
 起点课堂会员权益
起点课堂会员权益新疫苗实验刷屏,科学的AB测试是如何混淆视听的?
编辑导读:AB测试原本是互联网的一种工作方式,在是为Web或App界面制作两个或多个版本,分别让组成成分相同(相似)的目标人群随机访问这些版本,收集各群组的用户体验数据和业务数据,最后分析、评估出最好版本,正式采用。现在被应用到各行业,新疫苗的研发和使用也有涉及。

世界上有三种谎言:谎言、该死的谎言、统计数字。
There are three kinds of lies:lies, damned lies, and statistics.
01 全世界瞩目的两个对照试验
这周频繁被2组对照实验刷屏,都和抗Covid-19有关。国际上对疫情的报道不断,但也没有这两组实验的结果来得刺激。
1. 口罩实验
第一个刷屏的实验,是来自丹麦的 “口罩防护效果” 对照实验,如下图所示。

2020年11月18日, 医学内科领域顶级期刊《Annals of Internal Medicine》发表了一篇“惊世骇俗”的论文, 这个论文提出了一个观点“戴口罩对于防护新冠没用”。这篇论文已经在71 个国际主流媒体上被报道, 推特上已经有55,994个转发和讨论帖。
文中详细描述了,在丹麦进行的、关于戴口罩预防新冠感染的随机对照试验:6000 人随机分成两组,做了两个月试验,外出保持社交距离并戴口罩组的感染率是 1.8% ,外出保持社交距离不佩戴口罩的对照组感染率是 2.1% 。因为两组的感染率差异不显著,结果不具有统计学意义。因此,在这组实验中,结论是 “戴口罩的防护作用是无效的”。
2. 新疫苗实验
第二个刷屏的实验,是登上各大主流媒体重磅头条的“最新疫苗有效性”对照实验,如下图所示。

同样是11月18日,药品制造商辉瑞公司宣布最新实验结果:他们研制的冠状病毒疫苗有效性为95%,且没有严重副作用。Covid-19 疫情在全球范围内急剧上升期间,这组完整的疫苗试验结果给各国都打了一剂强心针。
这项试验包括近 44,000 名志愿者,其中一半人注射了疫苗、另一半人注射的是盐水(安慰剂)。然后,持续观察每组有多少人患上 Covid-19。最终,在 170 例感染了 Covid-19的患者中,安慰剂组占 162 例,疫苗组仅占 8 例。实验初步证明,该疫苗可以预防轻度和重度形式的 Covid-19。如果疫苗的授权审批通过,辉瑞公司将全面投入量产。
