
 起点课堂会员权益
起点课堂会员权益只玩裂变还不够,你应该还会搭建病毒式增长模型
“裂变”玩法可谓是互联网产品界的当红炸子鸡,很多产品都正在或者希望靠裂变来实现用户增长,那该如何分析和预测这种病毒式增长对用户数的影响?我们应该学会搭建病毒式增长模型。

近期,“裂变”玩法可谓是互联网产品界的当红炸子鸡,随着前几天网易云音乐的《你的荣格心理原型》再次刷屏,很多产品都正在或者希望靠裂变来实现用户增长。
但是,该如何分析和预测这种病毒式增长对用户数的影响?就需要我们建立一个增长模型,下面就用5000字带大家一步步搭建增长模型。
本文翻译自Rahul Vohra的系列文章《How to Model Viral Growth》,这一系列是我见过分析病毒式增长模型最透彻的,因此推荐给你,希望可以对你有启发。
一、什么是病毒式产品?
我们做出一款产品,需要靠各种渠道获取新用户。但也许,最迷人的渠道是现有用户本身。
病毒式产品的大部分增长来自其已有用户吸引新用户,用户可以通过简单的推荐(“来看看这个产品,它很酷/有用/有趣!”),或直接通过使用该产品(“我想在PayPal上给你汇款!”)来吸引另一个用户。
病毒式传播最有名的例子之一是YouTube。
在其获得巨大流量之前,你很可能会在新闻网站或个人博客上找到嵌入的YouTube视频。当你看完视频,你会被邀请通过电子邮件把视频发给你的好友,并且你还会获得将视频嵌入你网站的代码。如果你不想分享,YouTube会向你推荐你可能喜欢的其他视频。
很大程度上,你会观看并分享其中的某个给你的好友。然后,你的好友会观看视频,也会与他们的好友再分享。通过这个“病毒循环”,YouTube快速获取了用户。
那我们该如何预测病毒式产品的表现呢?
比如:获得一百万用户需要多长时间?我们的产品可以触达到一千万用户么?
要回答这些问题,我们需要建立一个病毒式模型。
二、最简可能性模型
假设我们有5000个初始用户,这些初始用户将带来多少新用户?
常见的情形是这样的:有些用户喜欢我们的产品,有些用户不喜欢;有些用户会邀请很多好友,有些不会邀请;有些用户可能在一天之后邀请好友,而有些用户则可能需要一周…
我们排除所有这些不确定性,假设平均而言,五分之一的用户会在第一个月成功带来新用户,那我们的病毒系数是1/5 = 0.2。我们最初的5000个用户会在第1个月吸引5000 * 0.2 = 1000个新用户,这1000个新用户会在第2个月再吸引1000 * 0.2 = 200个新用户, 接着第3个月会再吸引另外200 * 0.2 = 40个新用户,依此类推。
根据上面的计算,如下图所示:我们的用户会一直增长,直到我们拥有6250名用户。
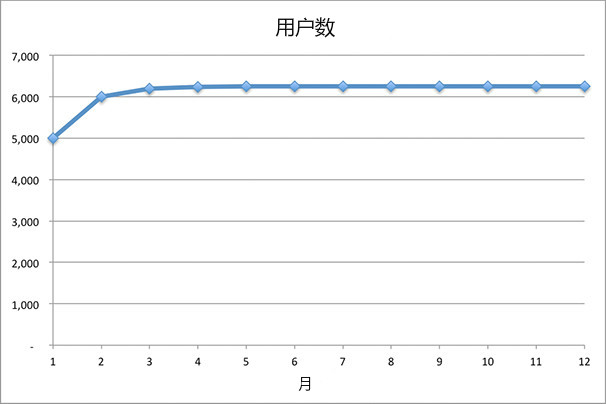
图2-1
如果我们的病毒系数是0.4,会发生什么?
