起点课堂会员权益
起点课堂会员权益豆瓣读书推荐策略的阶段性调研
调研豆瓣读书的书籍详情页,【喜欢这本书的人也喜欢这个】推荐模块的效果,一起来看看~

一、理想态
1.1 定义理想态
给用户推荐相关且用户潜在感兴趣的书籍,吸引用户进行深层次互动行为,包括点击、评论、收藏等,提高用户在平台的留存。
1.2 核心指标拆解
(1)用户基本行为分析
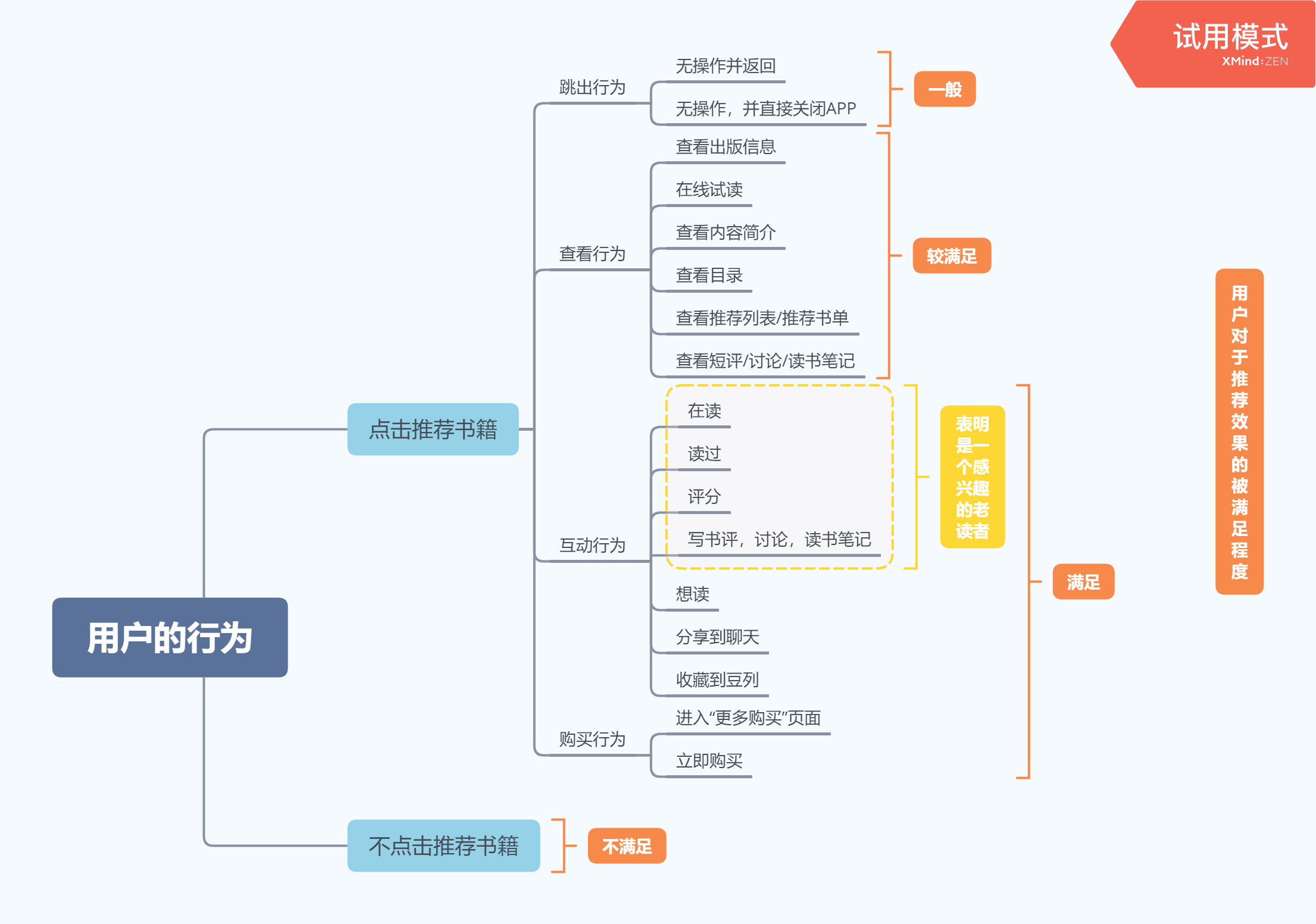
用户对于【喜欢这本书的人也喜欢】推荐列表的操作如下所示。
用户不点击推荐书籍,表明用户不满足,不是用户喜欢的;用户点击推荐书籍,但是存在跳出行为,表明用户对于该推荐一般;而存在查看行为,表明用户对于推荐的书籍存在一定的兴趣,较满足;若用户产生互动行为和购买行为,则认为用户被满足,达到较为理想的推荐效果。
Ps:对于已登入用户,假设推荐列表都是推荐给用户没有看过的书籍,如果用户后续操作标记“在读”,“读过”等,表明用户虽然看了此书但是并未在平台上有过相应的操作,平台并未识别到,那么后续推荐便可不再推荐。但是此次推荐,用户产生了互动行为所以依然可以被认为得到满足,因为符合理想态的定义。
(2)核心指标量化
