
 起点课堂会员权益
起点课堂会员权益什么是BitMap?BitMap技术的原理和应用
抖音、快手数亿级量级的APP,日活、月活、留存、漏斗分析、多维分析等是如何做到秒级响应的呢 ?这其中就是BitMap技术。本文作者从多个角度对BitMap展开了分析说明,希望通过此文能够加深你对BitMap技术的认识。

01 什么是BitMap?
此BitMap不是指图片存储格式里的位图。
Bit即比特,是目前计算机系统里边数据的最小单位,8个bit即为一个Byte。一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2.
BitMap可以理解为通过一个bit数组来存储特定数据的一种数据结构;由于bit是数据的最小单位,所以这种数据结构往往是非常节省存储空间。
比如一个公司有8个员工;现在需要记录公司的考勤记录;传统的方案是记录下每天正常考勤的员工的ID列表,比如2012-01-01:[1,2,3,4,5,6,7,8];假如员工ID采用byte数据类型,则保存每天的考勤记录需要N个byte,其中N是当天考勤的总人数。另一种方案则是构造一个8bit(即1byte)的数组,将这8个员工跟员工号分别映射到这8个位置,如果当天正常考勤了,则将对应的这个位置置为1,否则置为0;这样可以每天采用恒定的1个byte即可保存当天的考勤记录。
除了节省存储空间,BitMap结构的另一个更重要的特点,就是很方便通过位的运算(AND,OR,XOR,NOT),高效的对多个BitMap数据进行处理。比如上边的考勤的例子里,如果想知道那个员工最近两天都没来,只要将昨天的BitMap和今天的BitMap做一个按位的OR计算,然后检查那些位置是0,就可以得到最近两天都没来的员工的数据了,比如:
BitMap在有的文档里也称为:bit array, bitset或者bitstring。关于BitMap技术的详细信息,可以参考http://en.wikipedia.org/wiki/Bit_array
Java SDK里边有提供BitMap的实现:java.util.BitSet
02 BitMap在统计系统里边能做什么?
例子 1:针对独立用户的统计。比如想知道某个应用,每天有多少个独立用户使用了该应用?可以根据该应用的用户访问日志,每天生成一个BitMap;每个用户对应BitMap里的一个位置,如果当天访问了,该位置就置为1,否则为0。这样要知道当天这个应用的总独立用户数,只需要看看那天的BitMap里边有多少个1。
对于10M(1000万)用户的应用,每天需要的BitMap大小为10M/8=1.25MB,即只需要1.25兆字节。在采用一些压缩技术的基础上,可以进一步缩减需要的存储量,一般情况下可能只需要大约100-200KB的存储即可。
例子2:用户回访的统计。比如想知道某个应用,昨天使用过的用户中,有多少今天也使用了?可以在例子1(每天保存一个独立活跃用户的BitMap)的基础上,将昨天的BitMap和今天的BitMap进行AND操作,然后数一下生成的BitMap里有多少个1即可。
03 怎么将用户映射到BitMap里边的某个位置?
使用BitMap的时候,都需要将原始数据(比如用户)映射到BitMap里的位置;这种映射一般可以采用外部数据(比如在数据库里保存用户到BitMap位置的映射),或者采用固定的规则(比如计算用户名的hash code)。
采用第一种方法时,通常是在数据库里边给用户分配一个数值型的用户ID,而用户ID的生成规则采用自增量的方式来产生;这样比如有100个用户,则其用户ID为1,2,3,…,98,99,100;用户ID为1的用户映射到BitMap里的第1个位置,用户ID为2的用户映射到BitMap里的第2个位置…(问题:如果自增量的初始值不是0,而是比如10000,会产生什么影响?)