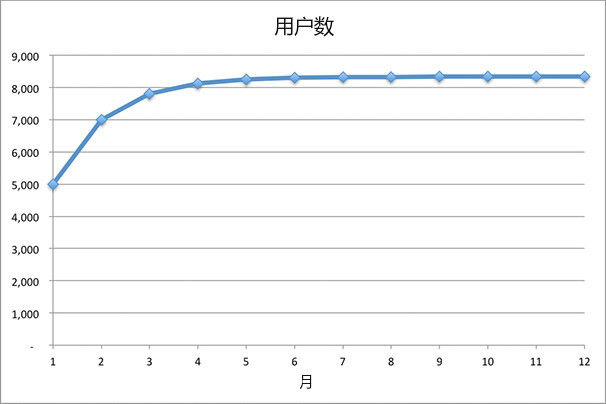
图2-2
同样,我们以不断下降的速度获取用户。但这一次,我们的增长会一直持续到约8300名用户。
如果我们的病毒系数是1.2,会发生什么?
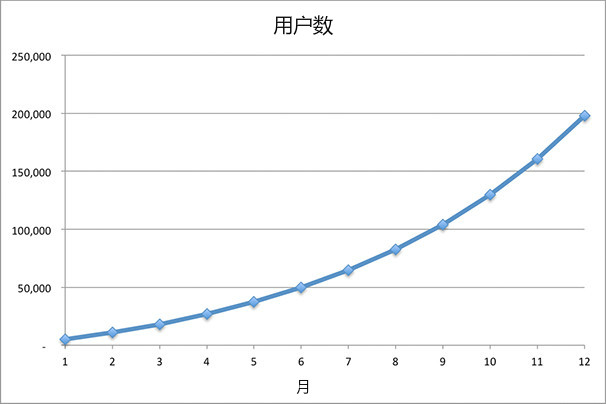
图2-3
这一次,我们以不断增长的速度获得用户。
事实上,通过一些简单的数学,我们可以得到以下结论:
- 假设初始用户数为 x,病毒系数v小于1,我们就会以递减的速度获取用户,直到我们拥有x /(1-v)名用户。
- 假设病毒系数大于1,我们会以显著增长的速度获取用户。
看到这里,你可能会说,这还不简单,我们只要让病毒系数大于1就行了。但是,其实并没有这么快……
- 首先,我们的模型存在很多问题,比如:随着我们获取越来越多的用户,我们最终会面临没有新用户可以获取。
- 其次,真正的病毒式增长非常罕见,很少有产品能在一段时间内,使病毒系数超过1。
通过和其他创业者,投资者和增长黑客讨论,我发现了这个结论:对于互联网产品,0.15至0.25的可持续病毒系数是不错的,0.4是优秀的,大约0.7是卓越的。
然而,我们刚刚已经证明了,当我们的病毒系数小于1时,我们会以不断下降的速度获取用户,直到不再增长。这并不是我们想要的结果,所以这其中缺少了什么呢?