一般来说推荐系统理想态的衡量指标是准确率和召回率。准确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。
因此本次设定指标如下:
准确率=每本推荐书籍的点击uv /推荐列表的总点击uv
例如我们给用户推荐了10本书籍,对其中2本,用户产生了点击,那么准确率为2/10= 0.2。推荐列表准确率=每本推荐书籍的求和平均值,可横向对比所有推荐书籍的转化情况,可以重点观察过高或过低的异常值。
召回率=用户在推荐列表的点击书籍数/用户在平台的总点击书籍数
例如我们给用户推荐了10本书籍,其中1本用户产生了点击,而用户最终在平台上总共点击了20本数,那么召回率为1 / 20 = 0.05, 表示的是推荐系统推荐的那些符合用户兴趣并产生点击的书籍占了用户实际总共点击的书籍有多少比例。
推荐位置转化率=第N个位置的点击UV/推荐列表的总点击UV
一般而言,越靠前位置的推荐书籍越该是用户最感兴趣,且与本书相关性高的,因此用户点击的可能性越大,推荐位置转化率越高;随着位置靠后,推荐转化率下降;可以纵向比较,不同书籍的同位置的转化率;可以横向比较同一个推荐列表的不同位置的转化率,一般而言推荐位置的转化率。
用户满足程度=采用对应路径进入的uv/通过推荐进入书籍详情页的总uv
如上图所示,将用户的交互行为路径分类,并进行量化。

