
 起点课堂会员权益
起点课堂会员权益案例解读:Canvas在翻转课堂中的二分类预测应用
编辑导语:随着技术的发展,我们会采取一些新形态来辅助日常业务,比如翻转课堂就是在线教育中的一种新形态。但是,如何才能让翻转课堂发挥更好的效果?本篇文章里,作者结合Amazon SageMaker Canvas做了应用测评,一起来看看吧。

一、案例背景
1. 背景介绍
在线教育的一种新形态,利用建构主义来推进更好学习效果的达成。
而形态上,更多以翻转课堂的形式来落地。它的真正达成需要一些要素,其中一个比较重要的点在于同学们之间能够互相讨论启发,这样才能发挥出教学内容的更好吸收效果。
在引入正式的分析之前,简单介绍一下翻转课堂,是一种讲练结合的方式,先老师讲一段内容,然后同学讨论,通过同学与同学之间对前面内容的讨论,达到对内容的更好理解,这种互相碰撞能对概念理解得更深刻,对使用边界更明确,对过往经验的复盘与未来使用方面都能有一些不错的联系与触动。
2. 当前问题卡点
而当前的中间过程的问题卡点,同学们进入翻转课堂时讨论不起来,而讨论不起来的原因是很少的人进入房间内发言,会有一个房间1个人发言,其他人沉默的情况。
二、分析框架确定
1. 基本假设
