
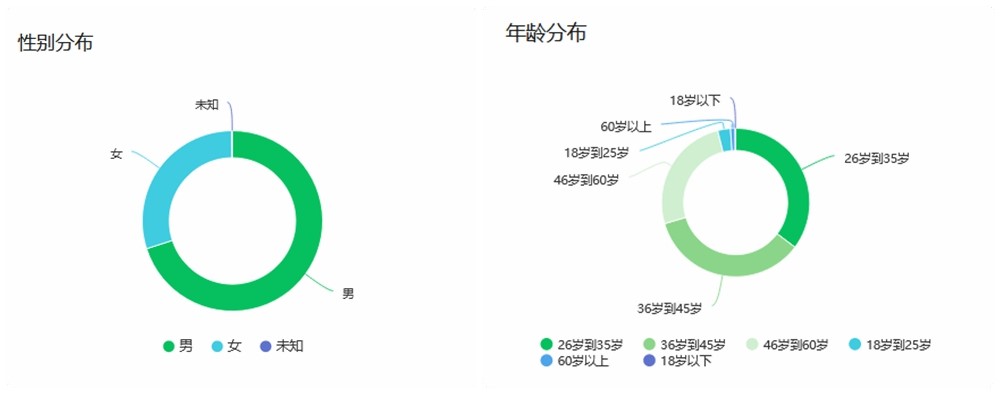
 起点课堂会员权益
起点课堂会员权益大数据,算不准老天爷
#本文为人人都是产品经理《原创激励计划》出品。
进入夏季后,天气开始变得“喜怒无常”,一会狂风暴雨一会晴空万里。出门前看看手里的天气软件,发现同样的手机型号,同样的天气软件,同样的时间地点,居然有不同的天气预测结果。这是为什么呢?本文作者对此进行了分析,一起来看看吧。

一、同样的屋檐,不同的天气
夏天到了,阴雨多发。
上班前闲着没事,一群无聊的人看着窗外天色,用几点下雨打赌,来决定午饭由谁买单。
一边下注,一边已经有人拿起手机,开始查攻略。
其实,这也算不上作弊。谁都知道,天气预报软件,报不准天气,有时候甚至还没猜的准。
而且,同事们拿着不同的手机,用着不一样的天气预报软件。念出的天气预测结果,果然也天差地别。
但当同事小艾,念出她手机的预测结果时,有些出乎我的意料——小艾和我用着同一款手机,天气软件都是系统自带的天气软件,但天气预报居然和我手机上显示的不同。
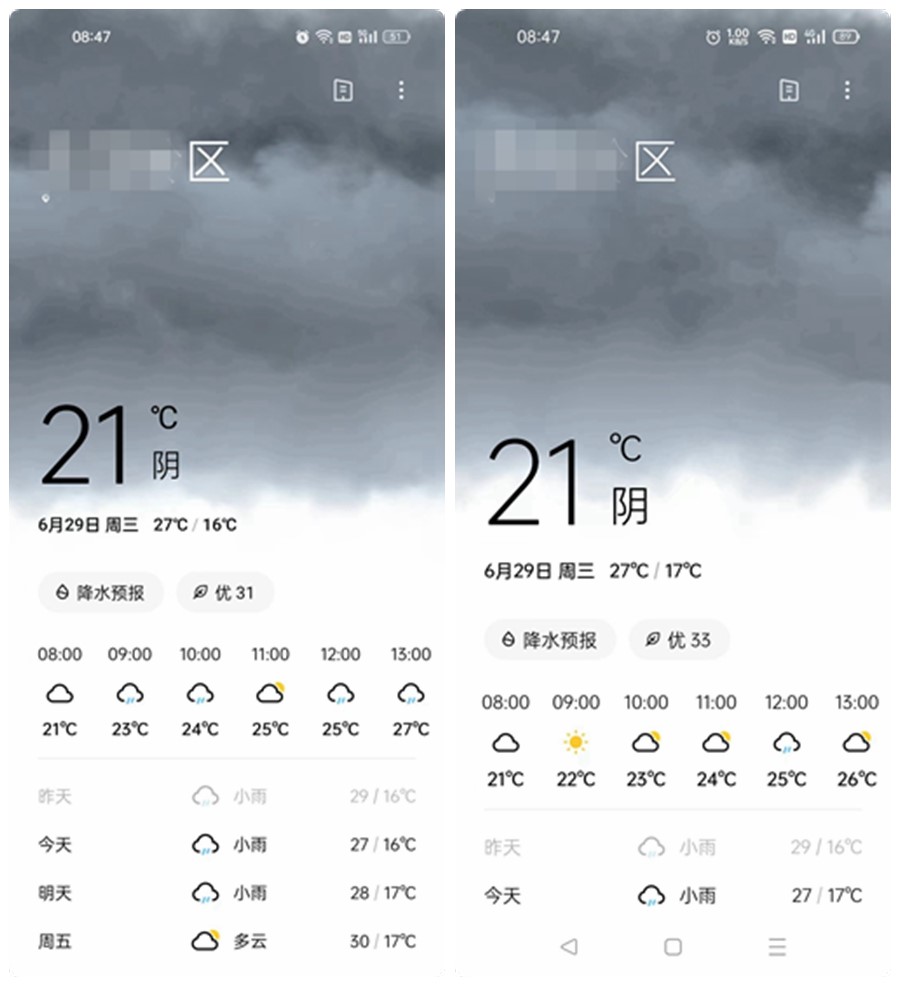
我拿来她的手机,再次确认:我们身处同一个位置,都开着系统定位,且都赋予了天气软件读取定位的权限,我们也在同一个WIFI环境下。
我们使用着同样的手机、同一个款天气软件,也更新到了同一版本。
我们为了避免时间误差,都多次刷新了天气预报页面。
但天气预报结果,依然是不同的。
这两份天气预报中,至少有一份是错的。又或者两份都是错的。
难道天气预报的数据推送,也会根据不同人的喜爱,给出不同的结果?
二、同样的行迹,不同的位置
最近几年,很多同事选择了自行车上下班。
因为健康,因为环保……也有可能是因为穷。
公司附近有几处重要的办事机构,管理较为严格,共享单车不能随地停放,必须放在指定的区域。
而在具体的操作中,必须现在手机上操作,确认已抵达规定还车地点,才能进行关锁。
然后,那些钟爱睡懒觉的同事,就体会到了什么叫噩梦。
离上班时间还有2分钟,骑自行车来到公司楼下,驻足在停车区域内,点击手机上的“我要还车”,然后看到提示:您不在还车区域。
