起点课堂会员权益
起点课堂会员权益数据驱动业务增长:如何做转化意愿预测?
编辑导语:在日常业务中,数据分析可以帮助我们挖掘业务增长点,提升转化效率,等等。那么,如何结合一款0代码机器学习智能工具实现数据分析?本篇文章里,作者结合Amazon SageMaker Canvas这款工具进行了转化意愿预测,让我们来看看他的体验评测吧。

引言
“数据驱动业务增长”是以业务线全链路海量数据的收集、存储、可视化、分析、挖掘作为核心支撑的,需要协同上下游参与且目标一致,最终将数据精准化、精细化为实现商业目的。
一、业务背景
1. 业务介绍
本产品主要是挖掘孩子的综合素质,覆盖思维、英语、语文等能力,帮助孩子在认识世界、探索世界的同时,打好全方位的能力基础,陪伴孩子共同成长。
2. 商业模式
通过低价课吸引用户,经过一些列课程培养和体验服务,最终转化成年课用户。
3. 分析主题
转化分析。
4. 现状痛点
- 营销运营的目标不够清晰和聚焦,人效较低。
- 很难快速掌握用户转化的核心痛点,转化率不高。
5. 分析目标
目前属于发掘的新业务,所以业务需要在招生分析的链路上,想要通过一系列的全面复盘和分析,核心提高转化率。
二、分析思路
