
 起点课堂会员权益
起点课堂会员权益内容处理和分发中的算法应用探究
现如今,算法已被应用到互联网各领域之中,其中以媒体内容领域尤为突出。算法不仅能实现多样化、个性化的内容精准推荐,还能赋能内容生产,辅助内容运营。

近期,腾讯PCG新闻产品技术部算法中心李彪应邀来到腾讯媒体研究院作内部分享,详细梳理了算法应用产品场景,以下为部分内容实录。
今天我跟大家分享的主题是算法赋能的内容处理和分发,重点讲一下内容处理。开始之前,先介绍一下算法在腾讯新闻的应用场景。

第一个,腾讯新闻APP中各种内容形态(如图文、视频、音频、话题、问答等)的理解和分发,涉及推荐系统,以及AI算法赋能内容的运营。
第二个,将腾讯新闻推送到微信,每次一个大图和三条新闻资讯,一共四条,点进去有些底层页能跳转到腾讯新闻APP。
第三个,海豚智音,一个“听新闻”神器,主要用于智能音箱、车载音响和智能家电,目前能提供市场上70%的语音资讯;它涉及语音摘要、语音录制和个性化语音推荐算法。
第四个,辅助创作(Dreamwriter),涉及写稿、内容创作、筛稿、配图等非常多的东西,也是本文介绍的重点。
一、算法的框架
算法整体框架由底层算法和上层应用组成。底层算法有NLP方面的词法、句法、篇章理解等、视觉方面的图像质量、图文匹配、图像视频理解等算法,还有针对搜索的一些基础算法。
底层算法的上面嫁接了两大类应用,分别是推荐系统和搜索,推荐系统可分为五步。
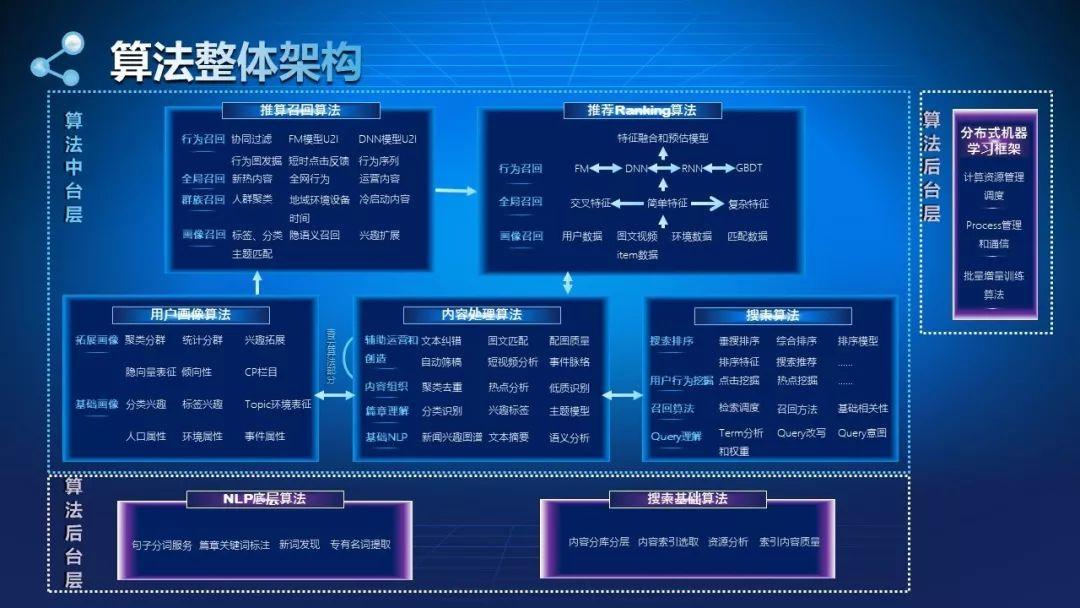
1. 内容处理
它也称内容管理系统,里面嵌入了文本分类、打标签、摘要提取、语意分析、内容去重、内容分析、纠错、配图、筛稿等等和内容处理相关的算法。
2. 索引
将初选完后的内容,即预备分发给用户消费的图文、视频等资讯,加入索引。
3. 画像
它可分成基础画像和拓展画像两部分。基础画像通过用户分类、Tag等兴趣点、用户基础属性、用户地理位置、用户使用时间段等情况,为用户提供个性化推荐;还可以借鉴第三方提供的画像,为用户做相应的推荐。
拓展画像会有一些隐式标识,比如根据他点击过的新闻序列,用一个向量描述他的兴趣点,而不是将他的兴趣划入某个分类或标签,这个向量也会用在召回和排序中。
4. 召回
根据用户画像描述的用户兴趣以及用户行为序列,在库中找他需要的文章。
比如通过画像的标签进行召回、通过模型预测用户的画像和文章的匹配度进行召回、根据用户的行为序列进行召回等等。
召回时,还要综合考虑文章的热度,比如四川地震可能不是用户的兴趣,但是是近期热点,也要召回,让用户消费这篇资讯。
此外,还得考虑人群聚类,用户可能和其他人群有类似的兴趣,但不体现在用户标签中,这时就需要做一些聚合,把别人喜欢的东西推荐给用户。
最终通过上面多种召回途径在库里找出比较大的候选文章集合,准备推荐给用户,但最终只展示一部分,因此需要进入精排选出top的。