之后,自然是一番折腾,向前动动,向后挪挪,但无论如何进出,手机页面上总显示者:距离指定还车区域3米。
更过分的是,旁边一样过来停车的人,纷纷抵达位置,其中有不少直接关锁走人,没有在定位环节遇到麻烦。
看着上班时间已过,成年人的崩溃,往往就在那么一瞬间:咱的定位数据,为什么永远都差3米?
不过,他也很快释然了:既然停不了车,干脆骑车出去吃个早饭吧。迟到要扣钱,违规停车也要扣钱,反正总要扣一个。
三、同样的搜索,不同的结果
还是闲来无事的办公室生活。
到了下午5点,人们都忙完了手头的任务,开始刷着手机,静待下班。
小艾新买了个头饰,杨妹子看着不错,问她要链接。
微信转发淘宝链接比较麻烦,小艾是个懒人,就跟杨妹子说:你就搜索#$%%@@%,第一个就是。
杨妹子听话照做,在淘宝搜索栏里输入了#$%%@@%,但别说第一个,连着刷了十页,也没有看到小艾买到的那件头饰。
其实,不同人在淘宝搜索同一个词,会出现不同的结果,也不算是什么新鲜事情。
系统会根据每个人的搜索、购买习惯,给他们推荐,系统认为他们最有可能感兴趣、最有可能购买的商品。
不过这些推荐,显然还没有完全猜透用户心意。
搜索结果,都是杨妹子不感兴趣的。
而她现在、立刻、马上就想要购买的商品,系统却没有推送给她。
大数据的判断,是不是很不准确?
四、数据缺陷,显而易见
大数据有问题吗?
它距离完美还差的很远。
而在生活中这些琐碎的事情上,我们也能看到,大数据一些显而易见的缺陷。
1. 因为边缘数据,忽略了主要问题
现如今的大数据,基于庞大的数据量进行推算。
不过,数据与数据间,也具有权重差异:一些数据对计算结果有重要影响,一些数据却只作为参考。
但当边缘数据足够多的时候,也会对结果带来质的影响。让一些本应该起到决定性作用的数据,被边缘化。
就如刚才天气预报结果的区别,可能也是数据推算带来的差异。
不只以气象局的预测为依据,也结合了每个人的行动轨迹、遇雨频率等个体差异,进行单独分析。
但分析结果怎么样?
同一时间,同一地点,却给出了截然不同的天气预报。
难道是否下雨,会根据每个人的行动轨迹而变化吗?