为了能够达到更好的效果,那么需要让同学在听讲之后,针对前面学过的内容进行讨论。大家可以回忆想象一下高中的场景,老师台上讲完了内容,台下前后桌分组讨论。讨论起来,互相碰撞思想时才是此时的精髓。
因为线下的过往关系积累以及线下的关系压力等,所以大家发言讨论不是难事儿,但线上的场景里,有些难度。在尝试了通过数据瞄定线上关系,通过关系分组失败之后,将视角转移到了人的方面,在这里首先有两个假设:
- 发言是需要有过往积累的。
- 发言的人在过去的迹象中有做出一些不同的表现,更活跃更愿意参与各种意见表达。
2. 确定分析目标
在结合问题方面,锁定分析目标就有两个:
- 通过同学历史数据进行建模,最终能够预测用户发言与否的模型;
- 能够尝试确定哪些行为对识别发言比较重要,作为后续产品运营的一个考虑抓手。
三、数据介绍
1. 基于假设的指标选择
为了能够相对准确地做出发言与否的预测,那么从两个假设里去找到相关的可量化的数据指标。最终选定了四大类数据。分别是基础数据、历史此类活动的数据、历史学习情况以及互动情况。
根据上面的四大方面,确定了如下的指标:
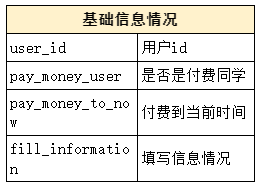
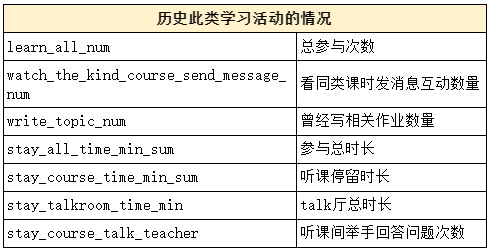


2. 目标值确定
