
 起点课堂会员权益
起点课堂会员权益
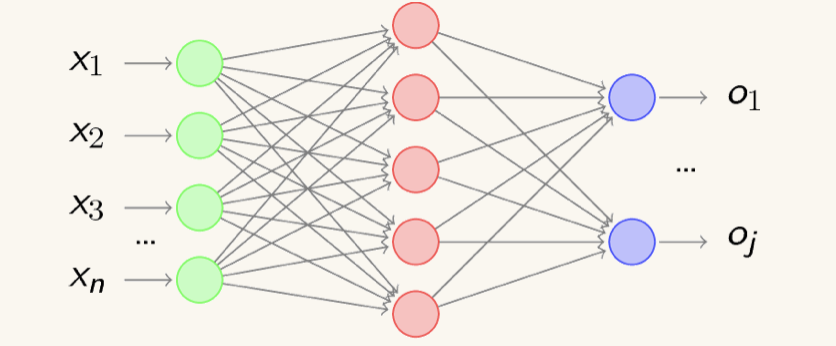
AI产品:BP前馈神经网络与梯度问题


通过上一章《神经元与神经网络》,我们大概了解了单个神经元的工作模式和简单神经网络的基本结构。接下来就要正式进入关于“神经网络”这个重头戏的学习了,神经网络分为“浅层”和“深层”,今天我们来探讨一下“浅层学习”中最经典的BP前馈神经网络,只要把它的工作原理搞清楚,其实后面的深度神经网络、卷积神经网络和循环神经网络都是在它基础上的变体。
一. BP前馈神经网络
1. BP前馈神经网络核心理念
BP前馈神经网络的英文全称为 Back Propagation Networks(反响传播网络),怎么理解这个“反响传播”呢,我们已经了解其实DL的核心理念就在于找到全局性误差函数Loss符合要求的,对应的权值“w”与“b”,也知道数据是从神经网络的输入层,进入隐含层,最后通过输出层输出的工作流程。
那么问题就来了,当得到的误差Loss不符合要求(即误差过大),就可以通过“反响传播”的方式,把输出层得到的误差反过来传到隐含层,并分配给不同的神经元,以此调整每个神经元的“权值”,最终调整至Loss符合要求为止,这就是“误差反响传播”的核心理念
2. 从“找关系”到“求误差”
前面我们已经多次提到”y=wx+b”,现在我给这个函数加一个“e”代表误差,其他的含义均不变
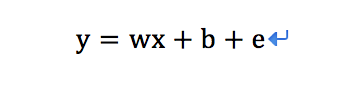
下面的转换,别被它吓到,其实很好理解,e的误差等于“真实数据y”减去“拟合值”,i代表数据的个数(简单理解为1、2、3……)
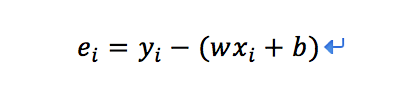
接下来点更好玩的(其实已经省略了一些步骤),我们一步一步来解释,Loss相信大家很熟悉了,就是所谓“全局性误差函数”,我们的最终目的,不就是让Loss等于“0”最好嘛,这就相当于是“现实的值”与“拟合值”完全吻合,也就是找到了数据与某种特征的现实“对应关系”。
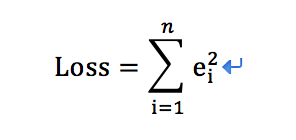
前面那个怪怪的图形,表示所有数据的“加和”(不然海量数据是咋来的呢),为什么要把误差“e”平方呢?其实是做了个“非负化”的处理,这样更方便运算嘛,正负不重要,重要的是“绝对值”。
最后,让我们看看我们得到了个什么东西:
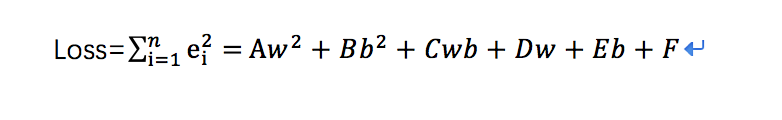
请各位不要慌,它就是一个“二次函数”,简化理解它的图像如下:
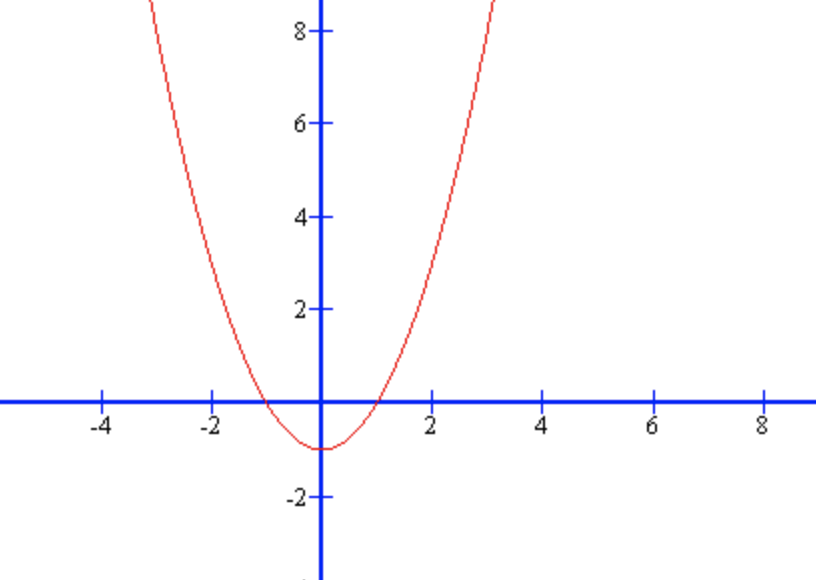
一切就到这里,通过上述过程的转换,让Loss这个全局性误差等于“0”,不就是转换成了求得这个函数“极小值”的问题了么!