所有的分析思路都应该以场景作为切入点,以业务决策为终点,因此本次项目梳理了五个步骤:
- 挖掘业务含义
- 梳理用户行为路径
- 拆分场景特征
- 构建模型预测
- 推动数据决策
1. 挖掘业务含义
用户旅程图:从用户角度出发,以用户调研和业务场景中发现用户在整个使用过程中的痛点和满意点,思考产品的增长点。
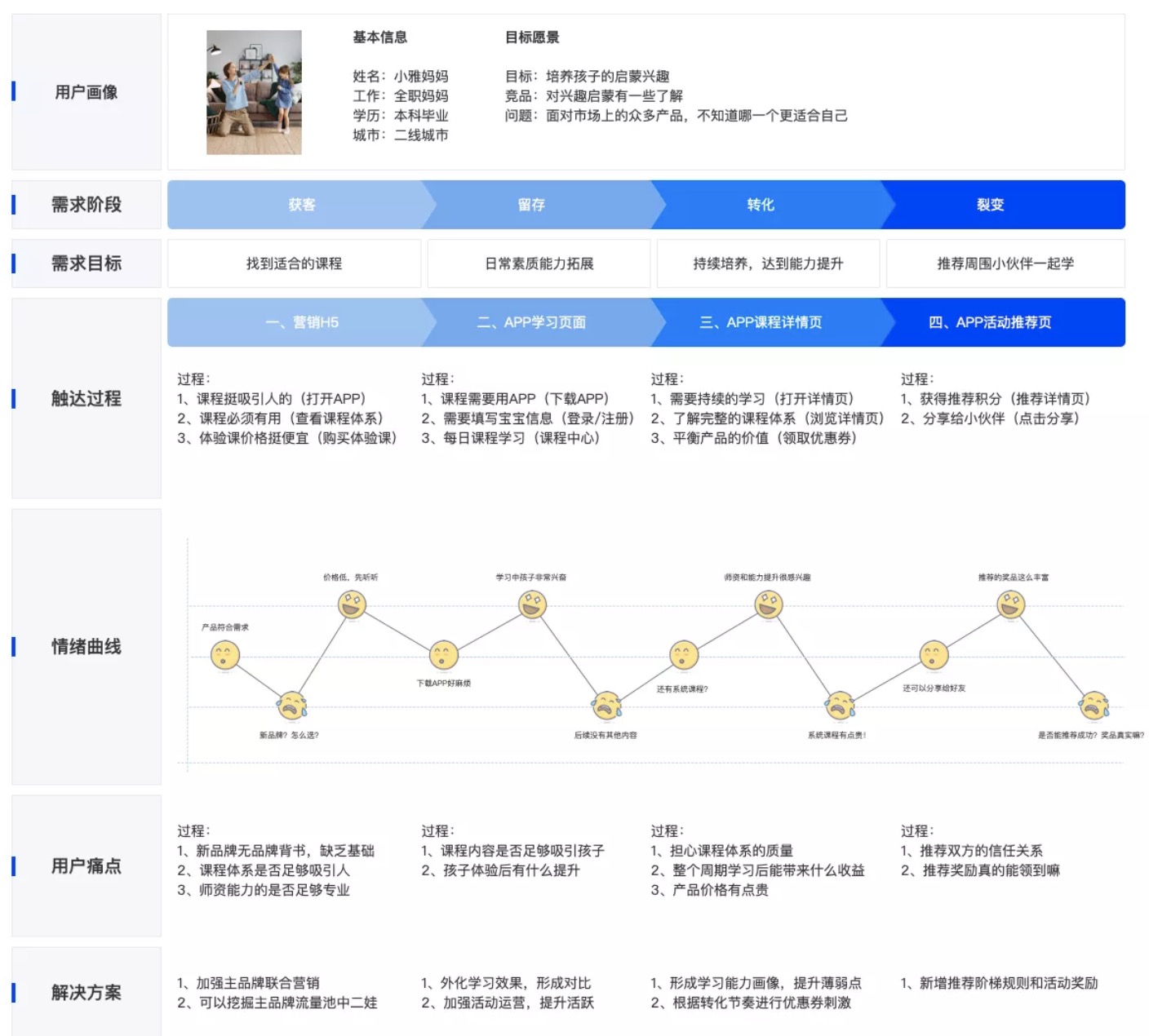
2. 梳理用户行为特征
1)路径拆解
在用户旅程的大框架下,通过对用户行为数据的采集,监测获得的数据进行分析可以让更加详细、清楚地了解用户的行为习惯,将他们的目标、需求与商业宗旨相匹配。
2)用户行为
根据用户旅程的体验中,可以把用户分为三个阶段,其中包含:获客、留存、转化,每个阶段的衡量反应出的分析目标和逻辑则不同。
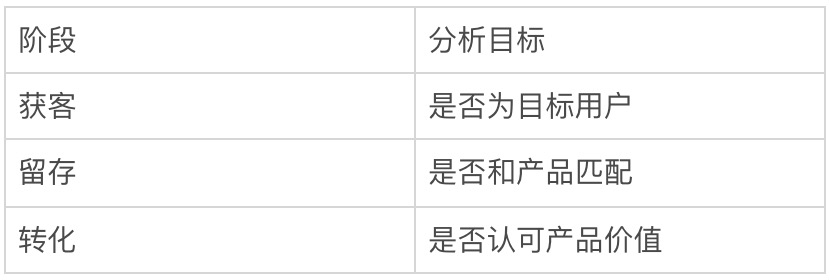
3. 拆分场景特征
1)相关性分析
主要用于研究用户行为事件的发生对转化的影响程度,针对这一行为特征进行相关性分析,确认导致该行为的影响因素和影响权重。
2)梳理特征(定义数据集)
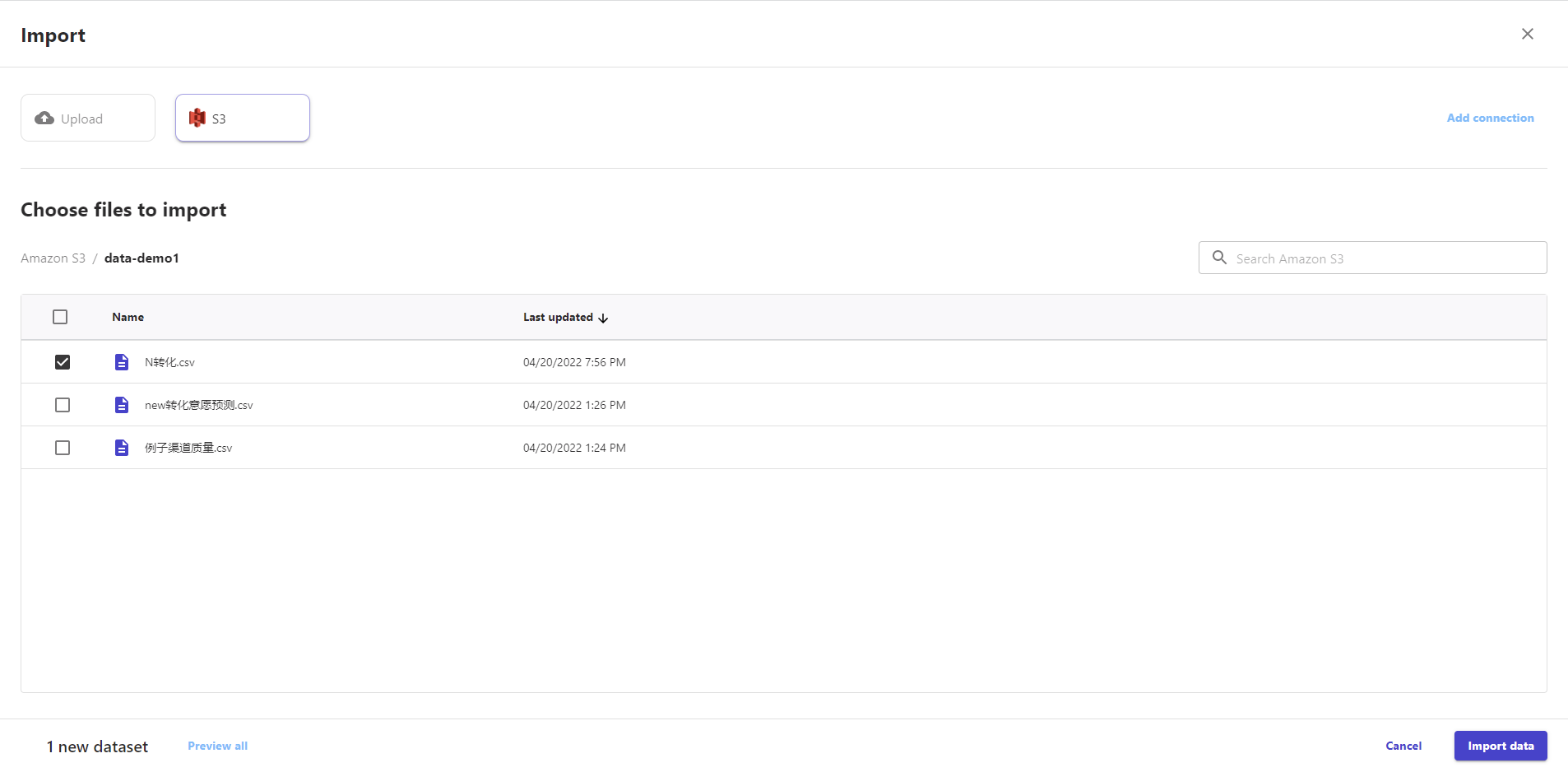
