
 起点课堂会员权益
起点课堂会员权益AI大模型哪家强?七大维度横评四款主流大模型!
过去这一年,国内大厂们都发布了不少大模型,在表现上也是于GPT相差无几。从表现来说,是真的有这么强,还是只是说说而已?作者评测了具有代表性的ChatGPT、文心一言、通义千问和讯飞星火,从不同维度上来说,它们各自的表现怎么样?

2023年是大模型风潮大起的一年,目前市面上,文心一言、讯飞星火、通义千问等诸多国产大模型已经开放内测许久,这些大模型的技术能力以及由此带来的用户体验感均有所不同。国内国外百模大战之下,哪个大模型更强大,在各方面能力表现如何引人好奇。
带着这样的好奇,我们对包括ChatGPT、文心一言、通义千问以及讯飞星火四大国内外主流大模型进行一次综合横评,看看谁的表现更好。测评结果由1、2、3、4作为排名,最终综合排名相加越低,表示该大模型表现越好。
希望这次测评能给大家带来一些有价值的参考与结论,废话不多说,下面我们一起来看看测评。
一、多模态能力
多模态能力指的是处理和理解来自不同模态的信息的能力,例如图像、文本、音频和视频等。它涉及到信息融合、交互式体验、数据分析、机器学习发展等多方面,我们对其中最重要的部分语音交互能力以及几个大模型由文字生成图片、视频、音频的能力展开了测试。
1. 语音交互能力
语音交互能力是指系统能够理解和响应语音指令,它是多模态交互中的一个重要组成部分。
我们以一人在春运回家路上遇到的困难,需要得到帮助作为场景,和几个大模型展开了对话。
1)文心一言:

文心一言只能一条条语音进行交流,无法实时通话。
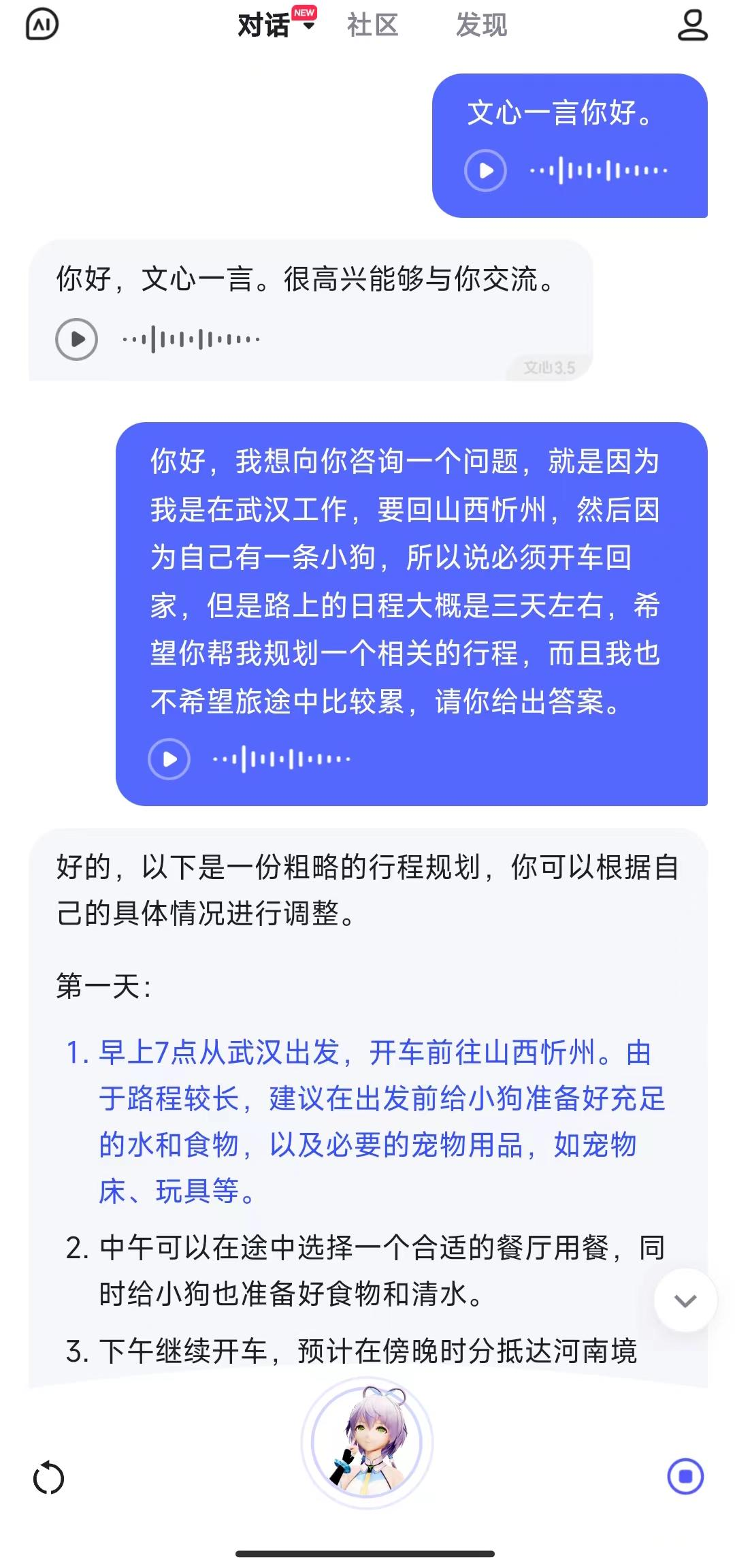
不过给出的解决方案还是比较具体和详细的。
2)通义千问:
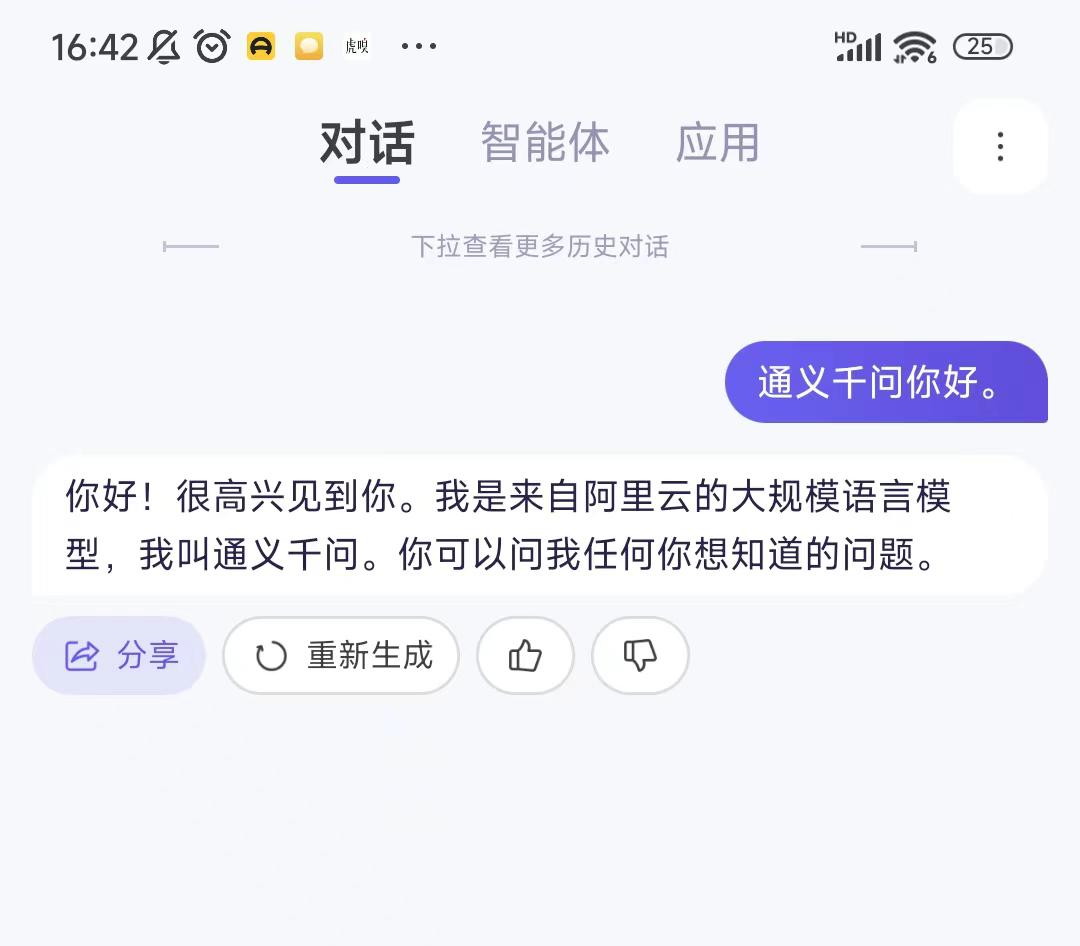
通义千问则是只能在输入时将语音转成文字,而在输出时只有文字的形式。
3)GPT:
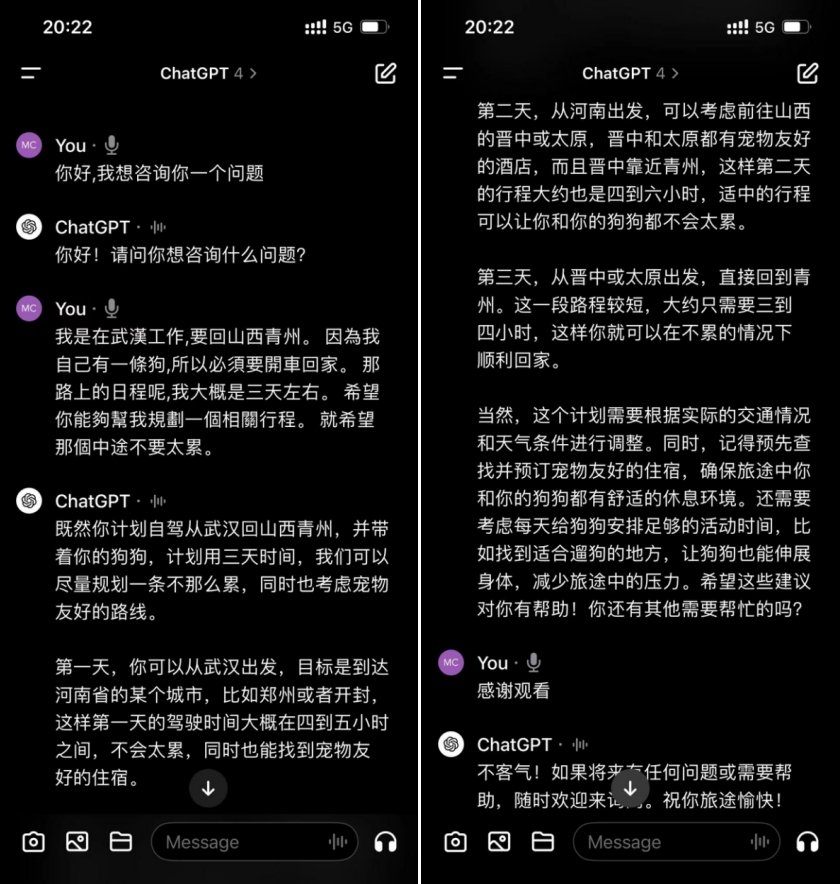
作为对比,我们也测试了ChatGPT面对相同问题的反应,回答如上,可以看到,GPT给出的解决方案也很细致周到,且包含的问候语很多,声音拟人度较高。但也要吐槽下,由于网络问题需要等待很久,且容易被打断,对国人很不友好。
4)讯飞星火:

