上的点是通过精度和维度来定义的,是二维的。如果每次通过经度纬度其中之一来进行检索,那么检索完一次,还得进行二次检索;如果是多维空间,就需要就那些多次检索。
这就涉及多维空间点索引算法机制,关于这方面的算法应用最广的是Google S2算法。
Google S2算法是将地图划分成正方形网格,网格的大小可根据实际业务情况进行设置,一共分30级,最小0级可将网格划分为0.48cm^2,最大为30级,将地球划分为6个网格,每个网格是地球面积的六分之一。
Uber 在一次公开分享上,提到了他们用的是六边形的网格,把城市划分为很多六边形;而国内滴滴也是划分为六边形,目前划分成六边形是最优也是最复杂的方法。
关于算法不是本文的重点,有兴趣的同学可以到Google官网去查阅有关S2算法的资料。
这篇文章只介绍了司乘匹配中,如何根据预先设定的派单范围,高效地找到符合条件的司机,算是完成了第一步。
第二步
对于乘客而言,希望平台将距离自己最近的空闲司机指派给我,司机越快到达上车点,乘客的满意度越高。
对于司机也是一样,接客距离越近,空驶里程就越少,节约成本,提升运营效率。
那么对于平台来说,是不是把距离最近的乘客、司机进行匹配,就是最合理的呢?
我们先从一个有针对性的场景入手:
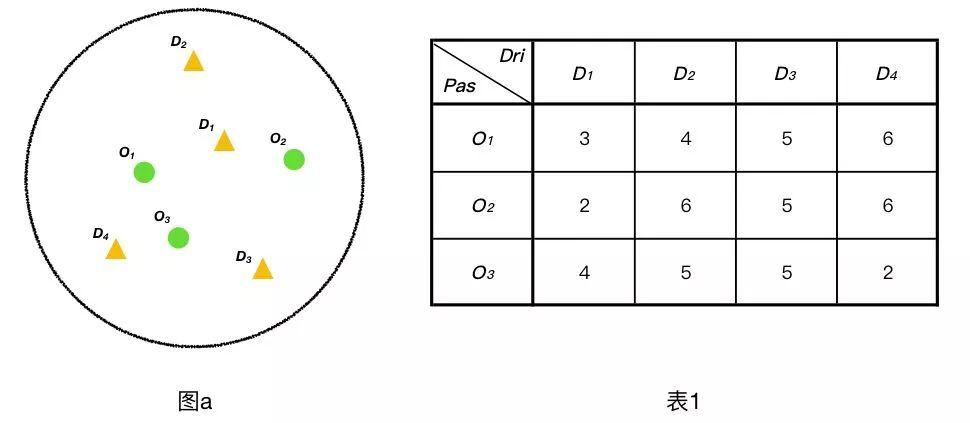
如下图a,假设在某可派单区域内,同时有O1、O2、O3三名乘客同时开始呼叫,此时在该区域内正好有四名司D1、D2、D3、D3。
在考虑实时路况下,表1给出了每一位司机到达乘客上车点所需要的时间,系统该如何进行一一匹配呢?
在回答上面的问题之前,我们需要弄明白一个前提:司乘匹配策略背后希望达到得目的是什么?
不同的场景和业务,可能会有不同的目的,有的可能以平台收益为核心,有的可能是为了优先满足核心用户利益,本文讨论的前提是建立在平台运营效率最大化基础上的。
现在再来考虑文章开头提出如何匹配的问题:从平台运营效率最大化的角度,是希望能找到运营效率最高的司乘匹配关系。
运营效率是一个不好直接量化的指标,通过拆解后,其中最关键的可衡量指标就是接客时长:平均接客时长越短,司机资源利用效率就越高,为平台创造价值越大。
为了让接客时长最短,我们最容易想到的是只要依次保证每位乘客匹配给耗时最短到达上车点的司机,就能保证总的耗时最短。
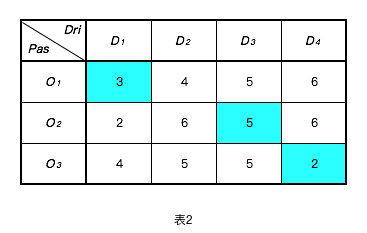
如下图表2所示,依次按照O1、O2、O3顺序去寻找耗时最短的司机,将会得到如下匹配关系:O1-D1、O2-D3、O3-D4,平均耗时约3.3分钟,总共耗时10分钟。
假设O1、O2、O3乘客呼叫时间相差很小,在不明显增加用户等待时长的情况下,系统可以等待最后一位乘客呼叫后,再来进行组合决策。
如下图3所示,可能得到另外一种组合匹配关系:O1-D2,O2-D1,O3-D4,该种组合决策下,平均耗时约2.7分钟,总共耗时8分钟。
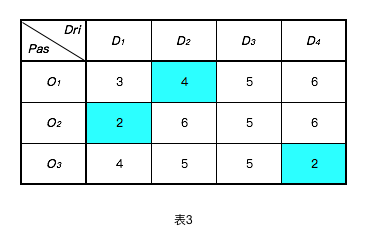
相比前一种组合策略,第二种组合策略总耗时减少了20%。
这里是我们随意列举情况,如果放在Uber、滴滴等日均上千万单的平台,第二种策略将带来极大的效率提升。
到此为止,司乘匹配问题就转化为:在一段时间内(很短,一般几秒),在可派单区域,存在多个乘客呼叫或有多个可服务司机,每一乘客最终只能匹配一位司机,如何实现派单效率最大化(总的接客时长最短)。
解决这个问题有如下几个方法:
1. 贪心算法
通过将所有可能的匹配关系进行一一枚举,计算每种匹配关系的总共耗时,然后再进行排序,最终挑选出接客时长最短的匹配关系。但是这种算法的复杂度是阶乘级别的(若有 m 个乘客呼叫,n 个可服务司机,则算法复杂为 m!· n)。
2. 图论-二分图的最大权值匹配
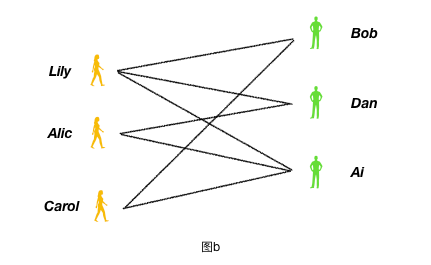
下图 b 是著名的男女配对问题:左侧3名女孩,右侧3名男孩,连线代表他们互相喜欢,如果将互相喜欢的进行两两配对,最多可以配出多少对?
