
 起点课堂会员权益
起点课堂会员权益在线社交网络核心用户挖掘与传播规模预测
编辑导读:新浪微博作为一个新型的社交软件,已经成为了信息传播的重要载体。它具有传播迅速、信息量大、覆盖面广的特点,但同时对一些不良的社会事件也产生了推波助澜的作用。本文将从六个方面,对其传播链路展开分析,希望对你有帮助。

摘要:
新浪微博作为21世纪一种新型的社交软件,已经成为当今中国社会各界信息传播的重要载体。与传统社交平台的传播方式不同,其信息通过用户交互行为如发布、评论、转发等形式进行传播,具有信息量大、覆盖面广、传播迅速且传播过程具有裂变性等特点,这在一定程度上推动了广告优化、商品营销等信息产业的发展,但同时也对危害事件、谣言等传播起到推波助澜的作用,其引发的问题为互联网的安全运行带来了新的挑战。
本文通过研究30条热门微博的完整转发链路,挖掘信息扩散主要推动者,量化参与者对信息传播的影响力,剖析微博热门信息传播范式,提出一种基于微博关注关系以及传染病模型的传播预测模型,同时展望信息强化效应在传播规模预测的应用,结合用户影响力,在线性阈值模型的基础上着重考虑不同用户的核心程度,预测单条微博的最终传播规模。
关键词:微博;社交网络;核心传播者;信息扩散;传染病模型
一、引言
在单条微博传播网络中,信息的扩散主要依赖于用户间的转发,大多数用户存在于信息传播树较底层次范围内,微博最终扩散规模通常由极少数用户决定,这些用户往往是官方机构、舆论大V或者事件实际参与者,即为核心传播者。
核心传播者的识别,可以协助人们快速了解信息传播过程以及整体传播趋势,精准定位信息扩散中的“裂变点”,便于提前对网络舆情传播进行有效干预,对于热点发现、广告投递、谣言阻断、官方辟谣等具有重要意义(1)。
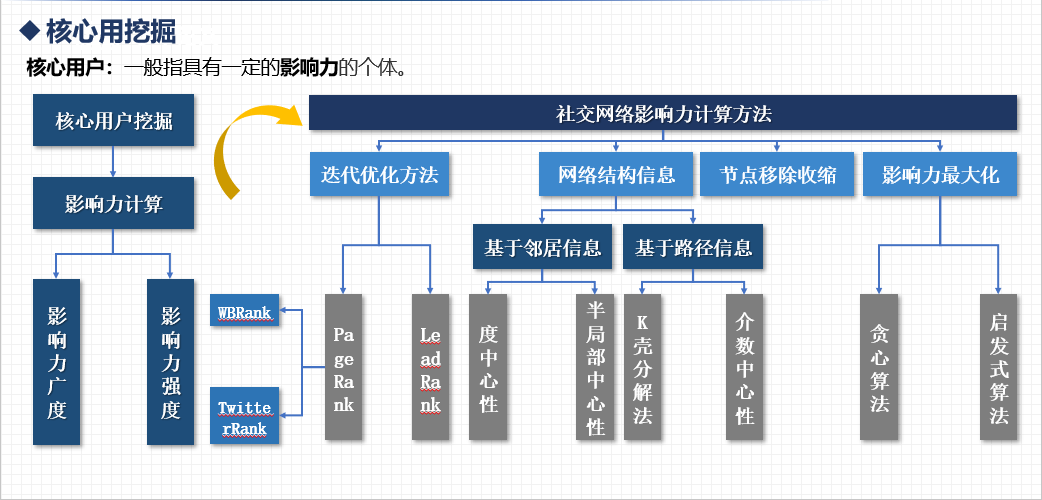
图1 核心用户挖掘相关工作
除了核心用户的识别,传播规模也是影响微博最终传播效果的关键要素之一。通过对信息传播规模的预测,可以提早发现信息传播的最终影响范围。相关研究集中于信息传播建模、影响力最大化等方面。其在实际应用中也十分重要,例如企业推广新产品期间,据此寻找最优营销策略,实现降低推广成本的同时提高经济效益;政府部门则可以用其来衡量谣言等不良信息危害程度,或运用信息在社交网络里的传播范式科学有效地发布信息,引导舆论走向,提供决策支撑等(2)。
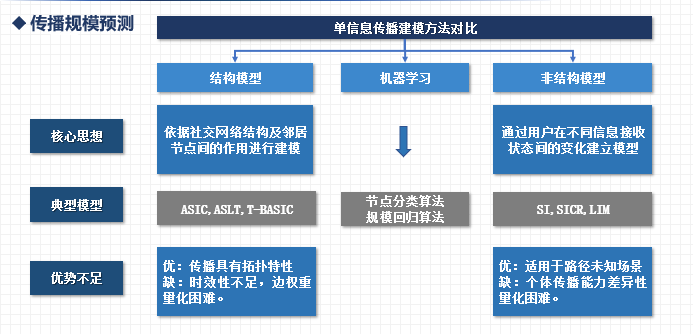
图2 传播规模预测相关工作
基于上述分析,本文主要阐述了以下两方面工作:
第一,本文通过分析微博网络中完整的转发链路,定义了核者的识别。
第二,本文通过提取微博网络中的相关特征,综合分析对转发产生影响的因素,考虑到影响转发因素的用户影响力以及信息强化效应,以线性阈值模型(LT)、传染病模型(SEIR)为最初蓝本,改进阈值表示方法,实现对于单条微博最终传播规模的预测。
二、数据分析
2.1 数据介绍
本研究使用数据为30条热门微博的完整转发链路,全部传播数据及参与传播的账号关系(脱敏),包括用户转发时间以及部分转发用户的关注。
2.2 转发层级分析
转发深度与广度是信息传播的重要指标,通过对30条不同类型微博传播链路进行分析,我们有如下发现(附录Ⅰ):
- 不同主体类型微博往往具有不同的转发深度。
- 对同一事件,不同微博文本对于转发深度也有不同影响。
- 转发深度与最终规模有相对较弱的正相关关系。
2.3 关注结构分析
关注关系是其社交网络结构的重要组成部分,用户间的关注关系共同构成网络结构的入度与出度。通过分析88829条用户关注数据有如下发现(附录Ⅱ(1)):
- 有8420人次(10%)关注人数高达993,我们分析提供的数据爬取时最高爬取量为993。
- 大量用户关注数在100~200档位,符合一般逻辑,因为大多数人处理社交事务精力有限。
三、核心用户挖掘
核心用户挖掘往往与关键节点发现以及影响力最大化等研究结合在一起, Richardson和Domingos等人(3)的研究认为影响最大化问题本质上是一个算法问题,问题的关键在于精确识别网络中某些对于信息扩散最具影响力的节点。
本文核心用户挖掘的工作主要围绕一个思想,俩个网络与四种指标展开。考虑到核心用户在不同场景下有不同的定义,在信息传播的情形下,本文使用用户微博扩散能力、对下级用户影响程度能力为衡量指标计算核心用户的核心程度。具体运用PageRank思想,基于微博转发关系网络、用户关注关系网络,构建微博转发时间性、用户转发影响力,对下级用户的情绪强弱性影响以及在静态网络中的用户自身位置信息指标决定用户核心程度。
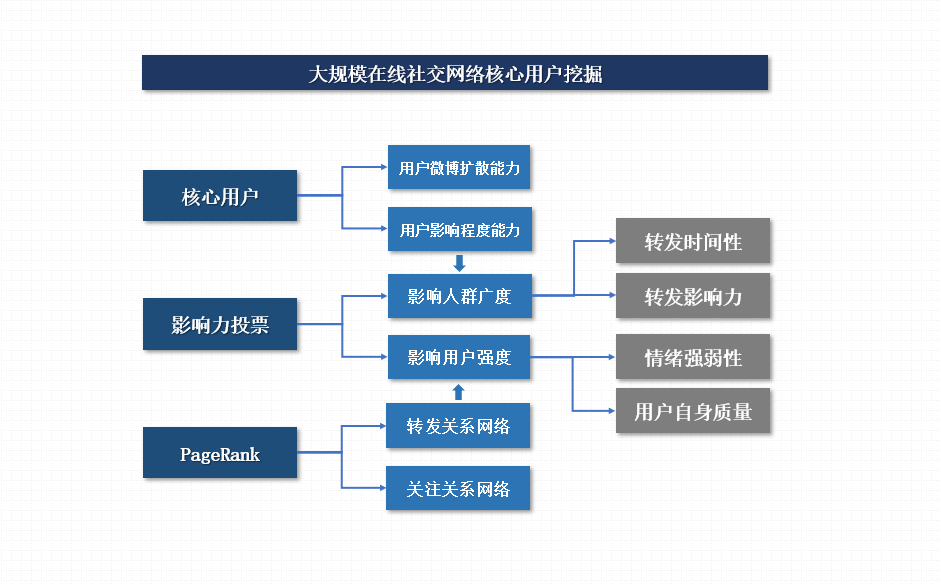