除了上述的变量之外,目标字段为talk,他的判断条件是在talk厅发言超过1min计为1,小于等于1min的计为0。
3. 数据量备注
因为使用Canvas的过程中会需要上传文件,所以进行了脱敏,使该数据集既能保留了数据原本有用的部分,又能得到一定的保护。
由于是新业务初期,所以能够拿到的只有2000+条数据。虽然看起来比较少,但能够用于做最初的简单模拟。
四、利用Canvas建立机器学习模型
1. 操作总结
在Canvas建立模型的操作分为以下5个步骤:
- 构建aws数据存储;
- 导入数据;
- 通过目标区分回归与预测模型;
- 建立模型;
- 完成模型,回归结果。
2. 构建数据存储
首先打开Amazon SageMaker Canvas。因为前期我已经注册好了Amazon SageMaker Canvas,所以注册登录等不做演示。
接下来搜索s3,打开s3,在buckets下创建数据存储位置,点击“create bucket”来创建存储数据的桶。
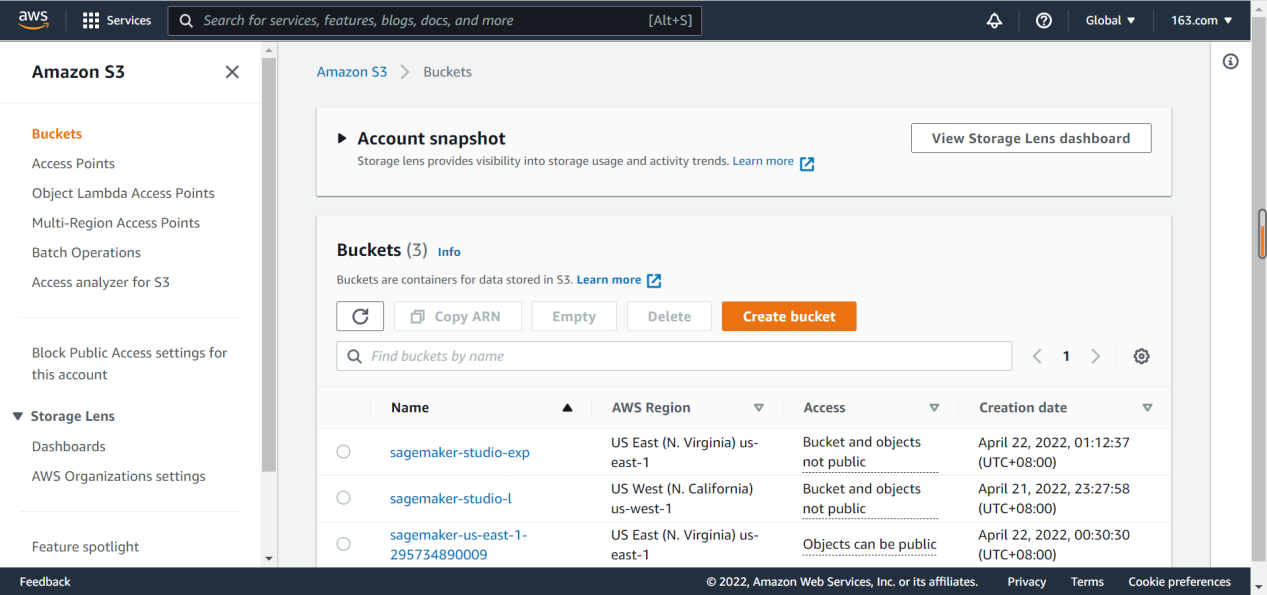
图中是我创建的三个bucket,我在本次操作中使用的是sagemarker-studio-l,点击打开它,在里面上传本地csv。此处需要注意,只能上传csv,xlsx这样格式上传之后后续也是无法使用的,需要格外注意。