涉及到原始的数据源,我们需要在亚马逊中找到S3的存储桶,将数据源文件传输至此。
数据源(行为特征):第一版本共梳理了70+特征因子,这一版本是通过产品和业务的直觉梳理和转化有的相关性,通过模型在去做筛选和相关性分析。

S3存储桶:亚马逊的数据源需要借用S3存储桶服务。
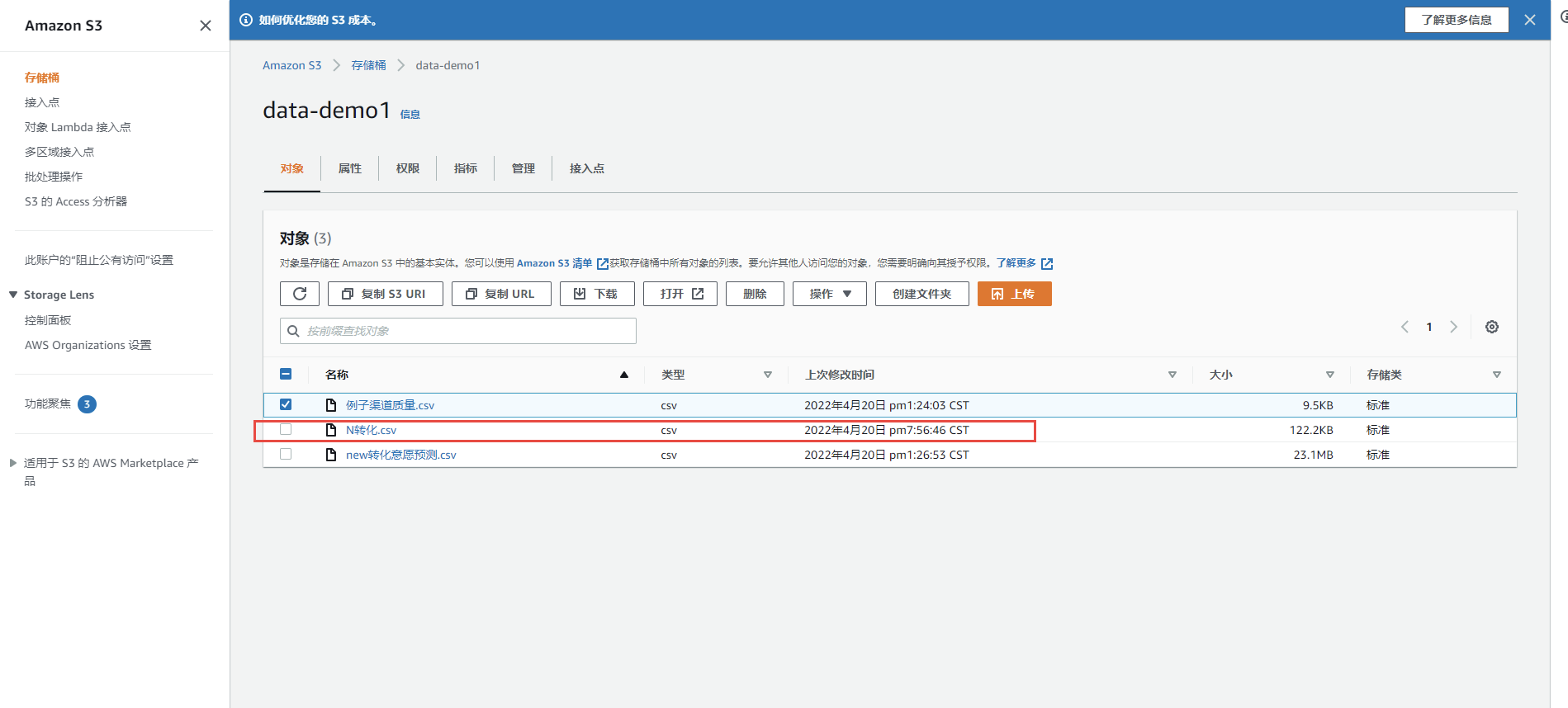
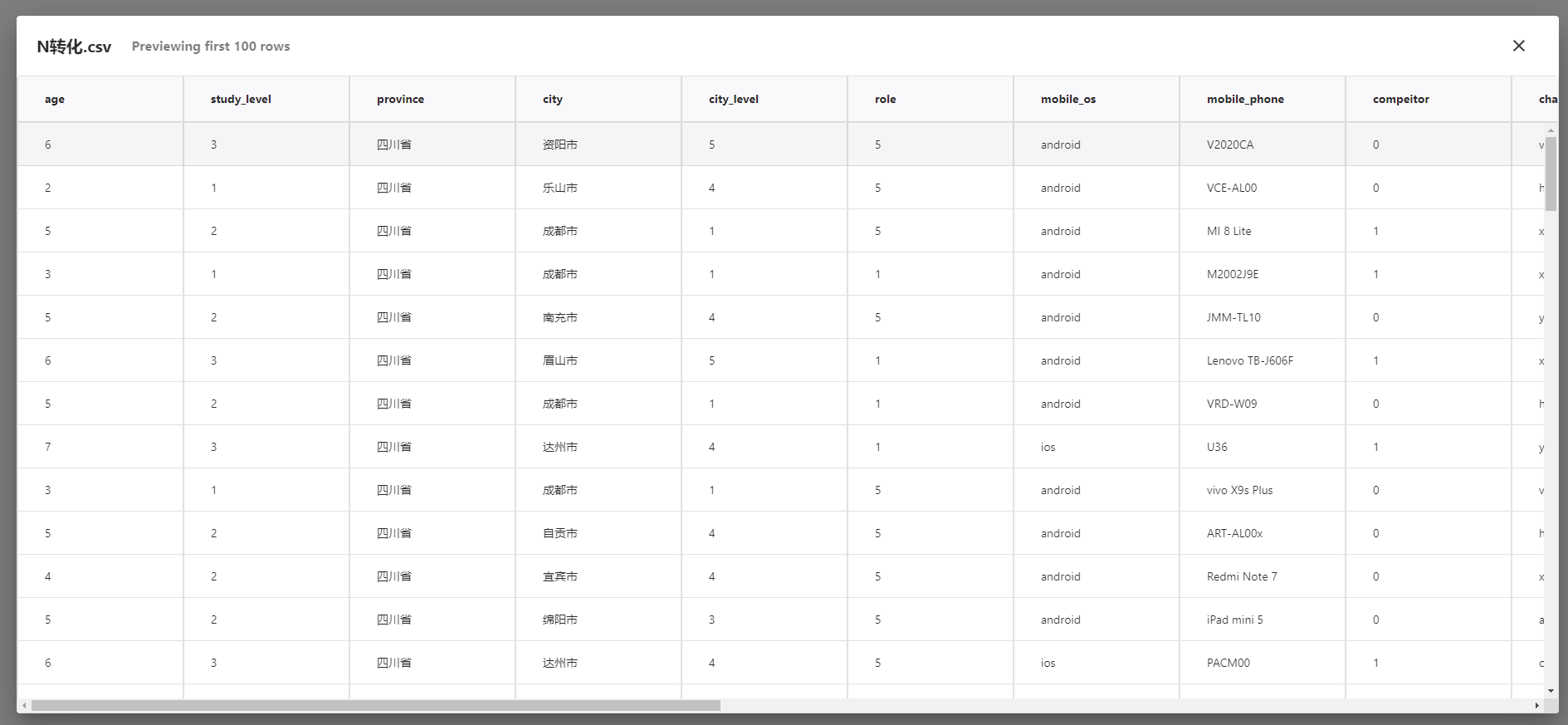
数据集:S3存储桶中数据源可以直接同步至画布的数据集,并且可以针对数据预览数据,这点两个功能点很棒,因为正式预览才发现数据源乱码的问题。
三、构建模型预测
1. 构建模型
第一步:直接就选择上传的数据集就ok了,这一步非常的简单。
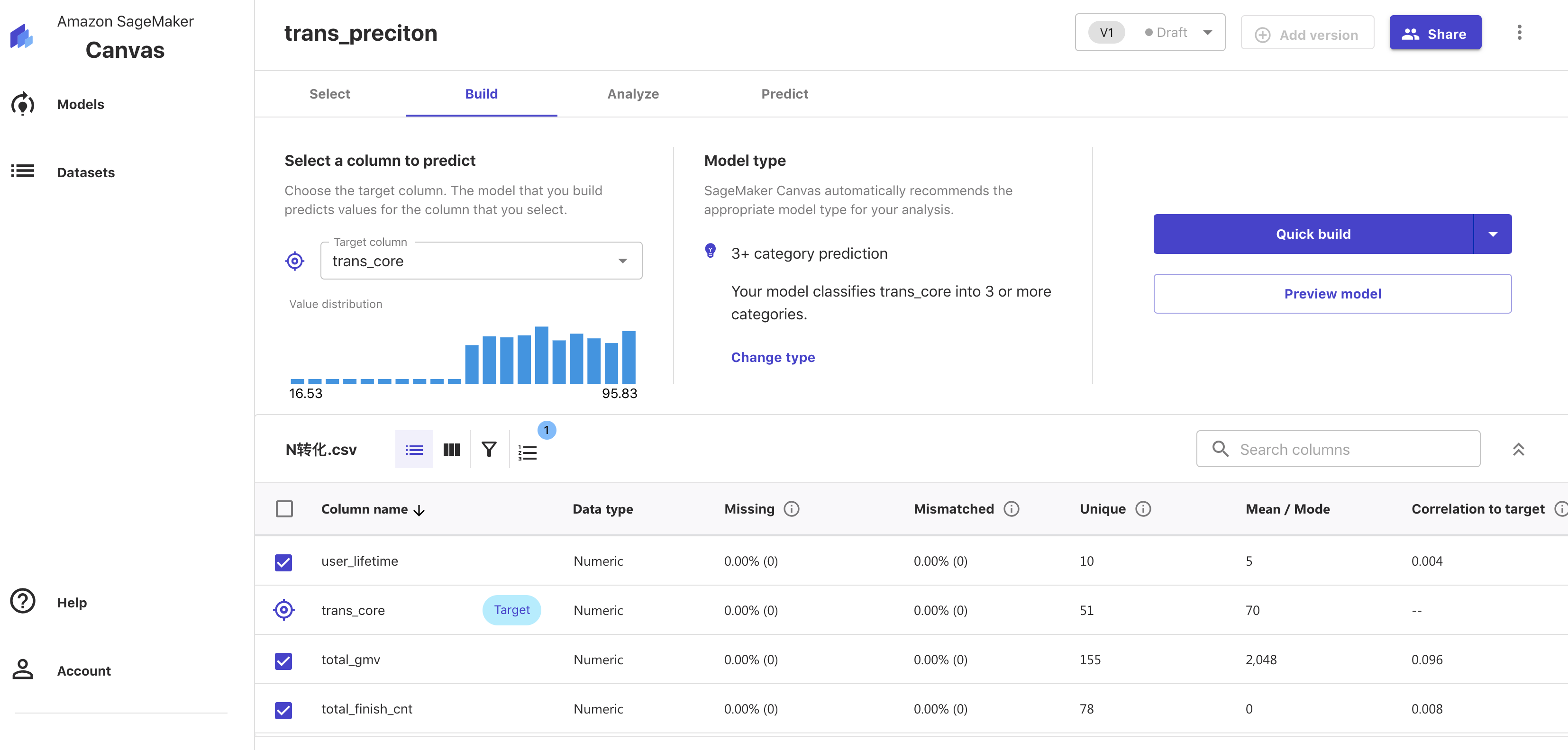
第二步:选择预测的指标很好理解,关键点在于模型的选择,转化预测本质是一个二分类的问题,预期是0-1的一个概率值,实战中选择的【xgboost】模型进行预测,通过和转化率强相关的因子和转化预测分层进行后续的营销策略。
这里的模型选择会根据我的数据集推荐模型,也会有一些内容的引导,不过other的模型有的不可选择,所以默认使用推荐的模型,看下初次效果。