二、抽样分析
由于数据获取较难,因此采取抽样调查的方法,检查核心指标是否达到理想态,从而探索豆瓣读书的推荐策略及是否存在问题。
2.1 分析维度及字段选择
一般而言,推荐策略的输入主要有两个特征,用户特征和书籍特征,将用户与书籍做匹配,但是调查发现:
(1)选取的指标需满足符合常理同时可量化,数据可获取的条件,用户特征无法获取。
(2)游客状态和登录状态,登录与多次操作后,该推荐模块都没有变化,也佐证用户特征没有作为输入。
因此此次主要从书籍特征进行分析,标记星号的为可用字段。

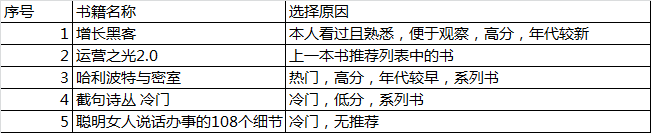
2.2 书籍选择
书籍选择如下,方便从不同维度进行分析。
2.3 样本分析
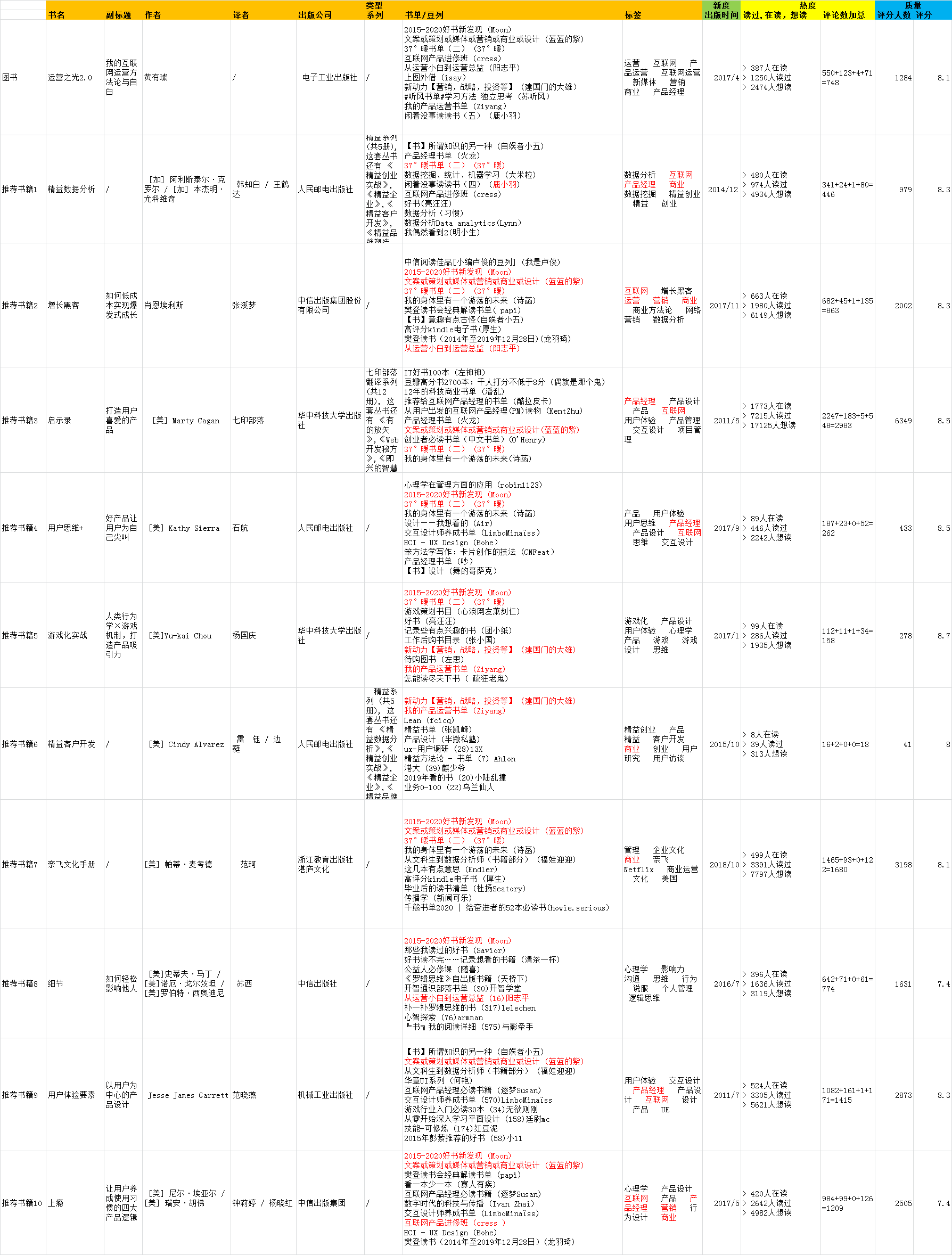
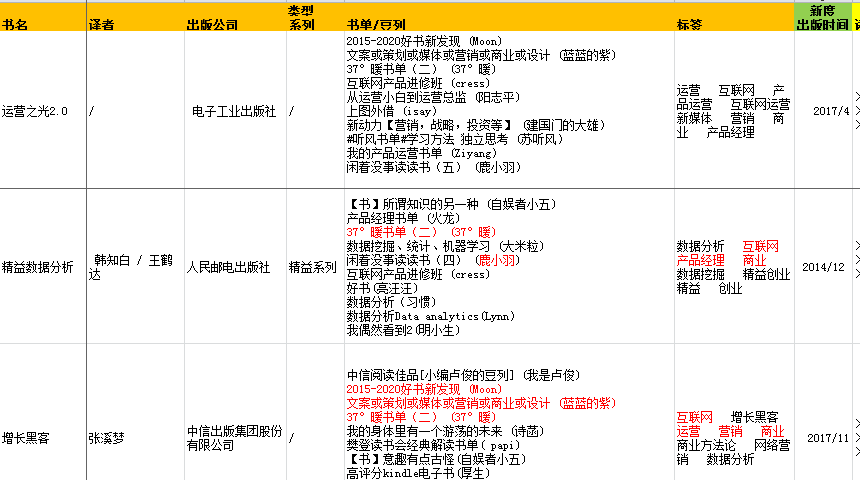
(1)增长黑客
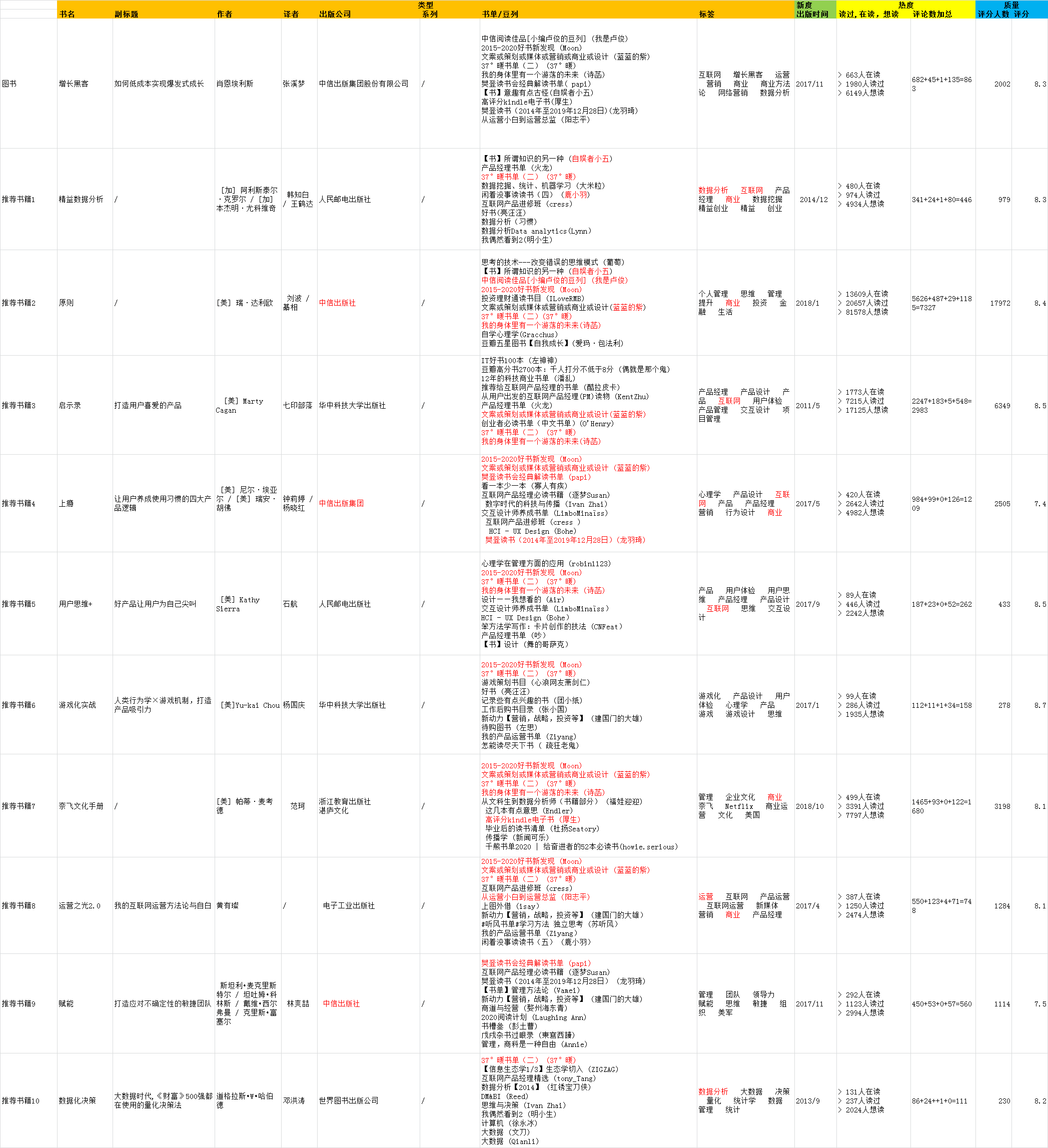
(2)运营之光2.0
(3)哈利波特与密室
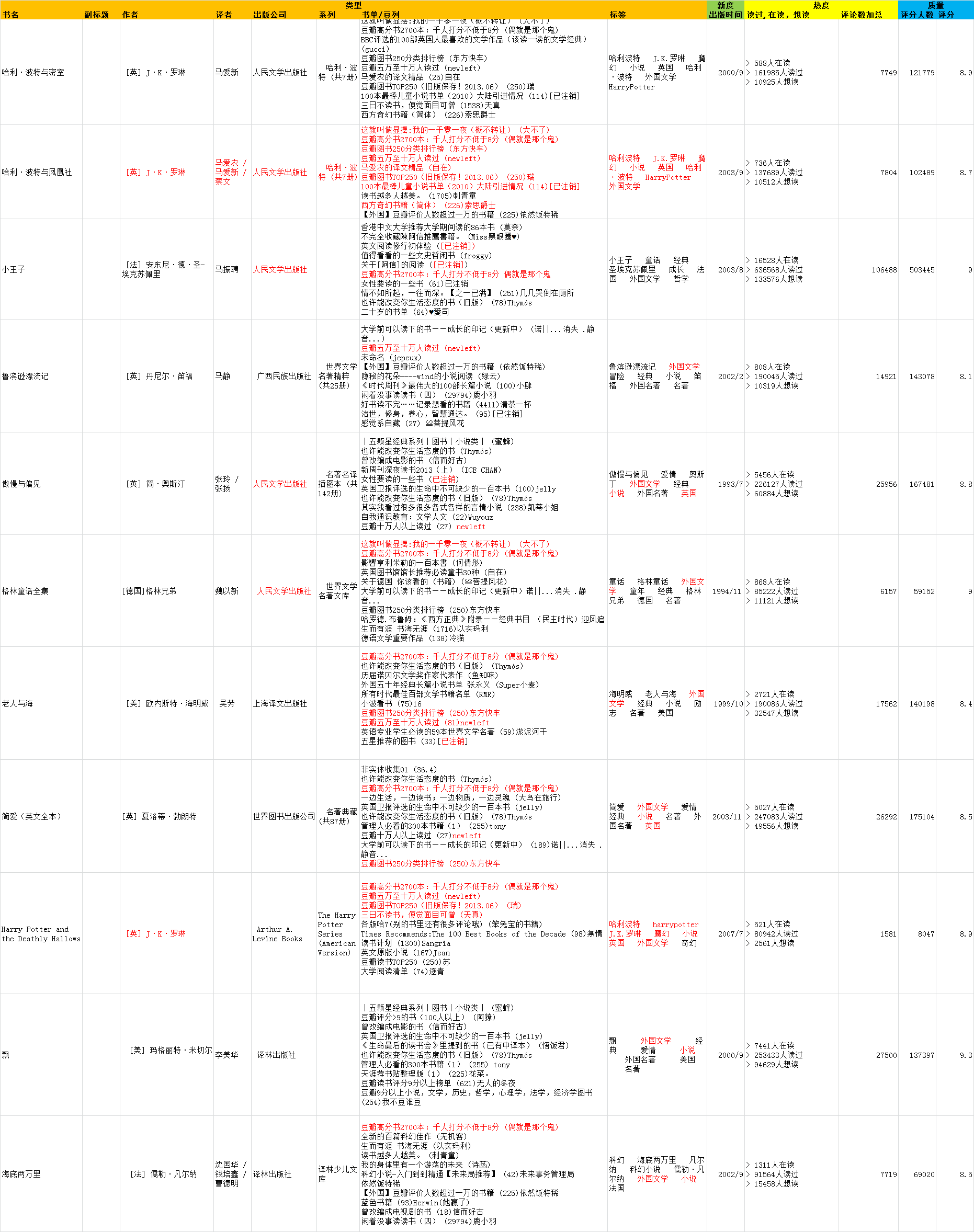
(4)截句诗丛冷门
 (5)聪明女人说话办事108个细节
(5)聪明女人说话办事108个细节