采用自增量的另外一个好处是,系统用户数少的时候,BitMap需要的位数也少;当用户量增长时,BitMap的位数跟着增长即可;而且如果记住每天的总用户数,BitMap里边还可以直接表明每天的新增用户是哪些(注意:此处对于我们的分析系统不一定适用)
采用第二种方法时,最常使用的规则是计算用户的hash(比如Object.hashCode,或者MD5);但由于hash生成的数字分布很宽(比如java里边Object的hashCode会返回一个int,所以其分布是-231 – 231-1),但需要的BitMap的位数往往不用那么大,这样就需要再做一个hashcode到BitMap里位置的映射(一般是取余数),这就要求必须预先知道BitMap的大小,且这个大小一般要求保持不变。
比如要求将用户映射到一个1024位的BitMap:用户A的hashcode是101,101除1024取余数是101,所以用户A就对应BitMap的第101位;而用户B的hashcode是1234567,1234567除1024取余数是647,用户B就对应BitMap的第647位。
第二种方法由于采用固定的规则来计算映射,而不需要去做外部数据查询,因此映射这部分的开销会较第一种方法低很多。但第二种方法也有两个缺点,其一是如果预期总用户量会增长到1百万,即使目前系统只有1000个用户,也需要一个1百万位的BitMap,这样会造成很大的存储和计算资源的浪费;其二是hashcode有冲突的问题(即有可能用户C和用户D计算出来的hashcode是一样的);
而hashcode到BitMap里位置的映射也会造成更多的冲突(比如用户E和用户F的hashcode分别是12345678和12377422,但除1024取余后都是334)。这些冲突的存在,导致了数据可信度的下降,比如BitMap里的第334位为0,则可以知道用户E和F都不在;但如果第334位为1,则并不知道用户E或者用户F是不是在。
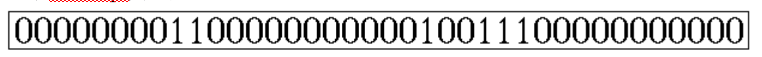
采用第二种方法的BitMap,有一个更广为人知的名字,即Bloom Filter (http://en.wikipedia.org/wiki/Bloom_filter)。 Bloom Filter经常用于文本分析中来记录某个词是否已经出现;或者垃圾邮件过滤中来检查邮件地址是否在已知的垃圾邮件地址列表里。
04 分析系统里,同一个用户在不同的应用里边,是映射到同一个位置,还是不同位置?
在我们的分析系统里边,一个用户/设备会同时使用多个应用;但主要的分析,都是基于某个应用来做,这种情况下就涉及到几个问题:
- 是在全局给用户分配统一的ID,还是在每个应用里边,对同一个用户会分配不同的ID?
- 也就是说,某个应用的BitMap,是根据所有应用的总用户数,还是这个应用自己的总用户数,来确定其BitMap的大小?
比如所有应用总共有1亿用户,应用APP1有1百万用户,应用APP2有50万用户,用户USER1同时使用APP1和APP2,那么以上的问题也就是:
- 核心问题是:用户USER1是始终映射到位置12345,还是在APP1里映射到123,而在APP2里映射到234?
- 由此引申的是:要记录APP1的活跃用户,是要维护一个1亿位的BitMap,还是维护一个1百万位的BitMap?
显然,这两种映射到选择影响到以下几点:
- 需要的BitMap的大小
- 需要维护的用户到用户ID映射表的大小
- 方便针对同一个应用的分析,还是方便针对用户的跨应用的分析?
采用全局用户ID的方案分别由下边的优缺点:
优点:
- 用户到ID的映射表较小,容量可控
- 用户的ID全局一致,便于跨应用来分析用户行为
缺点:
- 每个应用都需要很大的BitMap,造成BitMap空间的浪费;不过这个可以通过BitMap的压缩技术来改善
- BitMap里边不能很直观的反应:应用的总用户数和哪些用户是当天的新增用户,从而计算用户回访/保持需要额外的计算
采用在应用级别分配ID的方案则有如下的优缺点:
优点:
- BitMap空间的浪费少(不过引入压缩技术后优势应该不明显)
- 要是应用每天都有新增用户,从BitMap的大小,基本就可以知道应用的总用户数
- BitMap里边直观的包含了每天的新增用户信息,便于做用户回访/保持分析。
缺点:
- 需要维护更大的用户到ID的映射表;由于这个表在处理中有很大的查询量,有可能对该表的查询成为性能瓶颈
- 很难满足跨应用的分析,比如计算两个应用的重合用户
由此可见,采用什么样的映射方案可以获得最大性能/最方便的实现,跟要做什么样的分析直接相关。
拿计算用户回访为例,需要计算APP1昨天新增的用户,今天有多少人继续使用了APP1?
