
 起点课堂会员权益
起点课堂会员权益大数据产品经理必备的数据挖掘知识概述(一)认识数据之数据可视化
数据经过获取、存储、分析之后,最终目的还是为了给用户进行展示,以达到决策依据的目的。那么如何有效的将数据展示给用户呢?——数据可视化。

以下内容承接上一篇文章大数据产品经理必备的数据挖掘知识概述(一)认识数据。
1.2 数据可视化
数据经过获取、存储、分析,其最终目的是为了给用户进行展示,以达到决策依据的目的。
那么如何有效的将数据展示给用户呢?数据可视化,旨在合理利用图形清洗有效的表达数据的含义。
本节我们从一维到多维数据开始讨论一些基本数据可视化的表示方法,包括直方图、散点图、基于像素的技术、基本图符的技术、几何投影技术以及层次可视化和基于图形的可视化技术,以此讨论复杂数据对象和关系的可视化展示。(文中知识大多摘自《数据挖掘》一书,感兴趣的同学可以直接阅读此书)
1.2.1 基本的统计描述可视化
首先我们先研究常见的基本的统计描述图形,包括分位数图、分位数-分位数图、直方图和散点图。这些图有助于可视化地审视数据,对于数据预处理是有用的。前三种图显示一元分布(即,一个属性的数据),而散点图显示二元分布(即涉及两个属性)。
分位数图,是一种观察单变量数据分布的简单有效方法。首先,它显示给定属性的所有数据(允许用户评估总的情况和不寻常的出现);其次,它绘制分位数信息。
如下图:
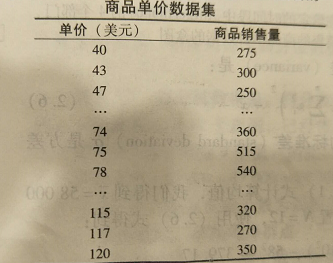
分位数-分位数图,或q-q图对着另一个对应的分数,绘制一个单变量分布的分位数。它是一种强有力的可视化工具,使得用户可以观察从一个分布到另一个帆布是否漂移。
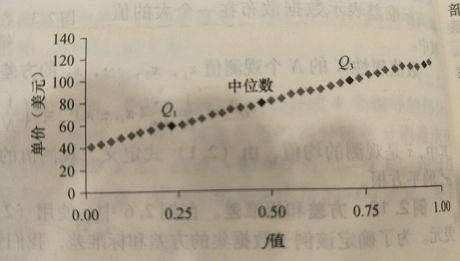
如下图显示给定时间段内两个不同部门销售的商品的单价数据的分位数-分位数图。每个点对应于每个数据集的相同的分位数,并对该分位数显示部门1和部门2的销售商品单价。
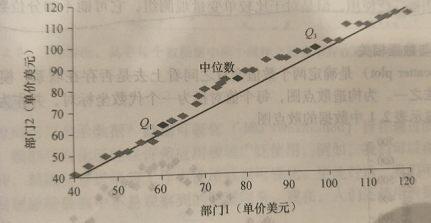
通过上图,在Q1我们看到部门1的销售的商品单价部门2低。换言之,部门1销售的商品25%低于或等于60美元,而在部门2销售的商品50%低于或等于78美元,而在部门2销售的商品50%低于或等于85美元。
一般地,我们注意到部门1的分布相对于部门2的一个漂移,因为部门1的销售的商品单价趋向于部门2低。
直方图,或成频率直方图,出现久远使用广泛。不做赘述。
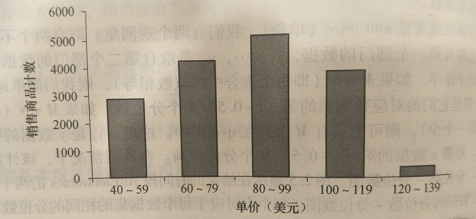
尽管直方图被广泛应用,但是对于比较单变量观测组,它可能不如分位数图、q-q图和盒方图有效。
散点图,是确定两个数值变量之间看上去是否存在联系、模式或趋势的最有效的图形方式之一。
用于观察点镞和离群点,或考察相关联系的可能性。如下图,对于两个属性X,Y,如果标绘点的模式从左下到右上倾斜,则意味X的值随Y的值增加而增加,暗示正相关,如果标绘点的模式从左上到右下倾斜,则意味X随Y值减小而增加,暗示负相关。可以画一条最佳拟合的线,研究变量之间的相关性。