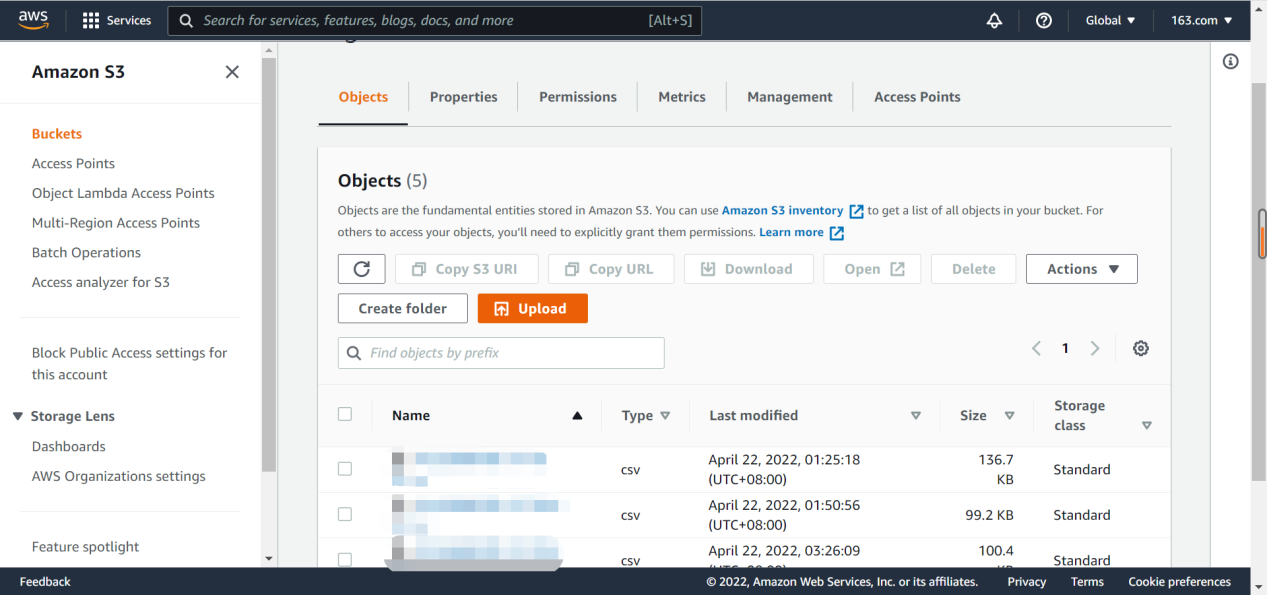
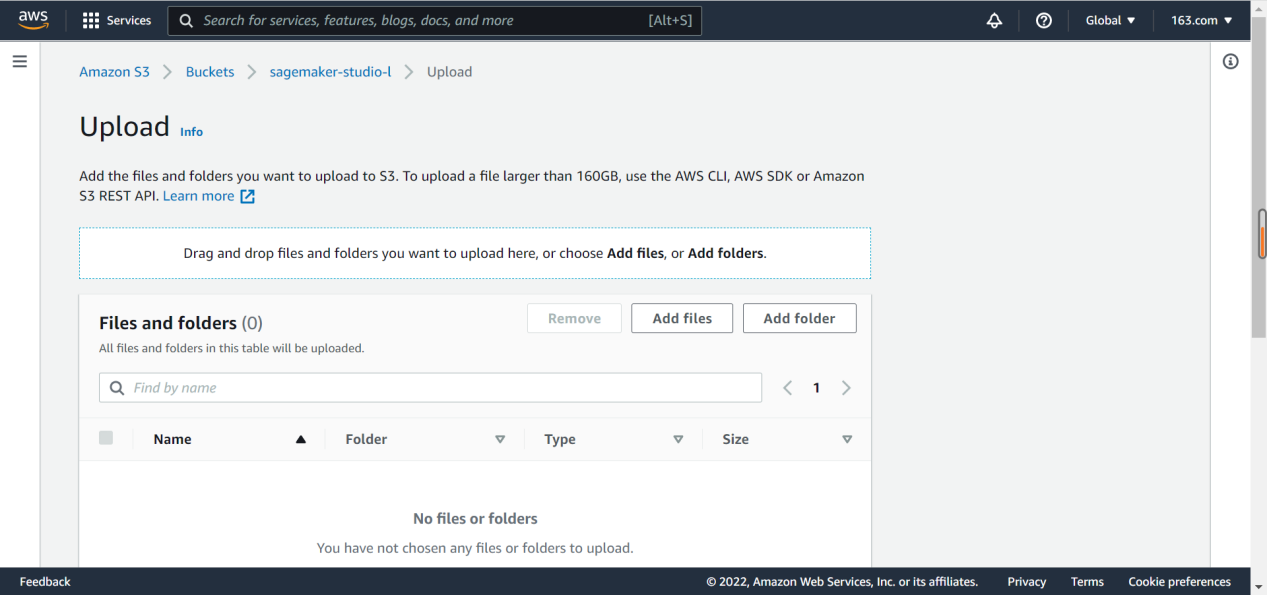
通过upload来打开下一个上传页面,通过add files打开我们要用的csv的文件夹,点击上传完成文件添加。
3. 导入数据
搜索Canvas回到这个页面,点击左侧边栏的Canvas启动Canvas功能。
打开后的页面就如下方图的界面。
理论上来说,都是有数据才有模型,不过在Canvas里并没有完全固定的顺序,先添加数据或者先添加模型都是可以的。
现在我们先建立一个模型,点击“new model”,对model起一个可辨识的名字。方便后续查看。
我会以我的目标以及版本操作来命名。在此次操作中,起名为talk-vx(下图是第3次建立模型,所以命名为talk-v3)。
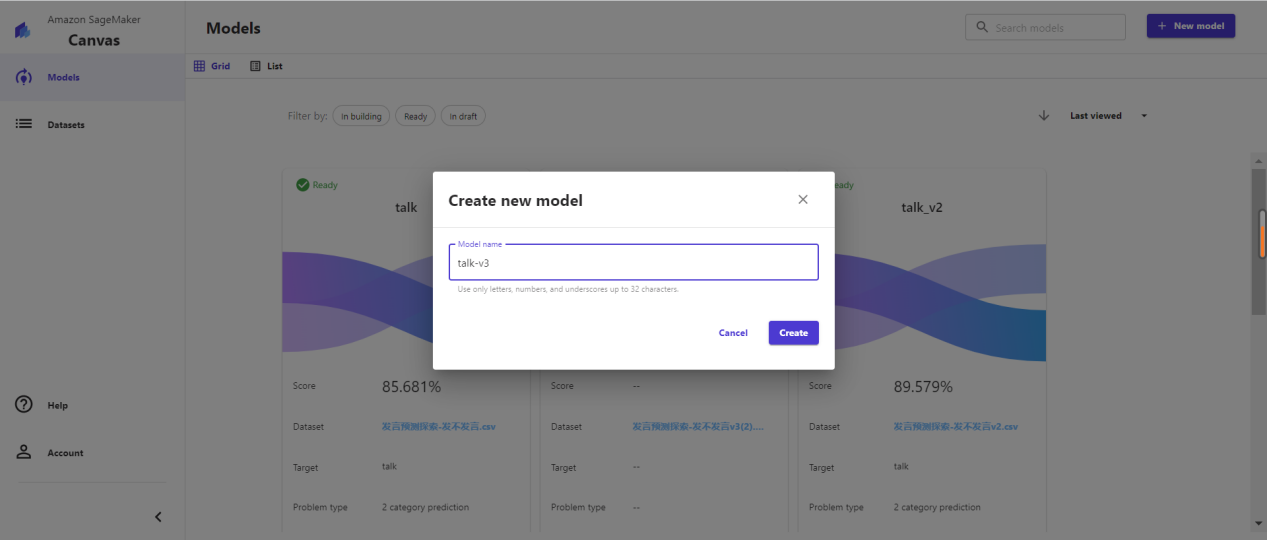
在页面中选择import数据的方式,将s3中bucket下sagemarker-studio-l中存储的csv导入到模型可选范围中,并选中对应数据集。下方图为操作示意图。
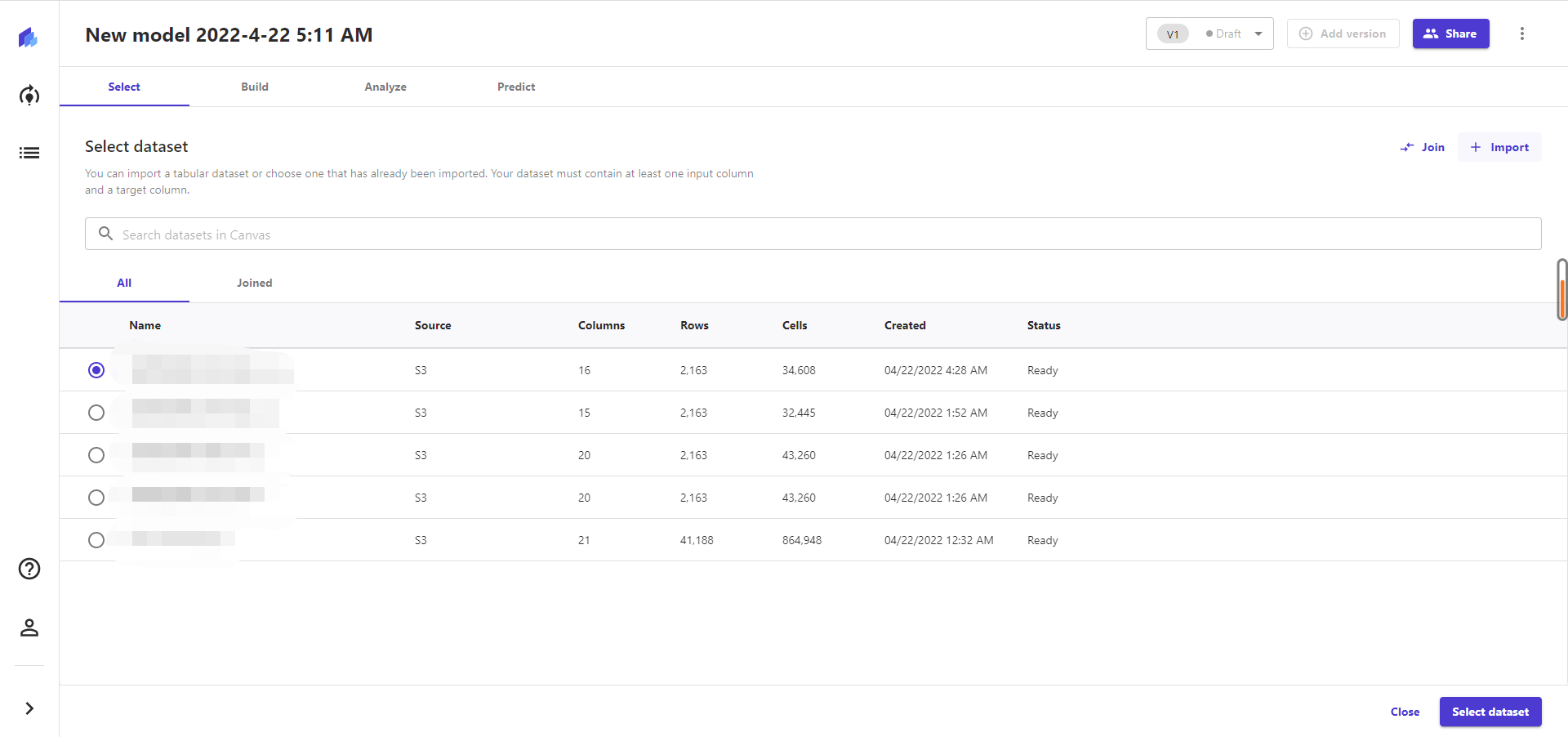