还没有建模时候可以简单对目标的相关性做个分析对比。
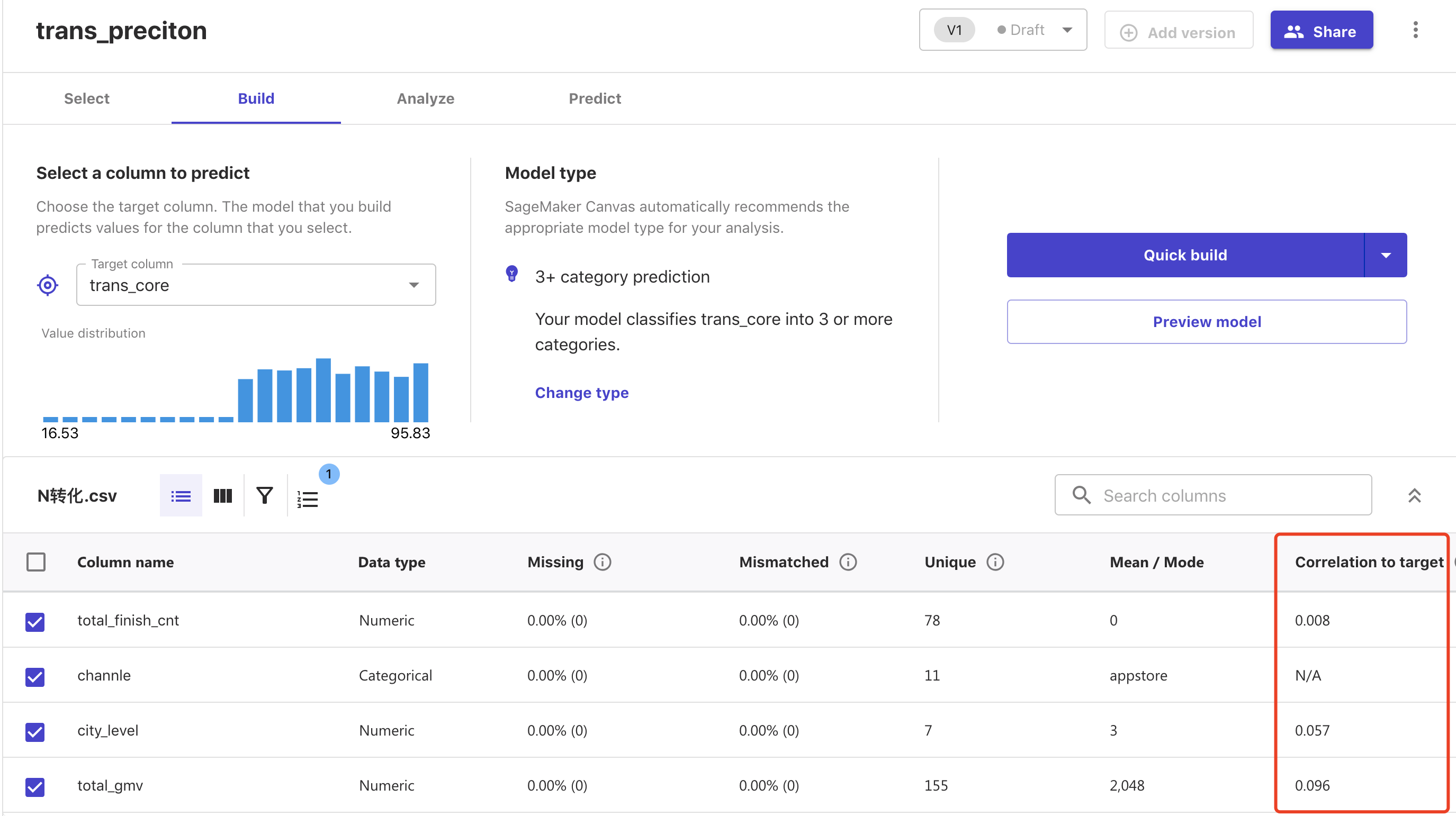
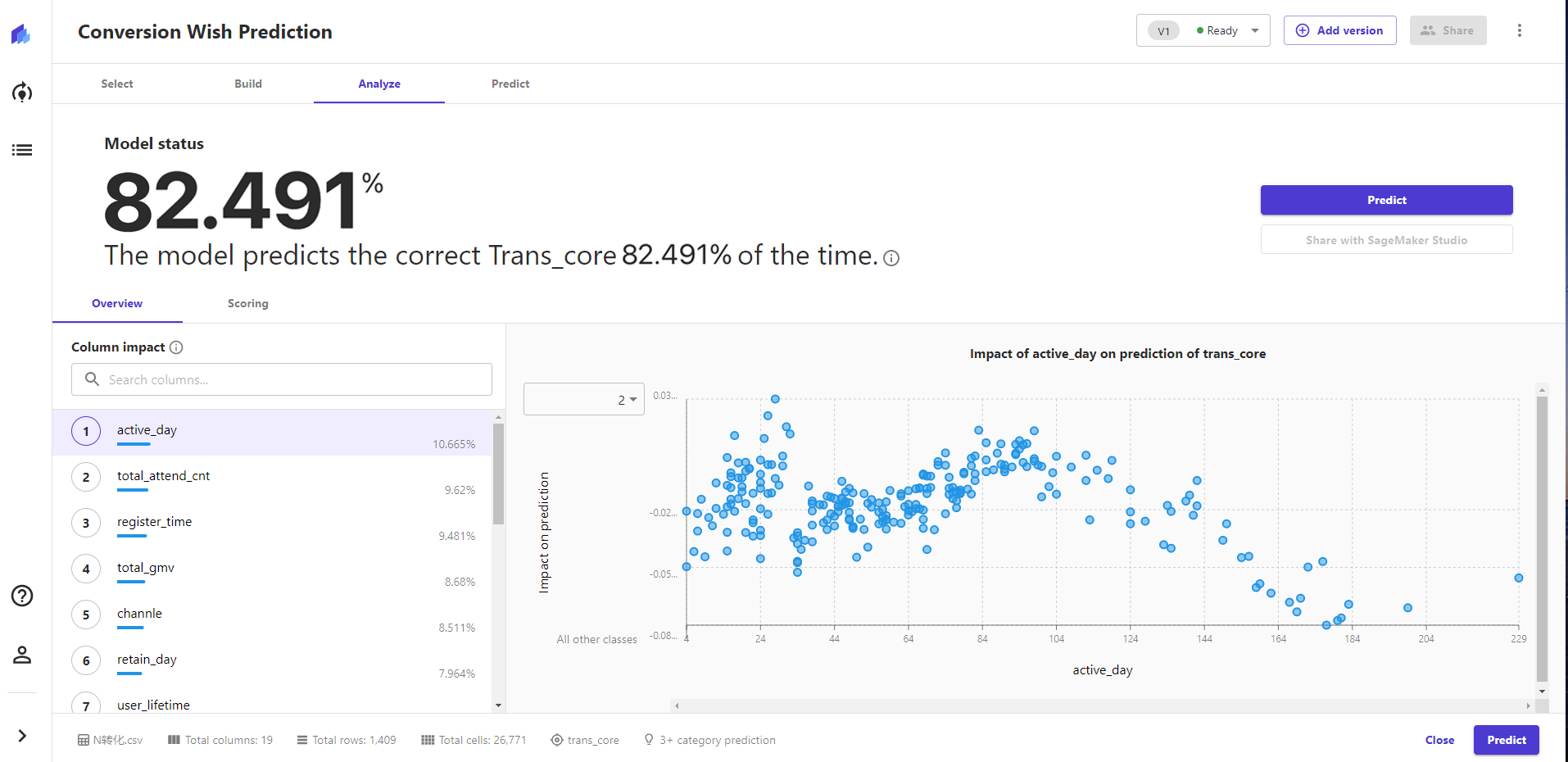
2. 模型表现
1)模型能力
处理速度:模型个处理速度在耗时3min左右,还是蛮快的,比较超出预期。
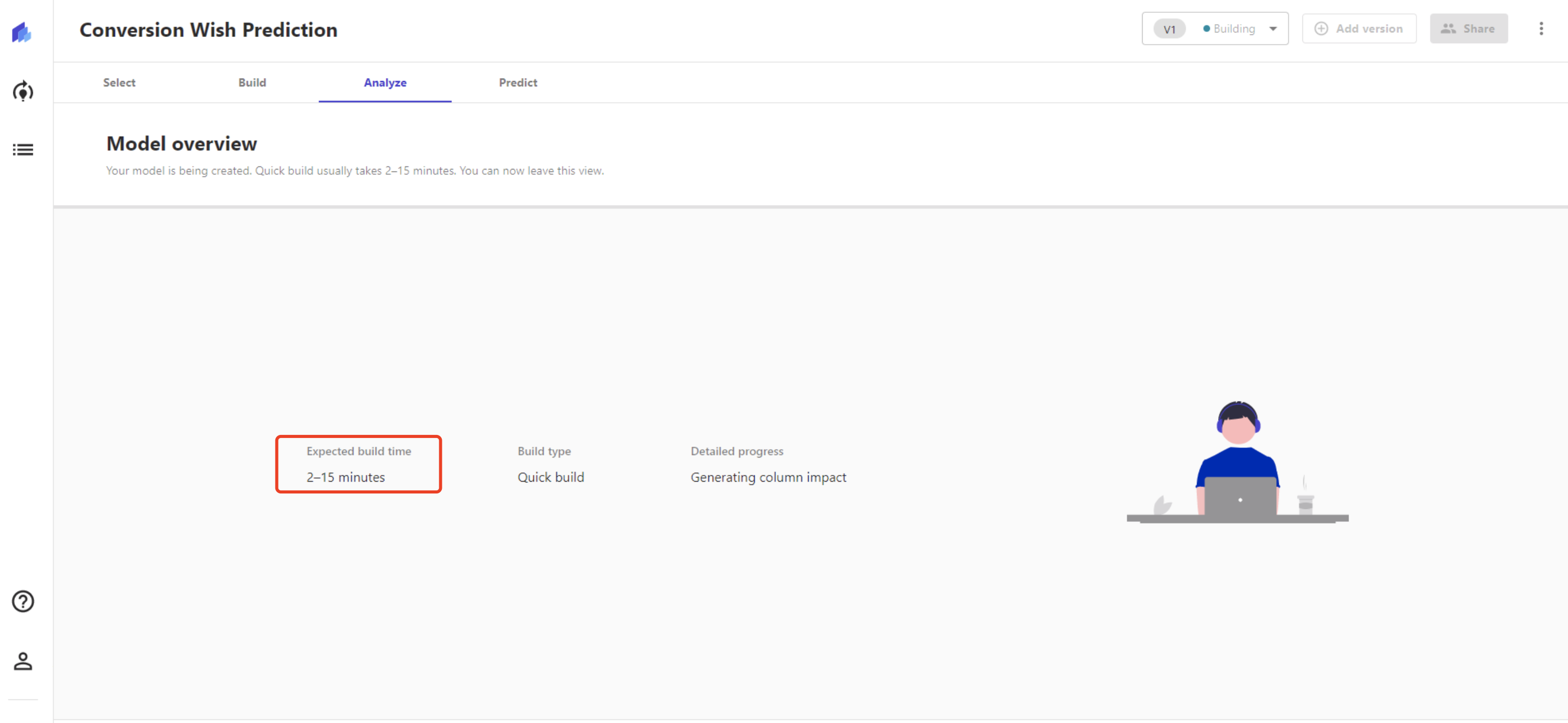
模型得分:模型分数和预期(70-80)相比会较高一些,可能由于数据量级较小,造成数据得分偏高;自建模型训练环境中的F1=0.78、AUC=0.85。
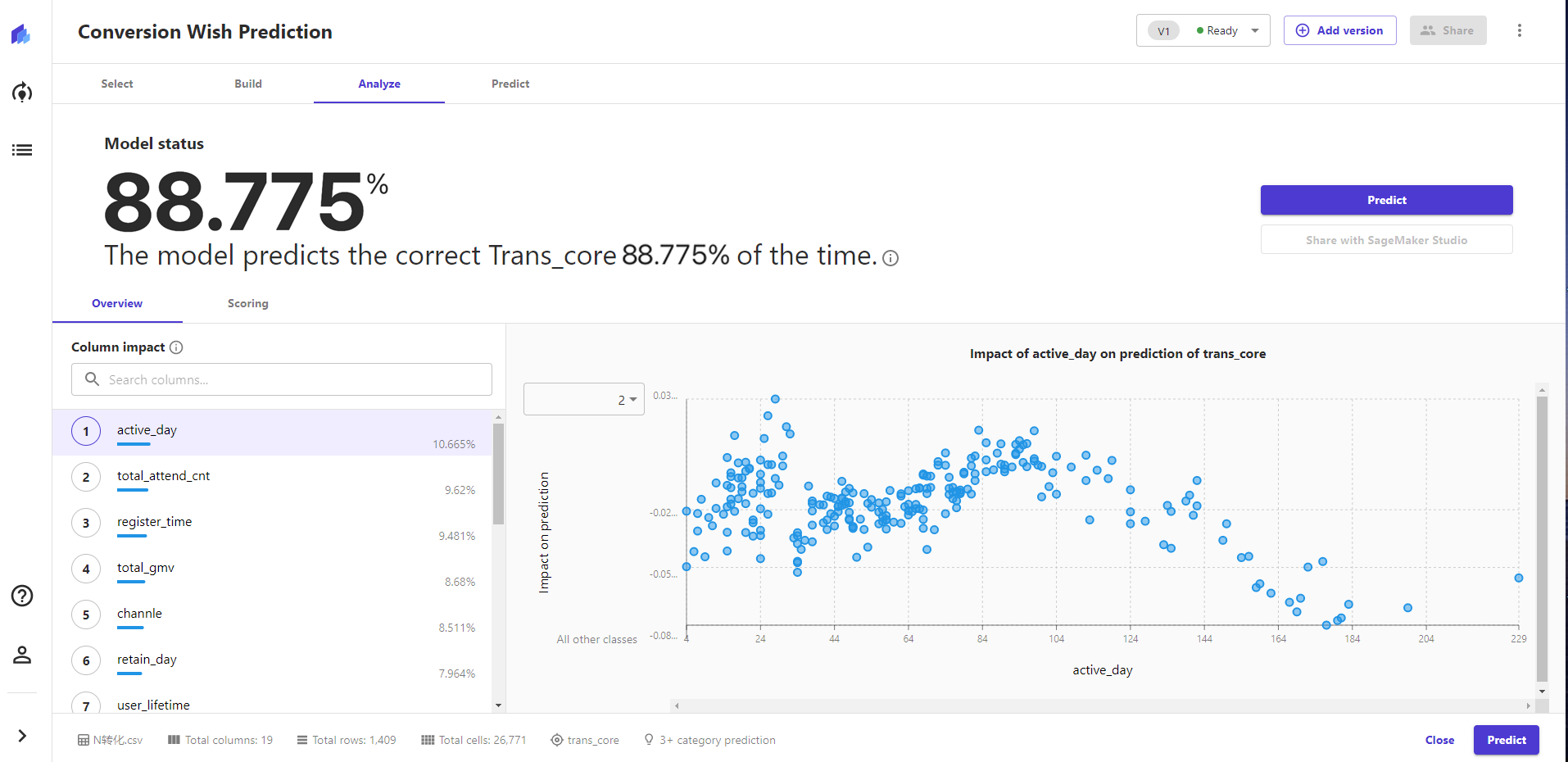
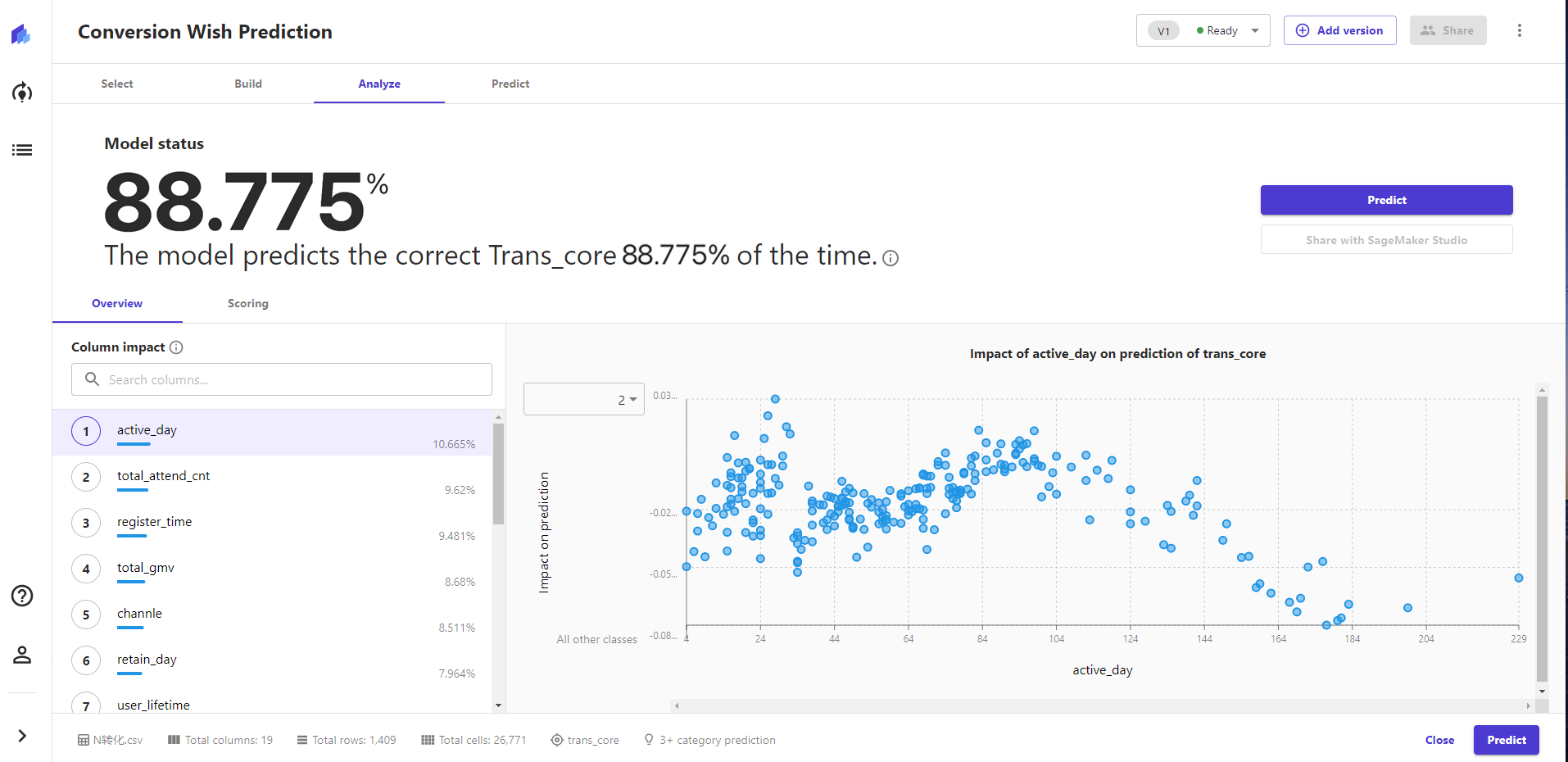
特征分析:这个可以根据转化意愿分值进行查看指标的影响和分布,这个功能是非常棒的,在数据产品视角对模型分析师偏概览的,这个可以细致的挖掘更深层的理解。
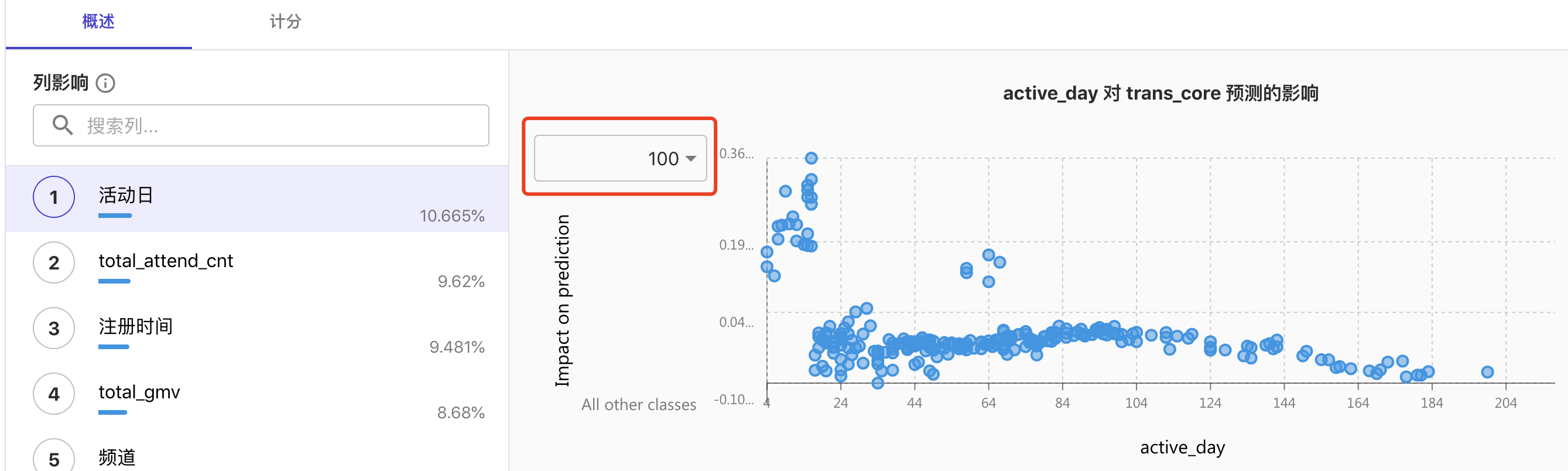
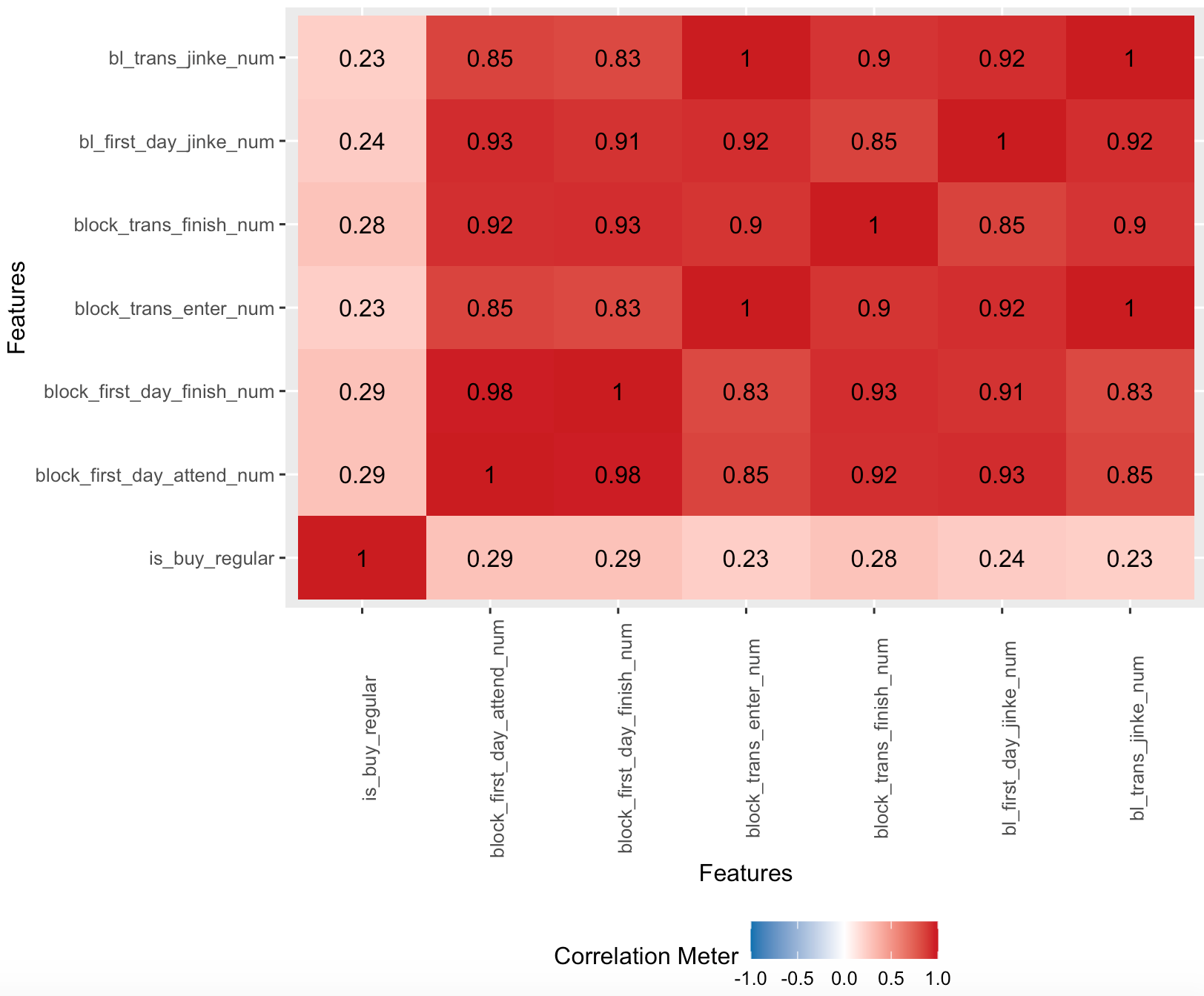