02 被大众“误读”的三组数据
对照实验(A/B测试)一直是科学阵地牢不可破的根基,它让我们更接近事情的真相,统计数据的价值也被充分发挥出来。但是,很多实验结果在向大众传播时,信息容易被误读,甚至会成为误导大家的工具。究其原因,只有一个:对A/B测试的理解不准确。统计数字从来不会说谎,说谎的是它们被解读的方式。
1. 1.8% VS 2.1%
前面提到,在丹麦进行的、关于戴口罩预防新冠感染的随机对照试验中,6000 人随机分成两组,试验进行了两个月,戴口罩组的感染率是 1.8%,不戴口罩组的感染率是 2.1%。在统计学上,这两组数据的差异没有显著性。所以,很多人就认为,口罩很鸡肋,对于防护病毒是无效的。
首先,在此研究进行的时候,新冠病毒感染在丹麦还很罕见,且丹麦的人口密集度低,口罩的作用本来就具有很大局限性,以至于该项研究得出的结论并不能反映:1. 在新冠爆发期间,戴口罩的作用;2. 在人口密集的地区,带口罩的作用。
其次,带面罩组有 42 名参与者(1.8%)、对照组有 53 名(2.1%)参与者感染,组间差异为 -0.3 百分点,这个百分点虽然不能说明显著性差异,但是如果换个角度解读,我们却能发现这组数据的可疑之处。
截至目前,丹麦实际的人群感染率约为 3/1000,如果试验扩展到从整个丹麦人口中随机抽取 6000 人,非口罩组的感染人数大致为 9 个,这个数字远远低于实验中的53例。就算口罩可以降低 50% 的感染率(这已经相当高了,现实中不可能),那么,这个假想的实验中,口罩组最多可以减少 4.5 例感染。
而现实中的口罩组,感染人数竟然比对照组少了 11 例,这得多大的预防效果才能存在如此之大的人数差异呀?可见,这组实验结论的漏洞很大。
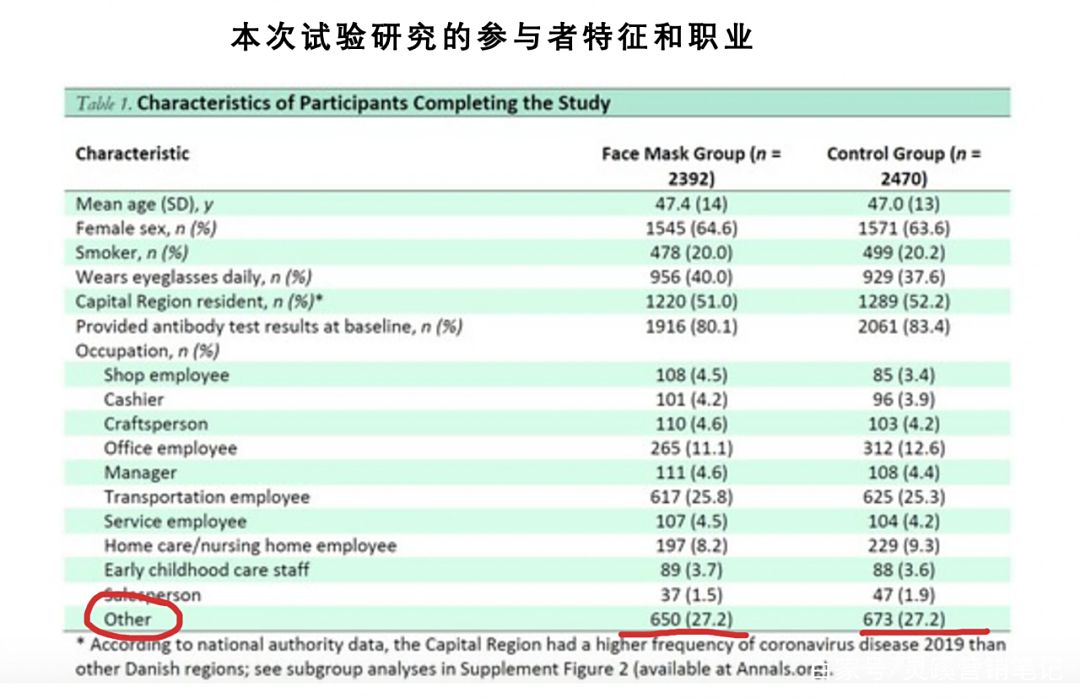
这还没有算上,被招募者的 6000 人,其职业、行动轨迹、行为习惯和身体素质都存在很大差异,如上图所示,仅职业不明的人群就占了总实验人数的 22% 。个体存在的差异会影响最终验证的结果,实验中参杂了太多的无关变量,导致实验结果很难被相信。
2. 大样本量 6000
姑且不谈现实中口罩的应用场景,这里仅深究一下 6000 的 “大样本量” 是否真的合理?
