
 起点课堂会员权益
起点课堂会员权益
隐含马尔可夫模型是什么以及如何应用
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..隐含马尔可夫模型最早成功的使用场景是语音识别,后来陆续成功的应用在机器翻译、拼写错误、手写体识别、图像处理、基因序列分析等很多it领域,目前也被用于股票预测和投资。

背景介绍
若只有两个事件Ot,St,那么,P(Ot|St) = P(Ot,St)/P(St)。
条件概率的意思:就是事件Ot在另外一个事件St已经发生条件下的发生概率,条件概率表示为P(Ot|St),读作“在St条件下Ot的概率”。
如果有足够多人工标记的数据,知道经过状态St有多少次#(St),每次经过这个状态时,分别产生的输出Ot是什么,并分别有多少次的#(Ot,St),就可以用两者的比值P(Ot|St) =#(Ot,St)/#(St),估算出模型的参数。
有限状态机
有限状态机是一个特殊的有向图,他包括一些状态(节点)和连接这些状态的有向弧。
地址的识别和分析是本地搜索必不可少的技术,判断一个地址的正确性,同时非常准确的提炼出相应的地理位置信息(省-市-区-街道-门牌号等)看似简单实际很麻烦。
如:北京市大兴区欣航路与黄鹅路交叉口东150米;北京市朝阳区东坝单店西路2号院。
这些地址写的都有点模糊,但是邮件和包裹都能收到,说明邮递员可以识别。但是,如果让一个程序员写一个分析器分析这些地址的描述,恐怕就不是一件容易的事情了。根本原因在于,地址的描述虽然看上去简单,但是它依然是比较复杂的上下文有关的文法,而不是上下文无关。
如:北京市海淀区马连洼街道19号院。当识别器扫描到马连洼街道时,它和后面的门牌号是否构成一个正确的地址,需要看它的上下文即城市名。地址的文法是上下文有关文法中相对简单的一种,因此有很多识别和分析的方法,但最有效的是有限动态机。
有限状态机是一个特殊的有向图,他包括一些状态(节点)和连接这些状态的有向弧。
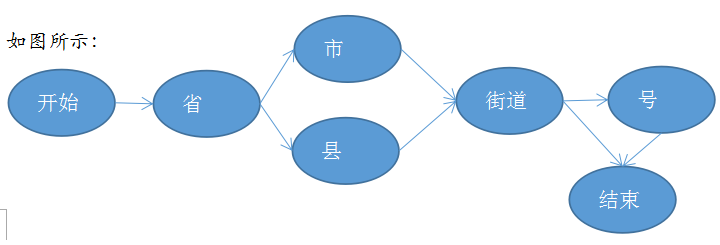
每一个有限状态机都有一个开始状态和一个终止状态,以及若干中间状态,每一条弧上都带有从一个状态进入下一个状态的条件。比如:在途中,当前状态是“省”,如果遇到一个词组和(区)县有关,那么就进入“区县”的状态,如果遇到的下一个词组和城市有关,那么就进入“市”的状态,如此等等。
如果一条地址能从状态机的开始状态经过状态机的若干中间状态,走到终止状态,则这条地址有效,否则无效。比如:“北京市建国路88号”对于上面的有限状态来讲有效,而“上海市辽宁省马家庄”则无效,因为无法从市走到省。
使用有效状态机识别地址,关键要解决两个问题:
- 通过一些有效的地址建立状态机;
- 给定有限的状态机后,地址字串的匹配算法。
有了关于地址的有限状态机后,就可以用它分析网页,找出网页的地址部分,建立本地搜索的数据库。同样,也可以对用户输入的查询进行分析,挑出其中描述地址的部分。当然,剩下的关键字就是用户要查找的内容。比如:对于用户输入的“北京市建国路附近的麻辣烫”,本地会自动识别出地址“北京市建国路”和要找的对象“麻辣烫”。