我们没有生活在楚门的世界,我们也不叫萧敬腾。
处在同一屋檐下,应该面对同样的天气,这个常识,却在计算中,被大量的数据挤到了一边。
而在网络世界中,事实被大量数据击垮,其实极为常见:
点赞多的视频,未必真的有趣。
如果能找来足够多的人刷点击、刷关注、刷赞、刷评论,一些低质量的视频,也可以成为热门,推送给很多人。
评分低的饭店,未必就很难吃。
只要找足够多的人去恶意差评,可以轻松把一家饭店的评分搞下去。而很多饭店在开业之初,也会找大量的人刷好评,让自己屹立在推荐头部。
当非真实的评价足够多时,真实就会被掩盖。至于饭菜味道究竟怎么样,数据又尝不出来。
2. 用复杂的方式,做了简单的问题
因为大数据的存在,让很多原本非常简单的问题,变得很复杂。
一些显而易见的答案,却被藏了起来。
当你搜索1+1时,首屏上80%的搜索结果,不是1+1=2,而是哥德巴赫猜想、电影、歌曲之类与1+1相关的东西,甚至关于1+1=1的推论。

明明是个很简单的问题,却因为大量相关资料的存在,而被演化的非常复杂。
就像小艾给杨妹子推荐的商品,她俩长期使用着同样的WIFI地址,也在不止一个软件上相互关注、加着好友。其中一人前几天购买了某商品,另一人几天后用同样的搜索词,搜索同一商品,想必也是数据能够监测到的。
如果只考虑这些显而易见的信息,推荐同样的商品,立刻就能促成购买。
但大数据偏偏考虑了太多过去的搜索、购买结果,认为她俩不是同样的消费群体,认为她俩具备不一样的喜好,所以推送的搜索结果也完全不同。
很简单的一道题,做的太过复杂。
3. 数据偏见,偏见螺旋
大数据的推送,更存在严重的偏见。
数据认识用户,很多时候就像盲人摸象一样。
只摸到了大象的腿,就认为大象是个圆柱体。
数据只看到了用户的某一面,认为用户就是那个样子的。
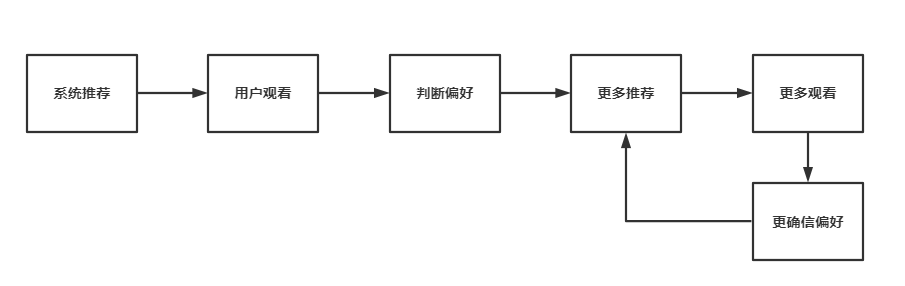
最初,数据通过盲猜的方式,向杨妹子推荐了某些商品、某些视频,她随意观看了其中的几个。
数据会对她的观看行为进行记录,并再次推送类似的商品、视频,进行验证。
果然,杨妹子确实对这些内容感兴趣,多次观看。
时间长了,数据就会记住:杨妹子是个喜欢火锅、喜欢年轻小鲜肉、喜欢朋克风穿搭的年轻女孩。并且会给她推送更多相关内容。
这样的推送虽然没错,却只是一种偏见。
其实,杨妹子也喜欢中国风绘画,喜欢绿色的头饰,喜欢吃东北菜,但数据却并不知道。
数据并非全知全能,对于自己没有收集到的信息,也无从得知。
尤其在针对性的推送中,更会形成一种偏见螺旋。
系统不断给杨妹子推送火锅、朋克、小鲜肉,杨妹子也确实喜欢看这些,持续观看、点赞、评论、购买。
数据记录在案,就更会不断加大相关推荐。
最终形成一个循环:
但对一个人来说,再喜欢的东西,看的太久了,偶尔也会有腻的时候。可系统仍然乐此不疲的推送这几种内容。
因为足够的数据证实,她感兴趣。即使偶然一两次没有观看,在整体数据中,这一两次不观看的行为,也依然无法抵抗之前频繁观看的偏好。