图3 核心用户挖掘解决流程
3.1 baseline:级联率
级联率(Cascade Ratio)刻画了参与信息传播的用户通过该条信息影响其粉丝的程度,用户u转发了某条微博i的级联率CR(u,i)可以定义为:
![]()
其中S(i)表示该条信息i最终的扩散规模;N(u,i)表示用户u引起的转发数量。一般来说,级联率计算简易,适用于大规模转发网络的核心传播者发现,局限性在于其对影响力的评估过于简单,缺乏对转发网络链路整体性的思考。
3.2 基于转发关系网络结构:转发时间性
微博具有大规模性、噪声多样性、快速传播演化性等新特征(5),面对海量信息覆盖,用户存在“快餐式”的信息消费习惯,致使大多数微博的存在寿命十分短暂,因此我们定义扩散速率为另一用户影响力衡量指标。因此我们用指数衰减函数模拟用户转发时间对用户影响力的贡献,衰减速率参数设置为11小时。这也符合戈兹等人基于微博分析提出消息影响力衰减服从幂律分布的结论。
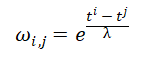
其中,ωi,j为用户i转发用户微博对其影响力的贡献值,ti为用户i转发用户j微博的时刻,tj为用户j发布或转发微博的时间。λ为控制衰减速率的参数,设置λ=11h。衰减速率控制参数λ确定(λ>0):
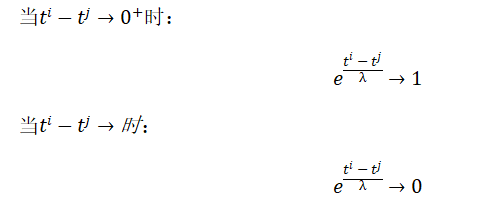 PageRank算法的计算公式:每个网页的 PR 值不仅仅要考虑被链接网页的数量,还要考虑链接到该网页的网页质量和重要性的影响。
PageRank算法的计算公式:每个网页的 PR 值不仅仅要考虑被链接网页的数量,还要考虑链接到该网页的网页质量和重要性的影响。
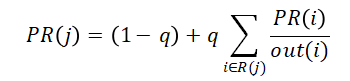
考虑转发时间性指标,转发影响力的计算公式:每个用户的转发影响力值不仅仅要考虑其引起转发的数量,还要考虑引起转发的用户的质量和重要性。
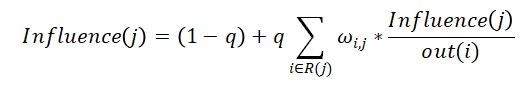
其中,influence(j)表示用户i的转发影响力,q为为阻尼系数(Damping Factor)且0<q<1,R(j)为用户i引起的转发用户集合,ωi,j为时间性指标,考虑到转发关系网络中用户参与转发微博的父微博用户唯一,因此式中out(i)为1。
转发影响力的计算中本文使用的基于转发时间性指标的PageRank算法衡量用户对于微博转发的影响力,具体旨在不仅用节点出度值计算贡献度,还考虑基于边赋值上由转发时间性得到的权重。同样的,考虑到大规模网络计算的复杂度指标,本文提出第二种衡量转发时间性的指标:
单位时间引起的转发量:统计某用ui户引起转发的微博的起始转发时间start_time(ui)与终止转发时间end_time(ui),及其引起的总转发量sum(ui),计算转发速度有:
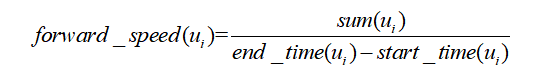 一定规模转发时间:取ui引发的所有微博转发总量的99%分位数记为threshold(ui),转发量在其下的,一定规模转发时间记为0,而微博转发量达到所有微博转发总量的99%分位数的微博,则统计微博的起始转发时间start_time(ui)与达到threshold(ui)转发量的转发时间threshold_time(ui)计算其一定规模转发时间为:
一定规模转发时间:取ui引发的所有微博转发总量的99%分位数记为threshold(ui),转发量在其下的,一定规模转发时间记为0,而微博转发量达到所有微博转发总量的99%分位数的微博,则统计微博的起始转发时间start_time(ui)与达到threshold(ui)转发量的转发时间threshold_time(ui)计算其一定规模转发时间为:
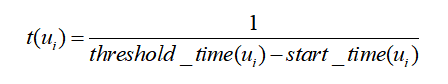
指标综合及规一化:
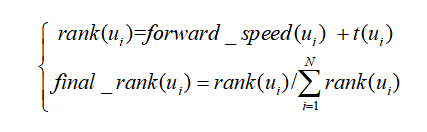
3.3 基于关注关系网络结构:用户自身质量
用户自身质量指标与用户在静态网络(关注关系网络)中的位置信息以及对下层用户的情绪影响决定。
参考PageRank算法的思想(4),利用真实转发链路数据提出一种新的核心传播者转发影响力评价指标ZX值,该算法基于社交网络上信息实际转发链路,能够相对客观地反应用户在单条微博的传播中对最终规模的影响力,用户ZX值定义如下:
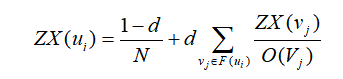