换句话说,3000 对 3000 的实验设计,是否具有预测价值呢?丹麦平均的感染率约为千分之三,依旧假设人群感染率为 3/1000,就算口罩的作用可以降低 1/3 的感染率(降低 1/3 已经是很强的作用了)。那么实验终点,非口罩组和口罩组预期感染人数分别是 9 例和 6 例,这一数字并不具备显著性。即使预期感染率达到 5/1000 (相当于武汉的感染率),那么非口罩组预期感染人数 15 例,口罩组为 10 例,粗略计算, p=0.42,还是没有显著差异……
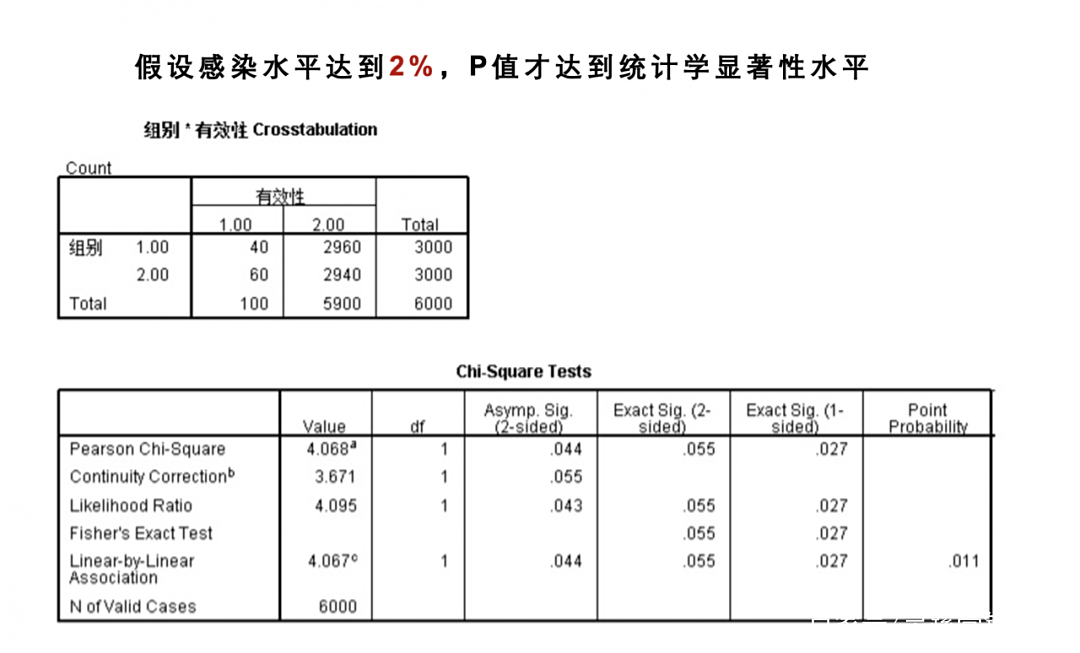
直到感染率达到 2% 的极高水平,非口罩组为 60 例,口罩组为40 例,p= 0.01 ——这时候才达到统计学显著性水平。可见,6000 人的设置并没有结合实际的人群低感染率来进行设计,只需稍微深究一下,就知道禁不起推敲。
换句话说,不是什么情况下,都适合做对照实验的。对照实验并不是万金油,必须和现实情况密切结合。如果实际需求的样本量很大、现实却只能收集很少的样本数据时,这样完成的实验结果,不仅不能说明问题,还很可能造成统计学上的某种误导。
3. 新疫苗功效高达 95%
上文还提到了有关“新疫苗”的试验,其结论也被很多人理解为,如果注射一支疫苗,就可以将感染机率降低 95%。实际上,这个数字也很有误导性。95% 这个数字是怎么来的呢?
以辉瑞公司的实验为例,首先招募了 43,661 名志愿者,研究人员等待 170 人出现 Covid-19 症状,并获得阳性测试结果。在这 170 个阳性结果中,有 162 个属于接受了安慰剂的对照组,只有 8 个是属于接受了疫苗的实验组。
然后,科学家对这两部分患者之间的相对差异做了定义:如果疫苗组和安慰剂组之间的感染人数没有差异,则功效为0%;如果疫苗组无人感染,则功效为100%。
通过计算,我们得出 (100% – 8/162) = 95%,这个数字无疑是证明疫苗有效的有力证据。但是这个数字并不能说明:一旦接种疫苗后,生病的几率是多少。同理,它也不能说明大规模接种疫苗后,接种人群的疫情降低程度。
现实中,接种疫苗后的情况并不好估计,因为参加试验的人员不能反映整个人群的复杂情况,在实际情况中,人们可能会遇到各种各样的健康和反应的差异,仅仅是一次大规模临床实验,根本不能说明其效果。之所以大概率会被推行,是因为事出紧急,疫苗的正面作用一旦被认可,就很可能做大规模的接种。毕竟,减少病毒的传播是第一要务。
但是,如果人们接种了疫苗,然后放松了戴口罩或其他安全卫生措施,则很有可能增加冠状病毒传播给他人的机率,更何况还存在相当数量的无症状感染者。因此,慎重对待特别积极的实验结果,才是更科学的思考方式。
03 给营销A/B测试的启示
A/B测试在广告投放、转化迭代、优惠策略等众多的营销场景中,被广泛应用着。一说如何提高营销 ROI,营销人最先想到的就是“做个 A/B 测试吧,咱用数据说话。”但是,营销中如何让测试数据说出正确的话,而不是像以上两个实验那样,对人产生不必要的误导呢?