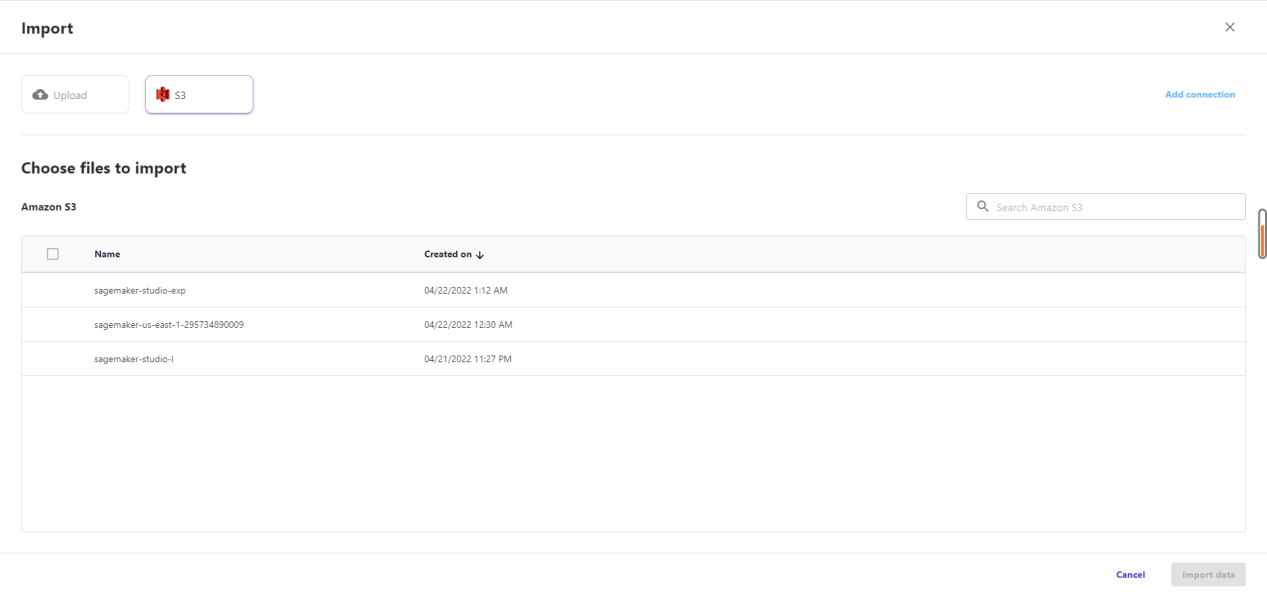
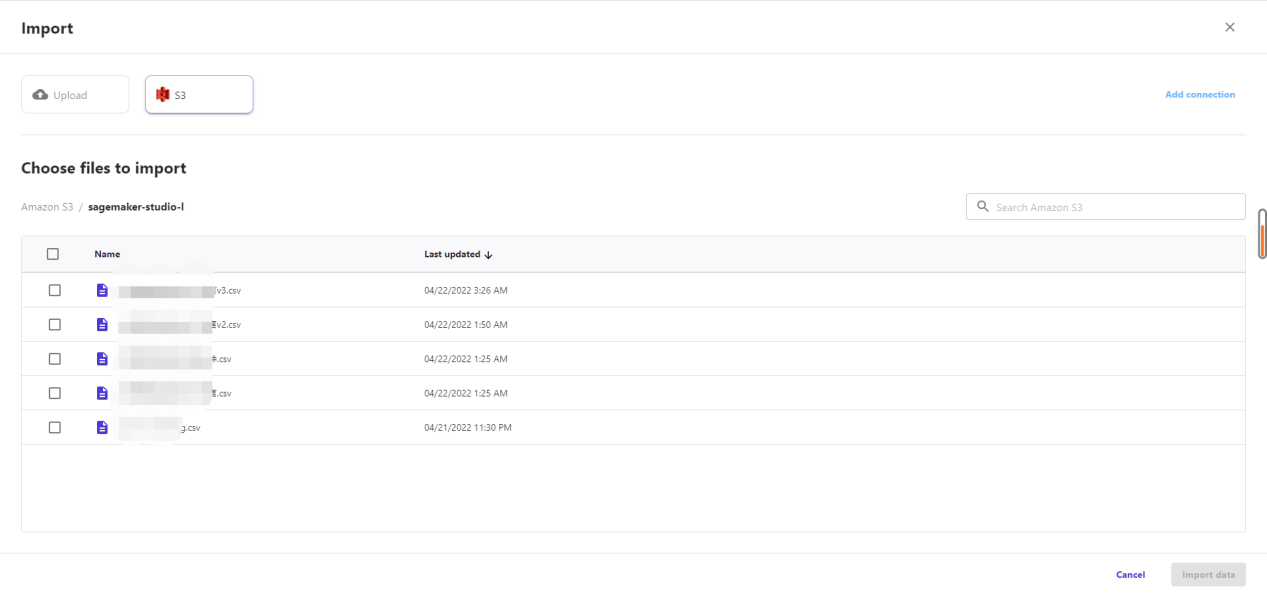
在所有都操作结束后,选择对应的数据集,点击“select dataset”来确定数据集。
4. 通过目标区分回归与预测模型
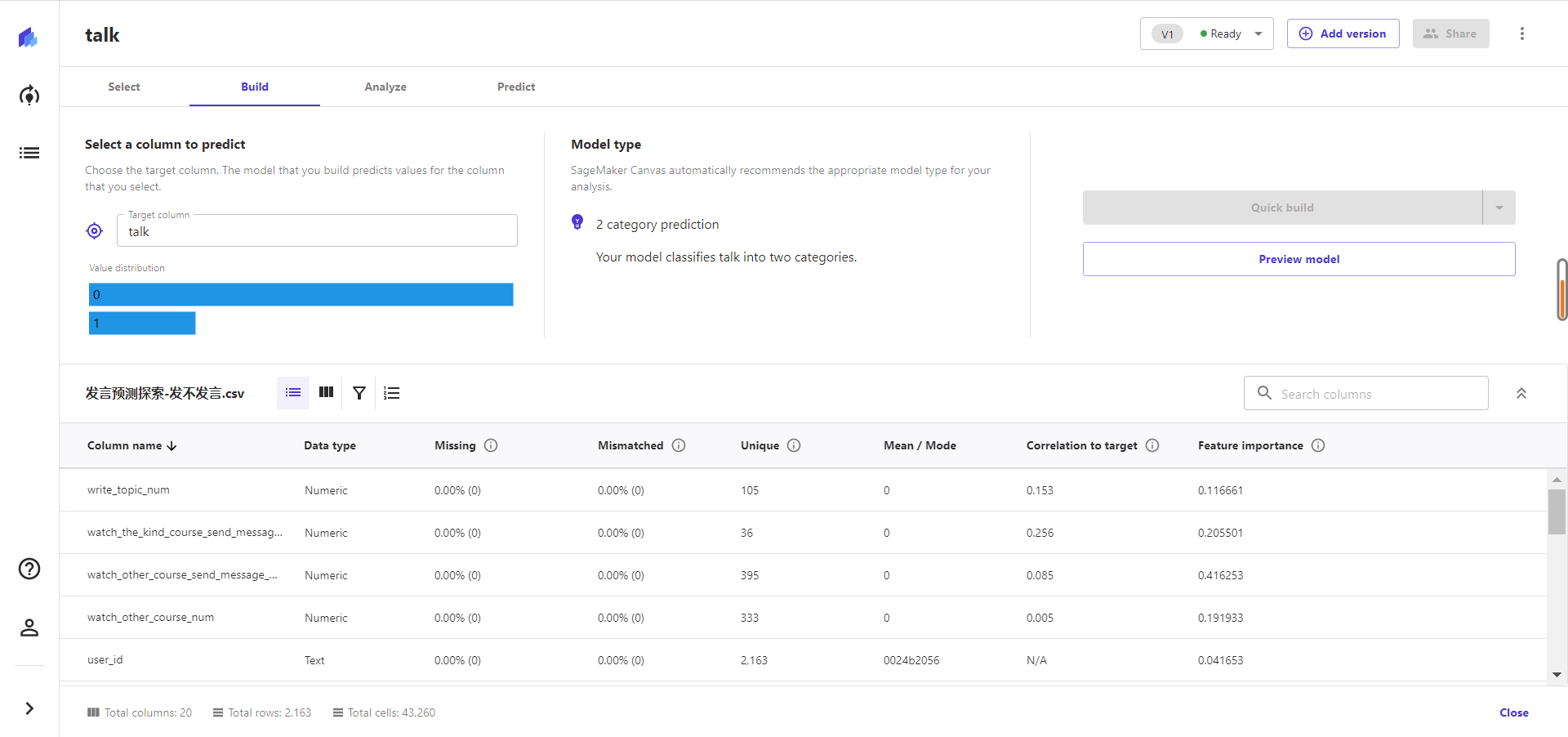
在我的数据集中,talk是这个用户发言or没有发言,再次明确一下这个目标字段的含义,在talk厅发言1min以上的为1,否则计为0。
在select a column to predict的栏目下,选择talk为最终目标字段。Canvas很智能地识别到了是二分类模型。
5. 建立模型
可以快速查看一下我们指标的情况,之后可以通过quick build快速构建模型,之后会自动定位到analysis页等待一段时间。
这个过程中我们只需要等待,别的操作是没有的。
6. 完成模型,回归结果
如下图所示,Canvas已经完成了模型模拟,并返回了准确率的结果。
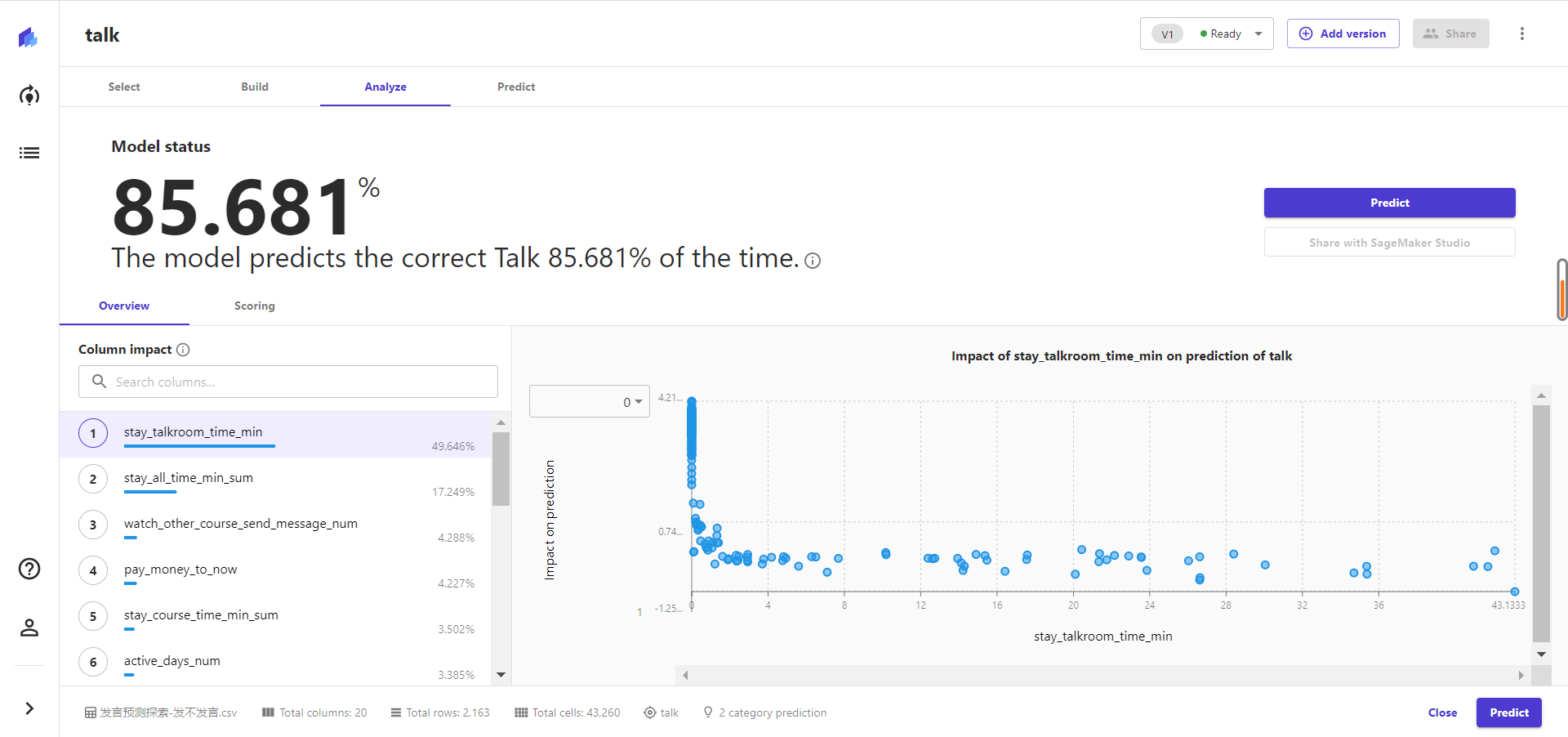
1)准确率概念明晰
准确度在85.681%,看起来是不错的情况了。但这里需要明确一个问题,什么是准确率?