其中ZX(ui)为参与转发微博的用户ui的ZX值;F(ui)为转发用户ui微博的用户集合;O(vj) 为用户vj的关注用户数;0<d<1为阻尼系数,其设置影响算法的性能,通常d为0.85。考虑到微博转发关系矩阵较为稀疏,故通过迭代后节点ZX值相对较小,又此处我们定义的ZX值仅代表单条微博所有参与转发的用户对信息扩散的贡献程度,故我们可以对此值归一化处理,方便以后的集成计算,有:
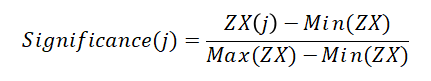
观察用户核心度值与引起直接转发数的相关性,可以发现该指标能够较好的体现其直接引发的转发数量,也考虑到对后续转发的间接推动(附录Ⅱ(2))。综合来看,社交网络往往普遍存在大规模性,因此使用复杂度高的算法难以实现对显示社交网络的指标计算,结合用户自身质量指标衡量手段不一,因此也可以考虑相关中心性算法实现用户自身质量的量化。
3.4 基于关注关系网络结构:情绪强弱性
考虑到观念、情绪等也是可以传播的,故本文旨在量化情绪的强弱对转发的促进作用,此处使用《基于情感词典的情感分析方法》计算用户情绪强弱性,对于每一个文本都可以得到一个情感分值,以情感分值的正负性表示情感极性,大于0为积极情绪,小于0反之,绝对值越大情绪越强烈。
基于情感词典的情感分析方法主要思路:
- 对文本进行分词,找出文本中的情感词、否定词以及程度副词;
- 判断每个情感词之前是否存在否定词及程度副词,将其与情感词分为文本中的一个组;
- 如果情感词前有否定词则将情感词的情感权值乘以-1,如果有程度副词就乘以程度副词的程度值;
- 加和所有组的得分,积极情绪得分大于0、消极情绪得分小于0,绝对值越大情绪越强。
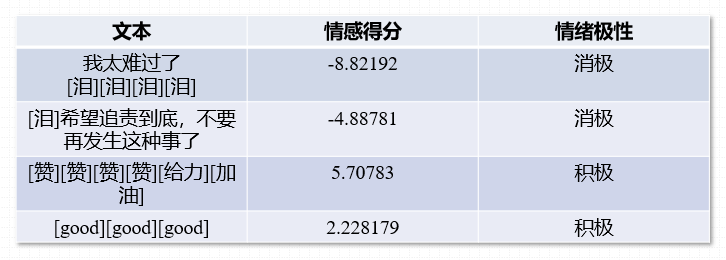
图4 情绪强弱性判定结果
一个转发用户的情绪影响指标由其对下层用户的情绪强弱性值决定,使用上述算法,以单条微博涉及用户为范围计算用户情绪影响指标,并做归一化处理。
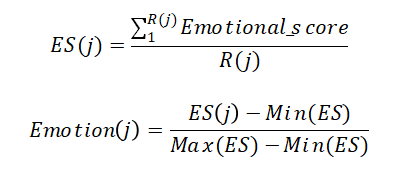
用户自身质量指标是位置信息与情绪影响的线性相加,有:
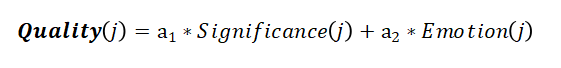
其中,a1、a2分别为用户自身质量计算中位置信息因素与情绪影响因素所占比重,设为0.8、0.2。
3.5 指标集成
对于高复杂度算法算法:在基于社交网络的信息传播过程中:
- 转发影响力:体现被转发用户信息传播能力在话题内的信息传播广度。
- 用户自身质量:体现用户信息传播能力影响用户的强度。
因此本文将这两个度量指标通过线性融合计算用户在话题内的信息传播能力大小。
![]()
其中,θ1为核心用户计算中用户转发影响力所占比重,θ2为用户自身质量所占比重;如设置θ1=θ2=0.5,表示认为用户转发影响力、用户自身质量对核心用户挖掘同等重要。该算法以社交网络理论为基础,结合 PageRank 算法,既考虑微博信息转发网络特征,充分结合用户转发行为的时间特征,又结合用户情绪传递性考虑微博用户的质量属性特征,具体体现于对信息扩散的推动、对下级用户的影响强度。
整体上看,能够较好地反映核心用户的综合影响力。对于低复杂度算法算法:综合考虑影响用户核心程度的各种指标,本文提出一种结合关注关系、转发链路以及扩散速率的核心用户挖掘算法,对于不同的微博类型,可针对性对NZX值以及final-rank进行赋权,针对娱乐性新闻WNZX,Wfinal-rank可分别设置为0.8,0.2;针对政治性新闻,由于其穿透性更强,转发深度更深,WNZX,Wfinal-rank可分别设置为0.5,0.5。综上定义核心度计算公式为:
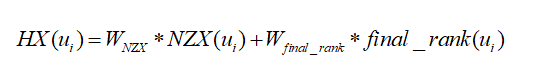
四、传播规模预测
在微博网络中,用户之间是通过“关注-被关注”联系在一起的,每一个用户都可以关注其他用户,关系网络可以看作是一个有向图。
4.1 结构化与非结构化传播
经典的传播理论认为信息的传播可以分为“大众传播”和“人际传播”。随着社会网络分析(SNA)方法不断地发展,对于信息传播规模的预测出现了过度“结构”化现象(6),即过分强调网络结构,忽略的信息传播的宏观性。个体间的相互作用对最终传播规模有着重要影响,夸大其网络结构的作用,往往有悖实际情况。
微博的出现让“非结构化传播”和“结构化传播”间的界限更加模糊,如微博信息扩散途径并不完全依赖于关注关系,还包括热门推荐、热搜榜单等都有可能是微博转发源(附录Ⅲ(1))。
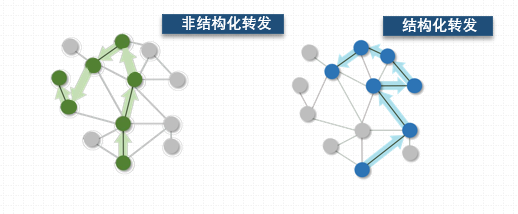
图5 结构化、非结构化转发示意图结果
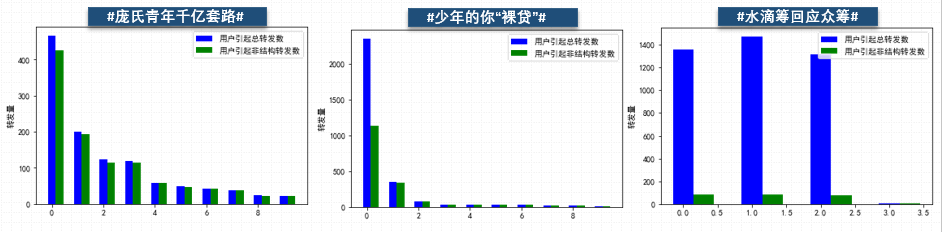
图6 不同网络结构化转发在对应转发深度中比重
4.2 非结构化传播预测