对于使用全局用户ID的方案,需要通过数据库,查询出APP1昨天新增的用户是哪些,他们的用户ID是多少,由此构造一个昨天新增用户的BitMap;然后将该BitMap和今天的活跃用户的BitMap进行一个AND操作,就可以知道其中哪些用户今天继续使用了APP1;然后做一个计数就可以得出人数。
而对于使用应用级别用户ID的方案,假如前天APP1的用户总数是1000,昨天是2000,那么就知道昨天新增的用户在BitMap里边是位置1000-2000;那么要计算今天的回访,只需要加载今天的BitMap,看看1000-2000这个位置范围内有多少个1就可以了。
05 如果要记录用户的多维信息,能否用BitMap实现?
统计系统中经常需要对用户进行多维分析;这些维度信息通常分为两类,一类是比较静态的,比如用户的性别,用户使用的手机类型;另一类则更动态,比如用户当前使用的应用版本,本次的联网方式,当天的位置,当天的第一次启动时段,等等。当然静态和动态也不是绝对的,更多还是取决于数据使用者对这些数据动态变化的精确程度的容忍度。
对于相对静态的维度信息,往往不需要在BitMap里保存,而可以在需要使用的时候,通过对主数据进行查询动态生成;即使在较大数据量下,这类简单查询的性能一般还是可控的。
例如要计算:昨天新增用户,且在今天继续使用的用户里边,三大运营商各占多少?可以对用户表做全表扫描,读取用户ID和运营商字段,根据运营商的不同,生成3个BitMap分别对应三个运营商的客户;然后将这3个BitMap和计算好的回访的BitMap进行AND,即可知道回访用户中运营商的分布情况了。
这种方案中有对用户表的全表扫描,估计很多人会想到另一个方案,就是对计算好的回访用户BitMap进行扫描,然后根据回访用户的用户ID去查询其对应的运营商信息,这样可以规避全表扫描;但实际中这两种方案该如何取舍却并不容易;因为全表扫描虽然需要访问的数据量很大,但可以保证是顺序的读取;
而通过用户ID去查询器运营商,则不一定是顺序的读取(跟这个数据库表的设计相关;因此要采用此方案,或者是回访的用户量较小,或者此处的查询要保证是对数据库文件的顺序读取);如果有大量的随机访问,反而性能有可能更差。因此选择什么方案还是需要具体分析。
对于某些动态数据,可能确实需要通过BitMap记录更多的数据(一般都是枚举类型的,也就是在几个可能的值中取一个),而不只是boolean型的true/false;这种情况下就需要用多个BitMap来表达了。
最简单的方案就是针对每个可能的取值,采用单独的BitMap来存储;比如说应用有1.1, 1.2和2.0三个版本,而用户可能在不同的版本之间切换;如果要记录用户每天使用的版本,则可以维护3个BitMap。第一个BitMap保存使用1.1版本的用户信息,第二个保存使用1.2版本的,第三个保存使用2.0版本的。
另一种方法是采用多个BitMap联合来表达;比如还是上边的例子,可以只适用2个BitMap即可:使用1.1版本的用户,在第一个BitMap里为0,但在第二个BitMap里边为1;使用1.2版本的用户,在第一个BitMap里为1,但在第二个BitMap里为0;而是要2.0版本的,则在第一个BitMap里为1,在第二个BitMap里也为1。也就是说,将3个版本分别编码为01,10,11;然后用两个Bitmap来分别保存第一位和第二位。
这种方法比前一种会更节省,但同样也会带来计算上会更复杂一些。
06 如果系统总用户有一千万,但今天只有100个用户活跃,是否还需要花费1.25MB的空间来保存这个BitMap?
利用BitMap来保存系统的活跃用户,一般的情形都是系统的总用户数会很多,比如是千万甚至亿级别的;但大部分应用的日活跃用户则只是十万或者万级别甚至更少;这必然引出一个问题,就是用一亿位的BitMap,来保存1万的活跃用户信息,岂不是有很多空间都被浪费了?