除非她真的歇斯底里,一连点了几十次“不要再推荐类似内容”。但一般人也不会如此做,毕竟推荐的东西,也都是自己平日里感兴趣的,还担心以后会看不到。
而在这种偏见循环中,已经确定偏好的内容推送越多,其他内容能跟用户见面的机会就越少。所以数据补全自己偏见的机会也就变得更少。
在向杨妹子推送火锅、朋克、小鲜肉的同时,偶然有一条热门视频也推送到了她眼前,是关于中国风彩绘的。
但这条视频的主角,说话娘娘腔,恰好是杨妹子无法接受的类型,直接划了过去。数据就恰好失去了一次,得知她喜好中国风彩绘的机会。
下次再有这样的机会,不知道又是几月后、几年后了。
五、大数据,还不够大
所有这些问题,归根结底,是大数据还不够大。
受限于技术、成本、隐私原因,获取数据的方式还不够多,不够精确。
如果数据捕获量够大,不只限于一个平台,甚至不只限于虚拟世界,能够看到更多细节。数据就有更高的机会,真正认识一个用户,而不是产生偏见螺旋。
如果数据获取手段足够细致,所有数据获取设备都足够精确,也就不会出现无法还车的问题。
如果大数据的探测手段足够高级,那不可预知的天气,也总有一天能够判断到一丝不差。
但受限于技术,大数据暂时还无法一眼看到事物的全貌。只能通过管中窥豹的方式,用几亿个角度观测出的视野碎片,拼凑出一只豹子的画像。
受限于成本,大数据无法获得充足的数据。或许几亿个视野碎片能拼出一只豹子的画像,但成本只允许获取几万个碎片,拼出的豹子自然也似是而非。
受限于隐私,大数据无法获得一些关键性数据。那几万个碎片中,还缺乏豹子某些关键部位的碎片。
最终结果就是,大数据所拼凑出来的豹子画像,虽然有了豹子的雏形,但离真实的豹子还差很远。
六、矛盾的隐私
技术、成本的局限,随着时代发展,总有解决的一天。
就像天圆地方的传统观念,终有一天会在天文卫星的见证下被颠覆。
但大数据未来的发展之路,必然还会和我们的隐私需求,出现更激烈的碰撞。
尤其是我们的真实需求,甚至连自己都很难说清——多数人对大数据的态度,欲拒还迎。
在需要大数据预测的时候,我们要求大数据保持精准。
在不需要大数据预测的时候,我们又担心对隐私泄露。
- 打车去某个偏僻的角落,甚至我们自己都不知道该怎么搜索目标位置,大数据就直接预判出了我们的目标地点。这节约了我们的时间,也让我们的出行变得简单、轻松。但在坐上车之后,我们又开始担忧,自己的出行信息,是不是会被有心人利用?
- 我们想购买的商品,被电商平台直接推送到眼前,节省了我们搜索、浏览、对比的时间和精力。但在享受这种便捷的同时,有的人又产生担忧,自己对某些商品的喜好,会不会被别人所知晓。
我们都很矛盾,既想占有大数据的好,又想摒弃它的一切不好。
但大数据的好与坏,本就是对立统一的。
没有足够多的数据埋点,就无法做出更准确的预测。
没有一次次的行为监控,就无法在你需要的时候,把你所需的信息送至面前。
更简单点说:手机中的导航软件,若没有精确的定位,没人知道你在哪、你去哪,又怎么给你准确的导航?