1. 测试不是打辅助,测试就是策略本身
与传统决策流程中的归纳后验式不同,A/B测试是一种先验的实验体系,属于预测型结论。和疫苗实验类似,得出的结论很难对全量流量做出预测,但是却可以作为权衡利弊的筹码,帮助你做出重大决策。
这也就带来了一个问题,很多人认为做完A/B测试,验出结果好坏,这个测试就可以结束了,殊不知营销的多变因素不亚于疫苗的接种情况,会遇到各种各样的差异性问题。这就需要营销人员持续地做测试,将测试作为一种手段和策略,而不是只给决策打个辅助,偶尔才用一下。
此外,将A/B测试当作策略、而非辅助,还有两个重要原因:
- 很多时候,做A/B实验时,会不自觉对用户进行筛选,这个时候得出的ROI较高,一旦扩量到全部用户,ROI可能就会降低(类比疫苗实验)。因此在说某个策略的ROI时,需要注意,是否是小规模用户的效率,而不是整体用户的ROI。这个时候,就需要做持续不断的测试,才有可能不断接近目标ROI。
- 还有一种新奇效应递减的情况,也很常见。在出某个新营销页面的时候,用户可能会比较感兴趣,这个时候效果最好。但是过一段时间,用户的新奇感就会消失,需要营销人员做持续、快速的创意测试,以防止因版本效果衰减而带来的转化率大幅波动。
【例子】:
某头部在线教育企业的课程,在移动端推广效率成为其市场部门非常重视的核心指标之一。为提高用户的购买转化,营销和产品部门合作,决定通过A/B测试找到优化方案。
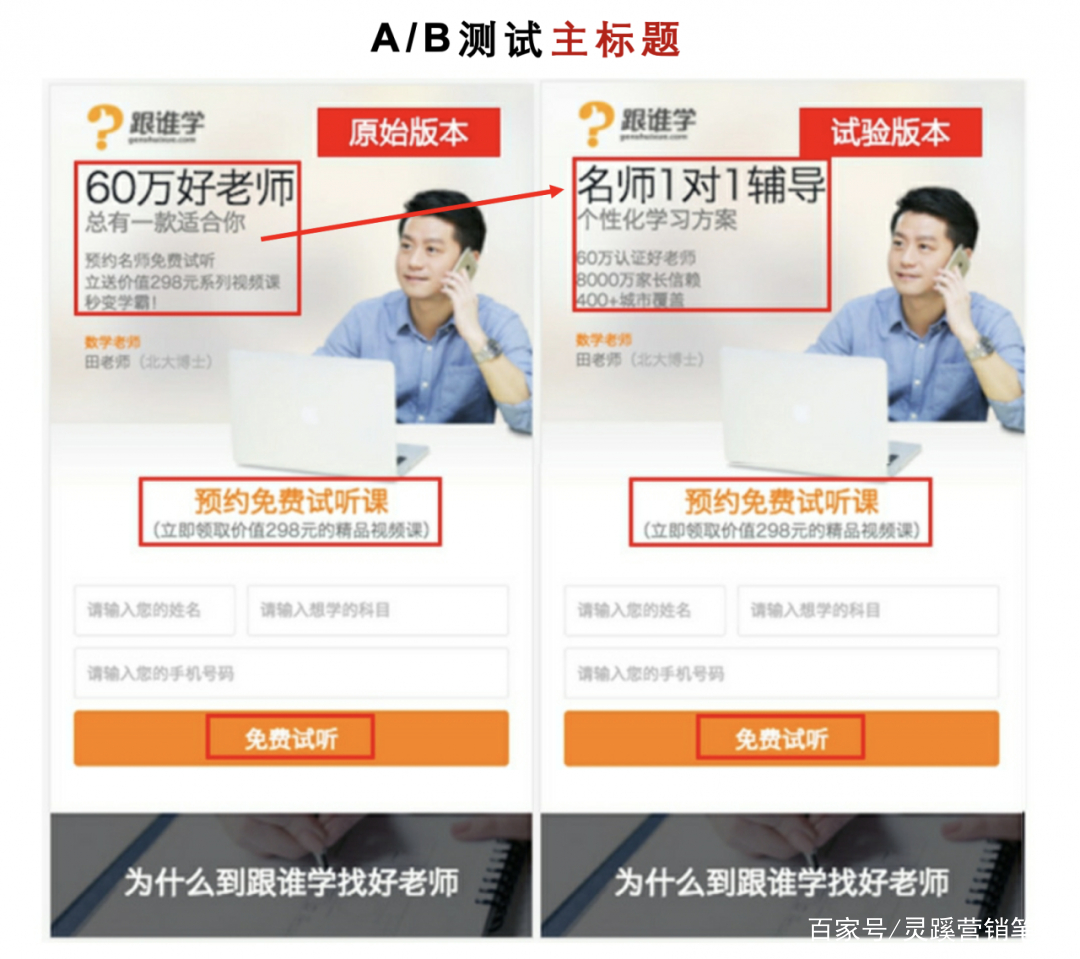