由上文的分析可知,本次竞赛提供的30条热门微博的转发数据不严格或者很少严格依据网络关注关系结构,因此本文提出基于传染病模型的非结构化的转发预测方法,该方法依赖于转发规模随时间的变化数据学习参数,图为30条微博转发规模的变化曲线,时间步长为一个小时。
图7 30条微博转发数随时间变化情况
SIRE模型定义:基于研究传染病传播的舱室(SIR)模型的基础上增加非结构化转发行为。
- 当用户参与单条微博信息的转发之后,基本不会再次转发,成为 “免疫用户”。
- 信息传播不全依赖于网络关系(关注关系网络),增加“外来用户”。
- 结合微博特性的传播预测模型:SIRE(Susceptible-Infectious-Recovered-External)模型。
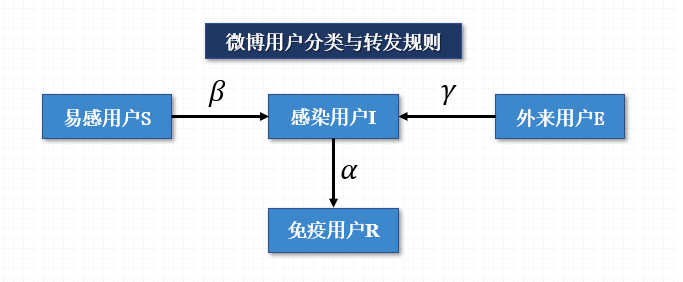
图8 SIRE模型示意图
在实际的微博传播过程中,比如某用户发布一条微博,最先被该用户的粉丝看到,并可能引起转发行为。当用户转发过这条微博之后,基本不会再次进行转发,从而成为这条微博的“免疫用户”。由于微博内容在网络中进行传播,也存在着不是微博用户的粉丝而进行的转发行为,即非结构化转发。因此,本文在基于研究sir传染病传播模型的基础上增加非结构化转发用户,即“外来用户”,提出满足微博特性的传播预测模型,定义为SIRE模型。
该模型满足以下假设:
- 假设1:用户发布或者转发用户的状态为感染用户,其直接粉丝的状态为易感染用户。
- 假设2:微博用户从易感染用户成为感染用户的概率为β。
- 假设3:用户从感染转态成为免疫状态的概率为α。
- 假设4:没有关注这些感染用户的状态为外来用户。此类用户自主阅读微博并转发的概率为γ。
当给定某条微博,t时刻,在SIRE模型中:
- S(t)表示t时刻易感染用户的数量,该部分人群可能会进行转发;
- I(t)表示已转发改微博的用户,并且具有传播力的人群;
- R(t)表示免疫用户R的数量,该类用户表示t时刻不会再转发该微博的用户人数。
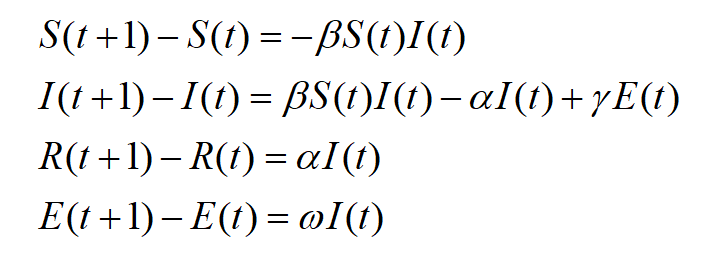
具体微分方程表达如下:
- 假设从t时刻起,单位时间内一个感染用户可能传播的易感染用户为S(t),转发传播的概率值为β,因此单位时间内变化的易染人群为β*S(t)*I(t)。(2)t时刻,单位时间内增加的免疫用户的数量为aI(t)。
- t时刻,单位时间内外来用户转发该微博的概率为γ,由外来用户转化为感染用户的数量为rE(t)。
- 易感的减少量减去转化为免疫的用户加上外来用户转发量为此时的感染数量。
设置微博发布时刻为初始状态状态,即t0,此时只有发布用户为感染用户,粉丝为易感染用户,即t=t0,I(t0)=1,E(t0)=0,S(t0)=N,N为微博发布者的粉丝数,可通过博文追溯得到。其中,参数β,α,γ,ϖ,设置β,ϖ为时域衰减,以符合实际传播情况,其值采用马尔科夫蒙特卡洛方法求解,确定最优值。
图为#中国女排卫冕世界杯冠军#与# 视觉中国#转发预测拟合效果。
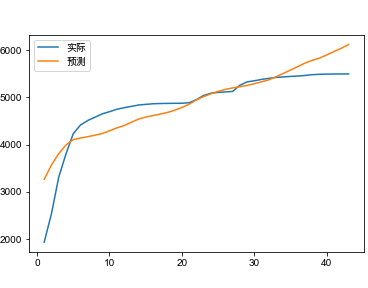
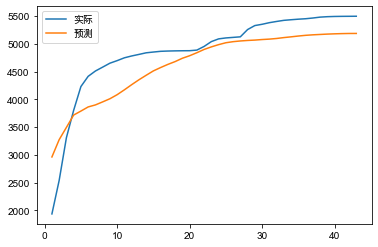
图9 拟合效果
五、结构化预测方法的展望与想法
5.1 转发行为影响因素提取
微博信息传播的主体机制就是转发行为,能对微博转发产生影响的因素有很多,不同的因素对用户最终转发与否的贡献值也并不相同,我们提出用户核心度、信息强化效应为用户转发的影响因素。
5.1.1 用户影响力
用户核心度表达了用户在社交网络结构中的重要程度,具体体现于一个人的行为引起其他人的行为改变的能力。现存众多基于网络结构的节点影响力计算方法(7),如K核中心性(K-shell)、介数中心性(Betweenness)等。Sergey Brin和Lawrence Page(8)提出的经典的网页排序算法PageRank值,Cataldi等人(9)考虑到微博等社交网络的连边关系与网页中的连接的相似性,将PageRank算法应用于社交网络中影响力节点的判断并可以较好展现网络中的用户核心程度,因此本文使用PageRank值作为节点影响力评价指标(附录Ⅲ(2))。
5.1.2 信息强化效应
在社交网络中,因为用户间存在趋同性,某些行为也具有类似信息的传播效果,例如同龄人的饮食行为(10),微博用户的转发行为等。我们对30条热门微博8万多用户参与的114856次转发行为分析时有如下发现(附录Ⅲ(3))。
- 有68340次转发(59%),其用户的关注列表中并没有参与该条微博转发的用户,可能转自推荐或者热搜,这也是微博信息传播的非结构化体现。
- 存在23843次转发,其参与者的关注列表中有一位参与该条信息转发的用户。