进一步分析下,浪费的有两个部分:其一是存储空间的浪费,BitMap需要保存到外部存储(数据库或者文件),计算时需要从外部存储加载到内存,因此存储的BitMap越大,需要的外部存储空间就越大;并且计算时IO的消耗会更大,加载BitMap的时间也越长。其二是计算资源的浪费,计算时要加载到内存,越大的BitMap消耗的内存越多;位数越多,计算时消耗的cpu时间也越多。
对于第一种浪费,最直觉的方案就是可以引入一些文件压缩技术,比如gzip/lzo之类的,对存储的BitMap文件进行压缩,在加载BitMap的时候再进行解压,这样可以很好的解决存储空间的浪费,以及加载时IO的消耗;代价则是压缩/解压缩都需要消耗更多的cpu/内存资源;并且文件压缩技术对第二种浪费也无能为力。因此只有系统有足够多空闲的cpu资源而IO成为瓶颈的情况下,可以考虑引入文件压缩技术。
那么有没有一些技术可以同时解决这两种浪费呢?好消息是有,那就是BitMap压缩技术;而常见的压缩技术都是基于RLE(Run Length Encoding,详见http://en.wikipedia.org/wiki/Run-length encoding)。
RLE编码很简单,比较适合有很多连续字符的数据,比如以下边的BitMap为例:
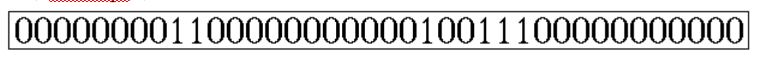
可以编码为0,8,2,11,1,2,3,11
其意思是:第一位为0,连续有8个,接下来是2个1,11个0,1个1,2个0,3个1,最后是11个0。(当然此处只是对RLE的基本原理解释,实际应用中的编码并不完全是这样的)
可以预见,对于一个很大的BitMap,如果里边的数据分布很稀疏(说明有很多大片连续的0),采用RLE编码后,占用的空间会比原始的BitMap小很多。
同时引入一些对齐的技术,可以让采用RLE编码的BitMap不需要进行解压缩,就可以直接进行AND/OR/XOR等各类计算;因此采用这类压缩技术的BitMap,加载到内存后还是以压缩的方式存在,从而可以保证计算时候的低内存消耗;而采用word(计算机的字长,64位系统就是64bit)对齐等技术又保证了对cpu资源的高效利用。因此采用这类压缩技术的BitMap,保持了BitMap数据结构最重要的一个特性,就是高效的针对每个bit的逻辑运算。
常见的压缩技术包括BBC(有专利保护), WAH(http://code.google.com/p/compressedbitset/)和EWAH(http://code.google.com/p/javaewah/)。在Apache Hive里边使用了EWAH。
07 引入BitMap技术后,分析系统可能的处理流程大体是什么样的?
- 数据收集系统收集手机上传数据,然后分发给实时处理系统和批量处理系统;
- 实时系统采用自有计数器程序,或者基于Storm之类中间件的计数器程序,计算各类简单计数器,然后批量(比如30s或者1min)更新到Redis或者HBase之类的存储;前端供应计数器类数据的服务通过访问后台计算器程序或者是计数器存储来给报表系统提供服务;
- 批量系统对该批的init事件按用户进行去重,然后将整理出来的新用户数据批量更新到主数据库;
- 批量系统对该批的init/launch/continue之类的信息综合按(用户+应用)去重,并按用户排序(optional,看具体情况),然后和主数据库join得到用户ID,然后按时间、应用和用户ID排序,批量插入用户活跃行为日志数据库(基于RDBMS或者HBase),并生成/修改 某天/某个应用的活跃用户BitMap,然后批量更新独立活跃用户总数之类的指标。
- 报表中针对独立用户的比较分析需要即时计算;对计算结果可以考虑引入有超时控制的cache。
08 EWAH只支持append,如何回避这个限制?
WAH以及EWAH都只支持append;也就是说,初始化BitMap的时候,只支持从低位到高位的顺序设置;比如设置位置100为1后,就不能再设置低于100的位置的数据了,这对我们的处理,特别是更新历史数据,或造成影响。
由于只支持append,所以要求批处理准备数据的时候,需要对用户ID进行从低到高的排序,这样保证了初始化BitMap时调用set(position)操作也是从低到高,从而规避了不支持append的缺陷。
对于更新历史数据的问题,在可以通过下边的方法解决:只针对本批数据生成活跃用户的BitMap,然后和历史保存的Bitmap进行OR,然后保存新的BitMap即可。
本文由 @高增强 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









更多产品干货请关注公众号:产品人栖息地,作者历任美团、用友一线大厂产品专家,整理一线大厂产品干货,希望帮助应届生/转型求职产品经理的你顺利入职大厂!