散点图可以用来发现属性之间的相关性
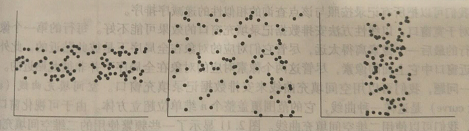
三种情况,其中每个数据集中两个属性之间都不存在观察到的相关性。
基本的数据描述图形展示(如分位数图、直方图和散点图)提供了数据总体情况的有价值的洞察,有助于识别噪声和离群点,对数据清理特别有用。
1.2.2 基于像素的可视化技术
前面讨论的是单变量数据,对于一个m维数据集,基于像素的技术在屏幕上创建M个窗口,每维一个。记录的m个维值映射到这些窗口中对应位置上的m个像素。像素的颜色反应对应的值。诸如此以像素的颜色反映维值称为基于像素的可视化技术。
例如,顾客信息表,包含4个维度:in_come(收入),credit_limit(信贷额度),transaction_volume(成交量)和age(年龄)。我们能够通过可视化技术分析income与其他属性之间的相关性吗?
我们可以对所有顾客按收入的递增序排序,并使用这个序,在4个可视化窗口安排顾客数据,如下图。值越小,颜色越淡。
使用基于像素的可视化,我们可以很容易的得到如下观察:credit_limit随income增加而增加;收入处于中部区间的顾客更可能购物;income与age之间没有明显的相关性;

其他形式,如空间填充曲线、圆弓分割技术等;(感兴趣的同学可以做更深入的学习)

一些频繁使用的二维空间填充曲线;
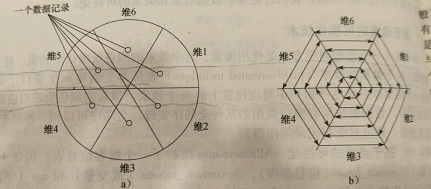
圆弓技术:a)在圆弓内表示一个数据记录;b)在圆弓内安排像素。
1.2.3 几何投影可视化技术
对于基于像素的可视化技术存在一个缺点即他们对于我们理解的多维空间的数据分布帮助不大,不是很容易理解。比如他们并不显示在多维子空间是否存在稠密区域。
几何投影技术可帮助用户更好的发现和理解多维数据集的有趣投影。几何投影技术的首要挑战是设法解决如何在二维显示上可视化高维空间。
散点图:使用笛卡儿坐标显示二维数据点。使用不同的颜色或形状表示不同的数据点,可以增加第三维。例如两个空间属性X,Y,而第三维用不同的形状显示。通过这种可视化技术,我们可以看“+”“X”类型的点趋向于一起出现。
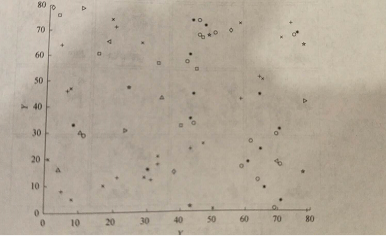
二维数据集使用散点图可视化,资料来源:www.cs.sfu.ca/jpei/public-tions/rareevent-geoinformatica06.pdf
散点图使用笛卡儿坐标系的三个坐标轴,如果也使用颜色,它可是显示4维数据点。如下图:
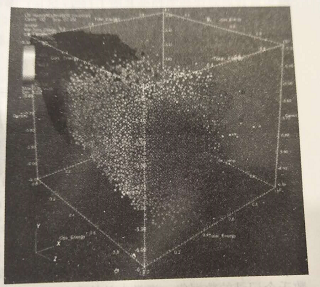
三维数据集使用散点图可视化
散点矩阵图:对于维数超过4的数据集,散点图一般不太有效。散点图矩阵是散点图的一种扩充,提供每个维与所有其他维的可视化。
如下图显示的是一种花的数据集。共450个样本,取自3种花。共5个维度:萼片长度和宽度、花瓣长度和宽度,以及种属。
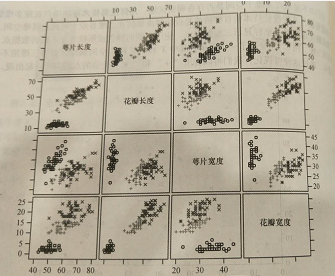
散点图矩阵可视化
平行坐标:随着维数的增加,散点图矩阵变得不太有效。平行坐标可以处理更高的维度,其绘制n个等距离、互相平行的轴,每维一个。数据记录用折线表示,与每个轴在对应相关维值得点上相交,如下图:
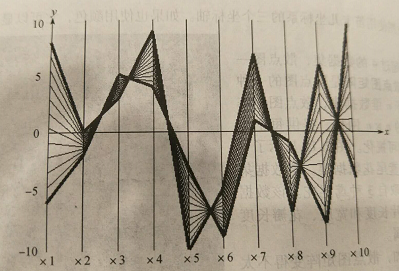
使用平行坐标可视化,资料来源:http://support.sas.com/documentation/cdl/en/grstatproc/61948/THML/default/images/gsgscmat.gif
1.2.4 基于图符的可视化技术
基于图符的可视化技术使用少量图符表示多维数据集。我们讨论两种图符技术,切尔诺夫脸和人物线条画。
切尔诺夫脸是统计学家赫尔曼.切尔诺夫于1973年引进的。它把多达18个维的数据以卡通人脸显示,有助于揭示数据中的趋势。
维可以映射到如下面部特征:眼的大笑、两眼的距离、鼻子长度、眼球大小、眉毛倾斜、眼睛偏离程度和头部偏离程度。切尔诺夫脸利用人的思维能力,识别面部特征的微笑差异并立即消化理解许多面部特征。
缺点是未显示具体的数据值。

