
 起点课堂会员权益
起点课堂会员权益网络购物“关联销售”三大招

在网络购物中,关联销售是网络购物提升销售的一个重要的方式。相比于传统的线下零售商,网络销售的“关联销售”方式更多,也更加强大。通常来说,主要有“诱惑”、“引导”、“理解”三种招数。下面就看看卢凯如何解析和试用这三大招数吧。
2012 年出现了这么一个互联网专用词:“剁手族”,意指“网购花钱太多,立誓再网购就剁手的人”。先不提剁手是不是真的能够控制住网购习惯,只看网购可 以让消费者上瘾,正说明网购充分满足了消费者的需求,消费者对于网购的黏性也非常高。网购让消费者欲罢不能,除了价格公道、购买方便、选择众多以外,我觉 得网络平台上“关联销售”的天然优势,也是一个重要原因。
关 联销售,简单说就是引导客户在购买商品时,一次性地购买多种。我自己前天在某网站购物时,本来只想购买一条长裤,最后的订单中却包括了一条长裤、一双袜 子和一条内裤。这就是商家利用“关联销售”的方法,引导客户购物的结果。相对于传统零售渠道,网络销售平台在“关联销售”这一领域,可以玩的手段要多得 多,也强大得多,这里主要讲3种常用招数,归纳为“诱惑”、“引导”、“理解”。
招数1:诱惑——捆绑优惠
捆绑优惠是指,当消费者按照一定的规则,购买两件及以上商品时才能享受到的优惠政策。
如上图所示为易迅的“随心配”模块,相机详情页中,显示一系列的捆绑优惠,只有在同时购买相机与其套装中设定的另外一件商品时,才能享受到价格折扣。类似的捆绑优惠在京东、天猫等处也可以见到。
捆绑优惠在线下渠道的使用也很常见,在超市中经常可以看到用黄色胶带捆绑在一起打折销售的商品组合。但是在网络平台上,捆绑优惠能够做得更好:
更直观:以上面易迅网的“随心配”为例,在一个不大的页面上,两件商品、折扣力度、最终价格都很明晰地展示了出来。而在线下渠道中,很难有这样普遍性而直观的方式,让客户了解到促销的具体内容。
更灵活:仍以“随心配”为例,可以看到对同一件商品,可以创建多种优惠套餐,消费者可以根据需要选择购买。这样的灵活度是线下很难达到的。
更快速:在网络平台中,可以很快速地创建出多个捆绑优惠套餐,消费者马上就能看到。例如:某厂家规定同时购买其生产的手机与蓝牙耳机就能够享受折扣。在网络平台上可以在半小时之内完成这一优惠的创建,而在线下,抛开系统设置不说,人员的培训、促销展示的制作也往往会耗时数天。
捆绑优惠这一招数,吸引消费者的是“优惠”,而将商品捆绑一起强行推销了出去。这一招可以归纳为:诱惑。
招数2:引导——相关搭配
搭配针对商品的自然属性,理解商品之间的相互关系,依据这一相互关系,引导消费者购买更多的商品。
由 于搭配是基于商品之间的自然关系,消费者买单的几率会高很多。以京东商城的“推荐配件”模块为例,对于手机类产品,在这一模块中可以看到京东商城推荐的 贴膜、保护套、电池、蓝牙耳机、充电器、数据线、移动电源、车载配件、耳机等其他种类商品。所推荐的其他商品,从商品类型上看,是与手机能够互相配合使用 的。
相对于线下渠道,网络平台上搭配功能的主要优势在于:
更广泛:以上面京东商城的“推荐配件”模块为例,对一款手机,在这个模块中搭配出了10件其他的商品(如有必要还可以搭配更多),而这一模块可以应用于几乎所有商品上。而在线下渠道中,限于物理展示空间,不可能做到如此的广泛。
搭配这一招数,吸引消费者的是商品之间的自然关系,让消费者觉得搭配的商品也能用得着。这一招可以归纳为:引导。
引导和搭配这两招可以综合使用,效果更好。例如前面举例的易迅“随心配”模块,既有低价的诱惑,又有商品配件关系的引导,消费者自然更加满意。
引导和搭配这两招是网络平台从线下渠道继承并强化的。与线下所施展的招数相比,虽然威力更大,但其本质相同。而这第三招“推荐”则是线上平台所独有,线下渠道是学也学不来的。