2.4 推荐策略猜测
(1)推荐策略的基本情况
游客与会员对比:在退出登录后,以游客身份重新搜索一遍相同的书籍,发现游客和会员看到的推荐书籍是一样的,由此猜测:豆瓣读书没有按用户类别做个性化推荐。
同身份多次操作对比:再次登录,在书籍详情页做了想读、在读、读过、评价、取消在读、取消读过等交互操作,推荐列表的书籍没有变化;点开推荐书籍详情页后,又返回原书籍详情页,推荐列表的书籍依然没有变化。
同身份隔天登入对比:发现该模块的部分书籍进行了替换,位置也进行了调整,如《增长黑客》替换了4本书,未被替换的6本位置也有所调整,表明该模块的推荐策略以天为单位进行重新推荐。

(2)是否进行推荐
通过对冷门书籍进行比对,发现是否进行推荐与评分人数和评分高低密切相关。

(3)推荐策略的关键输入
对于评分人数10人以上,评分6分以上的书籍进行推荐策略的猜测,根据抽样的结果整理可知:按照样本的情况,可知,比较书籍与对应推荐书籍的情况,推荐策略的关键输入根据相关性的优先级确定,排序依次为豆列,标签,评分,出版时间,出版公司等。
因此猜测对于评分人数10人以上,评分6分以上的书籍,大概率根据豆列,标签,评分,出版时间,出版公司等字段进行加权计算,得出候选内容池并进行排序,与本书籍相关性最高,得分最高的排在前面。

