
 起点课堂会员权益
起点课堂会员权益风险三方数据管理的HeadFirst
三方数据希望能够解决自己的部分工作事务,以留出更多的时间来处理其他事务。那么关于三方数据该如何进行管理呢?需要注意一些什么问题?本文梳理了相关工作流程,分享了三方数据扫盲贴,希望对你有所帮助。

日常工作过于繁琐,以至于感觉自己又从产品转型成商务了。所以就三方数据管理希望交出部分工作以解放其余工作的时间。常规风控系统、应用的讨论,至少在人人都是产品经理上,已经涉及了决策引擎、大数据平台等,但如果就三方数据的日常管理作为一项单独工作的讨论较少。
在《征信业务管理办法》实施近一年,“过渡期”越来越短的当前,三方数据管理应当可以单独设置一个篇幅来讨论日常的工作流程。此文既作为对接手三方数据部分工作的同事的扫盲贴,也作为自己这项工作的总结,以供同行讨论批评。
一、《征信业务管理办法》相关
2022年后的三方数据管理,是绕不开此办法的出台及执行的。此管理办法共计八章53条,共计4800字左右,预计十五分钟左右可以阅读完。其也是基于原征信业管理办法、之前试点八家征信机构的实际,所出台的。网上有诸多解读,不再赘述,挑选几个我个人觉得比较重要的点摘录解读。
第三条 本办法所称征信业务,是指对企业和个人的信用信息进行采集、整理、保存、加工,并向信息使用者提供的活动。
本办法所称信用信息,是指依法采集,为金融等活动提供服务,用于识别判断企业和个人信用状况的基本信息、借贷信息、其他相关信息,以及基于前述信息形成的分析评价信息。
相较于八家征信机构试点期间的情况,当时对于“个人信息”,及“个人征信信息”,是缺乏一个明确的界定的,大都特指一些多头借贷数据,以及在各种不同的机构中借款的借贷信息等。至于如行程轨迹信息,支付信息等,我个人理解在之前是从未明确说明是否为“信用信息”的。根据本办法的解读,个人理解“只要用于金融活动”,即可称为“信用信息”。即“信用信息”的内涵被扩大。
第五条 金融机构不得与未取得合法征信业务资质的市场机构开展商业合作获取征信服务。本办法所称金融机构,是指国务院金融管理部门监督管理的从事金融业务的机构。地方金融监管部门负责监督管理的地方金融组织适用本办法关于金融机构的规定。
第五十条 以“信用信息服务”“信用服务”“信用评分”“信用评级”“信用修复”等名义对外实质提供征信服务的,适用本办法。
此条基本上堵死了所有原三方数据公司的路,使其不得不转型。所有持牌金融机构不得与百行、朴道之外的机构合作。不论之前的名义与形式如何,此两条与上述第三条结合,基本上框死了三方数据机构、征信机构及应用方的位置。
第十二条 征信机构采集个人信用信息应当经信息主体本人同意,并且明确告知信息主体采集信用信息的目的。依照法律法规公开的信息除外。
第二十三条 信息使用者应当采取必要的措施,保障查询个人信用信息时取得信息主体的同意,并且按照约定用途使用个人信用信息。
此两条规定了采集方和使用方双方的一个要求。即采集方需要获得授权,同时使用方也得获得授权。基于以上三个部分,金融机构使用任何信息应用于金融业务,都需要通过百行、朴道进行,即所谓的数据”断直连”。
二、三方数据扫盲
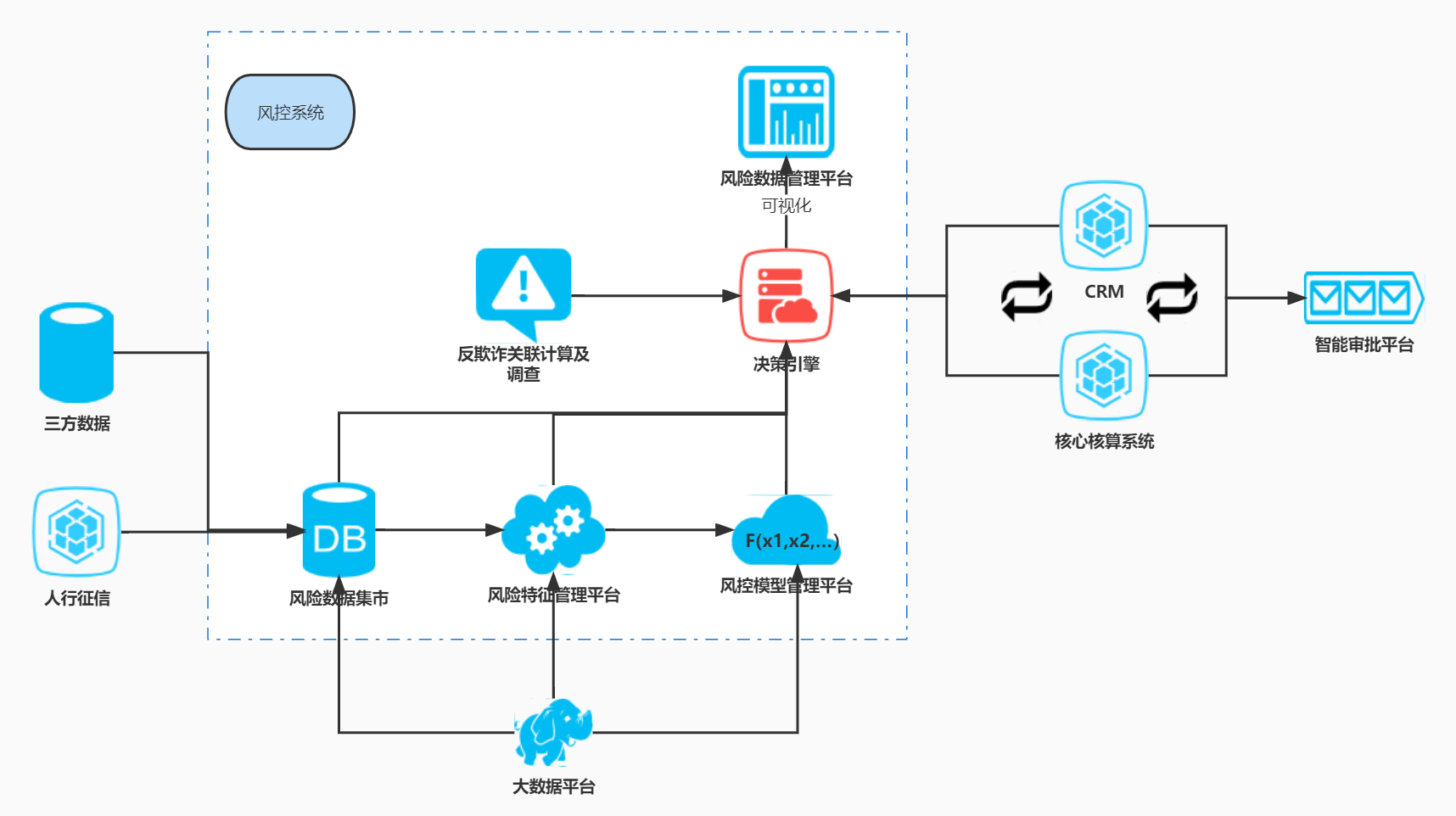
1. 三方数据是平常买的菜