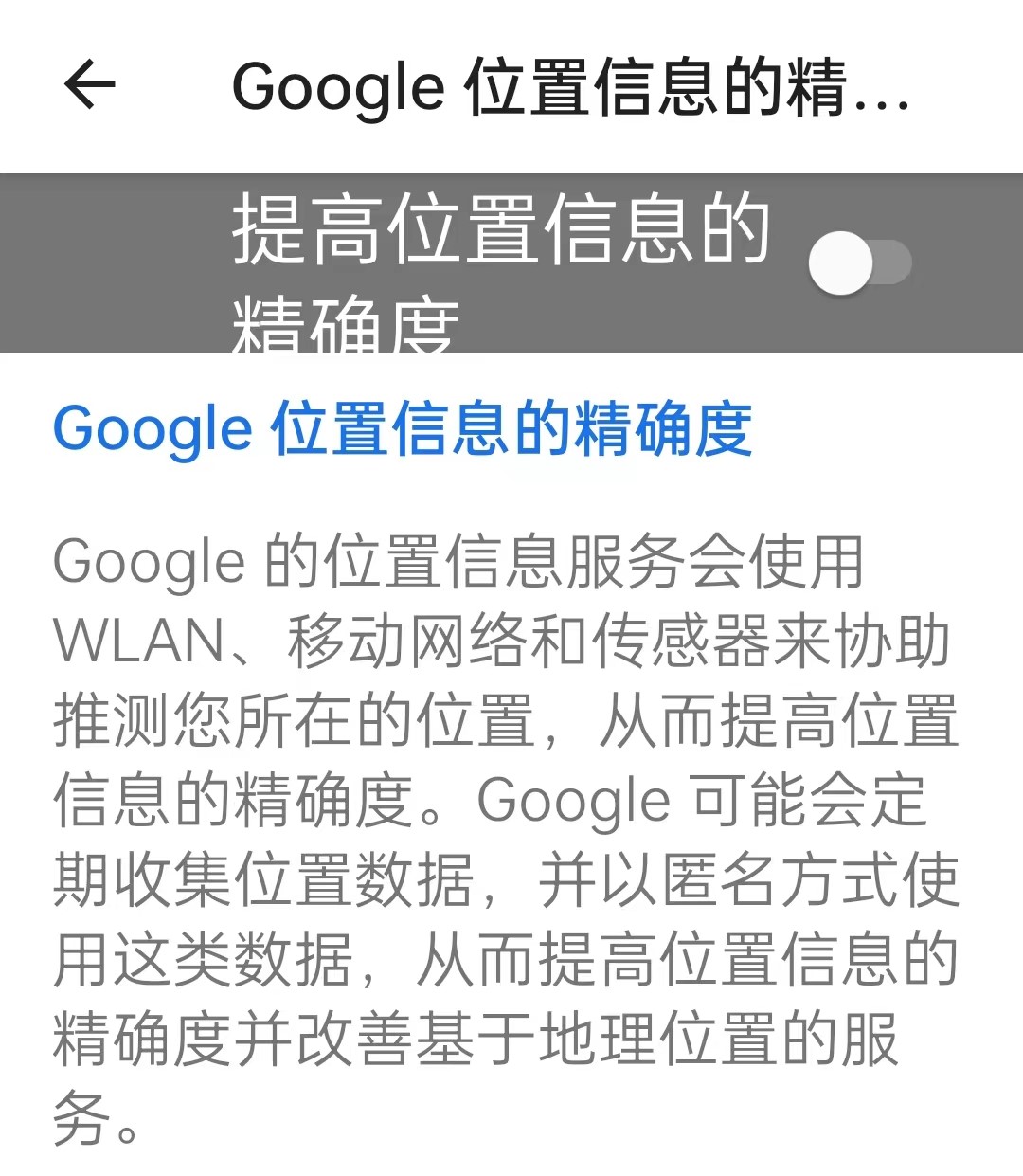
就像一些人所说:“其实我们不是没有选择权,即使是现代,也完全可以扔掉手机,一个人去山里生活,保护自己完整的隐私。”
这话虽然有些风凉话的意味,但也能反映出一个问题:当我们,把非智能手机换成智能手机时,当我们享受远程购物的便捷时,当我们随时随地通过搜索解答自己的疑惑时,我们也应该知道,自己将要拿出一部分隐私,去交换这种便捷。
隐私交换便捷,这是必然的结果。
而在大数据发展、完善的过程中,我们需要去争取的、社会需要去规范的,是付出多少隐私,能换到多少便捷;大众对隐私的付出,有没有自主选择的空间;付出隐私的边界在哪里;隐私除了交换便捷外,还会不会被其他人看到、利用。
现在还没有答案,但迟早会有答案。
总有一天,大数据能算准天气。
也总有一天,我们能找到便捷和隐私间的平衡。
#专栏作家#
墨饕,人人都是产品经理专栏作家,网络营销人,心理咨询师。擅长消费者行为学、文字传播学、市场营销学等领域。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
本文为人人都是产品经理《原创激励计划》出品。
题图来自Unsplash,基于 CC0 协议









数据推荐还不够精准智能啊,刚买好一件东西,短时间内也不需要买第二件但就是天天推送,就不能推一个月或半年前我买过的某些必需品吗?那种有更换期限的产品隔段时间推送不好吗?又不是没有给数据
很多时候我们不是担心隐私被数据知道,而是在担心数据是不是在我们不知道的时候擅自获取隐私信息,并且这些信息被其他人所利用
指定换车那个有相同的经历,明明是同样的共享单车,别人能换我换不了。
真是很好玩,看来现在真的啥都是因人而异的,大数据根据你的喜好进行推送,好像天气也能根据喜好变化一样
千人千面
现在评分也有很多是假的,就现在都是各种刷高分什么的,还挺容易受骗的