理解到这一层,我想是时候对机器学习其中的一个本质做个总结:我们通过对数据进行“标签化”、提取特征“向量化”,将现实客观世界的“关系问题”,描述转换成数学函数中求“误差”的问题,又通过函数性质转换成求“极值”问题。换句话说,找到了这个数学的“解”,也就找到了现实世界的“关系描述”。情不自禁感叹“数学之美”!
二. 梯度下降与梯度消失/爆炸
1. 迭代法
我们已经理解到“求极值”这一层面,但还有问题等待解决。在一个算法模型训练最开始,权值w和偏置b都是随机赋予的,理论上它可能是出现在整个函数图像中的任何位置,那如何让他去找到我们所要求的那个值呢。
这里就要引入“迭代”的思想:我们可以通过代入左右不同的点去尝试,假设代入当前x左面的一个点比比右面的更小,那么不就可以让x变为左面的点,然后继续尝试,直到找到“极小值”么。这也是为什么算法模型需要时间去不断迭代很训练的原因
2. 梯度下降
使用迭代法,那么随之而来另外一个问题,这样一个一个尝试,虽然最终结果是一定会找到我们所需要的值,但有没有什么方法可以让它离“极值”远的时候,挪动的步子更大,离“极值”近的时候,挪动的步子变小(防止越过极值),实现更快更准确地“收敛”
请观察上面那个“二次函数”的图像,如果取得点越接近“极小值”,是不是在这个点的函数“偏导”越小呢?(偏导即“在那个点的函数斜率”),接下来引出下面这个方法:
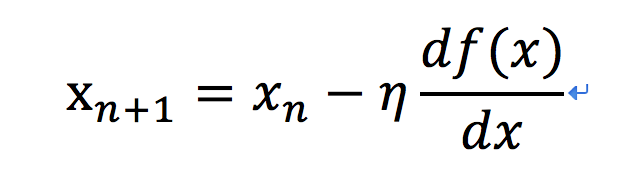
梯度下降核心思想:Xn代表的就是挪动的“步长”,后面的表示当前这个点在函数的“偏导”,这样也就代表当点越接近极值点,那么“偏导”越小,所以挪动的“步长”就短;反之如果离极值点很远,则下一次挪动的“步长”越大。
把这个公式换到我们的算法模型,就找到了“挪动步长”与Loss和(w,b)之间的关系,实现快速“收敛”:
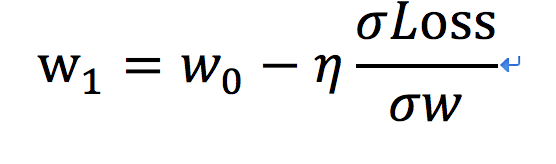
![]()
通过“迭代法”和“梯度下降法”的配合,我们实现了一轮一轮地迭代,每次更新都会越来越接近极值点,直到更新的值非常小或已经满足我们的误差范围内,训练结束,此时得到的(w,b)就是我们寻找的模型。
怎么样,现在是不是开始觉得对ML的本质理解的越来越深入,一旦转换成数学问题,我们就有很多方法可以实现我们的目标
3. 梯度消失
梯度消失,即在反响传播的过程中,因为层数太多或神经元激励函数作用,导致网络前端的w几乎没有变化,越往前的隐含层这种情况就越严重。
解决方式:目前常用的解决方式是选取合适的激励函数,如把Sigmoid函数换位ReLU函数,原理在这里就不过多解释了
4. 梯度爆炸
梯度爆炸,可以理解为梯度消失的“反向概念”,梯度消失本质是网络前层w权值变化太小,导致无法收敛,而梯度爆炸则是w权值一次的变化量太大,这样可能会导致直接挪动越过“极值点”。
最后
到这里已经基本介绍完神经网络BP前馈的基本原理,有没有觉得其实并没有想象中的那么难?而深度学习中的DNN(深度神经网络),如果不严格细纠的话,是可以简单理解为“隐含层层数”的增加的,基本的训练方法和工作原理也是一样通过误差反响传播,当然也做了很多优化来解决BP前馈网络的“缺陷”,这个我们在后面还会讲到~
相关阅读
本文由 @ Free 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议
















纯算法小白特地注册来感谢作者的讲解,确实从字里行间都能感受到作者对于小白的照顾,不知道作者5年后已经进步成什么样子了,作为一个从事刚产品两年的小白很想有机会能认识大佬,很多问题想请教沟通啊!