常规的量化风控决策,上游大体是核心系统、CRM系统,推送的客户信息由路由分解给人工审批或量化引擎(也存在量化引擎判断’存疑’的客户再推送给人工审批的可能)。决策引擎收到客户信息后,结合数据集市、标签管理平台(衍生变量计算平台)、风控模型管理平台,对客户的是否为黑名单进行判断,对客户的综合评分判断是否准入。
三方数据参与数据集市及标签管理平台,乃至作为一个入参参与模型的管理和变更。如果其他系统平台是锅碗瓢盆的话,三方数据更类似于每天要去菜市场采买的菜。
一个常规的策略做饭过程为:客户->基础核验->涉法核验->反欺诈评估->多头借贷情况评估->评分定价评估->自有模型评估。每个环节都需要不同数据产品参与。
2. 市场上都有什么菜
就三方数据,在浅薄的认知中没有一个权威的指导标准。结合近两年的工作,大体整理如下。在此没有包含人行征信数据,人行征信数据是一个不断完善的整体画像,不能单纯的归为哪类。需要单独说明的,是“其他”类的数据,关于反洗钱的名单、贷后管理的情况及学生身份确认,不甚清楚是只有持牌机构会被监管机构关注到,还是全行业均有同样的需求和问题。
不论各家公司产品描述的如何花里胡哨,但是分类上是一定能划分进如下的分类的。诚然,不同的公司在技术实力、数据源获取能力上,有一定的差异,但是在穿透过去的原始数据源中,一定仍然是那些信息。
因此在之前的三方数据引入中,曾经想过全数据类型制霸。但介于种种原因,最后并未完成。定性认知上觉得可能效果不错的三方支付通道的支付数据,也因为种种原因没有完全覆盖。
曾经设想过,因为金融交易总归会体现在账户余额变动上,如果可以合理合法地获取用户基于银联、网联、三方支付(支付宝、微信、平安付)的全部评分,很可能能做出来一个干净的客户画像,但因为难度太大而作罢。希望百行、朴道入场后,有一天可以基于这个想法来谈谈经验。
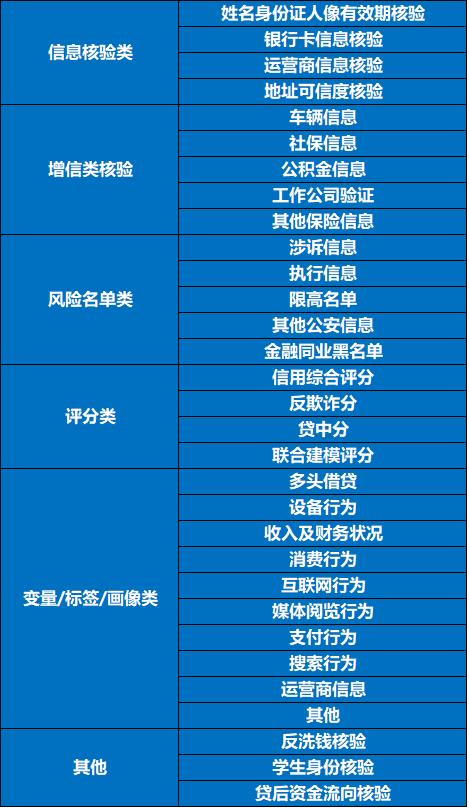
核验类的数据均来源于权威数据源,这个“权威”是指,公安一所三所、银联、及三大运营商。市面上所提供此类验证服务的,原始数据源也只可能是这几家权威数据源。‘增信类’核验,社保相关评分、工作公司验证除金保信外,似乎没有其他可输出的权威数据源。车辆信息,历史有部分险司或者导航公司输出过。公积金信息据了解至今未完全地全国联网,各家数据源也是只能输出部分信息。
其他商业险、增信保险出险情况等,了解到也只有银保信在输出。
风险名单类整体分为两个部分,一是金融机构的黑名单,如各公司自行积累的,历史逾期超过一定时间的客户情况,另如历史在P2P频繁借款及逾期的客户情况;另外二是公检法类的黑名单,如客户被起诉、被执行、乃至涉及犯罪的信息。就实际感受来讲,这部分黑名单从定性上来说,确实可以理解其“风险性”。
但是没有条件,也不敢,也未曾见过其他机构去测试,稍微放宽一下要求后,整体的不良率表现如何。消费金融或小贷公司,本身就面对着下沉客户,用黑名单历史框死客户,是否会导致之后的客户做无可做。
评分是各家公司主要输出的产品。不论名称多么花里胡哨,按业务流程上只分为综合、反欺诈、贷中三类。至于贷后评分,因为讨论的主要是准入侧的问题,就没有纳入。当然各家公司也可以与输出方进行联合建模,单独列出来是想说明其特殊性。
各类评分就如同碳水雕花。评分有其显著的优点,如不需要过多去研究内在逻辑和关联性,测试起来简单明了,基本上跑一遍LR,大体会有一个初步的结果。但其显著的缺点也是这个,以前讨论LR/xgb+boost等方法的优缺点时,经常会说到,LR的变量具有清晰地解释性,但xgb方法,经常跑的结果莫名其妙。