- 有22673次转发受到2次及以上激活,社会强化效应不可忽视。
5.2 基于强化效应预测模型
本文提出一种基于微博关注关系、用户影响力以及信息强化效应的传播规模预测模型,该模型在线性阈值模型(LT)(11)的基础上着重考虑不同用户影响力。该模型分为两个部分,启动部分及后续传播部分。启动部分考虑根微博用户u对粉丝集合fans(u)的影响力PR(u),用户v转发阈值设置为0到该粉丝所有关注用户(Fv)PR值之和间的随机数,即γv∈[0,sum(PR(Fv))],若PR(u)>γv,则用户v不转发;若PR(u)≤γv,则用户v转发。后续传播部分因为信息的冗余所以存在强化效应,对用户的总影响力Influce(v)计算如下:
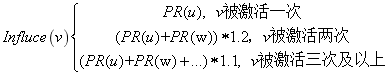
用户v转发阈值设置为0到该粉丝所有关注用户(Fv)PR值之和间的随机数,与LR模型不同,当v所关注用户近90%都转发了该微博,则用户v必参与转发。

循环上述算法二直至不再增加转发节点,可以得到基于关注关系结构的转发规模Net_Scale。结合上文对8万多用户的转发行为分析,59%的用户的转发不依赖于关注关系,所以有最终传播规模:
![]()
5.3 基于链路预测模型
分析本次比赛提供的数据之后,本文将微博信息转发预测问题转化为链路预测问题。链路预测的主要目的是基于推测网络节点之间存在链路的概率。本文主要研究基于转发关系的微博传播网络中的链路预测问题(附录Ⅳ(1))。
本文采用转发数据对不同的指标进行对比分析,将数据及按照0.85:0.15的比例切分训练集和测试集。分别尝试Adamic-Adar,Jaccard Coefficient, Preferential Attachment, Node2vec, Variational Graph Auto-Encoders等链路预测方法,衡量链路预测算法精度的指标主要有AUC和Precision,其中AUC从整体上衡量算法的精确度,Precision只考虑排在前L位的边是否预测准确。仿真结果发现Node2vec, Variational Graph Auto-Encoders, Spectral Clustering 在ROC得分和PR得分上要优于Adamic-Adar,Jaccard Coefficient, Preferential Attachment(详见附录Ⅳ(2))。
六、结论与展望
本文分析了新浪微博30条热门信息转发链路,提出了对于真实传播网络的核心传播者发现算法,该算法综合考虑用户直接带来的转发量,以及对信息后续传播的影响,提出用户核心度,转发速率指标,从时间、空间角度量化用户贡献值,实现单条微博转发中用户重要程度排名。
本文还深入分析了转发链路与最终传播规模的内在关系,提出了一种基于SIRE的传播规模预测模型,此外,想法拓展中提出一种基于影响力的转发阈值模型,该模型分为启动部分和后续传播部分,综合考虑了用户在网络结构中的影响力以及社会行为强化效应,通过仿真计算的方法预测传播规模,最后尝试了几种链路预测算法用于信息传播模型研究。社交网络上的信息传播机制相对复杂,其一定的传播机理附近存在大量的随机性与不确定性,受限于用户的兴趣爱好、转发习惯、甚至情绪的影响。
单从结构上、宏观上都无法准确描述其具体传播范式。实现真实准确的转发规模预测,即要考虑结构上的“内部影响”,也要考虑宏观层面的“外部影响”,以及结合用户习惯与博文属性等等因素。只考虑信息传播链路、用户网络结构等特征无法实现对于真实热门信息的全面挖掘。用户探索是发现社交信息传播模式的核心,新浪微博拥有海量用户,来自社会的各个层面,用节点代表用户,用连边代表关系是理想化的拓扑模型,方便计算却难以精准进行人群画像,从而忽略众多信息。
此外,本文对于信息强化效应的量化还有待提高,可在大规模社交网络上使用多种传播模型做多次信息传播仿真,这也是下一步的工作。
寻找信息传播可计算的基因远远不是几万行数据、几千行代码可以实现的,不确定的时代给计算传播学更多机遇与挑战,在线社交网络为信息传播研究带来极好的契机,推荐系统与社交关系改变了用户接受信息的方式,社交媒体与舆论大v创造了用户的信息环境,探索社交网络信息传播本质对大型社会网络研究将是巨大的贡献。
参考文献:
1. Fan L, Lu Z, Wu W, Thuraisingham B, Ma H, Bi Y, editors. Least Cost Rumor Blocking in Social Networks. international conference on distributed computing systems; 2013.