机器学习中的准确率=预测对的个数/整体的个数。
我们这里举个例子。在这个实验中,假如有10个数据,6个是0,4个是1;而预测出的10个结果,6个0中预测出了5个0,4个1中预测出了2个1,那么这里的正确率就是(5+2)/10 = 70%。
2)不使用准确率作为评判标准的原因
Canvas也提供了准确率部分的查询。可以打开scoring的页面来看整个模型的预测情况。
在下图中,能够看到最左边的数据是400+的数据量,而在前文中,放到模型里的数据是2000+的数据。
这里就类似我们在使用机器学习中切分训练集和测试集数据的操作,切出来一部分用做训练模型的预测。
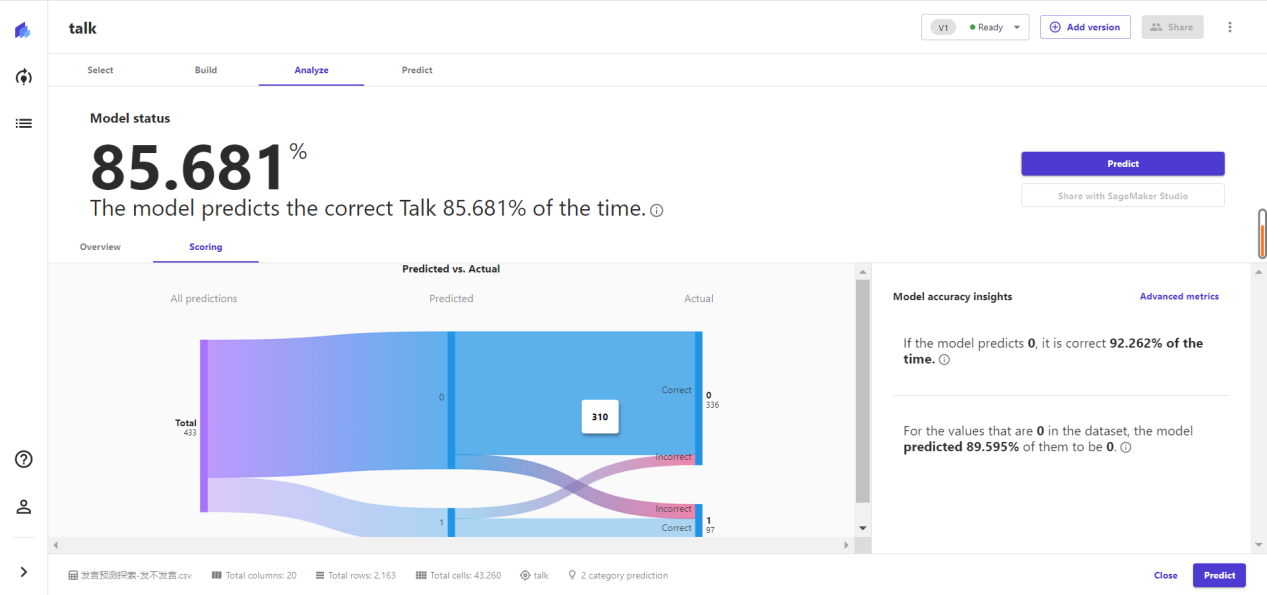
通过颜色与条状宽度我们可以分辨到1是个小部分,0是个大部分,但在预测错误的情况中,1预测为0的与0预测为1的这两种错误情况,图上的宽度看起来是相近的。
但这里有我们需要兼顾看真实的0和1的宽度分布,可以知道1预测错误的数量/实际为1的数量>0预测错误的数量/实际为0的数量。
所以可以很清晰地看到不均衡的数据用准确率的衡量方式并不靠谱。说个极端点儿的例子,1000条数据中,999个0,1个1,就算把所有都预测为0,也能保证其较高的准确率,99.9%。但在这种情况下,99.9%的准确率对我们实在预测时并没有什么用处。因为1才是我们希望准确预测出来的。
3)选择混淆矩阵作为评判依据
所以这里我们要用另一种方式来看,用混淆矩阵的方式来判断模型的好坏。当然Canvas也提供了查看混淆矩阵的入口。点击“advanced metrics”来查看混淆矩阵。
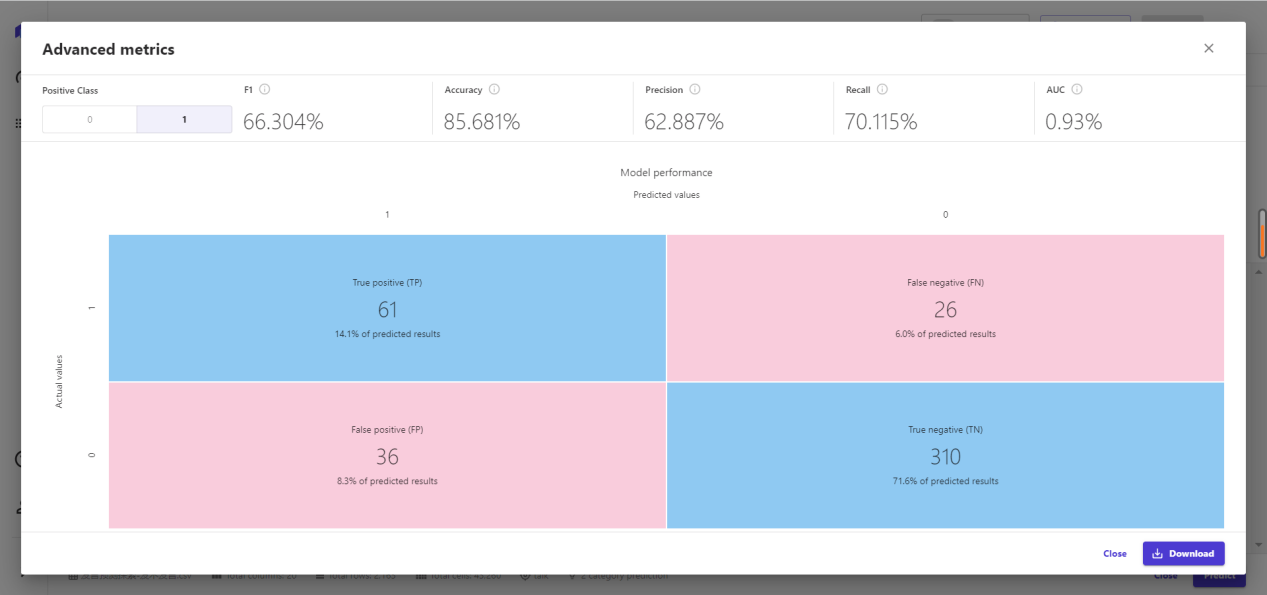
混淆矩阵中,我们需要定义什么是正例,正例就是我们期望的那个记过,在我们这个案例中,
因为我们要看到的预测人是发言的人,也就是talk = 1。于是在左上角“positive class”下选择“1”,那么我们可以很容易看到该模型在准确率与召回率两方面的情况,分别是62.887%和70.115%。都不是特别高的情况。
4)混淆矩阵快速理解
关于混淆矩阵,为了方便理解,通过一个小例子强调几个基本概念。
比如我们从一群人中通过数据预测出女生。
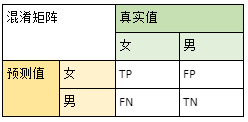
- 那么准确率就是TP/(TP+FP),这个值低就是把男生也预测为女生,说明把我们不想找到的也找出来了。
- 那么召回率就是TP/(TP+FN),这个值低就是把女生预测为了男生,说明把我们想找到的也没能找出来。
5)Canvas可以有更短时间有更高的模型效果
回到前面的案例,可以看到这准确率和召回率这两个都不是特别高的水平,低于80%。
那么这样的例子,可以说是Canvas的模型模拟水平不足嘛?