但是评分这类产品,LR的解释性优势也当然无存。但是某种意义上来说,“如非必要,勿增实体”的原则,在评分类产品中我个人理解是做的不太好的。经常可以看见诸多公司提供长篇累牍汗牛充栋的评分产品。但测试起来相关性肉眼可见的高,对产品的增益也非常的接近。这就纯属浪费使用方时间了。
变量、标签、画像与评分实际上是没有刀琢斧砍的清晰的分界线的。与评分的差异,在于其字段名称中,就业务上可以提供一些信息,如某字段的名称叫做“客户近一个月xx行为的分级”,就可以多提供一些业务上的信息,比揉成一坨的评分要稍微强些。
画像提供的变量,基本上可以满足自行建模的需求了,当然实际使用中也就会开始存在“你不知道为什么这个变量有用,但他就是有用”的情况。
3. 怎么去买菜
在《办法》执行后,一开始我盼望着以后买菜,只需要找比如百行的郝芳晨、雷国军,以及朴道的陶乾几位厉害的老师。
但实际执行下来,基于三方数据从一开始就有的几个痛点,如①数据公司的数据源所提供的数据,与你的客户不可能完全重叠,即覆盖率一定会有问题 ②百行朴道所覆盖的数据源也是不断完善,而不是已经覆盖了全行业的所有数据 ③另,每个公司策略实施的实践是不一样的。假如同行业的策略组都想做个“四喜丸子”,在其他公司的策略都是红烧的做法的时候,你是拦不住本公司的策略组结合
实际想做醋溜四喜丸子的。因此,在买菜之前,还是有一些流程要进行。
(1)三方数据公司的选择
针对实际原始的数据源公司,首先是有些唯一的排他性规则。即如果公司没有客户对其的清晰授权,不接;公司与朴道百行没有完成合作,不接。在过渡期到明年6月都截止的情况下,现在还去新增接入一些合规上可能有瑕疵的公司,是可能存在问题的。当然,这部分的两条要求其实可以简化为一条,即实际接入还是得通过百行朴道,由监管授权的征信机构对数据合规性进行审查即可。
(2)菜的选择
接入什么数据,其实主要还是看目前策略模型执行过程中,缺少哪些数据。这些是因公司,而且因策略实施而变化的。一个数据公司敢做这部分业务,且活过三年,自有其可取之处。也不必踩高捧低。
(3)数据的测试
按我执行的实际,在接入三方数据之前,是需要进行初步的一些评估的,从流程整体最优的角度,这也是为了减少不必要的合同签署及流程对法务及综合同事的压力。这一部分也需要结合数据产品实际情况去做。在下面篇幅中再行展开。
(4)过会、采购、合同签署
执行的实际中,因牵涉费用等问题,三方数据的测试引入是需要经过会议审议和采购流程的。这些不同公司实际情况不同,按下不表。
(5)日常对账、开票、付款等
4. 科技与狠活
三方数据既然作为一种“菜”,自然也存在美化造假的可能,这里稍微展开说一下几个常规的科技与狠活。
结果造假:既然谈到数据测试,则数据测试就存在抽样的问题,但抽样的客户,一定是贷后行为已经表现了的。理论上我们需要测试回溯所以也就存在一种可能性,即利用贷后情况对三方数据的效果进行一些’调整’。
这样的调整,其实是会让使用方误解产品的实际效果的。就实际效果而言,KS15-18的产品,是最令人放心的,10-15的产品,感觉效果一般,10以下的产品,又根本没办法写测试报告。但是KS超过20的产品,就应该开始谨慎。至于KS40以上的产品,我个人理解只有理论可能。但与单纯的批评这样的行为来说。
实际上可以多想一步,既然此产品可以更快地发现客户的贷后行为,或者基于现有数据能将KS做的非常高。那么反过来想,这个公司的产品,可能可以考虑在贷中使用。