2. Liu D, Jing Y, Zhao J, Wang W, Song G. A Fast and Efficient Algorithm for Mining Top-k Nodes in Complex Networks. Scientific Reports. 2017;7(1):43330.
3. Richardson M, Domingos P, editors. Mining knowledge-sharing sites for viral marketing. knowledge discovery and data mining; 2002.
4. 宫秀文,张佩云.基于PageRank的社交网络影响最大化传播模型与算法研究[J].计算机科学,2013,40(S1):136-140.
5. 丁兆云,贾焰,周斌.微博数据挖掘研究综述[J].计算机研究与发展,2014,51(04):691-706.
6. 许小可.社交网络上的计算传播学[D].北京:高等教育出版社, 2015:2-3.
7. 任晓龙,吕琳媛.网络重要节点排序方法综述[J].科学通报,2014,59(13):1175-1197.
8. Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bring order to the Web.
Stanford University Technical Report SIDL-WP-1999-0120, 1999.
9. Cataldi M, Caro L D, Schifanella C. Emerging topic detection on Twitter based on
temporal and social terms evaluation[C]. In MDMKDD’10, 2010: 4-13.
10. 许小可.社交网络上的计算传播学[D].北京:高等教育出版社, 2015:164-199.
11. Granovetter M. Threshold Models of Collective Behavior. American Journal of Sociology. 1978;83(6):1420-43
附录Ⅰ
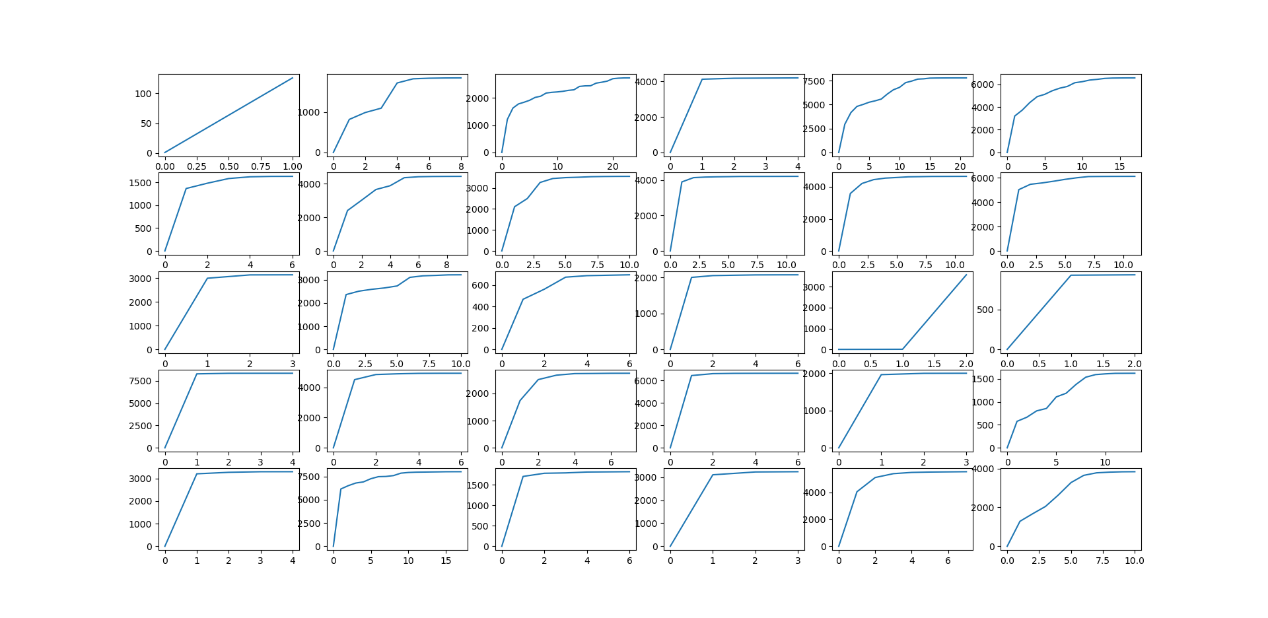
注:图示为30条微博转发趋势情况,横、纵坐标分别为转发深度、参与转发的用户总数。