当然不可以这么武断地下结论。
因为机器学习模型的结果不行,有两种可能:
- 第一种是数据不行,所谓“garbage in,garbage out”。
- 第二种是模型选取的不行,每个模型都有其适用边界,表现的好坏。
当然这两个可能都没有办法完全断定。
但用另一种方法来判断,拿这个数据通过python做过模型,利用自己做的模型选择的算法选择了逻辑回归模型。下方的LR即为选择的结果。
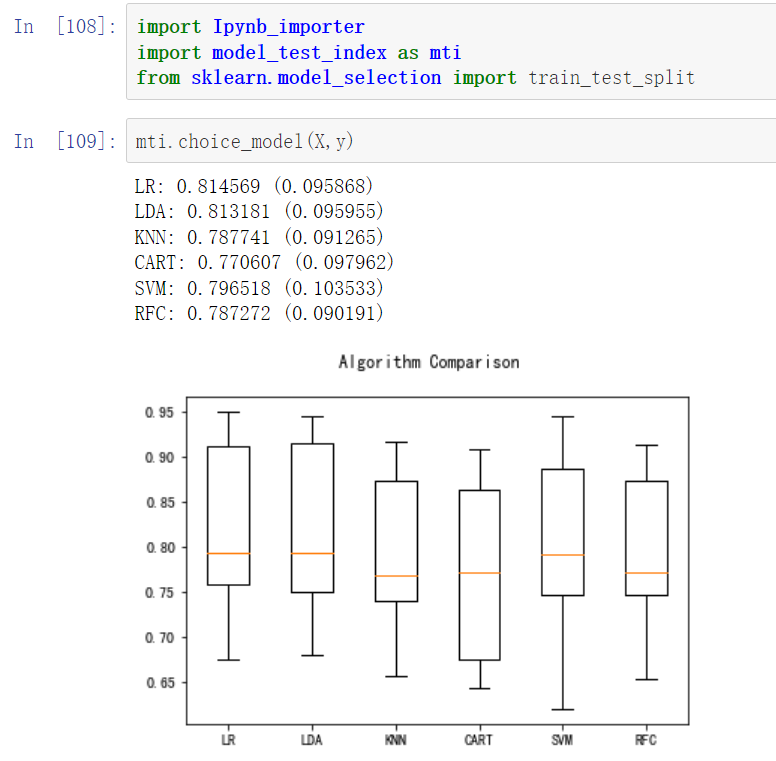
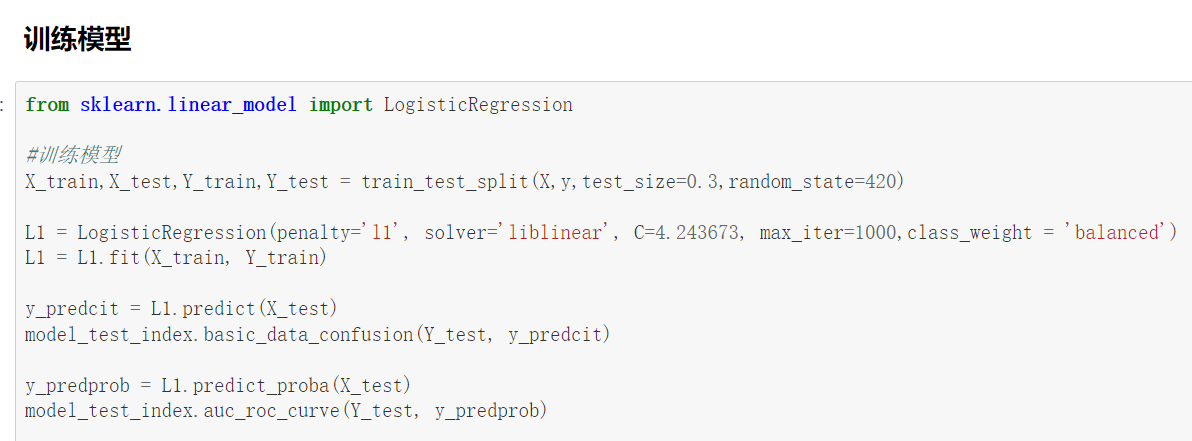
经过调参后,准确率60.85%,召回率65.84%。在不断调参之后效果并不如Canvas处理的好。
如果去使用Canvas的话,也就是消耗了1/10的时间与精力,就足以得到更好的效果,那么就可以大大提升日常工作效率。
回到上面的话题,通过这两次的比较,基本断定的是数据质量不高导致的。
需要对数据指标或者数据量需要有所改进。可以考虑:
- 用更多的指标或替换更有用的指标
- 更多的数据量来重新训练。
五、回归分析目标
那么回归最初的分析目标。
- 通过同学历史数据进行建模,能够构建预测用户发言与否的模型。
- 能够尝试确定哪些行为对识别发言比较重要,作为后续产品运营的一个考虑抓手。
1. 第一个分析目标回归
在第一个分析目标上,没有达成得非常好。但Canvas的结果比自己做的效果好,且时间更短。所以可以采用Canvas的结果,用Canvas建构的模型来预测后续的情况。
同时这里可以考虑两个迭代方向:
- 一个是在选择数据指标方面,能够思考找到更多逻辑上相关的可能数据指标;
- 另一个是在数据量方面,积累更多的业务数据来训练模型。
但是,在没有更好的策略时,Canvas的模型结果是一个当前可以考虑采纳的结果。
2. 第二个分析目标回归
在第二个分析目标上,可以初步找到需要关注的指标。
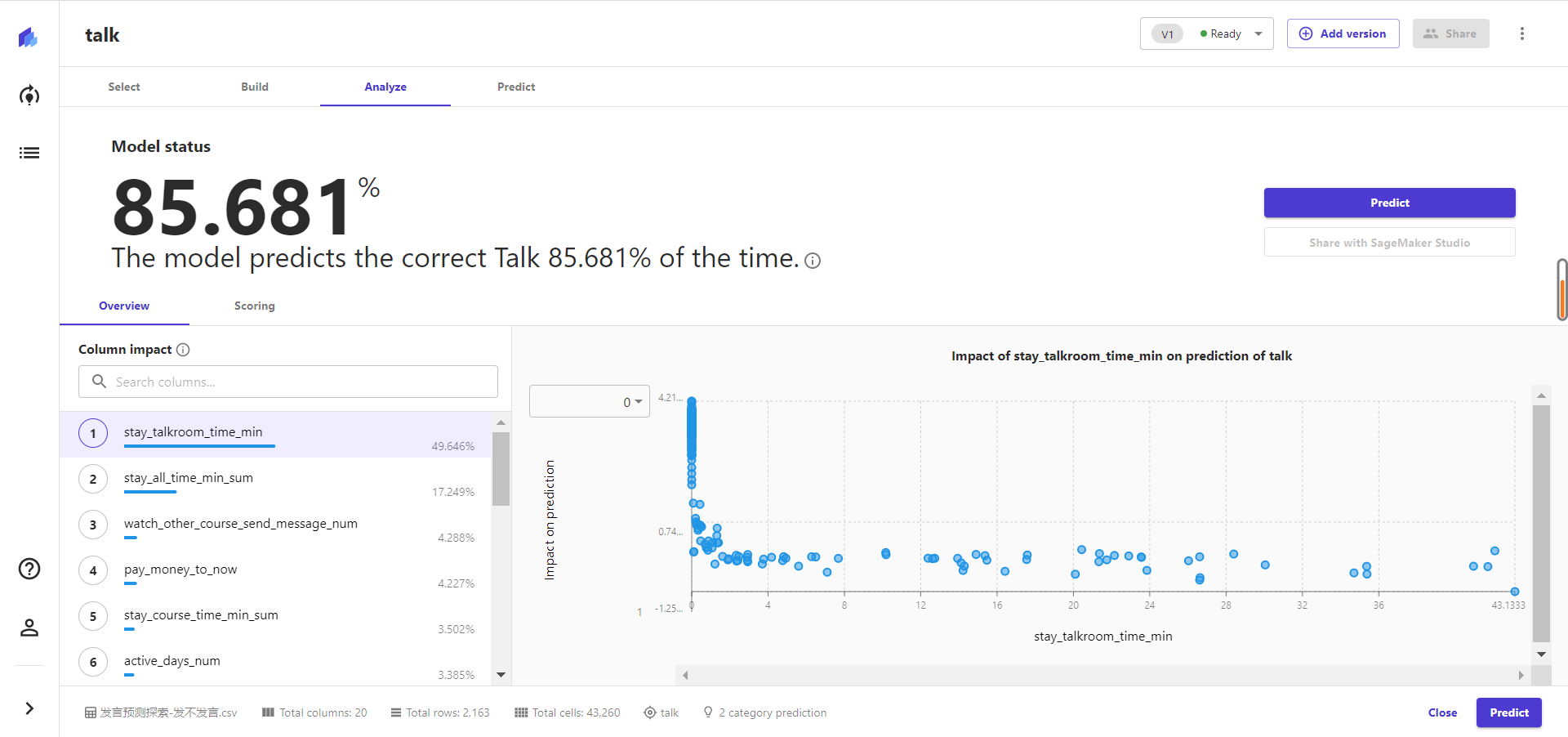