2)特征相关性
根据初次筛选,得出一些和转化有显著相关性的指标因子,并且可利用分布情况,分析背后原因。
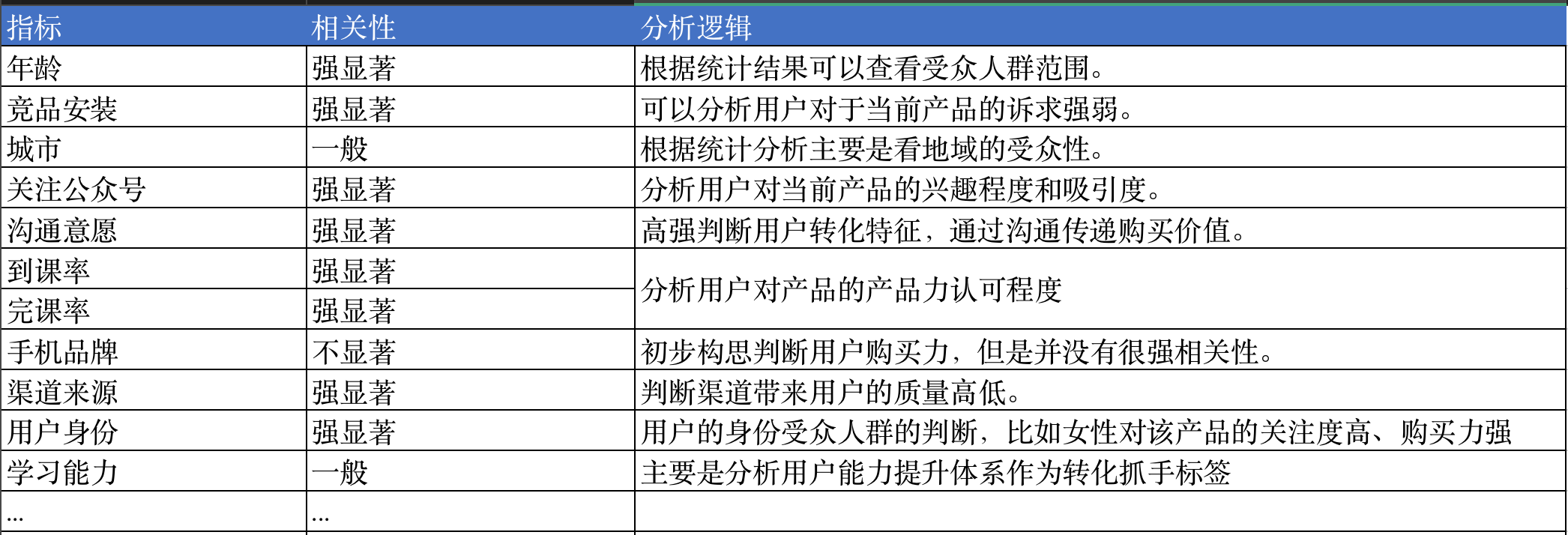
显著相关性概览:根据是否显著相关性整理一部分比较有趣,可以看出有一些认为有影响因素的其实问题并不大,有的标签其实和转化这个点关系并不强烈,但是可以作何核心的营销因素。
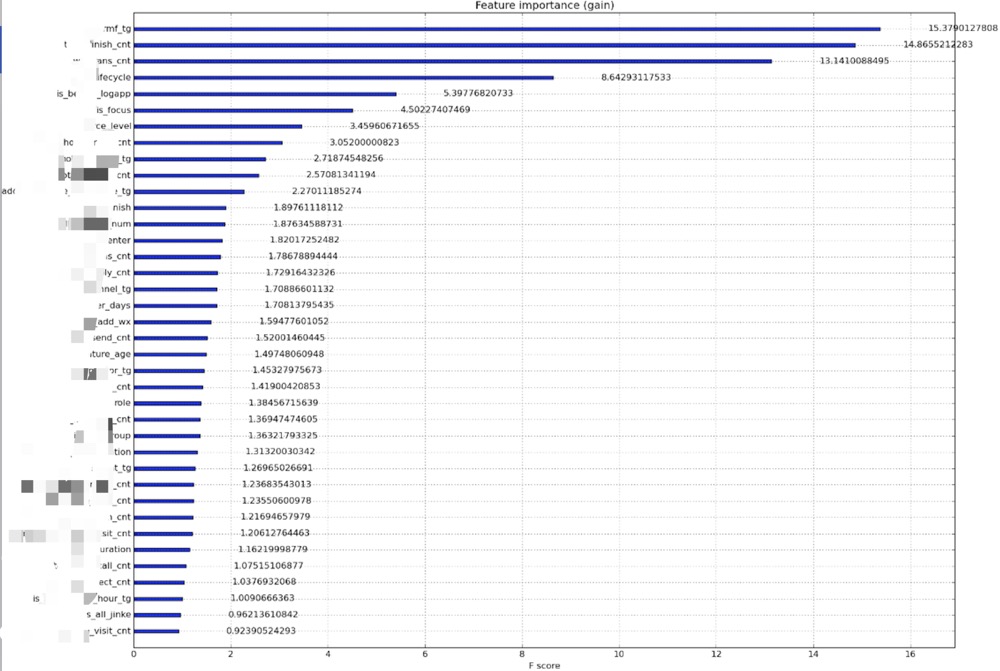
3)相关性排行
根据相关性整理了分值排行,更能直观看到哪些影响因子的重要程度。
3. 数据分析
1)分析理论
- 卡方检验:着重观察值与理论值的偏离程度,选择的考虑主要是基于特征的二分类问题和相互独立事件居多。
- 斯皮尔曼相关性分析:核心针对两个连续性变量且成线性关系,所以需验证其相关性。
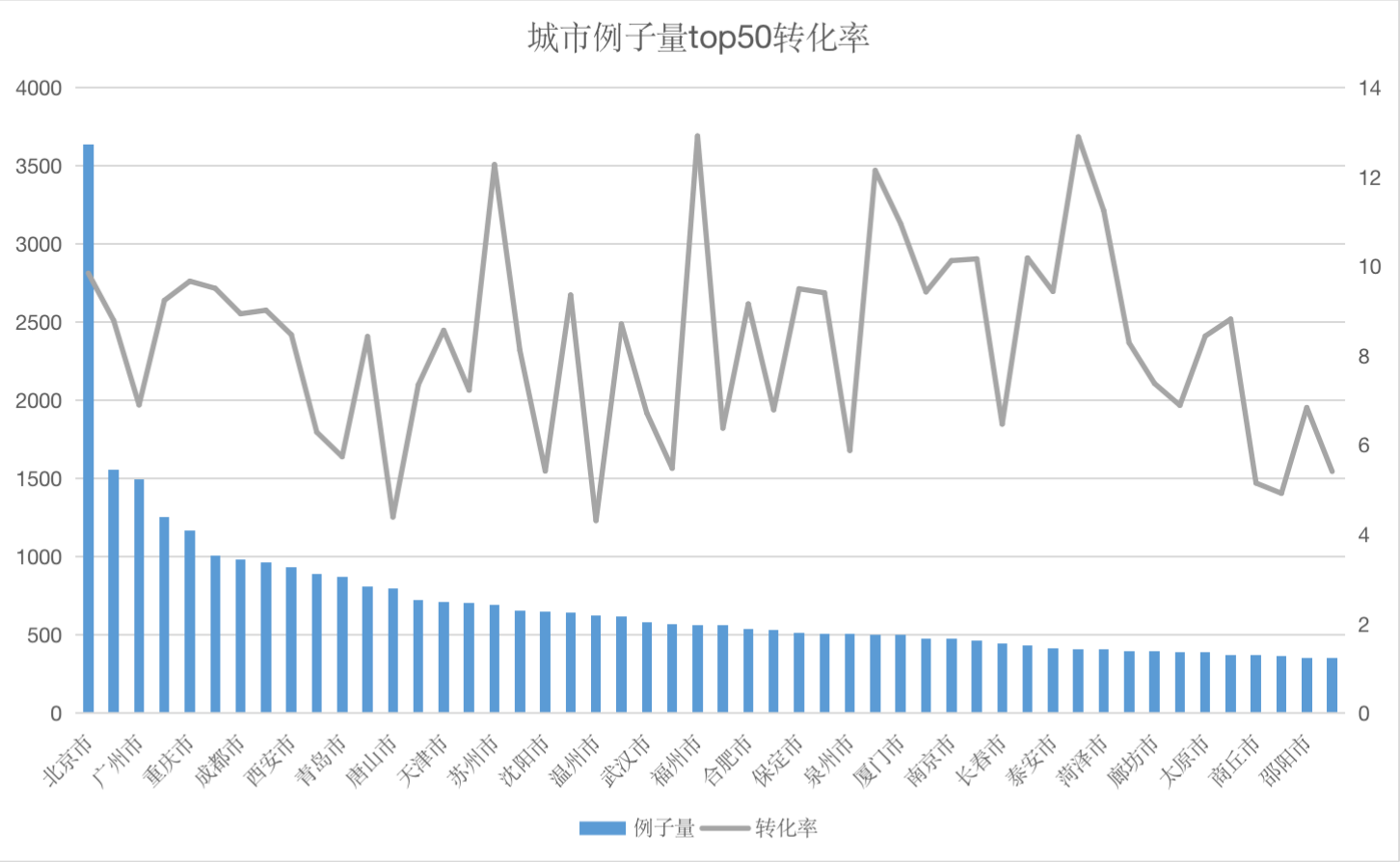
2)地域分析
从地域人群量级和转化率上来看,整体手中人群集中在二三线城市,所以在产品的投放和布局中,需针对等级进行策略规划。
3)竞品分析
卡方校验非常显著,从此指标可以看出,用户安装了竞品,直接可以筛选到核心的种子用户,因为该用户对此有强烈的潜在需求。