我们发现公共关注事件,例如“庞氏青年水氢车”,“女排夺冠”等话题,其往往能引起群体的愤怒或喜悦,信息穿透性更强,扩散范围更广泛,平均转发深度高达20;兴趣导向事件,例如“AI换脸”,“姐姐来了”,“易烊千玺”等文娱微博,符合部分用户的兴趣,转发深度较低,扩散范围较为集中,转发深度均值为5~6左右。针对同一事件的不同文本描述,例如“德云社弟子众筹百万”事件,存在不同的扩散深度与传播规模,其受限于博文新颖性、发布用户关键性,其中博文能直接引起“大众情绪”的转发深度高达24。
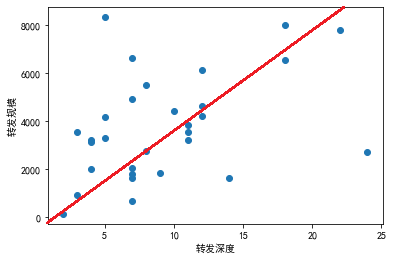
注:通过对30条各类型微博的转发深度分析得知,微博的最终传播规模与转发深度存在正相关性,相关系数为0.339518;去除转发深度24,规模2729与转发深度5,规模8356的离群点后相关系数高达0.66。附录Ⅱ(1)
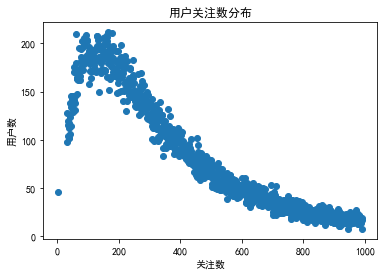
注:图示为剔除关注数量高于993的用户后剩余用户关注数分布,大部分用户关注数100~200档.(2)

注:图示为NZX值与节点引发转发数之间的关系,横、纵坐标分别为节点直接引发的转发数、原始NZX值整数扩样。(3)
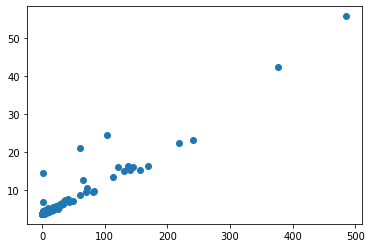
注:删除根微博用户,观察剩余用户NZX值与引起的转发量之间的关系,其整体上体现线性关系。图示的离群点用户,其引起的直接转发数不多但其中存在“裂变点”,故NZX值较大。附录Ⅲ(1)

注:推荐系统的发展使信息推荐更加符合用户的兴趣,精准投递用户感兴趣的内容,极大促成了用户面向非关注结构的转发行为;快节奏的生活压缩人们在社交网络上消耗的时间,部分用户为了信息获取的高效性、及时性、全面性往往格外关注热搜榜单,加之热搜的形成源自用户的普遍关注,也促成了用户面向非关注结构的转发行为。(2)
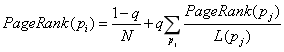
注:其中PR(ui)为用户ui的PageRank值;F(ui)为用户ui的粉丝集合; O(vj)为用户 vj关注的用户数; d为阻尼系数(Damping Factor),0<d<1。(3)
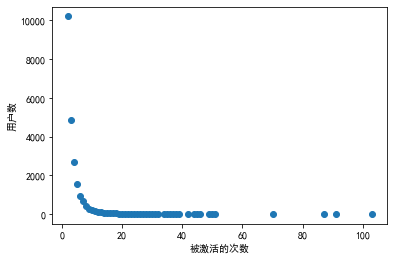