5. 精排
这里面涉及到排序算法,把底层最基础的数据维度,比如用户维度、内容维度等设计出各种角度的特征。
包括简单的值特征,以及交叉特征,甚至复杂的模型计算出的特征,输入到DNN+FM模型做点击和时长预估。
它的目的是从而从几千篇候选资讯中筛出几十篇,为什么不是10篇、20篇呢?
因为这中间要考虑业务需求,比如多样性因素,不能把用户感兴趣的资讯全给堆出来,要讲究文章的多样性,这里面就涉及到去重打散,要给用户更多的候选文章。
二、算法赋能内容
算法赋能内容运营,在公司内部叫青云项目,英文是Dreamwriter,它的主要目的是通过算法来辅助内容的运营,提高它的工作质量和效率。

新闻内容运营和流程
先看看这个项目的背景,作为公司级的内容媒体平台,有非常多的稿件要入库,存在稿件的精编、纠错、筛稿、配图、视频增量和热点监控这六大问题,整个流程非常耗时。
这挤占了编辑参与深度创作的时间,我们需要通过算法来解放他,让他更好地创作。
三、算法还能做什么?
1. 自动写稿
辅助创作算法(Dreamwriter)能写短文、能写长文,它是如何做到的呢?
答案是基于模版的方法来写作。
实际套路是根据原始的数据抓取或者是采买一些实时数据格式化入库,然后进行逻辑的判断,再根据信息的类型、类别选择相应的模版生成稿子去发布。

这里有两个疑问:如何构造模版库呢?如何做逻辑判断呢?
构造模版库时,先通过人工,比如编辑和运营会先写比较简单的稿件模版,基于这个模版,我们通过算法去迭代。
然后通过模版填充了一些词,再挖掘出词在不同语境下的不同模版,再循环迭代挖掘得到更多的模板。模板进入模板库前,需要人工根据判断准则审核一下。
接下来,我们再结合深度学习生成的模型,提升模版的多样化。
比如一句话的表述,它可以表述成A,也可以表述成B。通过算法找出A和B的变化,最简单的是进行同义词的替换。最后再攻克表述衔接性的问题,就能得到一个更好的模版库了。
有了模版库之后再进行逻辑判断,这时更多的根据内容源、所属的场景类别决定使用哪些模版。我们现在的模版范围挺大的,有一些类别是不需要人工审核,就可以直接发稿。
不过当前业界能自动写稿的场景还是比较有限的,从流程看它比较依赖于算法挖掘出来的模版,当模版没有套路时就很难做。
比如让它写一篇文学作品,当前是做不到的,因为它需要巧妙的构思。
如果让它写一篇财经报道或者球赛报道,由于模式比较固定,机器肯定会做得很好。
此外,生成式机器写稿还存在一些问题,比如新冷词不能很好地嵌入到文章里、生成的句子会重复等。
2. 自动配图
这个工作在新闻里面非常重要,它的目的是提升用户体验,吸引用户去浏览资讯。
- 有些文章是没有图片的,如何通过算法给它配图?
- 当文章比较长的时候,如何实现分段配图?
- 有的文章里面只有一两张图,由于三图文的点击率会比单图的高,如何凑满三张图呢?