4)留存分析
这里的留存主要指用户来学习的次数,分析图标看,用户持续学习提现出对产品课程的认可性,非常有利于后续营销转化。
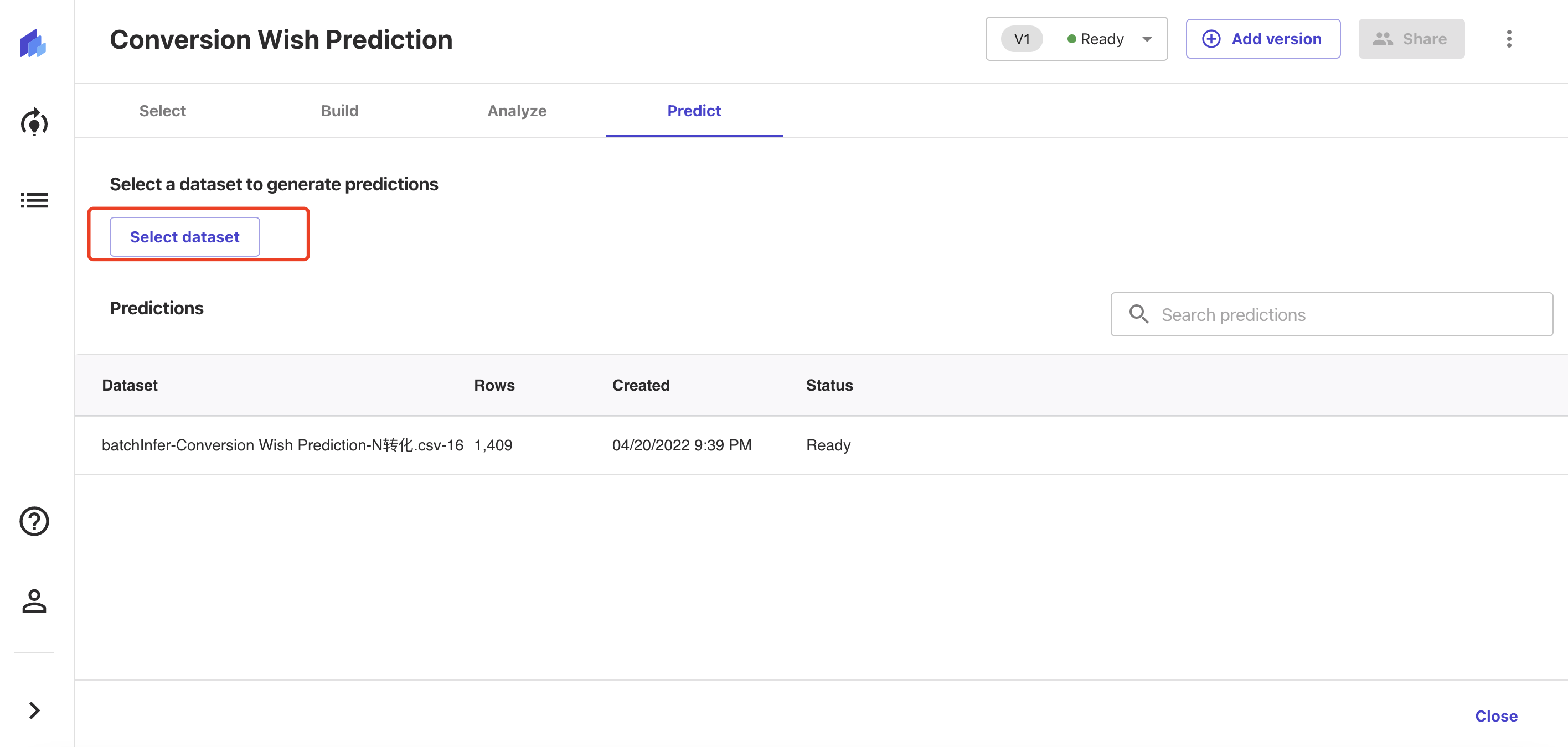
4. 训练模型
1)持续训练
防止数据量稀疏和数据量较小(试用最大100w单元格),所以需要加大数据源的量级,加强预测能力,防止结果的偶然性。
2)模型调优
- 调整不合理指标,防止特征穿越(比如浏览产品详情页,这种标签穿越特别严重,其实在模型中做预测是不太可取,反而可以成为营销策略的用户标签)。
- 对模型进行合理的剪枝规则,增强模型可解释性(针对特别明细标签,进行归因和聚合)。
3)预测模型
重新上传一组数据对模型进行预测,通过预测结果和本地训练集进行比对,准确率在70%左右,整体来说已经不错了,后续可以加大投入力度进行验证和训练,尤其是双向结合的方式,效率会大大提高。
四、推动数据策略
数据分析也好、数据挖掘也罢,只是实现商业目标的手段,真正想赋能业务并且驱动业务,一定要从实际场景触发,找到切入点。
策略一:提效
1)用户分层