效果衰减:三方数据是存在衰减的可能性的。假如最上游的数据产生了变化,或者在与欺诈客户的攻防中,欺诈团体调整了自己的策略。或者单纯的自己的产品特质、客群发生了变化;再或者就是三方数据源,基于成本考虑,在使用过一段时间后,对产品的上游数据源进行了变更;都会导致效果的衰减。因此,三方数据也是需要定期的再次评估。
三、什么是好的三方数据
这部分纯属一些基础概念展示扫盲,在其他的文章及其他的网站上,都有大量的展示,建议已经了解的直接跳过。
1. 评估三方数据的流程
大部分经验贴中都在强调量化指标的评估,但三方数据评估的上下游也直接决定评估效果。
从流程上讲,大体有:结合业务情况抽取样本->提交测试流程->对产品进行初步评估->通过模型对所有数据产品进行综合评估
2. 抽样的注意事项
在抽样过程中,基于目前现有的,测试样本只能支持2万到3万的现状。建议还是有针对性的进行选择。选择具体的场景和业务,而不是雨露均沾的全随机抽样。至于黑样本量的占比,目前实际会设置占比10%左右。这部分如果有同业有更好的建议,也希望斧正。
3. 评估
在量化指标之前,日常评估和分析的过程中,首先要对返回结果的分布进行观察。
根据大数定律,如果抽样整体比较均匀,不考虑黑样本的情况下,则分数,也应当服从正态或者偏态分布。考虑到不良率是做的,则分数应当服从一定的双峰分布。如果分布上就比较诡异,这个产品可能效果也不佳。
另外,尽管量化的指标可以评估效果。但是理论上讲,如果是连续的分数评分的话,从高到低应该有足够的单调性,这也是在分箱的过程中就需要观察的。
如分布不佳,单调性也不佳,即使总的IV好看,也是不能使用的。
如何评估一个三方数据是否优秀,有哪些量化的指标?数学部分建议直接翻CSDN。
(1)覆盖率
三方公司提供的数据产品,与客群之间是存在一定的差异的。理论上讲,产品的覆盖率就不应该是100%。其他量化指标与覆盖率需要综合来看情况。如果覆盖率只有40%、50%,即使IVKS较高,但可能实际使用上也有问题。
(2)黑名单准确度
针对黑名单类产品。预测逾期的/实际逾期的+预测不逾期的/实际不逾期的。用来评估黑名单类产品好坏。
(3)KS
KS(Kolmogorov-Smirnov):KS用于模型风险区分能力进行评估, 指标衡量的是好坏样本累计分部之间的差值。
好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。人话:MAX(累计坏客户 – 累计好客户)。
(4)WOE/IV
WOE的全称是“WeightofEvidence”,即证据权重。WOE是对原始自变量的一种编码形式。分箱后做一些处理。
pyi是这个组中响应客户(风险模型中,对应的是违约客户,总之,指的是模型中预测变量取值为“是”或者说1的个体)占所有样本中所有响应客户的比例,pni是这个组中未响应客户占样本中所有未响应客户的比例,#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
人话:iv即在该分箱内,这个数据在多大的程度上解释“现象”。
(5)PSI
检验变量的稳定性,当一个变量的psi值大于0.0001时,变量不稳定。一个变量,将它的取值按照分位数来分组一下,每一组中测试模型的客户数占比减去训练模型中的客户数占比再乘以这两者相除的对数,就是这一组的稳定性系数psi,然后变量的psi系数就是把这个变量的所有组的psi相加总起来。