招数3:理解——智能推荐
智能推荐是当前被炒得很热门的“大数据”的最常见应用形式之一,它对消费者在网络上的活动数据(包括浏览、购买、评价等)进行分析整理,判断消费者的行为特征,从而“智能”地为消费者推荐商品。
Amazon的智能推荐系统是为大家所熟知的,其首页上没有膏药般的促销信息,而是会根据每一位访问者的浏览记录、购买记录等为每一位消费者“个性化”生成推荐信息。而在商品详情页(itemdetailpage)中,也会根据商品的被购买记录计算出与其相关的商品。
On-lineFM站点也会使用智能推荐算法,向其听众推荐歌曲。例如豆瓣电台,用户对每一首歌都可以标记“喜欢”、“跳过”,而豆瓣电台在播放下一首歌时,会基于听众之前对每一首歌的操作,推荐听众最可能喜欢的歌曲。
智能推荐系统的算法是当前“大数据”方向的研究热点,粗略分其大类,有两种:
第一类:基于内容的推荐
这类算法是基于所分析数据的一系列不相关的特征数据或者类似性质,寻找较高属性相似度的数据。在计算时,需要对原始数据通过特征提取的方法获得对象内容特征数据,系统基于用户所操作对象的特征提取用户的兴趣。
最 著名的基于内容的推荐系统由PandoraRadio所使用。PandoraRadio的工作人员会为每一首歌从各个方面打上标签(作曲、演唱、年代、 曲风等,据称有上百个标签),并且用户的反馈也会对这些标签的权重有所影响。而PandoraRadio则会依据这些标签来为用户推荐歌曲。
目前,这种基于内容的推荐系统使用范围并不广,这一系统的主要障碍在于特征提取。以PandoraRadio为例,他们需要成立一个专门的团队,负责听每一首歌,并打上标签。这样的人力成本投入过高,且扩展性不够。
第二类:协同过滤
协 同过滤推荐是当前使用较多的技术,其基本思想非常易于理解,我觉得可以总结为“物以类聚,人以群分”,简单来说就是类似的人喜欢类似的商品,而喜欢相似 商品的人,往往也有着一些共同点。互联网上用户的一举一动,都可能被背后的计算机系统记录下来,用作协同过滤分析的数据。
以一个比较简单的例子来说明协同过滤的原理。下表为4个人对于6部电视剧的评价结果。可以看到,没有任何两个人的打分结果是一样的,也没有一部电视剧的得分结果是相同的。
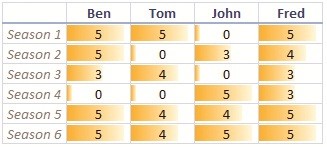
但是,如果把某一位用户的评分当作一个多维向量的话,我们就可以得到4个向量,并看作用户的特征。
Ben=[5,5,3,0,5,5]
Tom=[5,0,4,0,4,4]
John=[0,3,0,5,4,5]
Fred=[5,4,3,3,5,5]
在六维空间里,这4个向量的夹角即代表了用户的相似度,夹角越小,相似度越高。在例子来源处详细介绍了利用矩阵的奇异值分解法计算向量相似度的方法,得到的结果如右上图所示,可见Ben与Fred对电视剧的口味最为相似。
协同评价推荐系统的最大优点在于,计算机不需要真正地“理解”其所推荐的内容,而且是依赖于大量人群的交互数据。在这个信息爆炸、计算机能力充足的时代,协同评价系统得到了非常广泛的应用。但协同评价同样有着一定的局限性:
依赖于大量的数据,当数据量较少(新品)时,推荐精度不够;
当前的推荐系统需要处理数以百万计的客户及商品,其计算量非常庞大,对于计算能力及算法的要求非常高;
相对于数以百万计的商品,大部分消费者的交互数据只会涉及其中不到1%的商品,也就意味着交互数据矩阵极为稀疏(99%以上为空),算法设计困难。
不管是哪种推荐系统,依靠的都是丰富的消费者应用数据,并据此作出满足消费者潜在隐性需求的推荐。可以说,相对于其他的关联销售方式,推荐系统能够从某种程度上“理解”消费者的需求,因而也会受到越来越多的重视。
原文来自:互联网分析沙龙






- 目前还没评论,等你发挥!