三、问题汇总
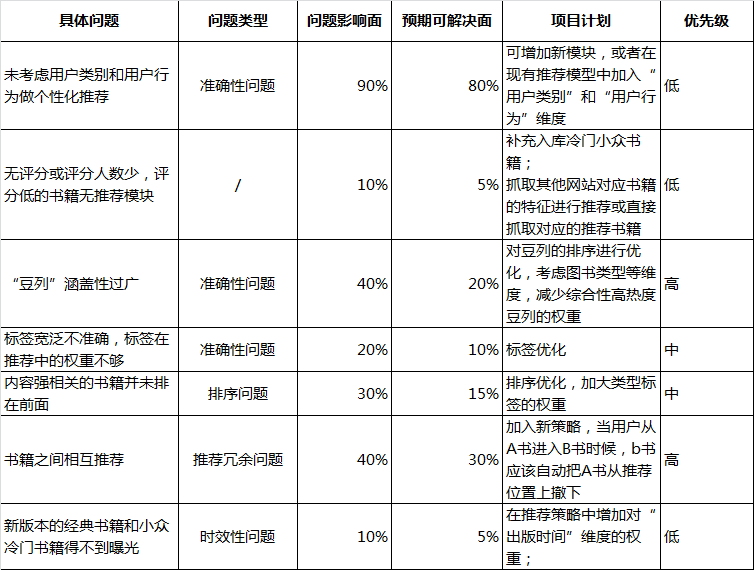
3.1 发现问题
(1)没有考虑用户类别和用户行为做个性化推荐
(2)无评分或评分人数少,评分低的书籍无推荐模块
(3)关键输入“豆列”涵盖性过广——准确性不够,推荐不准
《哈利波特与密室》,《增长黑客》等前三的豆列收录书籍过千,各种类型的书都有,泛而不精;依据此进行推荐,容易出现推荐错误。

《哈利波特与密室》前二豆列
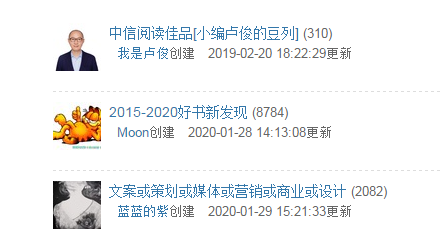
《增长黑客》前三豆列
如《范志红:吃出健康好身材》推荐《如何学习》,因为两者的豆列有相似,但是相似豆列均为收录数过千,泛而不精的豆列(37°暖书单(二) (37°暖))。
(4)标签宽泛不准确,标签在推荐中的权重不够——准确性不够,推荐不准
《范志红:吃出健康好身材》推荐《如何学习》,因为两者的标签都命中“学习”,而学习这个标签过于宽大。
《截句诗丛冷门》的标签为“诗歌 哲思 =i226+227= *合肥·黄山书社*”,《聪明女人说话办事108个细节》的标签为“聪明女人说话办事108个细节.pdf、说话的艺术、女人、女人说话、还凑合、智慧、很好 社科”,标签管理不到位,书迷贴上的稀奇古怪的标签限制了小众图书的推荐和曝光。