我们忽略了可以获取用户的其他渠道:新闻、应用商店、直接流量、集客营销、付费广告、搜索引擎优化、明星代言、街头广告等等。
下面,我们就把这些因素考虑到模型中来。
三、混合模型
混合模型包括了非病毒式传播渠道。
一些非病毒式传播渠道,比如:新闻,将使我们的用户数一下飙升。但另一些渠道,比如:应用商店,对用户增长的贡献会相对持续且平稳。
我们的模型需要尽可能的包含不同类型并尽可能的简单,因此,我们将考虑以下3种非病毒式传播渠道:
- 新闻:优秀的新闻发布会很可能会吸引70,000名新用户。
- App store搜索流量:应用商店每月可提供40,000次下载。但并非所有下载用户都会运行、注册我们的App并有不错的首次用户体验。让我们假设60%的下载用户有很好的首次体验。
- 直接流量:由于我们的老用户会进行口碑传播,潜在用户会直接找到我们的产品,这可能每月带来10,000次下载。让我们再次假设60%的下载者都有很棒的体验。
最后,我们假设应用商店搜索流量和直接流量都会保持不变。
让我们将病毒系数设置为0,看看如果我们的产品根本没有病毒式传播,用户增长会如何。

图3-1
在今年年底,我们会有约450,000名用户,现在让我们加入病毒式传播。
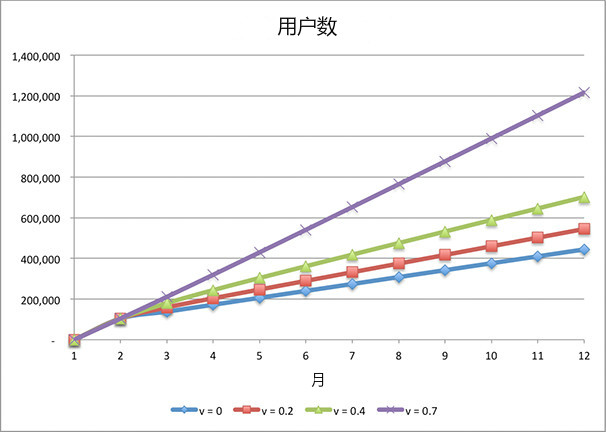
图3-2
在不错的情况下,病毒系数为0.2,在年底我们会有约550,000个用户。在病毒系数为0.4的情况下,年底我们会有约70万用户。如果我们的产品非常卓越,病毒系数为0.7,那么在年底我们会有约120万用户。
放大系数
上图说明了我所认为的病毒式增长:不在于病毒系数v,而是放大系数 a = 1 /(1-v)。想要计算用户总数,我们要做的就是用非病毒式传播渠道获得的用户数*放大系数。
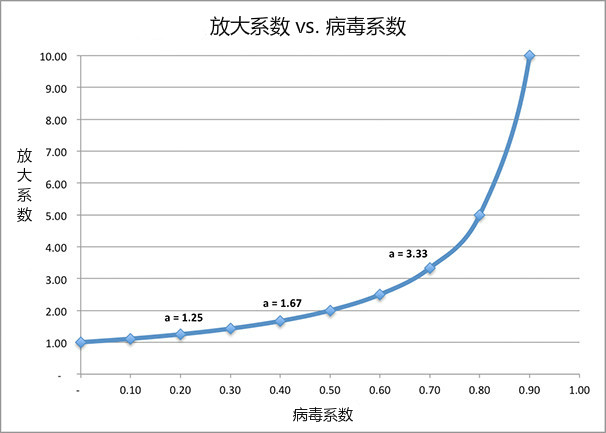
图3-3
该图显示了病毒系数的惊人潜力,即使它小于1:随着病毒系数的增加,放大系数呈双曲增长。也就是说,只要具备一个很好的病毒系数,我们可以不断加速放大非病毒式传播渠道的引流效果。
模型存在的问题
在模型中增加非病毒式传播渠道很有用,但我们的模型仍然存在重大问题。比如:我们假设获取的用户会永远留存下来。
但现实是残酷的:用户会随时停用、删除或遗忘某产品。因此,我们需要进一步优化模型。
四、混合模型(包括用户流失)
假设我们的病毒系数是0.2,并且我们有以下非病毒式传播通道:
- 发布新闻,吸引了70,000名初始用户
- 应用商店搜索流量,每月吸引24,000个新用户
- 直接流量,每月带来10,000个新用户
在模型中,让我们假设每月有15%的用户流失,数据如下:
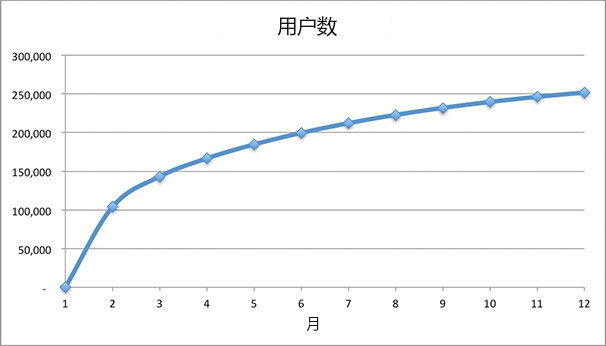
图4-1
在我们发布的新闻提供初始用户高峰之后,我们的增长似乎放缓了。事实上,即使我们的非病毒式传播渠道不断带来新用户,我们的病毒式传播渠道不断发挥他们的放大效应,从图中看,我们的增长也可能会完全停止。
究竟发生了什么?