根据用户的转化意愿预测值,进行用户分层,形成营销SOP清单,可以针对中高意愿以上的的用户进行精准触达,对于大部分销售人员可以减少人工判断成本,优先触达转化意向高的用户,合理分配时间和触达深度,并且可以制定标准的SOP动作,大大提高运营效率。
2)价值收益
提高了80%的人效,人效主要针对单个销售服务的用户比值。

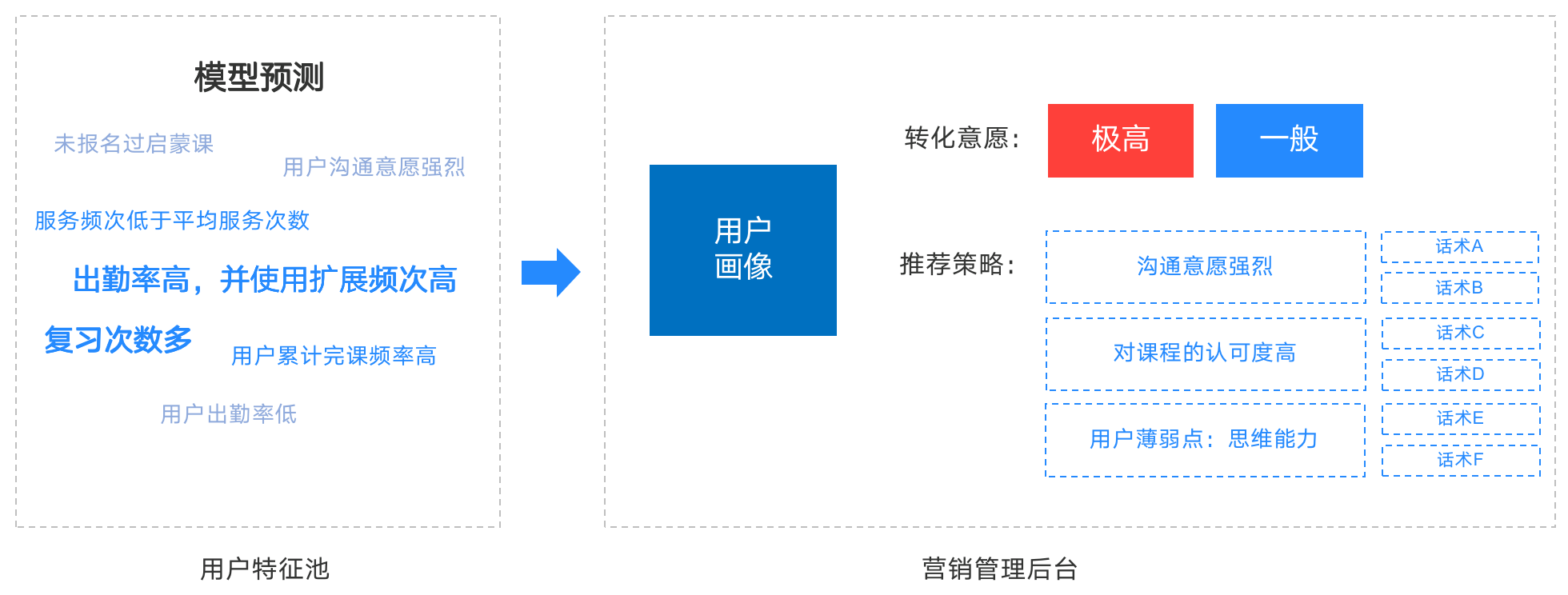
策略二:抓手
1)用户标签
在营销工具中实时更新用户的高意向标签(沟通意愿强烈)或者策略标签(学习能力画像:中),可联动知识库进行组合式营销,为用户解决痛点,提供优质的服务。
比如:用户的能力画像中“思维能力”薄弱,那么可以根据用户在学习过程中哪些思维题做的不好,引导用户如何针对性、系统化的提升,解决核心痛点。
2)价值收益
提高了15%的转化率,转化率=购买年课用户/购买体验课用户。
五、参赛总结
1. 产品体验
1)用户体验
① 产品设计
样式上紫色的主色调非常符合当前互联网人的视觉喜爱,紫色本来带有一些神秘感觉,在加上机器学习的加持,整体样式设计很足,而且紫白结合很干净和简洁。
② 产品交互
体验流程很顺畅,用起来很方便,比如在模型全链条是以流式,从选择数据集-构建模型-模型分析-模型评估,整体有从无到有的感觉,使用深度逐渐加深,比较符合预期。
③ 产品友好
功能细节上做的比较出色,感触较深的第一是数据集的预览,这样可以直接看见数据集的概览和样式,线上和本地会有数据解析的格式问题,第二个是模型的推荐,会根据内容的选择推荐相对应的模型,有充足的解释性引导和应用示例。
2)产品功能
- 模型构建:模型构建速度较快,这个有点超出预期。
- 模型评价:模型分析可以直接查看到相关性已经数据更强的透视能力,这个能力提升了很多效率。
3)优化功能
- 数据集兼容能力:这个针对不同数据源可以在上传做检验和预览,前置风险暴露能力。
- 模型调优能力:增强平台对模型进行调优的能力,比如可以考虑多个特征因子的融合、指标区间分析等。
- 数据源能力:可以把数据源的上传和存储考虑融合在产品内部。
2. 心路历程
- 参赛目标:首先想了解一下当前亚马逊的产品力;其次就是想在整个过程中梳理一下分析思路,复盘项目可以增加更多的思考。
- 参赛总结:整体产品体验我觉得还不错,有一点超出预期,后续会持续关注产品,也感谢人人都是产品经理提供本次参赛的机会~
本文由 @芥末先生 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!