人话:这个产品在这个月的客户上厉害,但是下个月会不会出现差异的评估。
(6)贡献度等
在此就不做展开了
以评分产品举例,日常初步评估的代码实例:
— coding: utf-8 —
import numpy as np
import pandas as pd
data_test=pd.read_excel(“”)
data_test.shape
data_test.info()
data_test.head(10)
eda=data_test.describe()
path=”
bin=分箱数#no1.缺失及覆盖率
miss_rate=data_test.isnull().sum()
miss_rate=miss_rate.reset_index()
miss_rate=miss_rate.rename(columns={‘index’:’varname’,0:’miss_num’})
miss_rate[‘miss_rate’]=miss_rate[‘miss_num’]/样本量
miss_rate.to_excel(path)#no2.黑名单标签类的准确性
verify_true = data_test[((data_test[‘blackflag’]==1)&(data_test[”]==1)) | ((data_test[‘blackflag’]==0)&(data_test[”]==1))]
print(verify_true.shape)#no3.整体相关性
df_new=data_test.drop([‘cust_name’,’id_no’,’mobile’,’blackflag’],axis=1)
corr=df_new.corr()
corr.to_excel(“path”)#no4.IV
def cal_iv(data,cut_num,feature,target):
data_cut=pd.qcut(data[feature],cut_num,duplicates=’drop’)
cut_group_all=data[target].groupby(data_cut).count()
cut_y=data[target].groupby(data_cut).sum()
cut_n=cut_group_all-cut_y
df=pd.DataFrame()
df[‘sum’]=cut_group_all
df[‘bad_count’]=cut_y
df[‘good_count’]=cut_n
df[‘bad_rate’]=df[‘bad_count’]/df[‘bad_count’].sum()
df[‘good_rate’]=df[‘good_count’]/df[‘good_count’].sum()
df[‘woe’]=np.log(df[‘bad_rate’]/df[‘good_rate’])
df[‘iv’]=df[‘woe’]*(df[‘bad_rate’]-df[‘good_rate’])
df.replace({np.inf:0,-np.inf:0},inplace = True)
iv=df[‘iv’].sum()
print(feature,’IV’,iv)
df.to_excel(“path/{}.xlsx”.format(feature))