为了使效果更明显,让我们将病毒系数设置为0,将月流失率设置为40%。
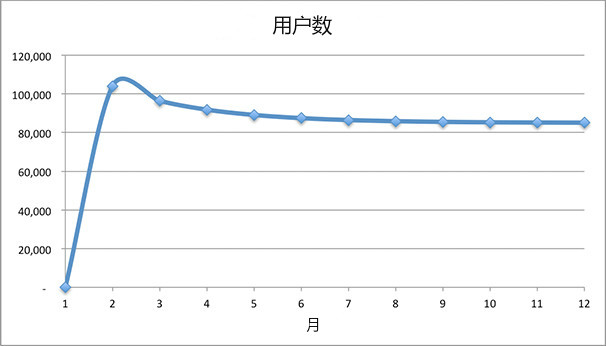
图4-2
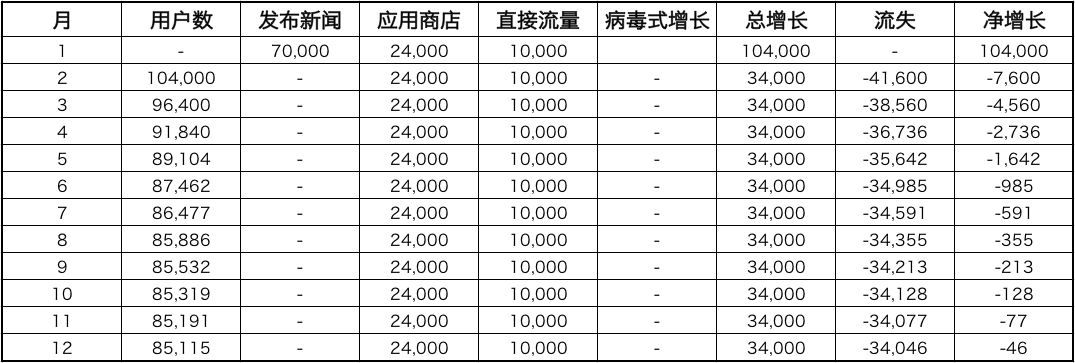
表4-2
在我们发布新闻后,我们的用户增长速度迅速稳定在每月34,000名用户。但是,在流失那一列,由于我们每月损失一定比例的用户,随着用户池的扩大和缩小,我们的流失数也会扩大和缩小。 事实上,我们的用户池将倾向于一个固定的规模,因为最终用户流失将等于用户增长。
承载能力
用户的增长和流失率直接决定了最终用户数量,在此模型中称之为承载能力。承载能力的定义是:当流失用户的速度等于获取用户速度时的用户数量,公式如下
U•l = g
U是承载能力;l是每月的用户流失率(或者在一个月内失去任何特定用户的概率);g是每月的非病毒式增长率。
因此,可知承载能力的计算公式为:
U = g/l,其中l≠0
为了使最终用户数量增加一倍,我们有两种选择:
- 将非病毒式增长率提高一倍(比如:在非病毒式传播渠道中投入更多资金)。
- 将流失率降低一半(比如:通过改善首次用户体验,或者将营销渠道集中在更精准的用户群)。
往往我们会两者兼具。
在我们刚刚的例子中,g是每月34,000用户,l是每月40%。该公式预测出我们的最终用户数U为34,000/0.4 = 85,000,正如图4-2所示。
具有病毒因素的承载能力
接下来,我们该如何修改承载能力公式以解释病毒式传播?