第一次测试,修改主标题,原版本的 “60万好老师”改为“名师1对1辅导”,转化率提升 3% 左右,采用试验版本。
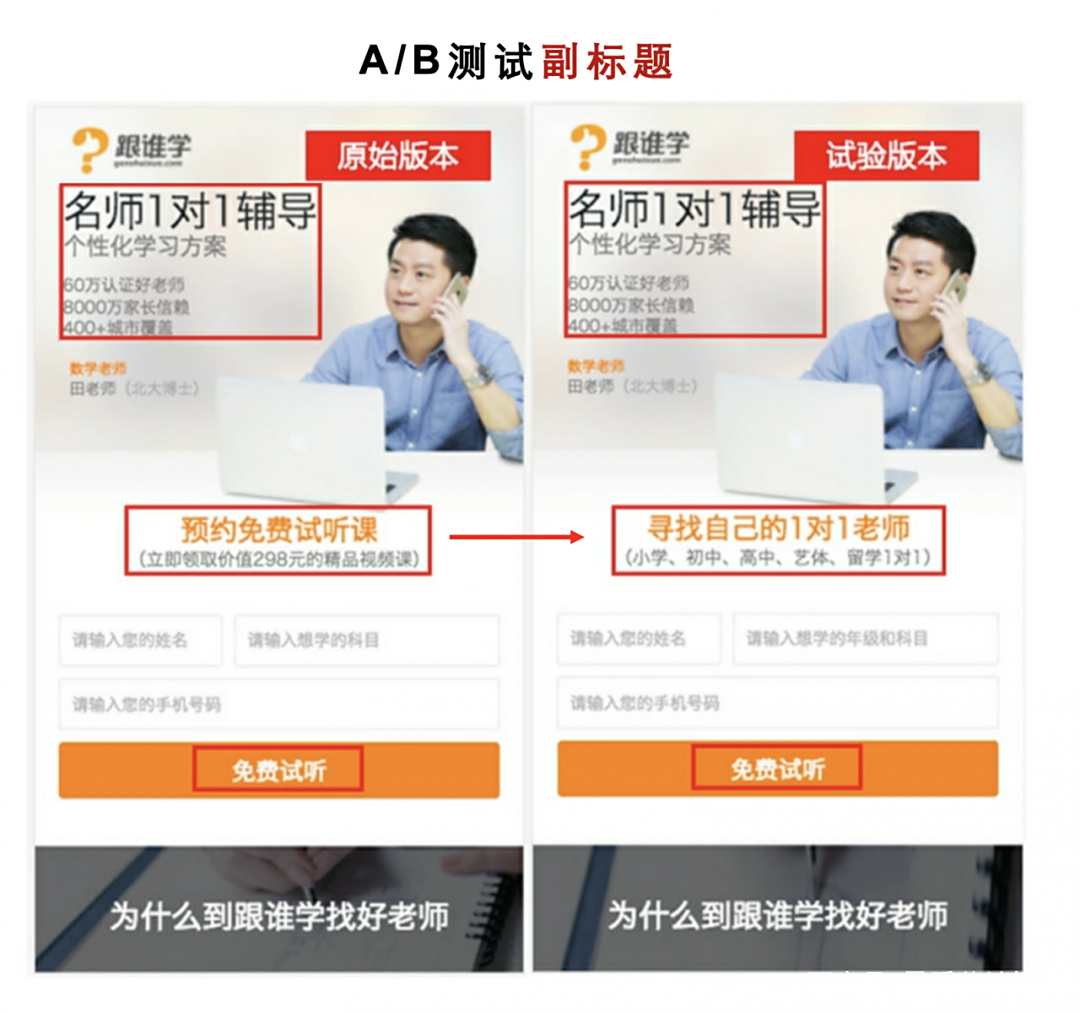
第二次测试,改副标题,结果原版本的“预约免费试听课”比测试版的“寻找自己的1对1老师”,转化效果要好 4.7%,于是继续采用原版本。
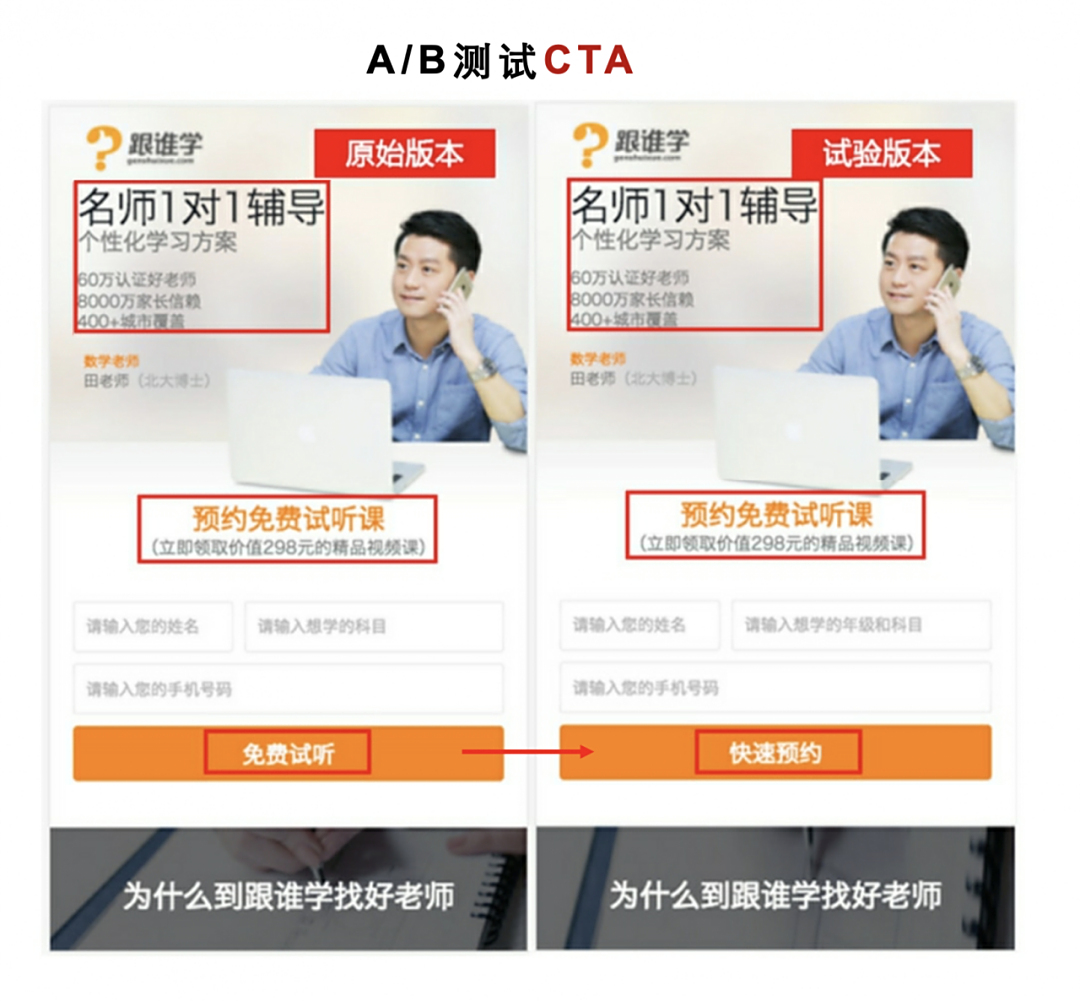
第三次测试最有趣,修改了按钮上的引导语。在按钮的点击转化方面,原始版本“免费试听”比试验版本“快速预约”高 10%。但是,在后续的实际购买转化追踪数据显示,试验版本比原始版本高出 9%!