return(feature,iv)
column_list=df_new.columns.tolist()
df_iv_result=[]
for i in column_list:
df_iv_result.append(cal_iv(data_test,bin,i,’blackflag’))
data_iv=pd.DataFrame(df_iv_result)
data_iv=data_iv.rename(columns={0:’feature’,1:’iv’})
data_iv.to_excel(“path”)#no5.KS
def cal_ks(data,cut_num,feature,target):
data_cut=pd.cut(data[feature],cut_num)
cut_group_all=data[target].groupby(data_cut).count()
cut_y=data[target].groupby(data_cut).sum()
cut_n=cut_group_all-cut_y
df=pd.DataFrame()
df[‘sum’]=cut_group_all
df[‘bad_count’]=cut_y
df[‘good_count’]=cut_n
df[‘bad_rate’]=df[‘bad_count’]/df[‘bad_count’].sum()
df[‘good_rate’]=df[‘good_count’]/df[‘good_count’].sum()
df[‘good_rate_sum’]=df[‘good_rate’].cumsum()
df[‘bad_rate_sum’]=df[‘bad_rate’].cumsum()
df[‘ks’]=abs(df[‘good_rate_sum’]-df[‘bad_rate_sum’])
ks=df[‘ks’].max()
print(feature,’KS:’,ks)
df.to_excel(“path/{}.xlsx”.format(feature))
return(feature,ks)
df_ks_result=[]
for i in column_list:
a = list(cal_ks(data_test,bin,i,’blackflag’))
df_ks_result.append(a)
data_ks=pd.DataFrame(df_ks_result)
data_ks=data_ks.rename(columns={0:’feature’,1:’ks’})
data_ks.to_excel(“path”)
注意,path,分箱数需要指定。根据经验,分箱越多,可能ks/iv越高。
四、结语
关于是否三方数据相应问题,其实还想展开说几个讨论。
如通过百行、朴道的三方数据引入,应当通过单一来源还是公开招标。三方数据的初步评估,比较简单无脑,是否可以作为数据管理运营平台的一个功能去处理。以及百行朴道之后,多头的数据是否
有了新的解决方案等。或者业务断直连和三方数据断直连到底衔接顺序和关系如何。
限于篇幅问题,而且这些问题并没有标准的答案,就此打住吧。
本文由 @肥柴周 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