注:图为参与转发的用户的关注列表中,同时参与该微博转发的用户数(被激活的次数),社会行为强化效应的存在已被证实且强化效果并不呈线性增加,如存在一位与用户直接相连的肥胖好友(一度好友),用户的肥胖风险将增加45%,对于二度好友增加20%,三度好友增加10%;对于转发行为的强化效应定量化表示仍是下一步的工作。附录Ⅳ(1)
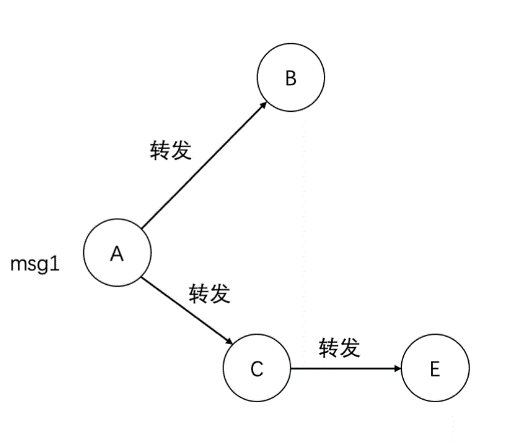
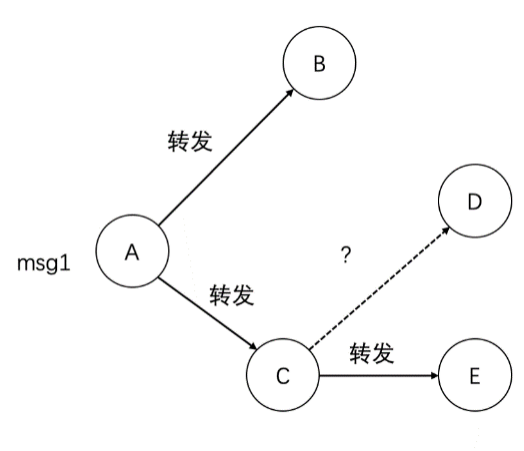
注:左图所示,用户B转发了A的微博,即形成一条有向连边。用Gmsg=(Vmsg′Emsg)表示,其中Vmsg′={v1,v2,…vn}⊆Vuser是微博信息msg在Gmsg上传播过程所覆盖的用户集合,Emsg={eij|1≤i≤m,1≤j≤m}⊆Euser,eij=1表示信息msg从用户vi传播到了用户vj,否则eij=0。
右图描述信息msg在传播网络中的链路预测问题,微博传播网络中的链路预测是预测用户采取转发行为的概率,当预测的转发概率大于设定的阈值时,会认为用户转发微博内容。(2)表1 链路预测方法比较
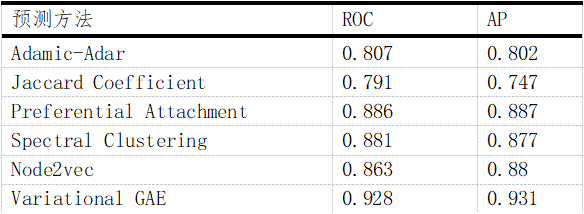
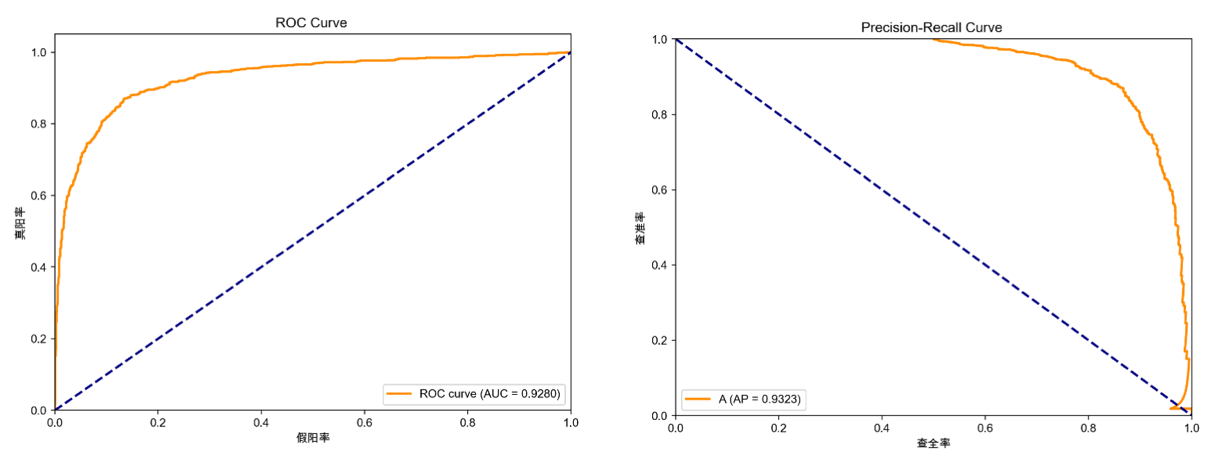
注:可以看出Node2vec, Variational Graph Auto-Encoders, Spectral Clustering 在ROC得分和PR得分上要优于Adamic-Adar,Jaccard Coefficient, Preferential Attachment。附录Ⅴ
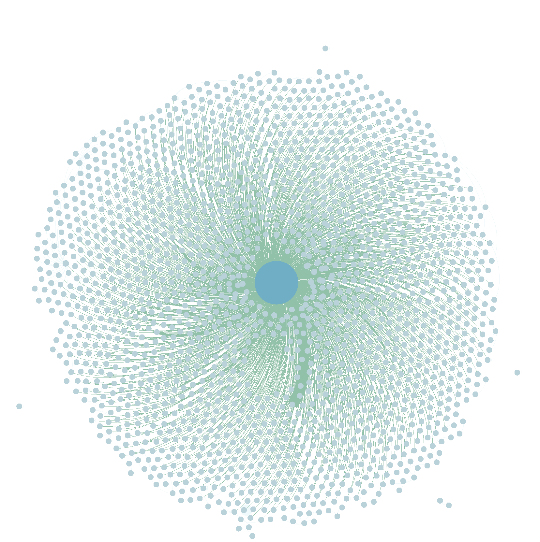
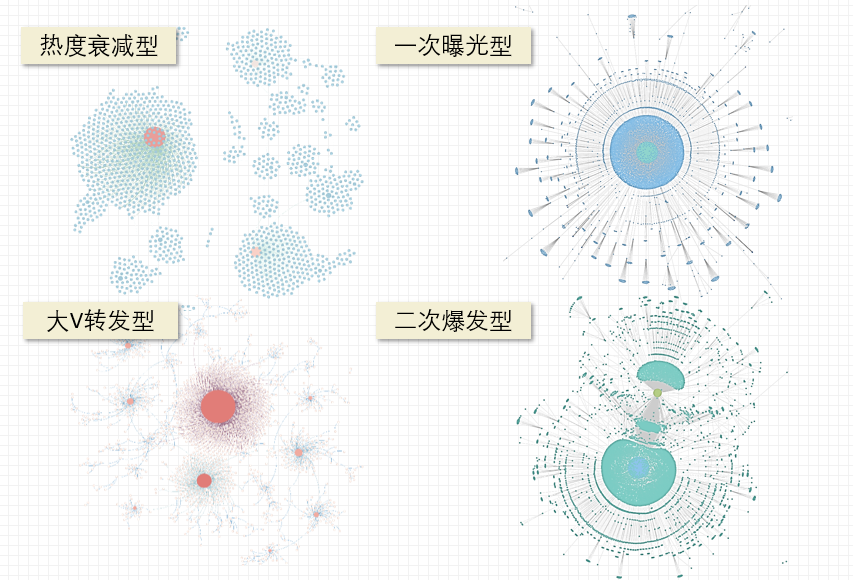
注:出道即巅峰型扩散网络,此类微博寿命较短,用户受兴趣导向转发,影响力相对较小。
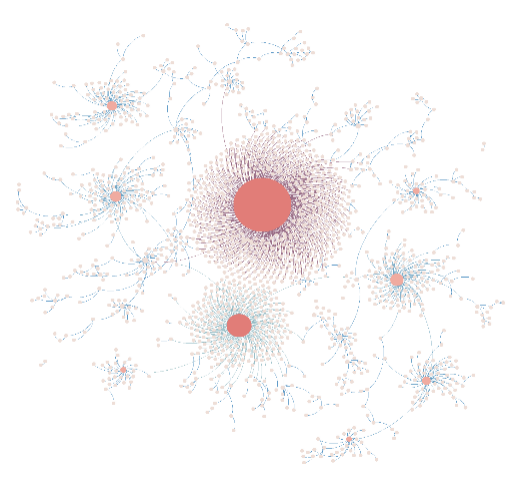
注:二次再爆发型扩散网络,此类博文通过知名博主转发后会再次引发扩散“裂变”。
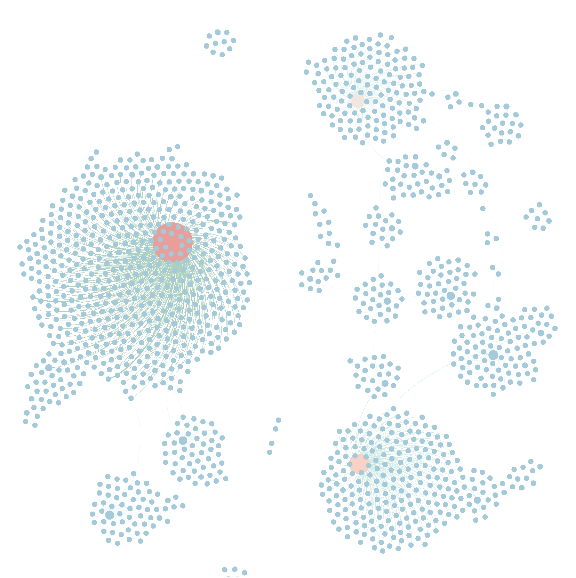
注:热度渐衰减型网络,此类微博受众用户广泛,信息渗透力强,往往能激发用户较为强烈的情绪或共鸣,寿命较长。
本文由 @数据锅 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。









不明觉厉,只怪自己当年,数学是体育老师教的,先收藏为敬。