切尔诺夫脸,每张脸表示一个N维数据点(n<=18)
已经提出非对称的切诺夫脸作为原来技术的扩展,感兴趣的同学可以深入学习。
人物线条脸是可视化技术把多维数据映射到5-段人物线条画,其中每个画都有四肢和一个躯体。两个维被映射到显示轴(x和y轴),而其余的维映射到四肢和长度。
下图显示人口普查数据,其中age和income被银蛇到显示轴,而其他维被映射到任务线条画。如果数据项关于两个显示维度相对稠密,则结果可视化显示纹理模式,反映数据趋势。

用人物线条画表示的人口统计数据,资料来源:G.Grinstein教授,马萨诸塞州大学(费弗尔)计算机科学系
1.2.5 层次可视化展示
迄今为止所讨论的可视化技术都关注同时可视化多个维,然而,对于大型高纬数据集,很难同时可视化所有维,层次可视化技术把所有维划分成子集(即子空间),这些子空间按层次可视化。
“世界中的世界”又称n-Vision,是一种具有代表性的可视化方法。
假设我们想对6维数据集可视化,其中维是F,X1,….X5,我们想观察维F如何随其他维变化,我们可以把所有维固定为某选定的值,比如C3,…C5,然后可以使用一个三维图(称做世界)对所有维进行可视化,如图,内世界的原点位于外世界的点(C3,C4,C5)处;为世界是一个三维图,使用为X3,X4,X5。
用户可以在外世界中交互地改变内世界的原点的位置,然后观察内世界的变化结果。此外,用户可以改变内世界和外世界使用的维。给定更多维,可以使用更多的世界层,这就是该方法称做“世界中的世界”的原因。
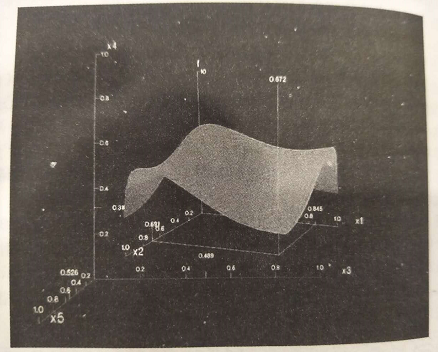
“世界中的世界”又称n-Vision资料来源:http://graphics.cs.columbia.edu/projects/AutoVisual/1.dipstick.5.gif
层次可视化方法的另一个例子是树图(tree-map),它把层次数据显示成嵌套矩形的集合。
例如下图,显示了对Google新闻报道可视化的树图。所有的新闻报道组织成7个类别,每个显示在一个维-颜色的举行中。在每个类别内(即在最顶层每个举行内),新闻报道进一步划分成较小的子类别。

新闻图:使用属兔对Google新闻报道标题可视化。资料来源:www.cs.umd.edu/class、spring2005/cmsc838s/viz4all/ss/newsmap.png
1.2.6 可视化复杂对象和关系
可视化技术除了对于数值数据,还包括对非数值数据的可视化技术,如文本和社会网络可视化已经成为可利用的,且备受关注。
许多可视化技术专门用户非数值类数据,如Web上许多对诸如图片、博客和产品评论加标签。
标签云,是用户产生的标签统计量的可视化技术。在标签云中,标签通常按字母次序或用户指定的次数列举。如下图,显示了一个对Web站点使用的流行标签可视化的标签云。

使用标签云对Web站点上使用的流行标签可视化。资料来源:www.flickr.com/photos/tags/2010年1月23日快照
通常,标签云用法有两种,一是对于单个术语,我们可以使用标签的大小表示该标签被不同的用户用于该术语的次数,二是在多个术语上,可视化标签统计量时,我们可以使用标签的大小表示该标签使用的次数,即标签的人气。
除了复杂的数据之外,数据项之间的复杂关系也可视化提出了挑战。
例如,下图使用疾病影响图来可视化疾病之间的相关性。图中的结点是疾病,每个结点的大小与对应疾病的流行程度成正比。如果对应的疾病具有强相关性,两个结点用一条边连接。边的宽度与两个对应的疾病的相关程度成正比。
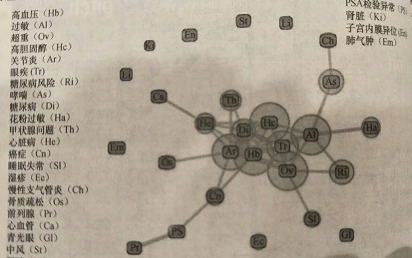
NHANES数据集中20岁以上的人的疾病影响图
综上所述,可视化技术为探索数据提供了有效的工具。我们介绍了一些流行的方法和他们的基本思想。有许多现成的工具和方法。
此外,可视化可以用于数据挖掘的若干方面。除了数据可视化之外,可视化也可以用于表现挖掘过程、从挖掘方法得到的模式,以及用户与数据交互。可视化挖掘是一个重要的研究开发方向。
本文由 @一毛硬币 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!