1965年,匈牙利数学家Edmonds利用图论给出了这个问题的数学解法,被称为匈牙利算法。在介绍匈牙利算法之前,先介绍几个概念:
二分图
图论是组合数学一个分支,在图论中,图是由点和这些点的连线所组成的,边在实际业务场景中的衡量值,如时间,距离等,被称之为权。把一个图的顶点划分为两个不相交的点集合,使得每一条边都分别连接这两个集合中的顶点。如果存在这样的划分,则此图为一个二分图(或二部图),如下图 c :
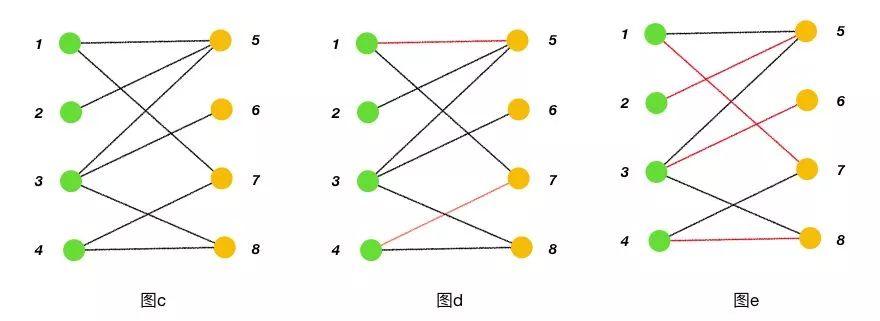
匹配:在图论中,一个匹配是一个边的集合,其中任意两条边都没有公共顶点。例如:图 d、图 e 中红色的边就是图 c 的匹配。构成匹配的边称为匹配边,匹配边上的顶点称为匹配点。
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。图 e 是一个最大匹配,它包含 4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 e 是一个完美匹配。
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边……形成的路径叫交替路,如图f。
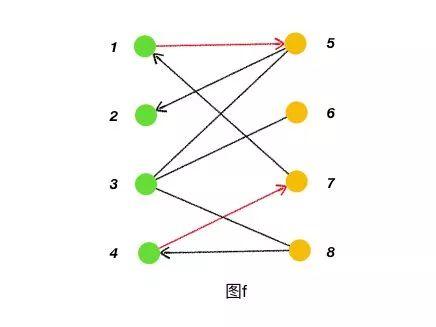
增广路:从一个未匹配点出发,走交替路,如果途经另一个未匹配点(出发的点不算),则这条交替路称为增广路。例如图 f 中的一条增广路:8→4→7→1→5→2。
增广路定理:通过不断找增广路来增加匹配中的匹配边和匹配点,当找不到增广路时,即达到最大匹配。
3. KM算法
通过匈牙利算法可以找到二分图的最大匹配,在司乘匹配场景中,即最大的司机乘客匹配数量(可能乘客找不到司机,也可能司机找不到乘客),其算法时间复杂度为n(O^4)。
在匈牙利算法基础之上,Kuhn-Munkres发明时间复杂度为O^3的KM算法,在解决带权值最优匹配的问题上更高效。
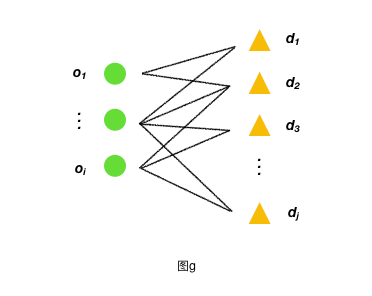
(1)如图 g 首先选择顶点数较少的Oi,初始时将dj的顶点顶标设为0,对Oj的每一个顶点设置顶标,顶标的值均为为该点关联的最大边的权值。
(2)对于Oi部中的每个顶点,在相等子图中利用匈牙利算法找一条增广路径.如果没有找到,则修改顶标,扩大相等子图,继续找增广路径。当每个点都找到增广路径时,此时意味着每个点都在匹配中,即找到了二分图的完备匹配。该完备匹配即为二分图的最佳匹配。
完备匹配:如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
相等子图:边权值等于两端点的顶标之和的边,它们组成的图称为相等子图。
有关KM算法的实现,在互联网上已经有很多相关讲解,这里不再赘述。
作者:花四爷,微信公众号:花四爷(ID:siyesay)
本文由 @花四爷 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议









那么问题来了,回家吃饭那个APP是如何找到厨师的?