基于状态机的地址识别方法在实用中会存在一些局限:当用户输入的地址不太标准时或者有错别字的时候,有限状态机会束手无措,因为它只能进行严格的匹配。当用户希望看到可以进行模糊匹配,并给出一个字串为正确地址的可能性。为了实现这一目的,科学家们提出了基于概率的有限状态机。
马尔可夫链
19世纪,概率论的发展从相对静态的随机变量的研究到对随机变量的时间序列s1,s2,s3…st,…即随机过程(动态)的研究。随机过程要比随机变量复杂得多。
- 首先,在任何时刻t,对应的状态时st,都是随机的。举个常见的例子,把s1,s2,s3…st,…看成是北京每天的高温,这里面每一个st都是随机的。
- 其次,任意状态st的取值都可能和周围的其他状态有关。也就是说,任何一天的最高温度,与这段时间以前的温度有关的,这样随机过程就有了两个维度的不确定性。
马尔可夫为简化这一问题,提出一种简化的假设,即随机过程中的每个状态st的概率分布,只与他的前一个状态有关即p(st|s1,s2,s3…st-1)=p(st|st-1)。
比如:对于天气预报,硬性假设今天的气温只和昨天有关而和前天无关。当然这种假设未必适合所有的应用,但是至少对以前很多不好解决的问题给出了相似解。这个假设后来被命名为马尔可夫假设,而符合这个假设的随机过程称为马尔可夫过程,也称为马尔可夫链。
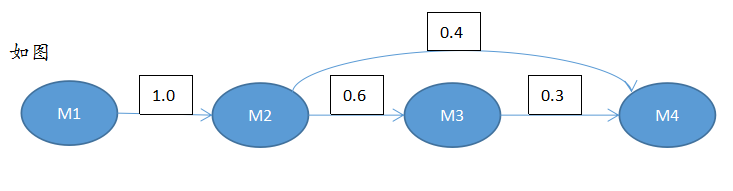
在马尔可夫链中,四个圈表示四个状态,每条边表示一个可能的状态转换,边上的权值是转移概率。例如:状态m1到m2之间只有一条边,并且边上权值为1.0.这表示从m1只可能转换到m2,转移概率是100%。从m2出发的有两条边:到m3和到m4,其中0.6表示:某个时刻的状态是m2,下一个时刻的状态是m3的概率是60%。
把马尔可夫链想象成一台机器,它随机地选择一个状态作为初始状态,随后按照上述规则随机的选择后续状态。运行一段时间后,就会产生一个状态序列s1,s2,s3…st,…。看到这个序列,不难算出某个状态的mi 的出现次数以及从mi到mj的转换次数,从而估算出概率。
隐含马尔可夫模型是上述马尔可夫链的一个拓展,在任何时刻t的状态st是不可预见的。所以我们没办法观察一个状态序列,来推测出转移概率等参数。但是,隐含马尔可夫模型在每个时刻t会输出一个符号o,而且这个符号仅与st相关。
使用场景
隐含马尔可夫模型最早成功的使用场景是语音识别,后来陆续成功的应用在机器翻译、拼写错误、手写体识别、图像处理、基因序列分析等很多it领域,目前也被用于股票预测和投资。
目前国内已有的语音识别是iPhone的Siri,小米的小爱音箱能够做到的也只是能够唤醒某个软件的启动,微软的小冰目前仍然有很大的局限性。
这是因为数据是人工标记的,这种方法是有监督的训练方法。人是无法确定产生某个语音的状态序列的,因此也就无法标注训练模型的数据。而在另外一些应用中,虽然标注数据是可行的,但是成本非常高。比如:训练中英机器翻译的模型,需要大量中英对照的语料,还要把中英文的词组一一对应起来,这个成本非常高。
参考资料:《如何用简单易懂的例子解释隐马尔可夫模型?》
本文由 @小可爱 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议







- 目前还没评论,等你发挥!