- 有时图片比较多,如何选出高质量的图,还和语意匹配呢?
最开始选图时,只要能过滤掉表情图、微博、文字图和表格图就行,这时使用图像的分类模型就能实现,缺点是有时候它选出来的图和文章的语意匹配度不好。
举个例子,比如之前网上画了一个户型图,标题是君住长江尾我住长江头。意思是说房子特别长,你住这头,我住那头,每天要跑很远才能见面。
第一版配的图是它的报价,但是户型图没有配。
后来利用图文语意匹配的模型解决了上述问题,整个语义匹配模型准确度超过90%,如何实现的呢?
先对标题或者正文的内容做一些标识,训练时计算正例的图片特征和负例的图片特征之间的相对距离差,大于一个阈值,就认为语意匹配成功,即正例的图片比负例的图片和文章主题更贴近。
这里引出另一个问题,即如何选正例的图片和负例的图片?
通过人工在之前分发过的文章列表中,找和文章语意最相似的图片作为正例;至于负例,将在正文里面达到一定条件的图片作为负例,或者随机采一些负例。
在上述基础之上,对于无图的文章,我们先建立一个图库。这个比较简单,可以和第三方合作。
还将历史分发的有问题的图片建立另一个图库,并监控它的标签。
有了图库,无图、少图、多图的文章面临的配图难题就迎刃而解了。不过模型还需要进一步的改进,比如图像所处的位置和文本的匹配,再比如图像主体和文章想描述的主体之间的语义匹配。
3. 自动提取摘要
它可分为两种:一种是全文摘要,另一种是分段摘要。
如何提取摘要呢?整个过程可分为四步。
第一步是预处理,做一些片断的分析,比如图像的注释不适合做摘要,比如整篇文章没有几个字也不适合做摘要。
第二步是给句子打分,就是看看文章的哪些句子更可能被选为摘要的句子。假设跟文章标题最相关的句子作为摘要候选的句子,据此提取很多特征,比如句子的位置,在段首或者段尾的句子更有可能表达最重要的信息。
第三步是句子选择,结合句子打分再考虑冗余性和连贯性来筛选句子。
筛选句子时,会遇到候选句子有很多的情况,需要去掉冗余。这时先从库中选一个句子,再和已选的句子集合进行匹配,相似度高的句子就放弃。还会遇到句子评分很高,但不能体现文章的核心内容的情况,这时需要做一些处理。
第四步是后处理,对选出来的句子做一些融合,再形成摘要,再然后通过人工评价内容是否通顺、信息覆盖是否全。
此外,智能的语音资讯也不能太长,因为10分钟或5分钟的语音会让用户很烦燥。这时需要对一篇新闻资讯提取出几个摘要,确保一分钟之内就能读完。
4. 自动生成短视频
基于摘要配图,再综合文本,就能自动生成短视频,即图文转视频。
有些文章,特别是娱乐类的图片比较多,文字也不少,但是没有对应的视频,怎样才能把这些图文修成一个视频呢?
先出一些摘要,再把摘要的句子打散,把这些句子配到每一个图片上面。
然后通过人工录播或合成人声搞定声音,再做图像之间的渲染和背景音乐的选择,就生成了一个视频。
虽然它跟真实的视频有一些差距,但是它的效果还是非常好的。