前文说过,当我们的病毒系数小于1时,我们可以把它解释为放大系数 a = 1 /(1-v)。由于放大系数适用于我们的非病毒式增长率g ,我们可以直接把a放进公式里:
U = a•g / l = g /(l•(1-v)) 其中l≠0且v <1
让我们回到第一个例子,我们的增速正在放缓。在这里,g是每月34,000个用户,l是每月15%,v是0.2。该公式预测我们的最终用户数U 为34,000 /(0.15•(1-0.2))= 283,000。这个结论正好和图4-1的发展方向吻合。
五、留存曲线
假设我们的产品非常棒——人们在生活中离不开它,会在开始使用后的数月甚至数年都保留。对于这样一个好的产品,我们的之前的用户流失模型就太苛刻了,随着用户持续使用我们的产品,我们会更好地留住他们,因为会发生以下几种自我强化效应:
- 用户在我们的产品中留下的数据增多,转换到竞争对手会更加困难(例如:Dropbox和Evernote);
- 用户在我们的产品上投入的时间增多,会养成使用习惯(例如:Uber);
- 基于上述两种情况,用户与我们的产品建立了情感联系。
现实中,我们的用户会展现出留存曲线,留存曲线体现了用户在给定时间点仍在使用我们产品的可能性。
留存曲线取决于产品的类型和质量,以及我们对营销渠道的定位。比如:浏览器插件,通过调查,我了解到不错的浏览器插件的留存曲线长这样:
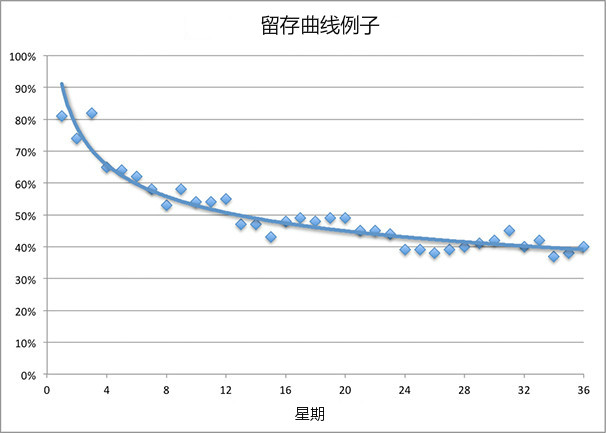
图5-1
一周后,可以留住80%的用户。一个月后,可以留住65%的用户。两个月后,可以留住55%的用户。长期看,会留住约40%的用户,并且每月的下降速度非常缓慢。
六、病毒式传播曲线
在我们把留存曲线加入模型之前,让我们先考虑留存曲线对病毒式传播的影响。
到目前为止,我们假设我们的用户只会在第一个月邀请身边的好友。但是,如果40%的用户会长期使用我们的产品,并且持续邀请身边的好友,那么我们的用户数将实现病毒式增长。
换句话说,我们的用户也将展示出病毒式传播曲线,病毒式传播曲线体现了普通用户的病毒系数随时间如何变化。
为什么用户的病毒系数会随着时间而改变?
