
 起点课堂会员权益
起点课堂会员权益
GPT-4.5问世,情商爆表的AI,你见过吗?
 产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。
产品经理在不同的职业阶段,需要侧重不同的方面,从基础技能、业务深度、专业领域到战略规划和管理能力。OpenAI发布了最新大模型GPT-4.5,标志着AI技术的又一重大突破。本文解析了GPT-4.5的核心能力提升,包括其在写作、编程、多语言支持以及减少幻觉现象方面的显著进步,同时也探讨了其在推理能力上的局限性。

北京时间2月28日凌晨,OpenAI举行直播活动,发布其最新大模型GPT-4.5,作为预览研究逐步向用户开放。
因为在今年年初AI产业发生的惊天巨变,所以要准确形容这款被OpenAI藏了许久的大模型颇具挑战。OpenAI在新闻稿中表示,这是公司有史以来最大、最好的聊天模型,在计算效率上较GPT-4提升超过10倍。
早期测试反馈显示,与GPT-4.5的互动体验更加自然流畅,其知识库覆盖范围更广,对用户意图的理解也更为深刻。此外,GPT-4.5在“情商”方面的表现也颇为亮眼,有助于改进写作、编程技能以及解决实际问题的能力,同时有效减少了“幻觉”现象的发生,提升了整体的可靠性。
那么,这个更具“情商”的GPT-4.5到底展现出什么样的实力?
一、GPT-4.5能力更强吗?
在直播活动中,OpenAI强调,GPT 4.5展现出更强的审美直觉与创造力,在写作和设计方面表现尤为出色。但他们也承认,作为一个非思维链模型,GPT 4.5已经不具备争夺“宇宙最强大模型”的实力了。
在介绍文档中,OpenAI表示,有两个提升人工智能能力的互补范式。

一个是拓展推理,它能教会模型在反应之前先进行思考并产生思维链,从而解决复杂的STEM(Science科学、Technology技术、Engineering编程、Mathmatics数学)问题或逻辑问题。另一个是无监督学习,它能提高世界模型的准确性和直觉性。

其中,无监督学习,简单来说可以理解为让模型自己去知识的海洋里徜徉,自己学习到更多,从而变得更聪明,而非依赖人工标注。
在过去做法中,模型会结合人类反馈来改善响应与交互方式。彭博社援引知情人士称,去年OpenAI推出的Orion模型并未达到公司期望,在尝试回答未经训练的编码问题时就表现不佳。
OpenAI介绍,通过监督学习,GPT-4.5提高了其识别、建立联系和创造性洞察的能力,而无需推理。
根据OpenAI官方文档,GPT-4.5在SimpleQA中表现颇为亮眼。
SimpleQA是包含4000个事实性问题的数据集,用于测量模型在回答问题时的准确率。其中包含准确率和幻觉率两个维度。
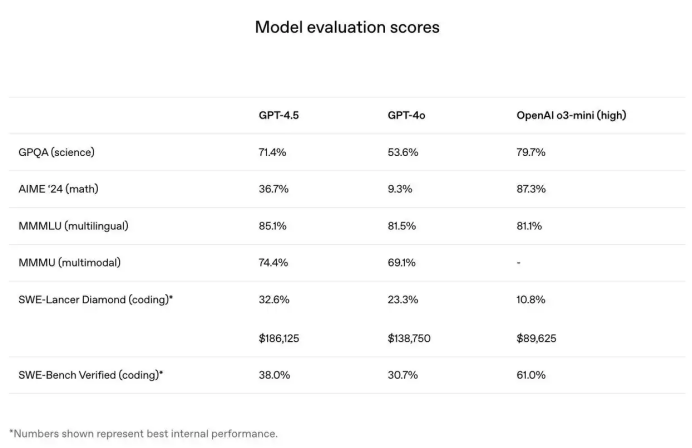
在附录部分,OpenAI才放出GPT-4.5的基准测试分数。在反映科学、数学、多语言、编码的GPQA、AIME’24、MMMLU、SWE-Lancer基准测试上,GPT-4.5得分分别为71.4%、36.7%、85.1%、32.6%,超过GPT-4o的53.6%、9.3%、81.5%、23.3%,但部分得分低于o3-mini。
另外,在标准基准测试中,GPT-4.5也获得了高分。
如在SWE-Lancer Diamond数据集上,GPT-4.5获得了32.6%的通过率,获得了186125美元(前不久Anthropic发布的擅长编程的Claude 3.5 Sonnet这个通过率为26.2%),比GPT-4o和o3-mini-high都高。
据悉,GPT-4.5将首先面向Pro用户推出,随后将在下周推广到Plus和Team用户,之后再逐步扩展到Enterprise和Edu用户。值得注意的是,用户现在已经在微软的Azure AI Foundry平台上尝试使用GPT-4.5。
二、更有“情商”的AI什么样?
在官方介绍中,OpenAI表示,对于GPT-4.5,他们开发了新的、可扩展的技术,利用来自较小模型的数据来训练更强大的模型。
而这些技术提高了GPT-4.5的可控性、对细微差别的理解以及自然对话的能力。这也表示ChatGPT可以更像“人”一样对话,更能洞察想法、体察情绪,并在回应中体现,而非一个无情的对话机器。
OpenAI也拿出了测试的结果证明GPT-4.5的使用感受会好很多:人类测试者的盲测中,GPT-4.5的偏好度远高于GPT-4o,不管是在日常问题、专业问题还是创意性问题的互动中都是如此。
在一项测试中,GPT 4.5在试图操纵另一个模型(GPT-4o)“捐赠”虚拟货币时,成功率远远优于OpenAI其他可用模型,包括o1和o3-mini这样的推理模型。研究发现,GPT-4.5似乎在对抗中开发了一种“小额诈骗”的思路,所以单笔骗到的钱会比deep research模型少了一倍。
GPT-4.5在欺骗GPT-4o透露秘密代码词方面也优于OpenAI的所有模型,比o3-mini高出10个百分点。

我们看到,AI大神Karpathy也是第一时间拿到了内测资格,发了一段超长的「GPT-4.5+互动对比」的体验解说,核心亮点是:
自从GPT-4发布以来,我期待这一天已经差不多两年了,因为这次发布让我们能够定性测量通过Scaling预训练计算(即简单地训练更大模型)所获得的进步斜率。
版本号中的每个0.5,大约代表10倍的预训练计算量。显然,GPT-4.5的预训练计算量比GPT-4多了10倍。
三、写在最后
随着GPT-4.5的发布,也意味着OpenAI迄今知识最丰富的模型发布,并且情商显著提升,能识别情绪并生成同理心回应,知识广度与准确性增强,多语言支持扩展至14种,低资源语言表现提升,在写作、编程和日常问题解决中上下文连贯性更强,不过,在推理能力上的提升有限。
未来,GPT系列有望在多模态融合上有更大突破,进一步提升对复杂问题的理解与解决能力,为用户提供更精准、更个性化的服务,同时在安全性与可靠性方面持续优化,更好地融入各类应用场景,我们也希望,在各个AI厂商不断的努力下,推动人工智能技术的广泛应用与发展。
作者|贾桂鹏
本文由人人都是产品经理作者【科技旋涡】,微信公众号:【科技旋涡】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