对于这个试验结果,该品牌根据这个产品在市场上的发展阶段,进行了综合评估,最终还是决定最终的试验版本,尽管点击率差一些,但是转化收益最优。
可见,持续的测试、并根据实际业务情况做出优化,应该成为营销人的日常策略。因为总是有随市场变化的因素,今天表现好的元素也不一定明天还好,效果是动态的,测试也同样需要动态中进行。
更何况每次测试都可以得到一些新的积累,比如这个案例中,如果这个课程产品是刚起步阶段,需要更多地拉新用户,那么营销人员就应该选择原始版本——能获取更多潜在用户的资料。
2. 测试结果要综合看,维度不能单一
通常,我们会从一个固定的测量维度来评估测试结果。但是如果只考虑一个维度也意味着脱离了情景来看实验数据。比如,疫苗实验的结果中,就没有考虑到无症状感染者的情况,很可能导致结论有偏差。
数字结果是一方面,但是其背后的业务含义更加重要,不能忽略。比如,在不同的情景下,你可能需要对相同的A/B测试结果,做出不同的决策。
一个营销活动,在进行不同优惠策略的A/B测试时发现,A版比B版的用户总活跃度高出 5%,但是却同时降低了其中年轻用户的活跃度占比,那么应该推广哪个版本好呢?
情景一,这是一个中老年购买力占主导的营销活动,显然更倾向于总活跃度的提升,至于年轻人,反正也没有实际购买欲望,可以在这次活动中忽略掉。
情景二,这是一个青年人购买力占主导的营销活动,总活跃度提升,但年轻人活跃度度下降,很可能影响实际的成单率,A、B版本的选择,必须重新进行评估。
此外,维度不能单一,还包括避免习惯性地将测试结果当作一个绝对整体来看待。一般而言,从某个固定的测量维度来评估测试的结果是没错的,这样做通常可以避免在多个维度中挑选最符合“需要”的数据,而故意忽视不符合假设的结果。
但同样,仅考虑一个维度也意味着脱离了情景来看试验数据——不同的情景,很可能意味着对A/B测试结果截然不同的解释。
【例子】:
几年前 Airbnb 对搜索页进行了改版设计。搜索页是 Airbnb 业务流程中非常重要的一个页面,决定后续的转化情况。
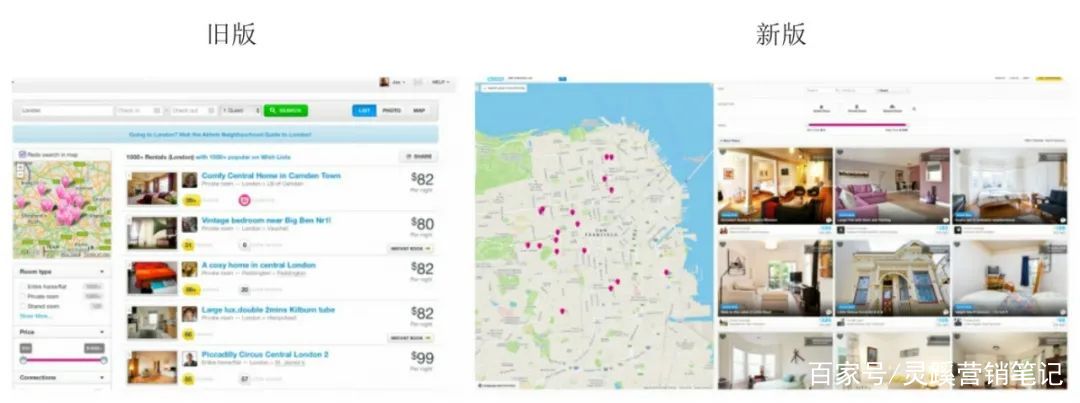