除了很大程度上取决于产品,也要考虑以下场景:
- 起初,用户会犹豫是否邀请好友使用,因为他们仍在测试我们的产品;
- 一旦用户爱上我们的产品,他们会快速邀请一群好友来使用;
- 很快,用户会邀请完身边可以邀请的好友;
- 偶而,用户会邀请他们刚认识的新朋友。
在这个场景下,用户的病毒系数会有短暂的初始延迟,然后会快速增加,接着快速减少到稳定但较低的速度。
我们可以对这个曲线的每部分都进行建模,但可以聚焦到最主要的趋势:病毒系数随时间而变小,因为用户会邀请完可以邀请的好友。
让我们用几何衰变来建模:每个月,病毒系数是上个月的一半。 例如:病毒系数在第一个月可能是 0.2,第二个月是 0.1,第三个月是 0.05,依此类推:
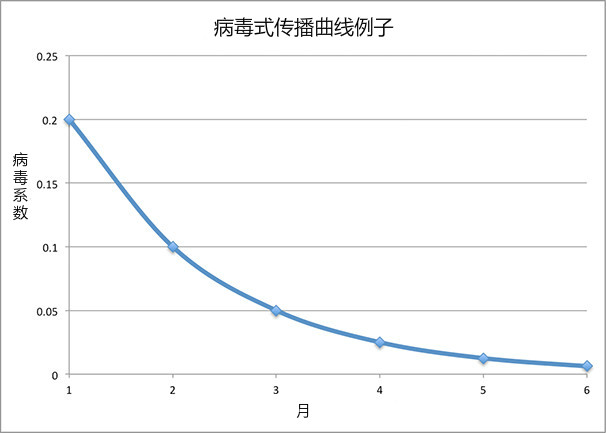
图6-1
如果我们把用户生命周期中所有的病毒系数相加,就会得到终生病毒系数v’,为 0.2 + 0.1 + 0.05 + … = 0.4。
我们之前的直觉继续适用:
- 对于互联网产品,可持续的终生病毒系数v’在0.15至0.25是不错的,0.4是优秀的,0.7是卓越的。
- 我们的放大系数 a 现在为1 /(1-v’)。
七、组合模型
截止到目前,我们升级了模型:结合了非病毒式传播渠道,保留曲线和病毒式传播曲线。公式比以前更复杂,下面我们就把它们变得直观些。
除了用户增长图,我们还做了下面的图表,用于比较各个增长渠道,以及其对用户流失的影响。
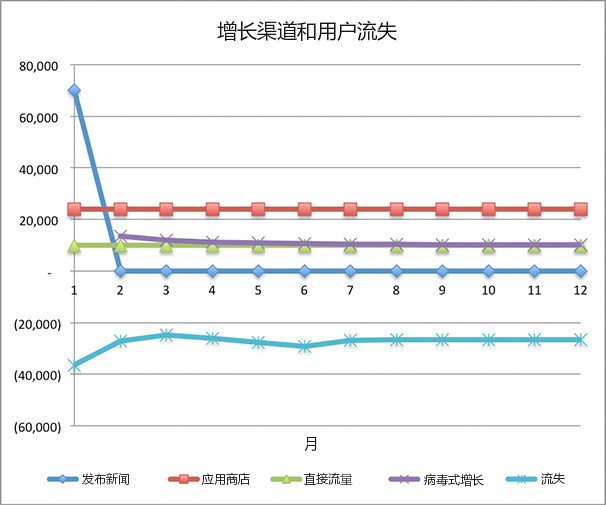
图7-1
想知道这些因素如何相互作用的最好方法是做数字游戏并观察图表的变化。在观察增长渠道与流失的对比时,我们可以尝试以下方法:
(1)提高留存曲线
将第1个月留存设置为90%,第2个月留存设置为80%,第6个月留存设置为60%。
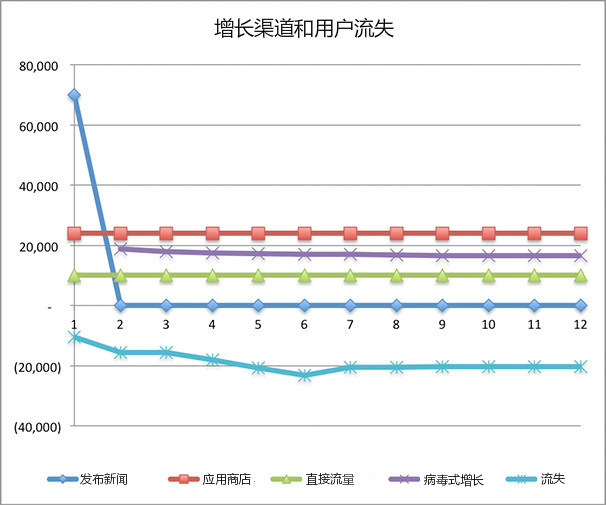
图7-2
我们看到不仅流失减少了,病毒式增长也增加了。因为当用户停留时长增加时,他们会邀请更多的好友。
(2)提高病毒式传播曲线
将第1个月的病毒系数设为0.35,因此终生病毒系数会为约0.7。