《增长黑客》推荐《赋能》,标签不相同但是被推荐,通过阅读发现两者书籍分别属于互联网运营类和领导思维类,与其他被推荐书籍相比,类型差距较大,推荐由于标签权重不够,没有被剔除。

(5)内容强相关的书籍并未排在前面——排序问题
《运营之光》属于运营类书籍,《增长黑客》比《精益数据分析》的类型,关联豆列,热度(读过、在读、想读、评论数加总)都要高,但是却排在后面。
(6)书籍之间相互推荐——多样性不够,推荐冗余
书籍与被推荐书籍之间:《增长黑客》和《运营之光2.0》的推荐书目重合6个;《哈利波特与密室》与《海底两万里》的推荐书目重合4个;与《鲁滨逊漂流记》的推荐书目重合5个。
系列书籍之间:《哈利波特与密室》中推荐了两本哈利波特系列书籍;《截句诗丛冷门》的推荐书目全是同系列书籍,其对应的推荐书籍也推荐本书。
(7)新版本的经典书籍和小众冷门书籍得不到曝光——时效性缺乏
通过抽样可知,一般都会推荐年份差距不大的书籍,但是经典书籍的新版本和相关性较高的小众冷门书籍,猜测因为评分,评论数等不够,并没有被推荐,得不到该途径的曝光。
3.2 优先级判断
本文由 @宋夏天 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!