对于图片比较少的文章,不足以支撑几十秒的视频时,需要通过自动配图先给它配一些图,再通过自动提取摘要萃取文章精华,最后自动生成短视频。
5. 分类平台
AI辅助运营时,有很多分类,比如文章质量分、调性分、自动筛稿、一级分类、二级分类、地域分类、题材分类,归根到底,从算法的角度来说就是分类任务。
最难的就是定义分类的标准,比如说按照质量分,质量分为三级,什么是一级、二级、三级,肯定有一个标准。
在这个过程,编辑老师需要和算法团队频繁沟通如何制定标准,如何标注数据,还得不断反馈这些标注的质量。
标准确定后,累积一定样本就可以通过文本分类方法来做,我们分类平台能自动训练,模型选择,评估和在线服务化。
6. 自动纠错
由于错别字的范围不太好限定,所以错别字的纠正非常难。
常见的同音或近意错别字,比如发标、发表,很容易纠正。
再难一点的是搭配错误,词或者是字本身没有错误,但是它不适合在这个语境用,搭配错误涉及到长距离的语意搭配错误(比如第一遍和第二遍的内容不一样)和短距离的语意搭配错误。
更难的设计知识内的错误,比如政治问题或者历史人物信息等错误。
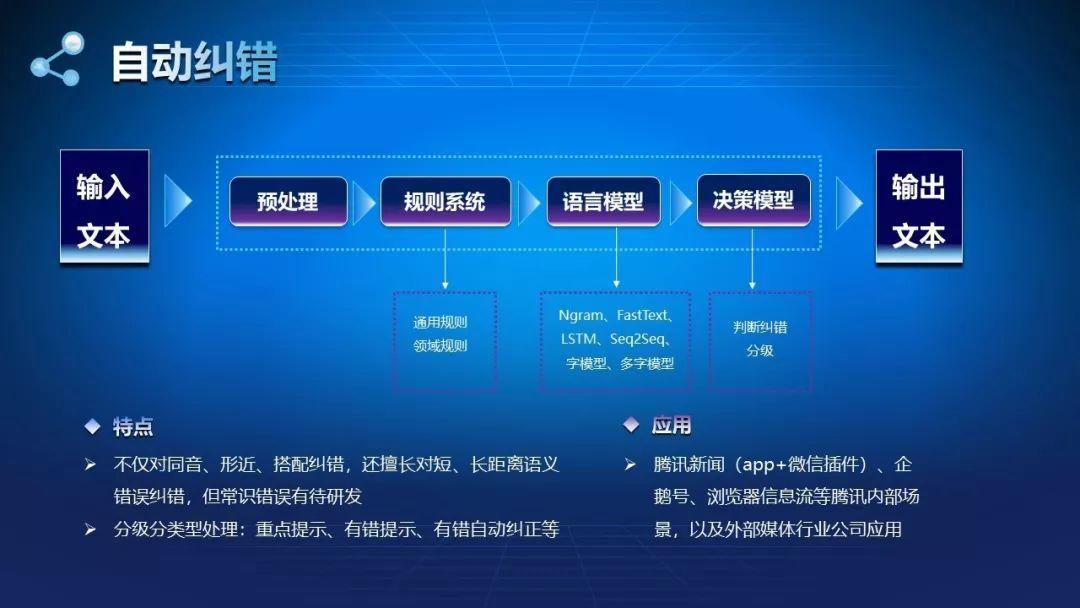
从应用角度来讲,靠算法纠错有时候不一定很准,有些本身没有错误但算法提示错误,比如某一个人物讲的话,这时需要标红提醒一下。有时这个地方可能错了,但算法没有找到合适的词去纠正,就有错误提醒。
自动纠错大体可分为两步:
第一步是对输入的文本先进行预处理,再加入一个规则系统。通用规则有成语、谚语,它是约定俗成的,字不对的话直接纠正过来就行。
第二步是通过模型纠正中高频词,通过自创方法纠正低频词。一般某一个字错了,它的分词也是错的,这种需要结合上下文进行纠正,是比较难的。对于高频词的纠正,可以通过算法模型学习来实现。对于低频次,就非常难学好。
7. 生成简报
即综合好几篇文章,自动生成一篇综合性的文章,这个完全由算法来做。怎么做呢?
首先是选文章,根据过去一天里用户反馈的信息,拿出一个候选的文章集合,再从每篇文章里抽取摘要。然后是配图和选图,这样就得到了一个由标题、摘要和图片组成的比较短的内容,之后把这些文章整合在一起。接下来就是生成一个让用户更容易点的标题,最后需要人工审一下。
8. 热点监控
热点监控会对不同来源的热点做实时监控。监控之前需要更快地找到热点,如何实现呢?
第一种是通过微信和微博,微信热点通过内部合作来找到,微博热点通过抓取大V之间的转发、转评赞等方式发现热点。
第二种是根据用户的消费情况找到热点,相对会滞后一点,比如推荐系统里面的统计热点召回。
第三种是通过库存的网站发现所谓的热点,比如自媒体的文章同质非常多,通过算法得到潜在的热点。
作者:李彪,腾讯PCG新闻产品技术部算法中心。微信公众号:腾讯媒体研究院
本文由 @腾讯媒体研究院 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash, 基于CC0协议






- 目前还没评论,等你发挥!