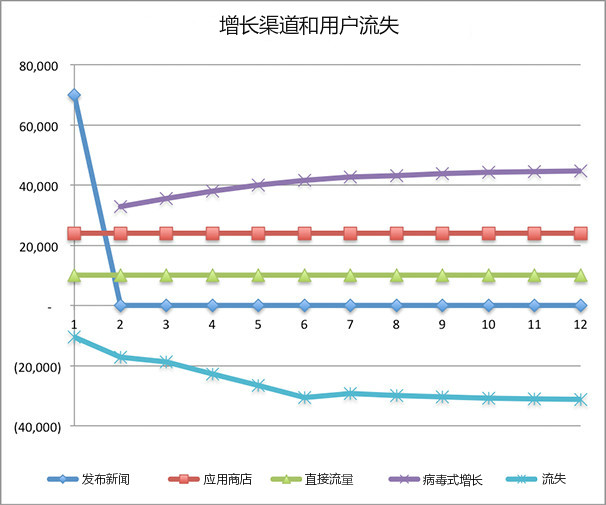
图7-3
这对病毒式增长渠道产生了巨大影响,该渠道从每月约20,000名用户增加到每月约40,000名用户。但对用户总数影响不大,因为从长远看,我们仍会流失40%的用户。
(3)再加入一个新闻发布
将第6个月的“发布新闻”设置为100,000。

图7-4
我们可以清楚的看到图里的峰值,相应地,它导致了流失峰值。不久之后,可以看到病毒式增长迅速飙升然后缓慢下降,因为没有更多新用户了,并且我们的新用户也没有更多好友可以邀请。
八、局限性
我们永远不要满足任何模型,因为它们都有局限性,我们的模型可以改进的以下方面:
- 我们假设非病毒式传播渠道保持不变,事实并非如此:平台增长,新竞争对手和口碑传播都会带来很大影响。
- 我们考虑了数量有限的渠道,事实上,我们会有更多非病毒式传播渠道和病毒式传播渠道。
- 我们假设6个月后停止流失用户。不幸的是,不管是自然流失还是用户转向竞争对手,我们一直会流失用户。幸运的是,当我们获得了数据后很容易建模:要做的就是将留存曲线延长到6个月之后。
- 我们保守地假设用户在6个月后停止病毒式增长。同样,当我们获得数据时,很容易建模:所需要的只是延长我们的病毒式传播曲线。
- 我们假设留存曲线和病毒式传播曲线不会随时间而改变。事实并非如此:随着我们不断测试和迭代产品,我们的留存曲线和病毒式传播曲线也会得到改善。
最后,我们再回顾一下文中的模型是如何一步步优化的:开始为最简可能性模型,后来引入了非病毒式传播渠道,迭代为混合模型,接着进一步引入了用户流失,升级为混合模型,最后引入留存曲线和病毒式传播曲线,成为组合模型。
当然,正如文章最后所说,每个模型都有其局限性,我希望本文可以为你捋清建模思路,从而对你的用户增长有所帮助和启发。
本文由 @原子大大 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议










承载能力公式里g的定义应该是“每月的非病毒式增长用户数”而非“每月的非病毒式增长率”,希望纠正~~
到承载能力那部分已经错了好么
456
写的真好
很好
的确是很好
没错
是呀是呀
支持支持
123
是的
mercy