
 起点课堂会员权益
起点课堂会员权益搜索引擎中的网页分类技术

1. 技术背景
分类问题是人类所面临的一个非常重要且具有普遍意义的问题。将事物正确的分类,有助于人们认识世界,使杂乱无章的现实世界变得有条理。自动文本分类就是对大量的自然语言文本按照一定的主题类别进行自动分类,它是自然语言处理的一个十分重要的问题。文本分类主要应用于信息检索,机器翻译,自动文摘,信息过滤,邮件分类等任务。文本分类的一个关键问题是特征词的选择问题及其权重分配。
在搜索引擎中,文本分类主要有这些用途:相关性排序会根据不同的网页类型做相应的排序规则;根据网页是索引页面还是信息页面,下载调度时候会做不同的调度策略;在做页面信息抽取的时候,会根据页面分类的结果做不同的抽取策略;在做检索意图识别的时候,会根据用户所点击的url所属的类别来推断检索串的类别等等。
2. 自动分类的原理和步骤
在分类的时候首先会遇到文档形式化表示的问题,文档模型有3种:向量空间模型,布尔模型和概率模型,其中我们常用的是向量空间模型。向量空间模型的核心描述如下:
- 文档(Document):文本或文本中的片断(句子或段落)。
- 特征项(Term):文档内容用它所包含的基本语言单位来表示,基本语言单位包括字、词、词组、短语、句子、段落等,统称为特征项。
- 特征项权重(Term Weight):不同的特征项对于文档D的重要程度不同,用特征项Tk附加权重Wk 来进行量化,文档D可表示为(T1,W1;T2,W2;…;Tn,Wn)
- 向量空间模型(Vector Space Model):对文档进行简化表示,在忽略特征项之间的相关信息后,一个文本就可以用一个特征向量来表示,也就是特征项空间中的一个点;而一个文本集可以表示成一个矩阵,也就是特征项空间中的一些点的集合。
- 相似度(Similarity):相似度Sim(D1,D2)用于度量两个文档D1和D2之间的内容相关程度。当文档被表示为文档空间的向量,就可以利用欧氏距离、内积距离或余弦距离等向量之间的距离计算公式来表示文档间的相似度。
其中特征选取是文本表示的关键, 方法包括:文档频率法(DF)、信息增益法和互信息法等等。
在做特征选取之前,一般还要进行预处理的工作,要对先对网页降噪。另外在实际的分类中,除了利用文档的内容特征之外,可能还会用到实际应用中所特有的特征,比如在网页分类中,可能用到url的特征、html的结构特征和标签特征等信息。
分类的基本步骤是这样的:定义分类体系,将预先分类过的文档作为训练集,从训练集中得出分类模型,然后用训练获得出的分类模型对其它文档加以分类。
3. 常用的分类算法
文档自动分类是学术界研究多年,技术上比较成熟的一个领域。目前分类算法主要分下面这些:
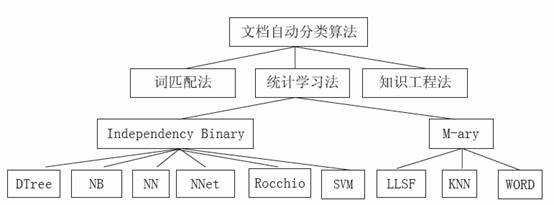
其中比较常用的是:支持向量机(SVM)方法、朴素贝叶斯(NB)方法、神经网络(NN)方法、K近邻(KNN)方法、决策树(Decision Tree)方法等。
- 支持向量机(Support Vector Machines, SVM)由Vapnik在1995年提出,用于解决二分类模式识别问题。它通过寻找支持向量来确定决策面,并使分类间隔最大。SVM方法提供了解决 “维数灾难”问题的方法。SVM方法较好的理论基础和它在一些领域的应用中表现出来的优秀的泛化性能,尽管SVM算法的性能在许多实际问题的应用中得到了验证,但是该算法在计算上存在着一些问题,包括训练算法速度慢、算法复杂而难以实现以及检测阶段运算量大等等。
- 朴素贝叶斯(Naive Bayes,NB) 概率分类器是机器学习中很常用的一种方法,其基本思想是利用单词和分类的联合概率来估计给定文档的分类概率。
贝叶斯公式:P(C|X)*P(X)=P(X|C)*P(C)
特征向量:X=(x1,x2,x3…) C={C1,C2,……}
其中P(C)是每个类别的先验概率,即,互联网上各个分类所占总页面的比例
P(X|C):条件概率,表示在类别为C的训练集合中,X的分布情况。
P(X):每个特征值的分布,由于特征值的分布是随机的,所以P(X)相等
- 神经网络(Neural network,NN)技术是人工智能中的成熟技术。将神经网络用于文档分类时,需要为每个分类建立一个神经网络,通过学习得到从输入单词(或者更复杂的特征词向量)到分类的非线性映射。其计算量和训练时间非常庞大。
- KNN是著名的模式识别统计学方法,已经有四十年历史,它是最好的文本分类算法之一。KNN算法相当简单:给定一个测试文档,系统在训练集中查找离它最近的k个邻居,并根据这些邻居的分类来给该文档的候选分类评分。把邻居文档和测试文档的相似度作为邻居文档所在分类的权重。如果这k个邻居中的部分文档属于同一个分类,则该分类中的每个邻居的权重求和并作为该分类和测试文档的相似度。该方法的特点是允许文档可以属于多个分类。KNN通过查询已知类似的例子的情况,来判断新例子与已知例子是否属于同一类。
通过我们对现实网页的分类测试情况看,这些方法中SVM方法的效果是比较好的,但是性能不高; 朴素贝叶斯的分类效果虽然略差于SVM,但是性能上要好很多。
4. 网页分类应用
4.1分类算法
实际应用中, 除了分类效果外, 速度是一个需要重点考虑的因素。
4.2分类类别
在搜索引擎中, 在不同的应用场景下, 会有不同的分类的标准, 比如在链接调度中需要信息页、索引页这样的分类,不同类型的页面更新调度的周期不一样;排序对分类的要求又不同, 比如按表现形式分图片、视频等;按网站类型分为论坛、博客等,不同类型的页面抽取策略也会不尽相同;再按内容主题分成小说、招聘和下载等类别。对网页从多个维度进行分类,能更好给用户提供更为贴切的检索结果。
4.3 特征选取
在学术研究中, 一般比较重视分类算法的研究,在特征选择上比较忽视。传统的特征选择一般是用TF*IDF等方法选择内容关键字等,这也是我们使用的一个重要因子, 但是除内容特征之外,我们还会用到很多其它特征,比如:网站特征、html特征和url特征等,这些特征会明显的提高分类的准确率和召回率。
本文来自:http://blog.qq.com/qzone/774789782/1300432753.htm






- 目前还没评论,等你发挥!