可以从这个左边指标影响程度上能够看到哪些指标是对预测发言情况有作用的指标。
前6个指标分别是:
- 停留在talk厅的时长;
- 停留在课程与talk厅的总时长;
- 看其他课程并发送消息互动的数量;
- 付费到现在的时间天数;
- 停留在老师讲课处的时长;
- 周活跃天数。
这些是可以考虑的前6个指标,但有个额外注意的内容,单纯地提升talk厅的时长是没有意义的,所以需要接下来去看什么与talk厅停留时长相关,那些停留时长更长的与更短的区别在哪些方面等等。
当然这些都是与业务集合推进的步骤,但确实是找到了接下来可以考虑的抓手方向。
六、期望与总结
在使用过程中对Canvas有两个期望:
- 能够连上公司的数据库,拿到数据更方便,这样能够更快去选取数据并构建训练模型。
- 能够将数据预测结束后的结果返回,例如有返回结果api接口。这样就能辅助后续线上的互动教育做到更快速又合适的分组了。
总结
Canvas是一个非常方便快捷高效的工具,它的好处如下:
1)简单快捷易操作,通过导入数据、quick build等快捷完成短时间高效果的模型训练。相比于自己模型写代码,训练模型且不断调参,Canvas达到更好的效果也就消耗1/10的时间。
2)因为模型的效果更好,训练速度更快,可以在特征工程做完之后,快速对数据情况有个把握,这些数据能够训练到什么程度。当然没有特别好的特征工程处理的话,就可以用逻辑缩小范围,不断构建模型尝试,找到最合适的用于分类的要素。
3)能够在模型结果输出后,得到模型中的指标重要性,可以考虑作为相关的抓手要素.
作者:李猛
本文由 @三法 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于CC0协议。









看到最后再想到自己的粗略分析就笑了,不愧是得一等奖的牛神。。。。还是得细致出功夫
一篇手把手教你如何使用Amazon SageMaker Canvas工具的文章,感觉可以有效提高翻转课堂的效率
哈哈哈哈作者分析的很是专业!看标题我以为是可画,结果是这么高级的东西