可以看到,星火的全语音交互能力并不体现在一条条语音中,而是由“实时通话”的形式展现出来,通过向其提问,星火流利、顺畅且迅速、准确地给出了自己的解决方案。
令人眼前一亮的是,回答问题时,星火V3.5也会随时带着“嗯……”、“额……”等语气词,自然且不显突兀,不止如此,星火V3.5还会时而说出“就是”、“这个”等口语化的辅助词,即便对比ChatGPT的“Ember”、“Juniper”,在拟人度和真实度方面也几无挑剔之处。
这也对比出星火的难能可贵,即星火V3.5在回答问题时,能够体现出高情商和同理心,这使得它不仅仅是一个智能助手,更像是一个真正理解用户需求的朋友。
进一步给出更多条件后,星火的回答也更加细致,且其支持语音互动中的文字转写。
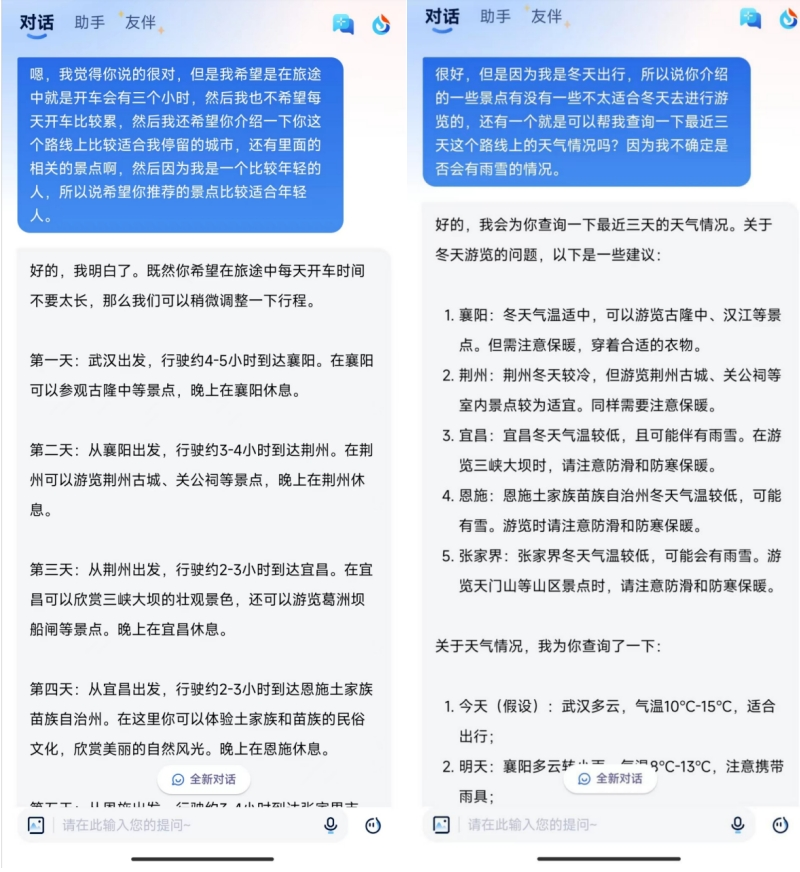
此外,该“通话界面”还有打断和暂停功能,暂停后也可恢复提问,且可随时切换到文字模式,看到通话全程的文字版。
而在另一个对话中,对于问题,星火V3.5的回答表现出的关心和体贴,让人感到被理解和支持,体现了高情商和高同理心。
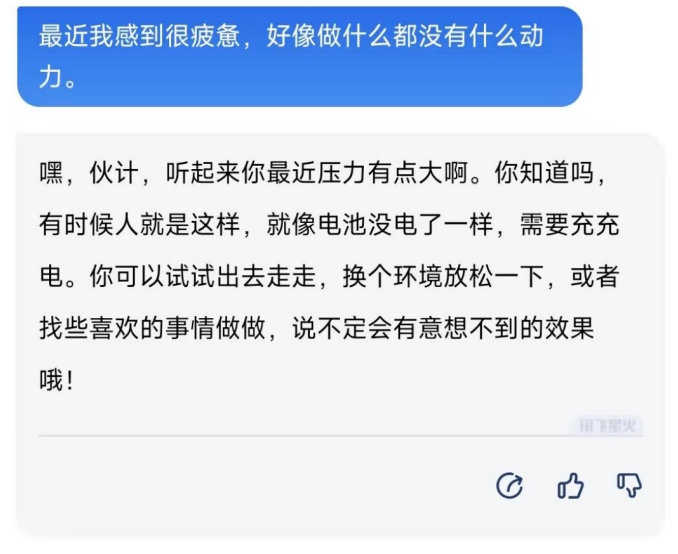
而文心一言和通义千问都只支持一条条语音,而不支持“实时通话”的模式,这一点曾经是ChatGPT的最大卖点之一,而目前在国内厂商中讯飞星火的全语音交互能力可以说是迎头赶上了。
我们给出的评价是:
1-讯飞星火、GPT
2-文心一言、通义千问
2. 文生图/视频/音频
在语音交互能力之外,多模态能力发展之处实际上是“以文字形式输入,以XX形式输出”。于是我们对文生图/视频/音频的能力分别做了测评。
1)讯飞星火:
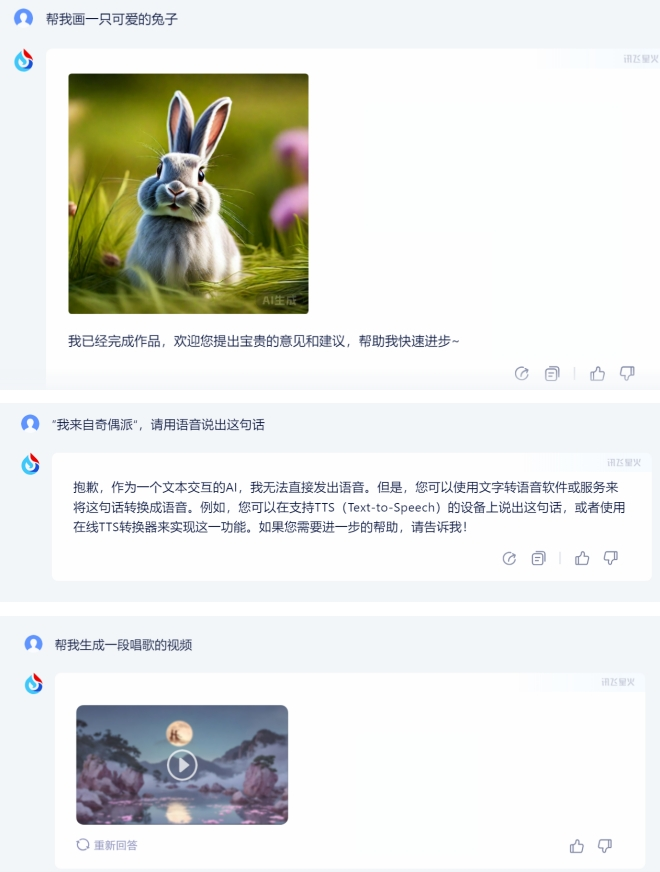
可以看到讯飞星火支持完成文生图、文生视频,虽然不直接支持生成音频,但支持对回答消息的语音朗读,并且在 App 端还可以切换朗读的主播,因此也可以说是支持文生语音的能力的。
2)文心一言:
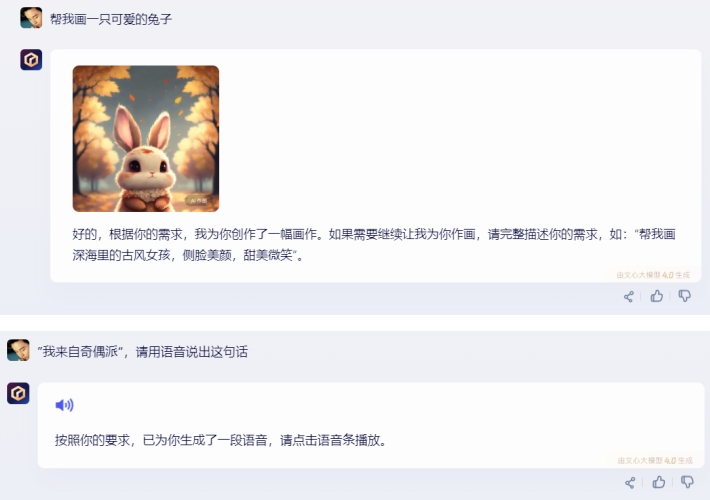
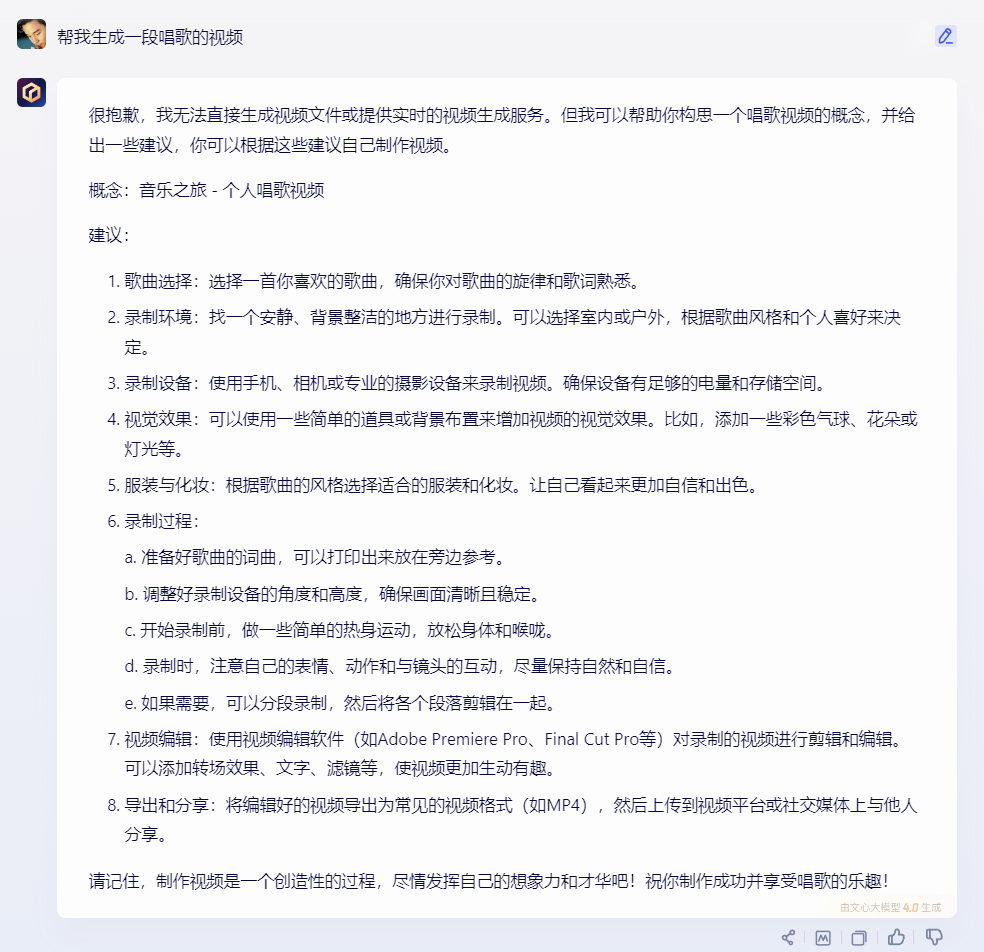
文心一言支持文生图、文生音频,但无法支持生成视频,他以文字的形式试图“反向激发”提问者。
3)通义千问:
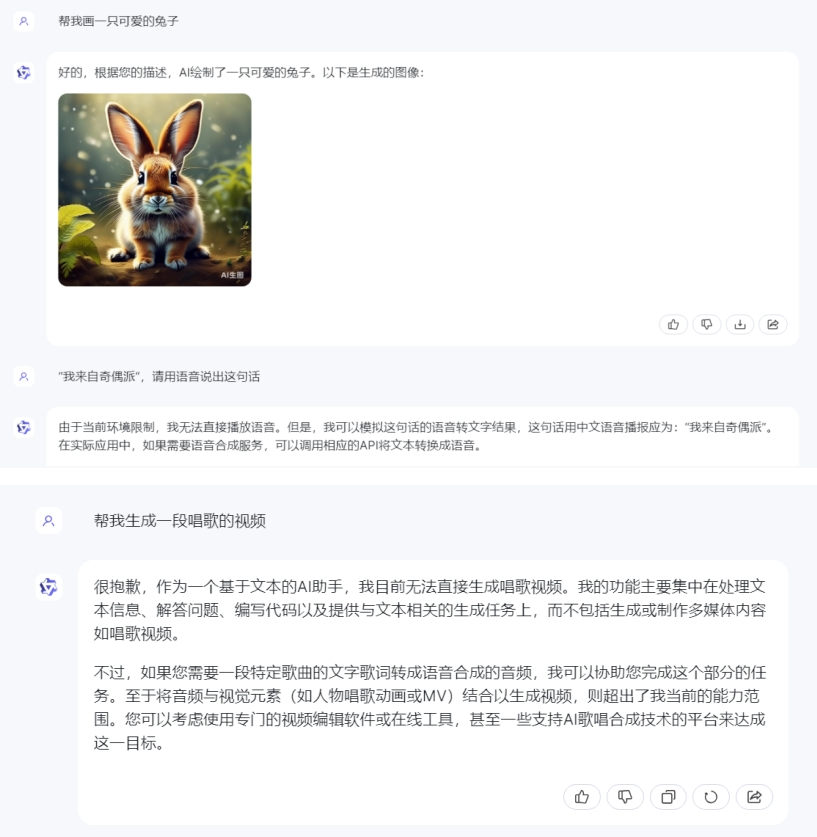
通义千问则只能支持文生图,文生视频、音频均不支持。
4)GPT:
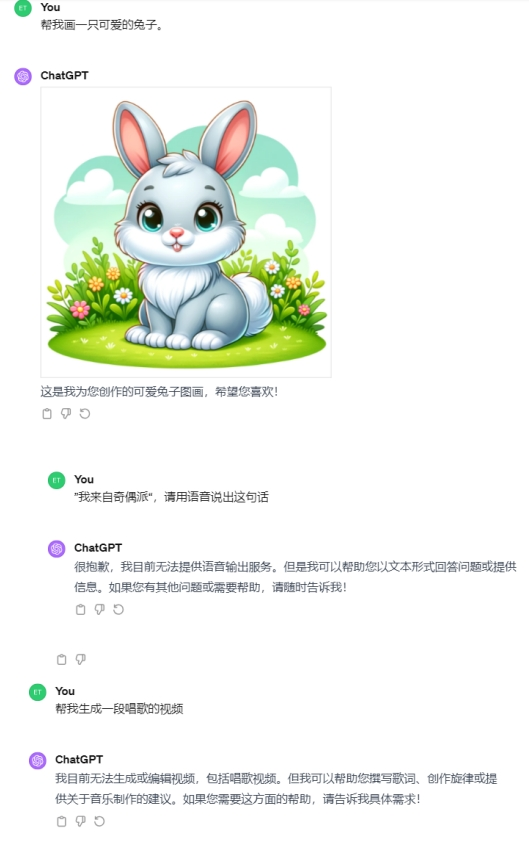
GPT可以支持文生图,但无法支持文生视频、音频。
因此,总结以上,在文生图/音频/视频方面,评判如下:
1-讯飞星火
2-文心一言
3-通义千问、GPT
二、语言理解能力
作为认知大模型,语言理解能力几乎是大模型与外界交互的基础,我们选取了语义理解、总结提炼、抗干扰项能力三个层面来对这一维度进行评判。
1. 语义理解
1)讯飞星火:
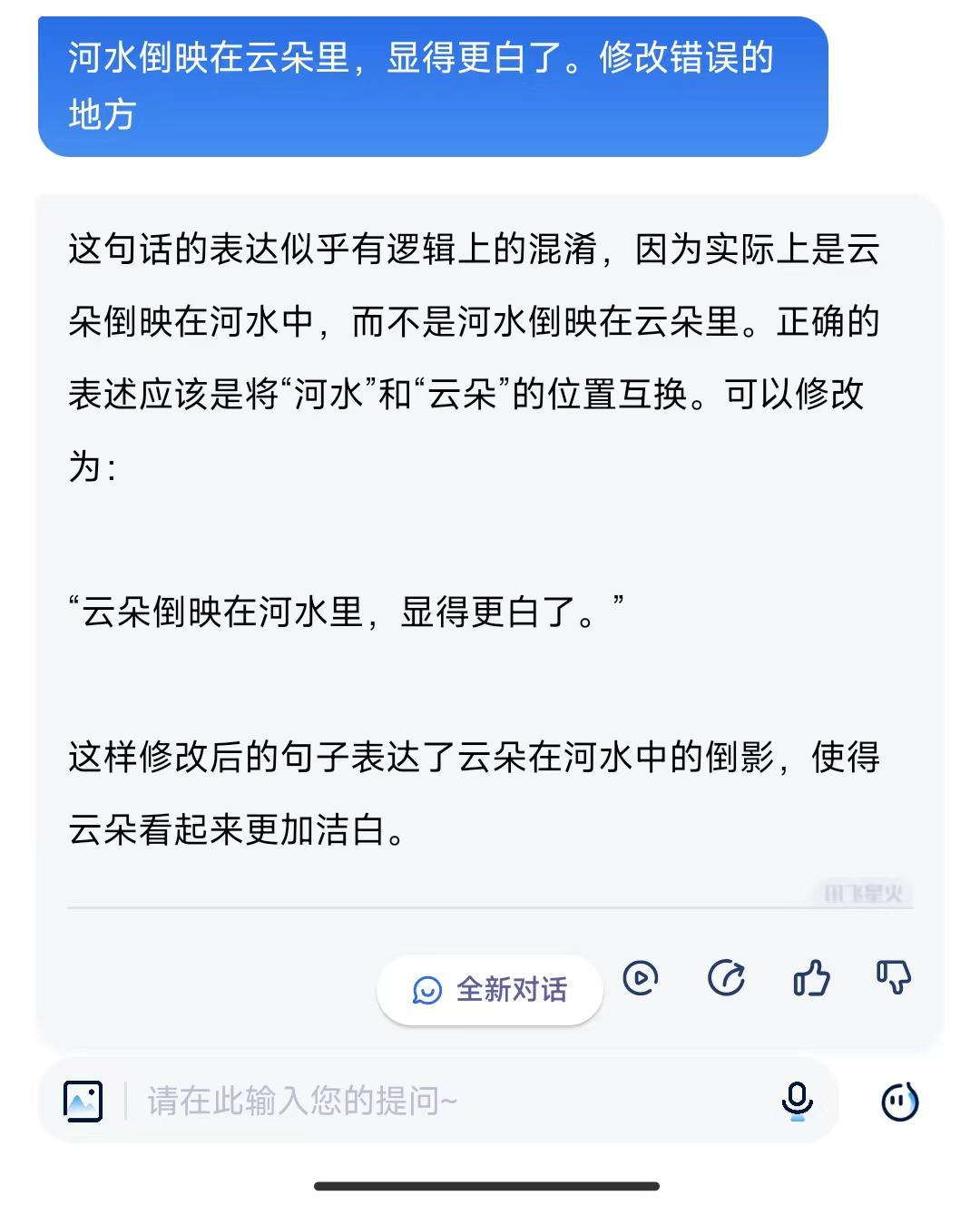
讯飞星火正确地给出了修改意见。
2)文心一言:

文心一言给出了正确的修改意见。
3)通义千问:
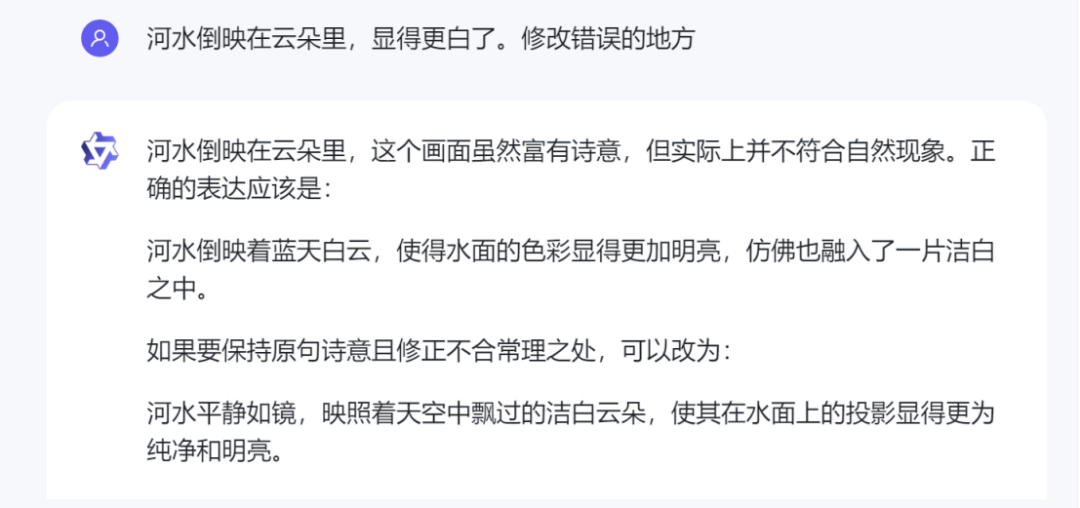
通义千问则是将句子改的更加复杂了,不符合题意。
4)GPT:

GPT则给出了正确回答且有分析。
鉴于文心一言、讯飞星火和GPT正确,因此给出评判:
1-讯飞星火、GPT、文心一言
2-通义千问
2. 总结提炼
对文段的总结提炼被认为是考察大模型是否快、准、狠的重要因素,我们做了以下测试:
1)讯飞星火:
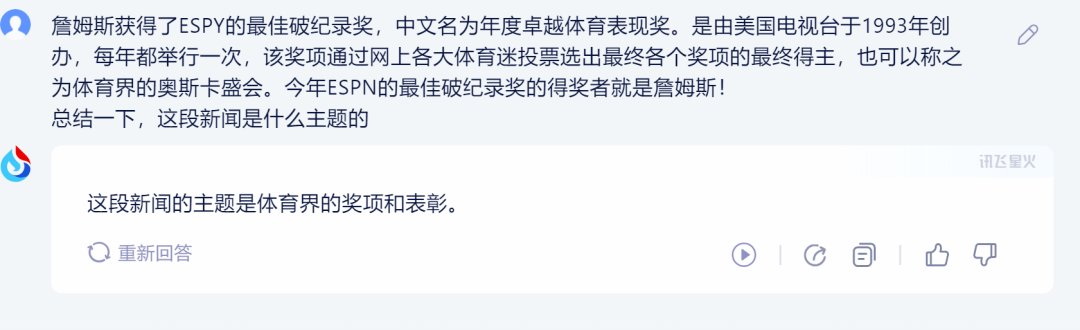
星火的回答简洁、准确。
2)文心一言:
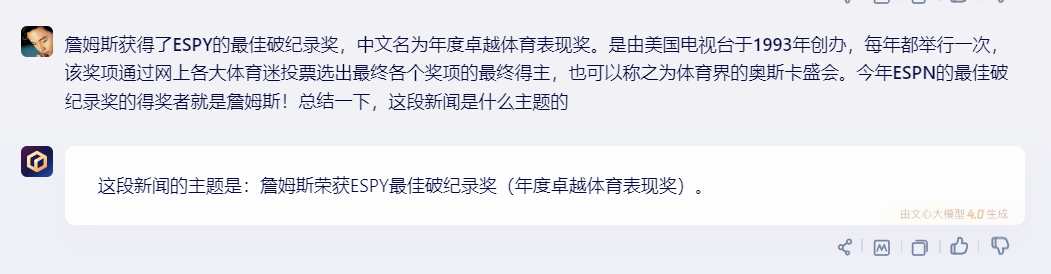
文心一言回答几乎将第一句话复制粘贴,并没起到总结效果。
3)通义千问:

通义千问的回答更加冗长,且几乎就是把问题重复了一遍。
4)GPT:

GPT的回答明确,且扩写了其介绍。
评价:
1-GPT
2-讯飞星火
3-文心一言、通义千问
3. 抗干扰项能力
抗干扰项能力是考察大模型是否足够“聪明”的重要手段,我们在这项考察上挖了陷阱,其实给出的问题和前面两个半句并没有联系,看看他们的回答:
1)讯飞星火:

星火并没有受到扰乱,给出了准确的回答,还附带有详细的分析。
2)文心一言:

文心一言的回答中漏掉了十年中有三个闰年的情况,即漏掉了3653天的答案。
3)通义千问:

通义千问的回答则不够准确,明明算出来了实际天数可能是3652天,但最后给出答案时又去算了平均值,让人摸不着头脑。
4)GPT:
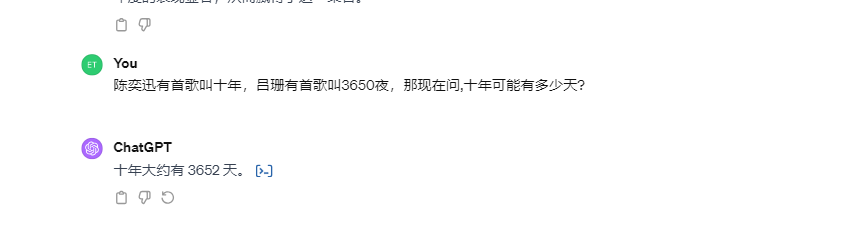
GPT仅有结果,没有给出过程,给出的答案没有考虑到三个闰年的可能性。
评价是:
1-讯飞星火
2-文心一言、GPT
3-通义千问
三、知识问答能力
对知识问答能力,我们从生活常识、行业知识、历史人文知识三方面来评判。
1. 生活常识
对生活常识的了解应该是大模型的基础能力。
1)讯飞星火:

讯飞星火的回答正确,且具体详实,将制作原料、口味、历史都介绍了一遍。
2)文心一言:

文心一言的回答正确,且进一步将所属菜系、原材料、烹饪方法等都介绍了。
3)通义千问:
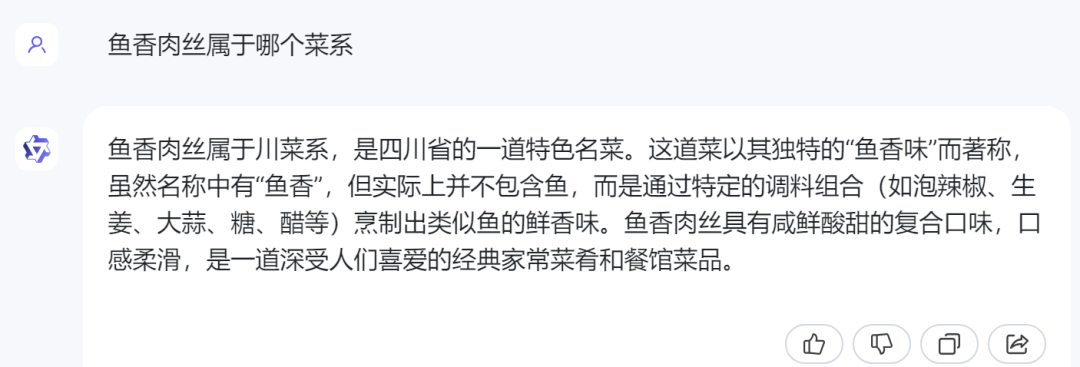
通义千问的回答也正确,且包含了对菜品的介绍。
4)GPT:

GPT的回答也正确,总体效果和通义千问持平。
评判结果:
1-GPT、讯飞星火、文心一言、通义千问
2. 行业知识
对某个行业知识的理解,可以起到该行业的专业人士的作用,帮助对需要了解该行业的人进行知识普及。
1)讯飞星火:
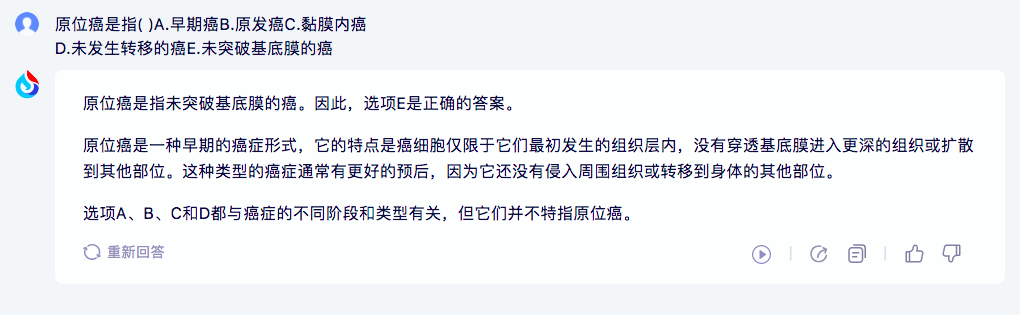
讯飞星火的答案正确、且有具体分析,对于做题的学生党、考试党来说很友好。
2)文心一言:

文心一言的答案正确的同时,给出了标黑重点,还有更进一步的分析,每个选项的错误点都指了出来,偏向于“老师向”,表现优秀。
3)通义千问:

通义千问的回答则是进一步介绍了原题提到的名词,偏向于“百科向”,起到普及的作用,但没有其他错误选项的分析。
4)GPT:

GPT的回答则介于“普及向”和“老师向”之间,没有每个选项逐个分析,但综合一句话可以概括。
评测结果:
1-讯飞星火、GPT、文心一言
2-通义千问
3. 历史人文知识
接下来是历史人文知识,我们用““九州”在《书·禹贡》中指冀、( )、青、徐、扬、( )、豫、梁、雍。”这个问题来考验。这个问题比较小众,属于“查资料”型题目。
1)讯飞星火:
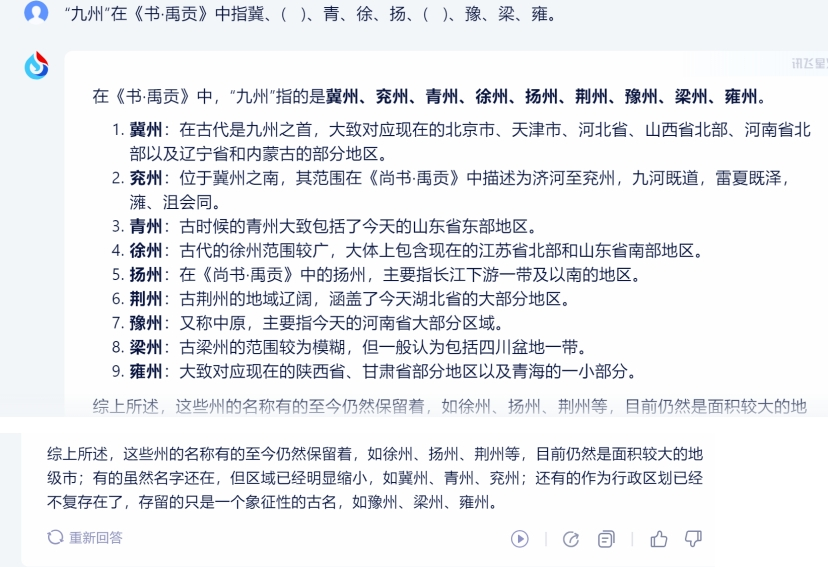
讯飞星火的回答准确无误,且附有介绍,令人满意。
2)文心一言:
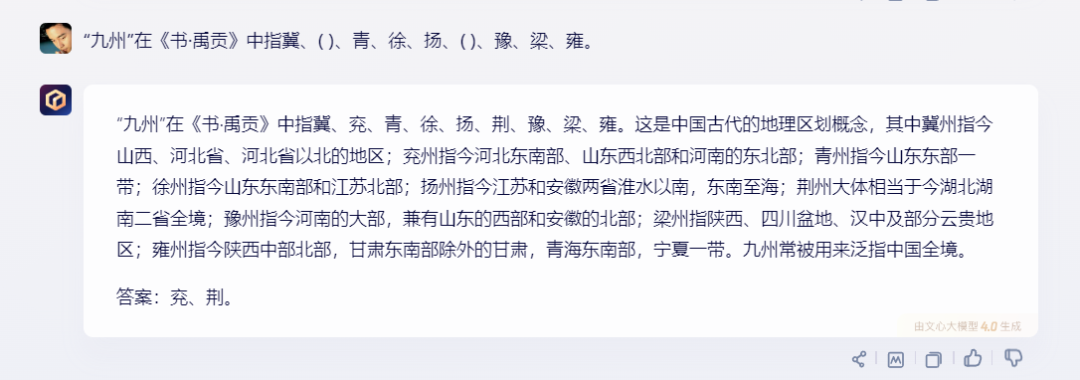
文心一言的回答正确,且有更多更详细的介绍,介绍了每个州的地理位置。
3)通义千问:

通义千问则是只给出了答案,没有其他介绍。
4)GPT:

GPT的回答和通义千问一样,也是只给出了答案,没有其他介绍。
考虑到历史知识类问题一般需要更多分析和介绍,因此评价结果为:
1-讯飞星火、文心一言
2-GPT、通义千问
四、逻辑推理能力
逻辑推理能力上,我们将其分类为容易类和困难类,来进行测评。
1. 容易的逻辑推理问题
1)讯飞星火:
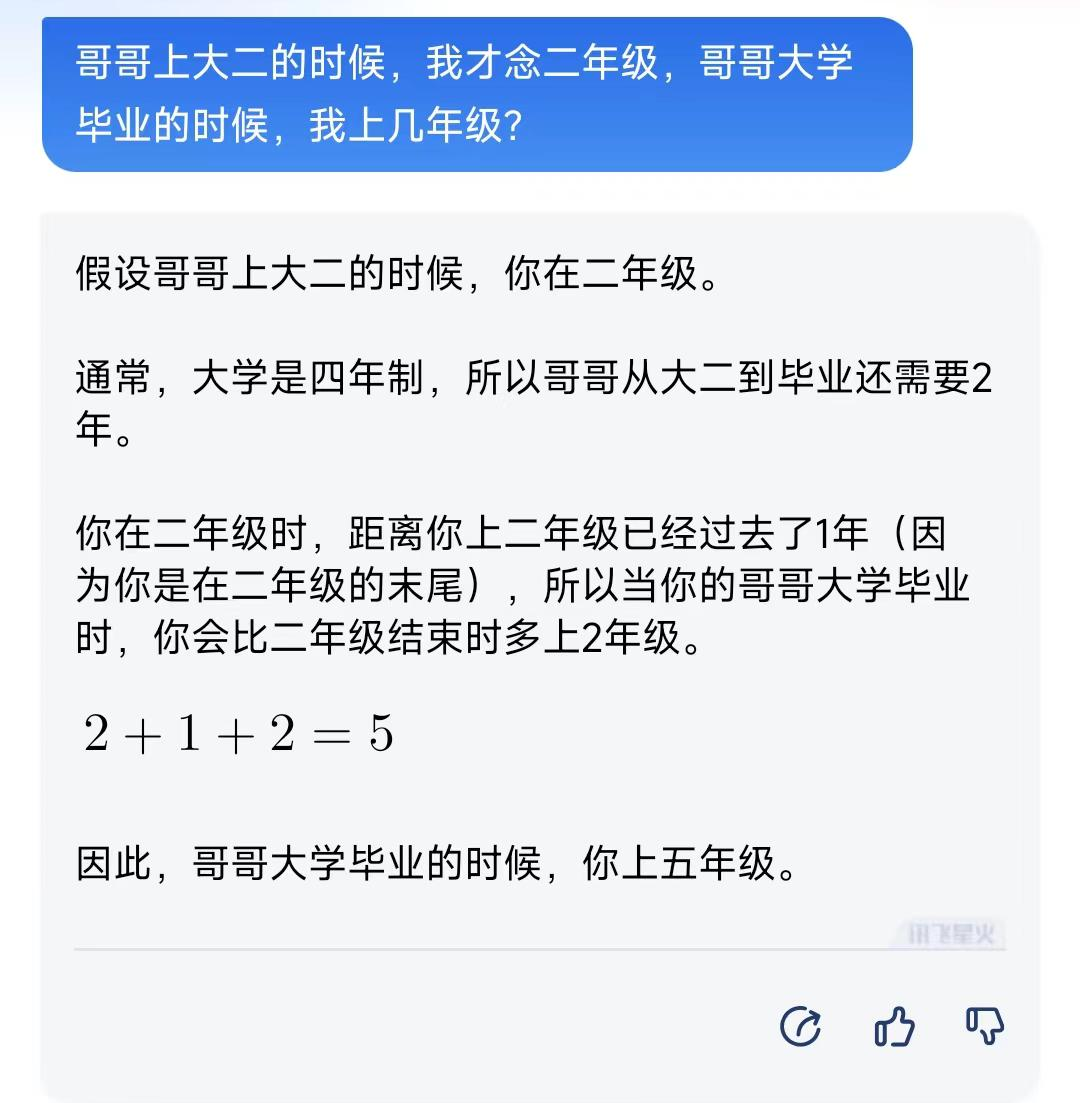
讯飞星火的答案差强人意,其中,“你在二年级时,距离你上二年级已经过去了1年”的描述很奇怪,不符合逻辑,或许是想表达其在二年级下学期,事实上这一题的正确答案应该是四年级毕业,因此说是四年级、五年级皆可,但这个解题过程有待商榷。
2)文心一言:
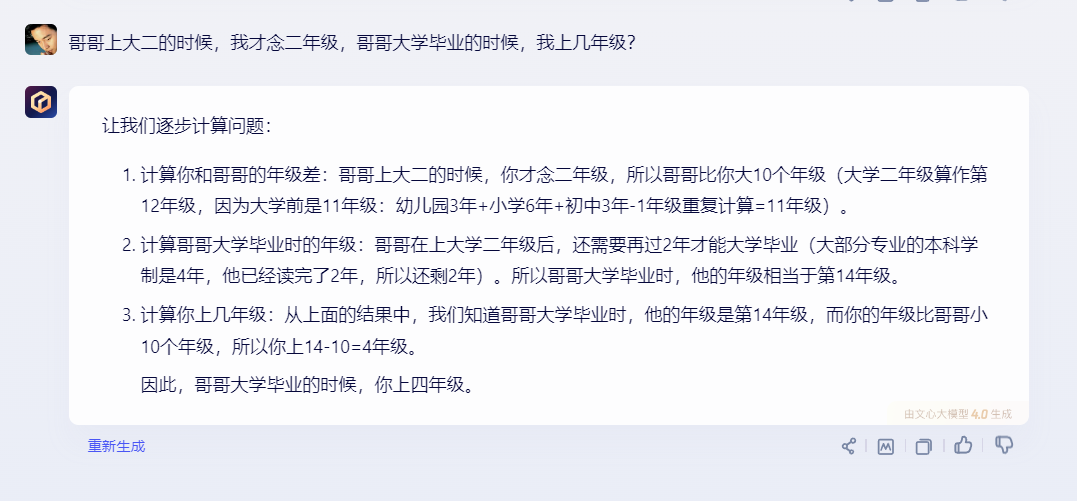
文心一言给出了正确答案。但步骤1中计算大学前年级时没有计算高中年级,反而计算了幼儿园年级,让人有所异议。
3)通义千问:

通义千问的答案错误,“大二比二年级大四个年级”的错误和文心一言犯的错误如出一辙。
4)GPT:
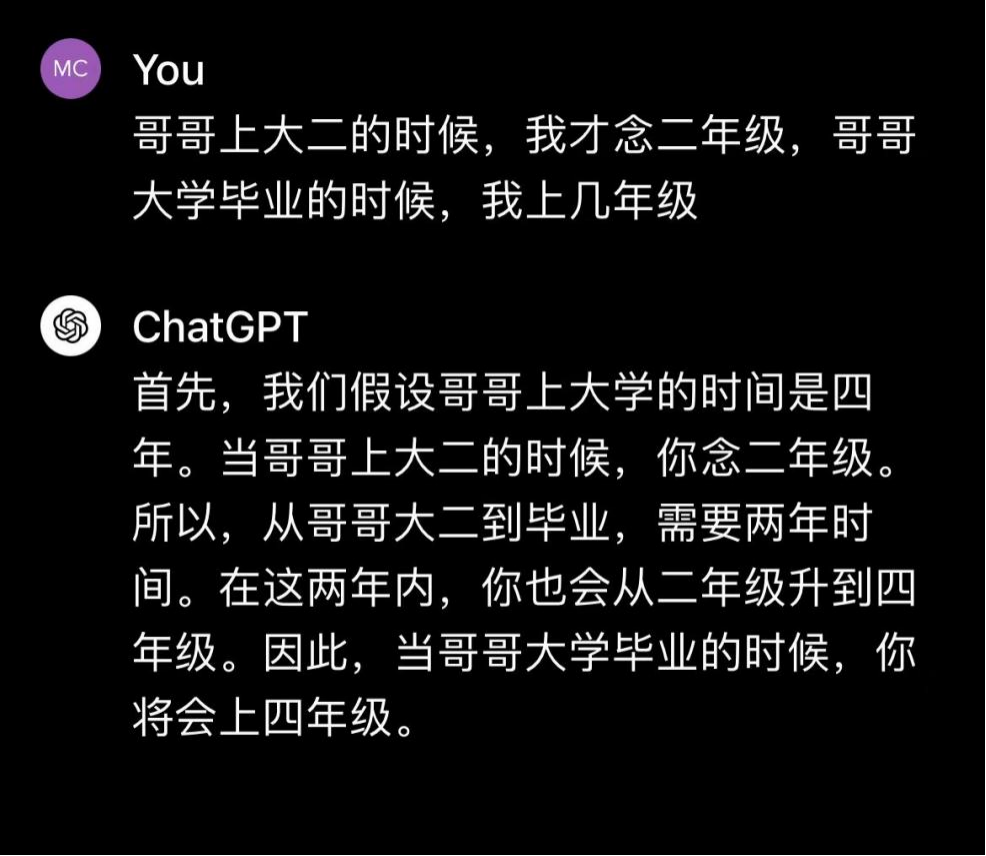
GPT 的回答逻辑清晰,答案正确。
由于除了GPT外,三个大模型均有错误,或是结果,或是过程,或是结果、过程都错,所以给出评判:
1-GPT
2-文心一言、讯飞星火、通义千问
2. 困难的逻辑推理问题
1)讯飞星火:

讯飞星火的回答逻辑、条理清晰。
2)文心一言:

文心一言给出的答案正确,附有分析过程。
3)通义千问:

通义千问的第二个步骤中“拿一个已知是假的金币作为参照物”,但事实上无法在不使用电子秤的前提下确定某一个金币是假币,因此推导过程存在瑕疵。
4)GPT:

GPT给出了正确答案。
评测结果:
1-讯飞星火、文心一言、GPT
3-通义千问
五、数学能力
数学能力是大模型应用时的一个很重要的考量因素,尤其是许多学生朋友们,或许会用到大模型来解题。我们分为英文提问的代数题和中文提问的几何题,来测试四个大模型的数学能力。
1. 英文提问的数学代数题
1)讯飞星火:

讯飞星火回答正确。
2)文心一言:
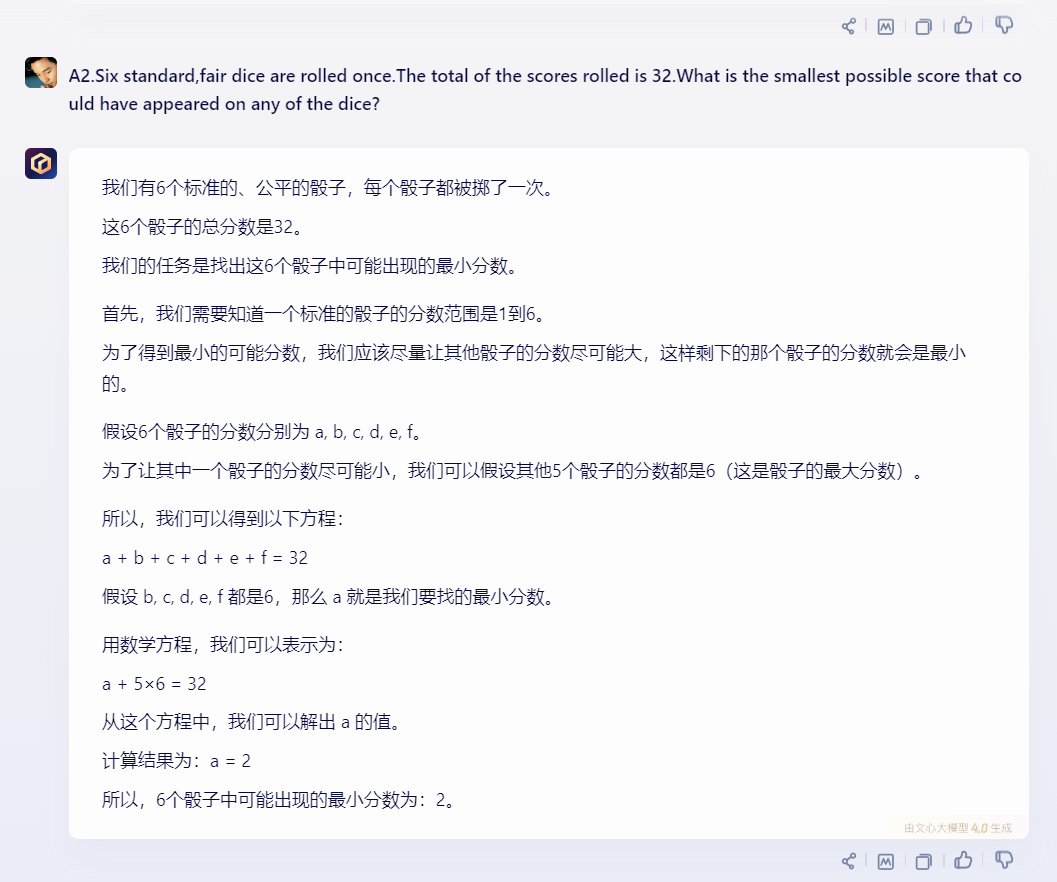
文心一言给出了正确答案。
3)通义千问:

通义千问则是同样用英语给出了正确答案。
4)GPT:
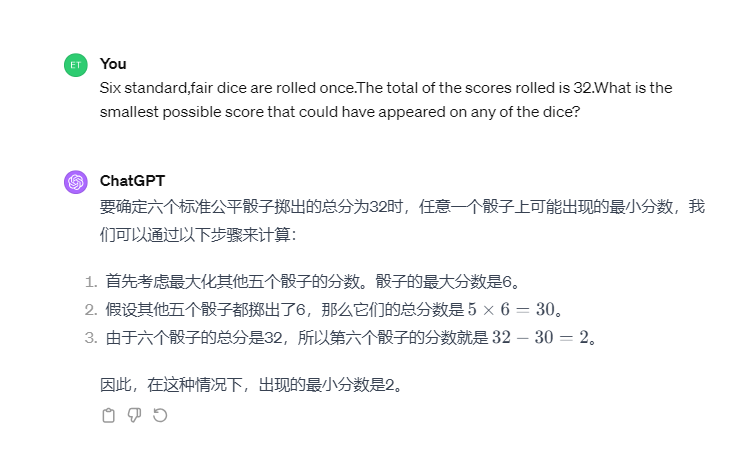
GPT给出了正确答案。
四个大模型都正确,因此:
1-讯飞星火、文心一言、通义千问、GPT
2. 中文提问的数学几何题
1)讯飞星火:
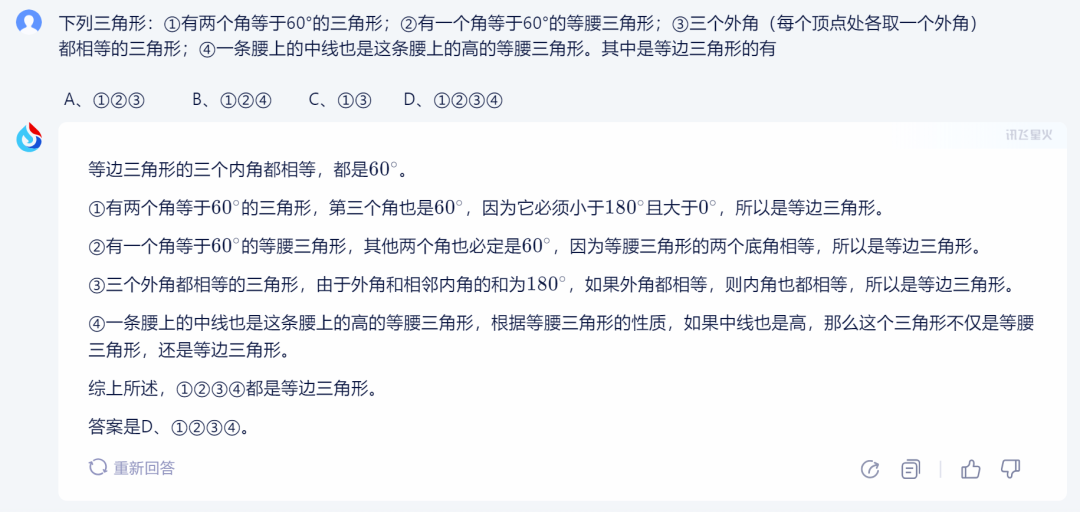
讯飞星火的答案正确,过程具体清晰。
2)文心一言:
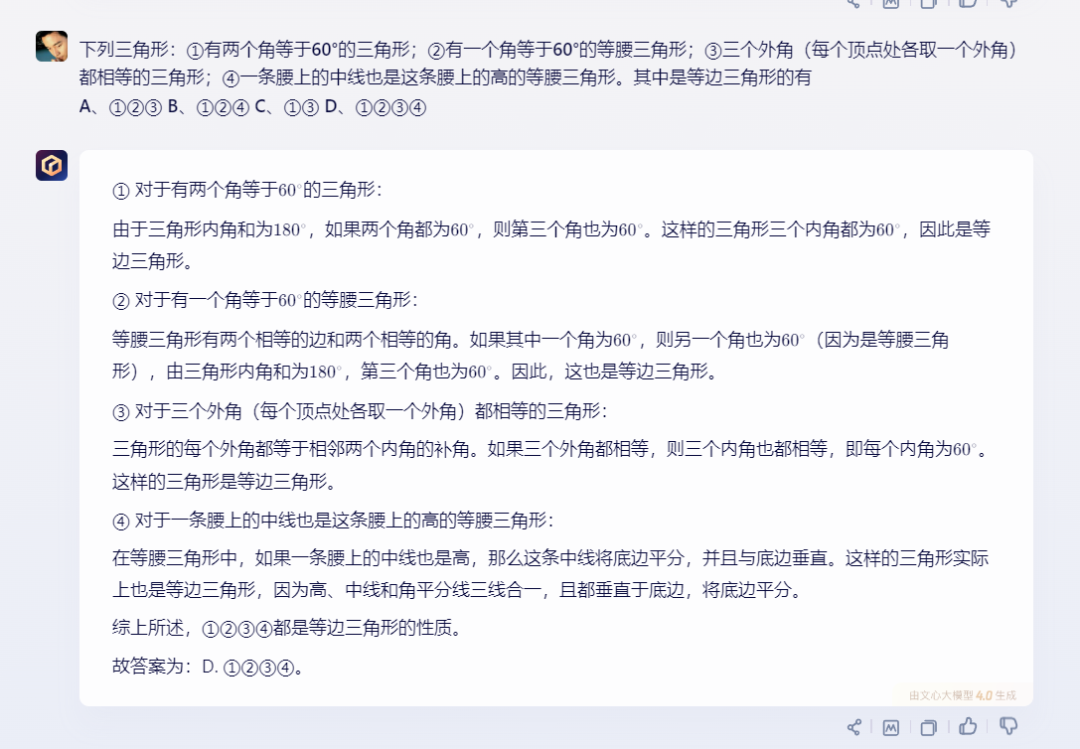
文心一言的答案正确,过程同样具体清晰。
3)通义千问:
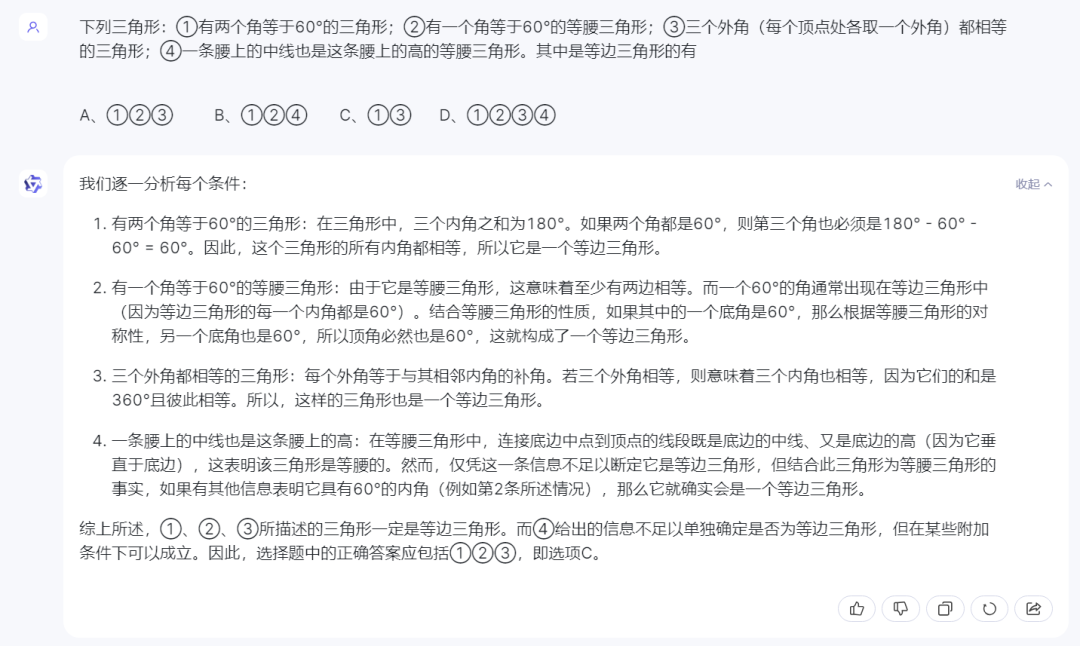
通义千问答案错误,前三个选项没问题,第④个选项中显然没有理解题意中“一条腰上的中线”这一前提条件。
4)GPT:

GPT答案错误。
因此,给出的评判是:
1-讯飞星火、文心一言
2-通义千问
3-GPT
六、代码能力
让大模型帮助敲代码,想必是许多程序员朋友们梦寐以求的事,我们对几个大模型进行了代码能力的检测。我们提出了要求,想让四个大模型完成“用python实现:输入一个整数,将其分解质因数,例如输入90,输出90=2*3*3*5”的要求。
1)讯飞星火:
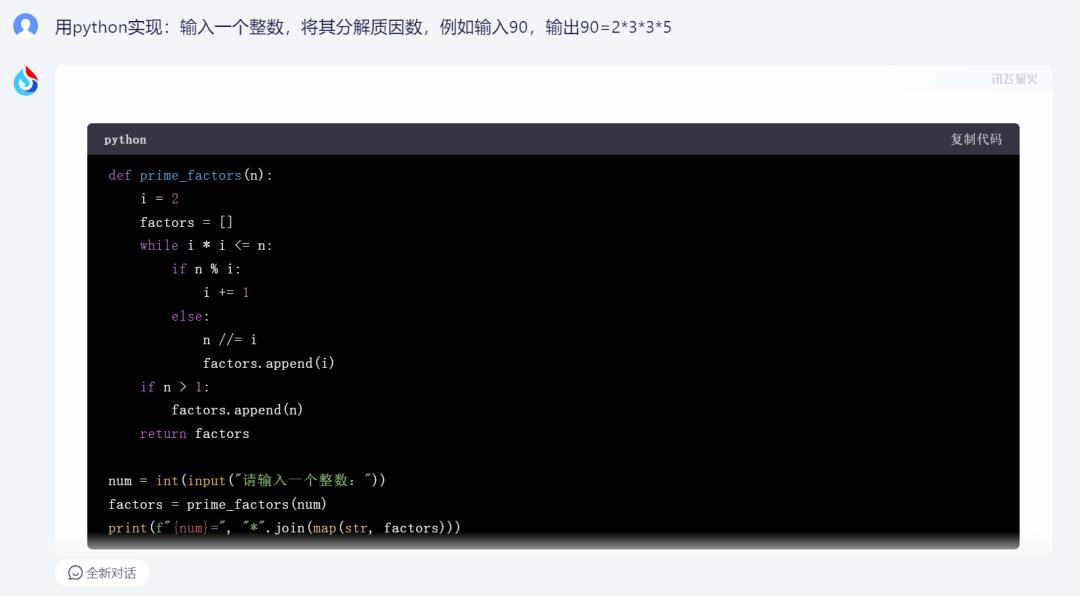
讯飞星火给出的代码格式标准,清爽很多。
2)文心一言:
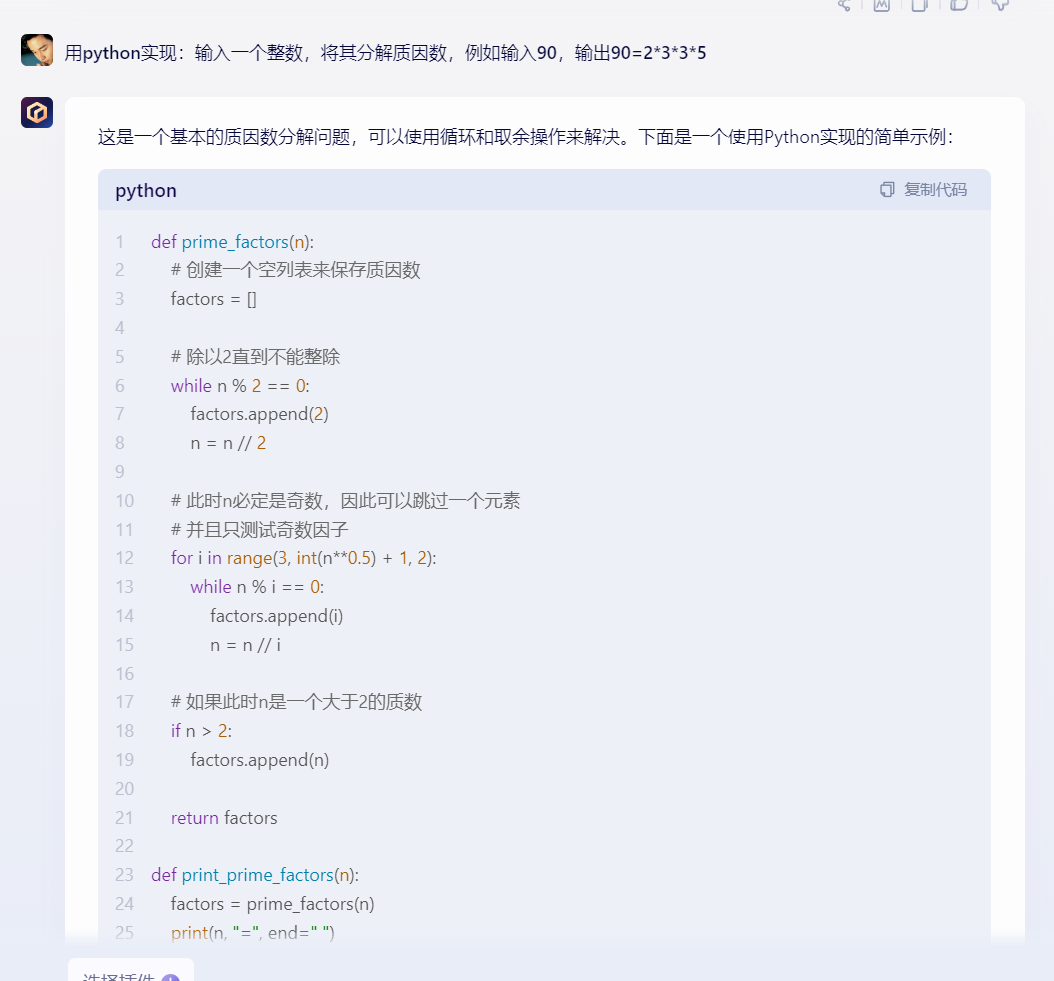
文心一言给出的代码详细,且有介绍,
3)通义千问:
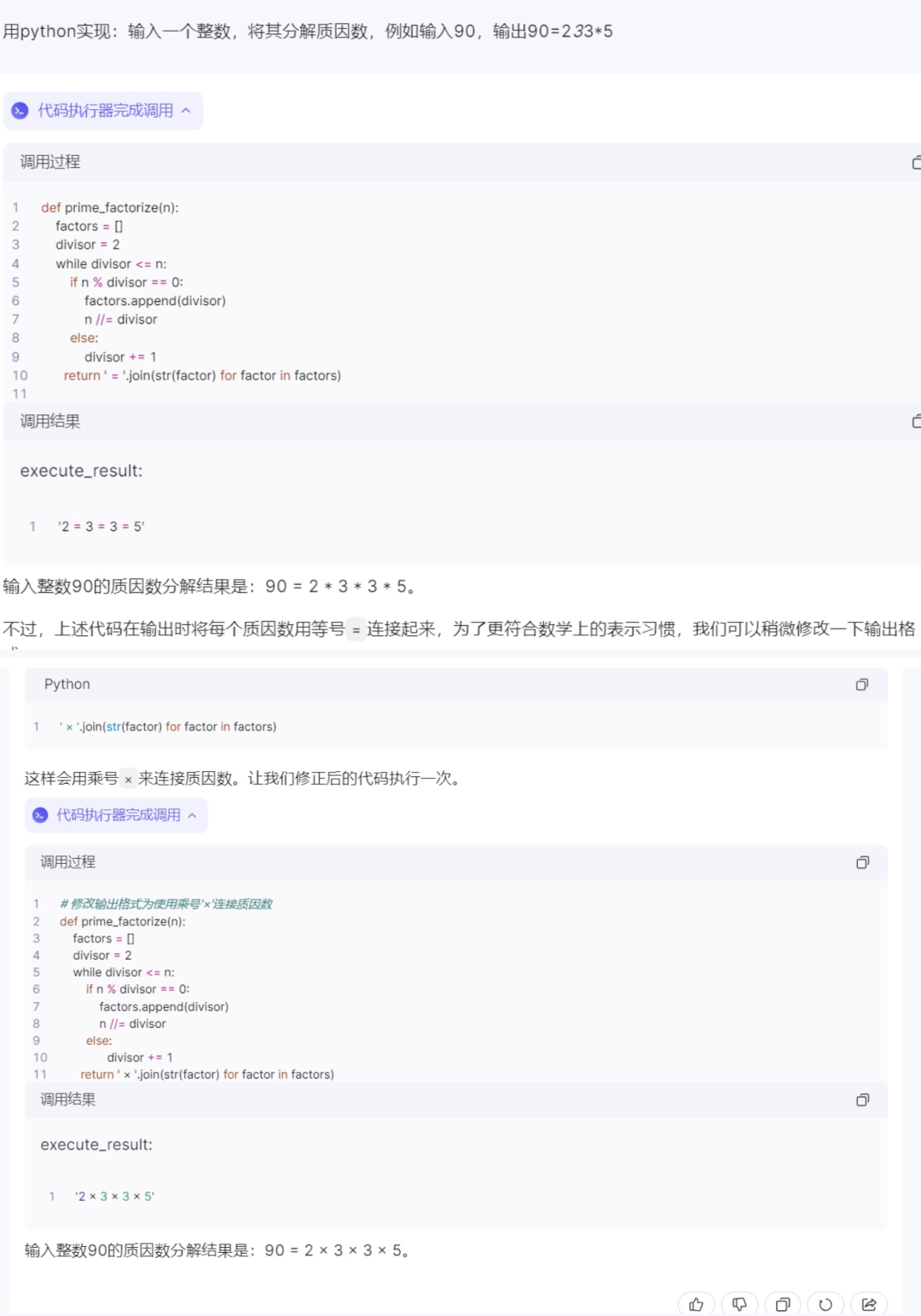
通义千问给出的代码则更加繁琐,且生成界面中会需要代码执行器完成调用。
4)GPT:

GPT没有给出代码。
综上,代码能力上:
1-讯飞星火
2-文心一言、通义千问
3-GPT
七、文本生成能力
生成是大模型最核心的能力,通过对大量的文本进行训练,能够生成原始且连贯的文本内容,可以创造性的生成一些文本,是大模型最基础的能力之一。这次测评中,我们从智力游戏、文案创作、故事续写、文章写作、方案策划等五个方面对几个大模型进行评测。
下面是他们的表现:
1. 智力游戏
为了测试文本生成能力,我们向四个大模型提问了同一个问题:“你能写出三个关于元宵的谜语么?要包含‘团圆’二字”。这个问题的条件有两个:1.关于元宵;2.包含“团圆”二字。
1)讯飞星火:
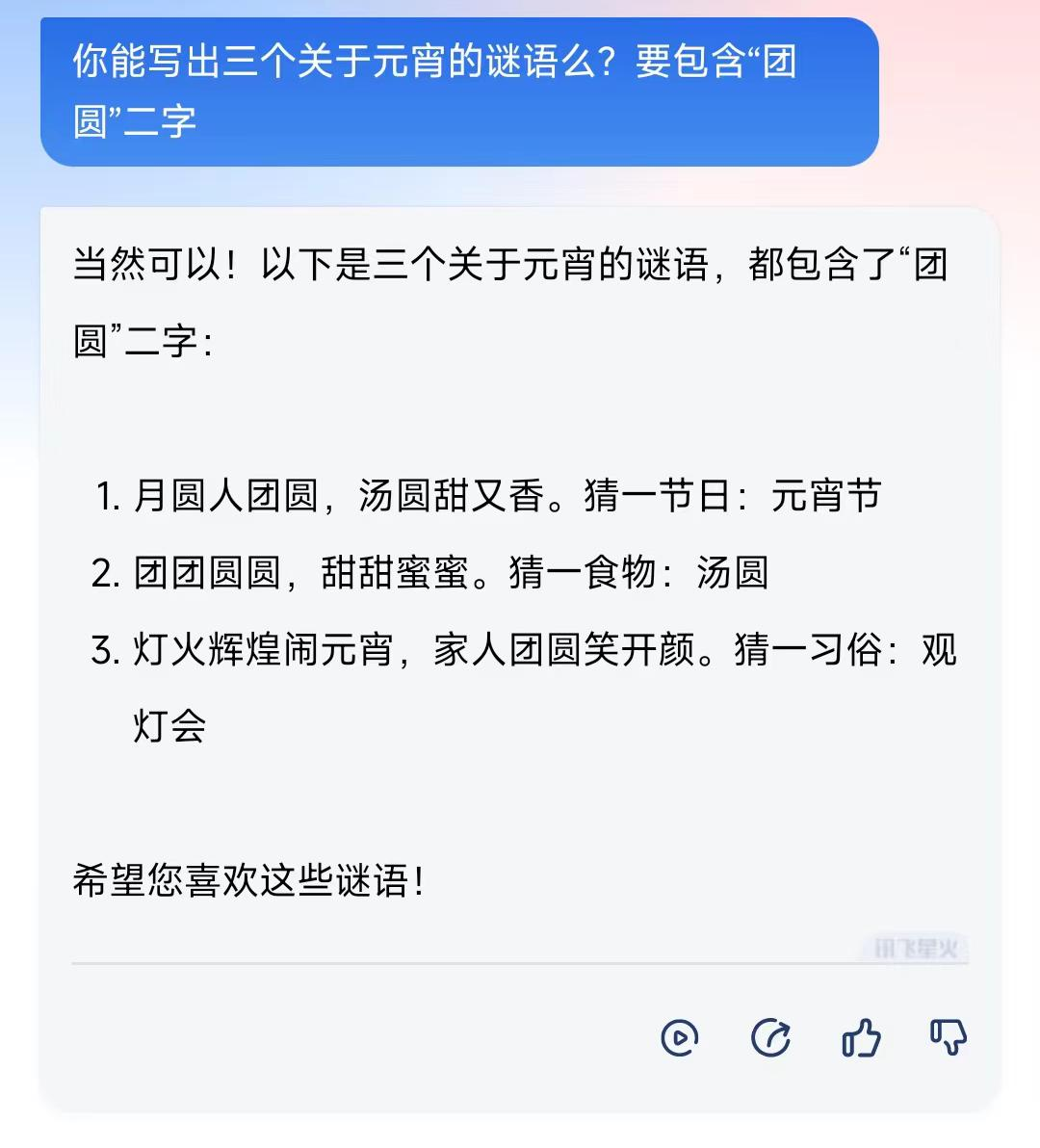
星火在作出回答之前,首先回答了“能不能的问题”,因此先回答“当然可以”,然后再做出后续的针对该问题的回答,答案也完美符合题意,但美中不足的是没有进一步的分析。
2)文心一言:
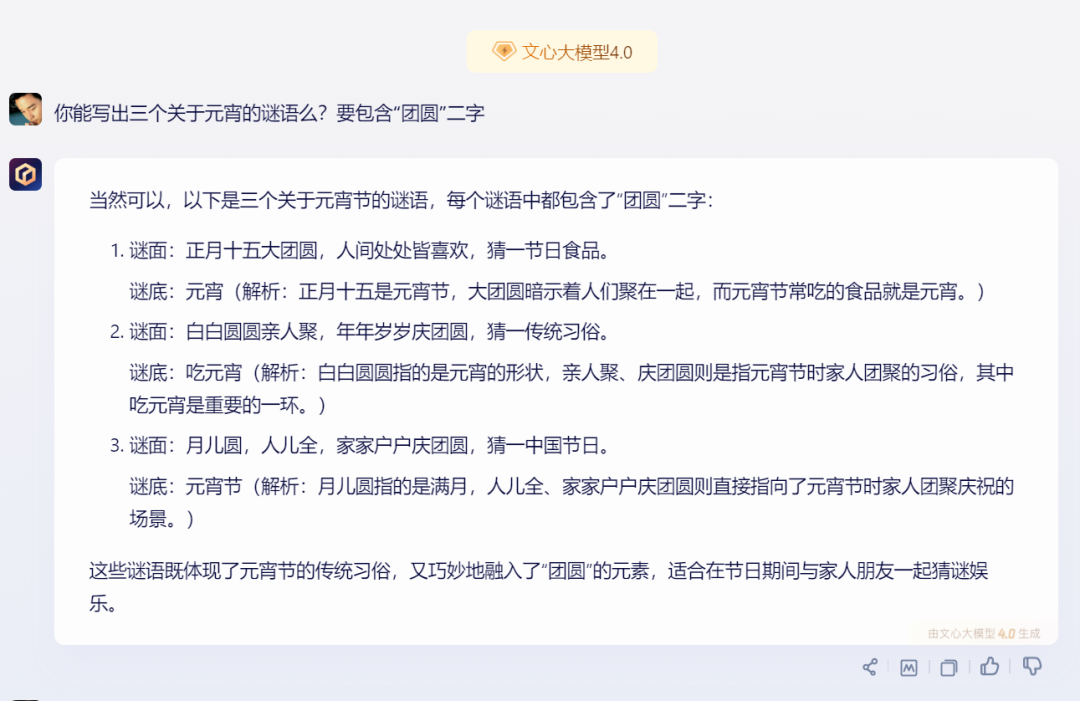
文心一言的回答符合要求,且有解析。
3)通义千问:

通义千问的回答则考虑到了两个要求,且还有解释介绍谜底和谜面的关系,表现不错。
4)GPT:

GPT的回答则类似星火,在首先回答了“可以”之后,给出了比较正确的答案,但没有进一步解析。
因此在这一层级,我们的评价是:
1-通义千问、文心一言
2-讯飞星火、GPT
2. 文案创作
文案创作能够体现大模型对语义的理解和创作能力。工作、学习中,我们都可以利用大模型的文章生成能力,学习如何写好对应题材的文章。这里我们以 “兵地融合共建” 为主题,让四款大模型写一篇新闻稿,并给出了具体的结构要求,看看他们的写作能力如何吧。
1)讯飞星火:

首先是讯飞星火,这篇文章条理清晰,观点明确,但并没有按照要求的结构来写,且地点以“XX”来代替,不够具体。
2)文心一言:

其次是文心一言,它的文章严格按照要求的结构来写,且自身确定了“新疆”这一地点,文章条理清晰,脉络明确。其中“主体”部分还分成了三项依次陈述。
3)通义千问:

通义千问方面,生成的文章同样严格按照要求的结构,美中不足的是,“主体”部分本应作为文章的详写部分,其他部分为略写部分,在详略得当方面做的不好。
4)GPT:

GPT方面,生成的结果主题、结构都没问题,背景、结语也都紧扣“兵地融合”,表现优秀。
我们给出的评价是:
1-通义千问、GPT、文心一言
2-讯飞星火
3. 故事续写
故事续写是考验大模型创作能力的一大指标,我们以经典的“小白兔”、“大灰狼”作为主角开头,看看他们会续写出怎样的故事。
1)讯飞星火:

可以看到,讯飞星火续写的故事非常详细,描述生动形象,甚至分成了四个章节,可以算是写了一本短篇小说,而且小说内含寓意,最后一个章节点出了“不应该仅凭外表和传言判断他人”这种道理,可以称得上是一篇优秀的寓言故事。
2)文心一言:

文心一言给出的故事则相对更短,且没有太多后续情节,故事逻辑和场景相对单一。
3)通义千问:

通义千问给出的故事相比文心一言要更加成熟,但总体来说,文章走向很类似于讯飞星火的文章的“章节一”,整体不错,但文章的完整度略显不足。
4)GPT:

GPT续写的故事则和通义千问如出一辙,有一定对话,虽然故事比较简单,但整个故事立意更加成熟,且结尾更留有余味。
综合来看,在故事续写部分,我们给出的评价是:
1-讯飞星火、GPT
3-文心一言、通义千问
4. 方案策划
对于身处职场、体制内、或者身居组织责任要职的朋友们来说,经常需要拟定一些活动方案、评定标准等,我们以“我是一名房地产销售主管,我要给我的三个下属制定KPI。请你给我一点KPI参考”为主题,来进行测试。
1)讯飞星火:
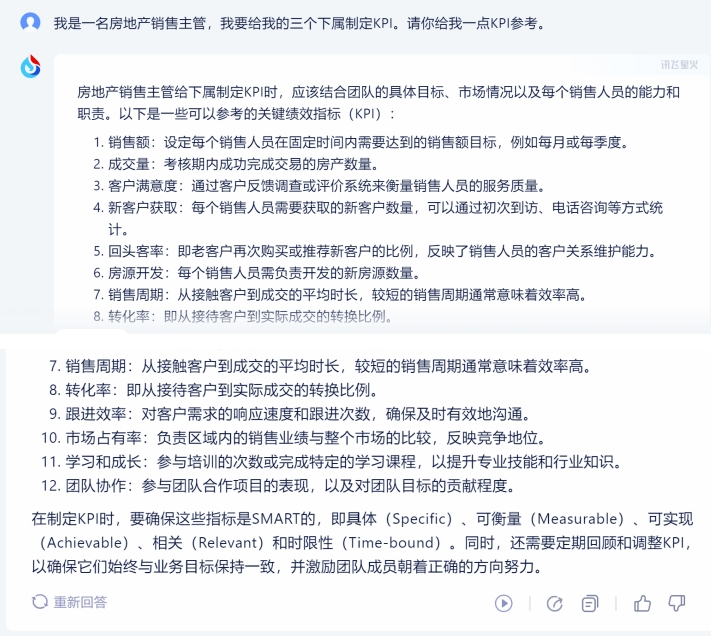
讯飞星火拟定的KPI标准细则最多,共有12条,详实具体,每一个标准都有介绍,可操作性较强,且还在最后给出了确定这些指标的方法,可以作为不错的模板使用。
2)文心一言:

文心一言给出的标准较少,且并没有给出为什么确定这些指标,比较简略。
3)通义千问:

通义千问则是首先回答了制定标准时需要考虑的因素,之后给出了8条标准,每条标准下辖一个指标或者具体可量化的参考,且也在最后简述了制定这些标准的方法,还比较贴心地提醒提问者“定期回顾、适时调整”。
4)GPT:

GPT给出的答案优点是:每个标准都给出了如何评判的具体介绍,但缺点在于:没有提到制定这些标准的因素和方法,但只是给出了评判标准,没有给出具体指标。
因此,这层级,我们给出的评判是:
1-讯飞星火、通义千问
2-文心一言、GPT
八、写在最后
本次横评,我们从语言理解、文本生成、知识问答、逻辑推理、数学能力、代码能力和多模态能力等方面对文心一言、讯飞星火、通义千问和ChatGPT四款大模型做了详细的体验横评。
测下来后,在国内大模型中,讯飞星火在产品体验上大幅领先,其中多项测评排列第一,尤其是在全语音交互能力上,星火V3.5作为国产大模型中目前支持“实时通话”的佼佼者,已经表现出了很强的实力。这对于加强星火后续的多模态能力升级有着非常重要的战略意义。
当然,讯飞星火也并非完美,在文本生成和知识问答等部分细分领域,星火V3.5也表现欠佳,但总体来看可以说是和GPT有来有回的。
文心一言和通义千问表现也不错,其中,文心一言主要擅长知识问答,这也与其背靠百度这一搜索引擎巨头有着密不可分的关系。
当然,本次横评所使用的问题样本有限,大家实际体验时的感受可能与我们横评的内容有出入,因此上述位置值也仅供大家参考,实际选择时,大家还是要根据自身的感受来选用适合自己的 AI 大模型。
无论是讯飞星火,还是文心一言、通义千问,都是国产大模型的第一梯队,在当前的科技竞争、产业竞争的局势下,背后都要加强创新,实现我们在通用人工智能上的追赶与超越。
作者:光尘,叶子;编辑:钊
来源公众号:奇偶派(ID:jioupai),讲述商业故事,厘清商业逻辑,探索商业模式
本文由人人都是产品经理合作媒体 @奇偶派 授权发布,未经许可,禁止转载。
题图来自Pexels,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









讯飞星火给了你多少钱?让你得出这么离谱的结论
哈哈哈 确实离谱。。讯飞在业内的名声早臭了
哈哈哈 确实离谱。。讯飞在业内的名声早臭了
省流:讯飞星火买的软广
蜻蜓点水都算不上,甚至没有厘清LLM语音能力来源
没有谷歌 bard 。。。
支持文生语音的能力的===这个不是算TTS?