搜索页改版前后的变化如图,新版更强调房源的图片(Airbnb为房主提供专业的摄影服务)及标记了房源所在位置的地图。为了这次改版,团队投入了很多资源,设计人员和产品人员都预测新版肯定会表现更好,定性研究也表明新版本更好。
但针对搜索页的A/B测试结果却显示,新版转化率并没有更好。这个结果让人大跌眼镜,因此分析团队将数据细分到不同的情景中,来查找结果背后的真正原因。
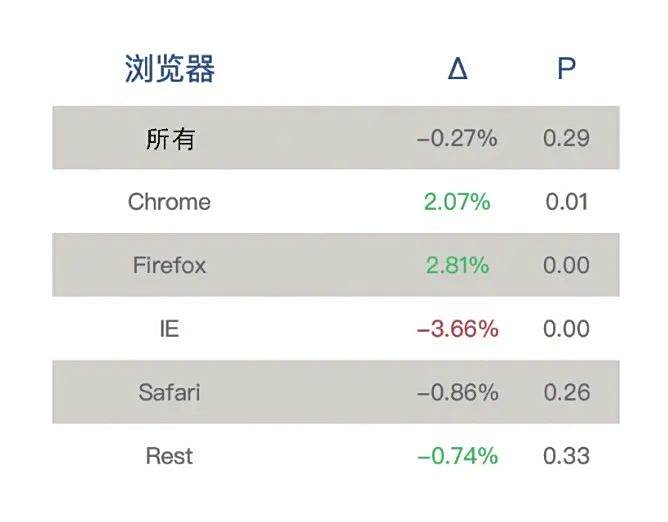
经过分析后发现,问题出在 IE 浏览器上。如上图,除了来自 IE 的访问以外,新版在其他主流浏览器上的表现都是优于原版的。这个纵向的深入分析,帮助团队找到真正的问题:搜索页的改版很有效果,但是代码实现存在严重问题。在修复相关的问题后,源自IE的数据也有了超出 2% 的增长。
这个案例是A/B测试中一个被人津津乐道的案例,可以看出,从多个维度对测试结果进行解释,是很有需要的。营销人员都应该尝试将数据分解到不同的维度,然后去理解不同维度下测试的实际效果。
最后,需要强调一点,A/B测试虽好,但是如果使用不当、或解释不当,都可以成为增加营销阻力的因素。这就需要营销人避免在分析结果时出现自欺欺人的倾向。
我们都理解,测试过程很费时费力,有的改版结果,测试后发现很打脸。这种情况下,很多营销人为了找到有利的结果,会刻意去分解数据,然后在多个维度中挑选“最符合需要的”数据,或者和上文中的两个“刷屏”的抗疫实验一样,为了证明某个假设而只突出部分数据或片面解读。
例如,尽管我们都知道A/B测试的最终还是要落脚于优化整体营销ROI,而不是为了单纯优化某个指标。但是,当某个指标表现及其抢眼的时候,可能会导致优化者的短视。比如,过分注重某一层的转化率,从而在设计引导上急功近利或花样百出,甚至强迫用户去做出点击,而不管后续转化的质量。
还是那句,A/B测试从来不会说谎,说谎的是它们被解读的方式。想获得消费者洞见和营销优化策略,就要遵循科学的方式、做好充分的解读,数字太漂亮或太反常,都要保持十二分的警惕。
#专栏作家#
Agnes;微信公众号:灵蹊营销笔记,人人都是产品经理专栏作家。关注智能营销领域,擅长发现最新的营销技术及工具,并发掘行业前沿案例。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


