
 起点课堂会员权益
起点课堂会员权益打造冷启动:走出先有蛋还是先有鸡的困境
本文讲冷启动问题归为三类:用户冷启动、物品冷启动、系统冷启动,并针对性地介绍了其中的操作思路与注意要点。

冷启动(cold start)在整个推荐系统中,是一个重要的开始。推荐系统一般需要在大量的数据基础上才能比较准确的进行推荐,APP的冷启动可能直接决定着这个新用户会不会继续使用,新物品的冷启动也影响着生产者的积极性,所以冷启动很重要。
冷启动问题分为3类:
- 用户冷启动:新来的用户,应该给他推荐什么内容?
- 物品冷启动:新来的物品,应该把它推荐给谁?
- 系统冷启动:在“一穷二白”的基础上,新来的用户和没有推荐过的物品,怎么建立他们的关联?
用户冷启动思路
用户冷启动,最常见的场景就是新用户冷启动。一个新用户转化为老用户的路径是:新用户兴趣获取(构建冷启动用户初始画像)->内容消费和兴趣收敛->沉淀兴趣成为老用户。概括地说,第一步就是“千方百计”获取用户画像或让用户主动产生画像,有几种方法可以考虑。
利用用户的社会属性,如性别、年龄、地区等。在用户第一次打开APP的时候,很多APP会提示或留有入口供用户填写相关信息。即使用户不主动输入,也可以尝试从外部渠道(渠道画像、矩阵画像、applist等)引入画像信息(但需要注意用户重合度和相关度)。有了这些信息,就可以基于社会属性进行粗颗粒度的个性化推荐。
利用用户的关系链,可以借助运营活动收集(如支付宝活动收集好友关系、亲子关系)或从外部引入(第三方登录或开放API),基于“人以群分”的道理给用户推荐好友喜欢的内容。
利用热门内容,对用户“一无所知”的情况下,基于从众心理和二八定律,可尝试给用户推荐热门内容,这种方式主要注意热门的范围和算法,效果会比随机推荐好。利用高质量内容同理。
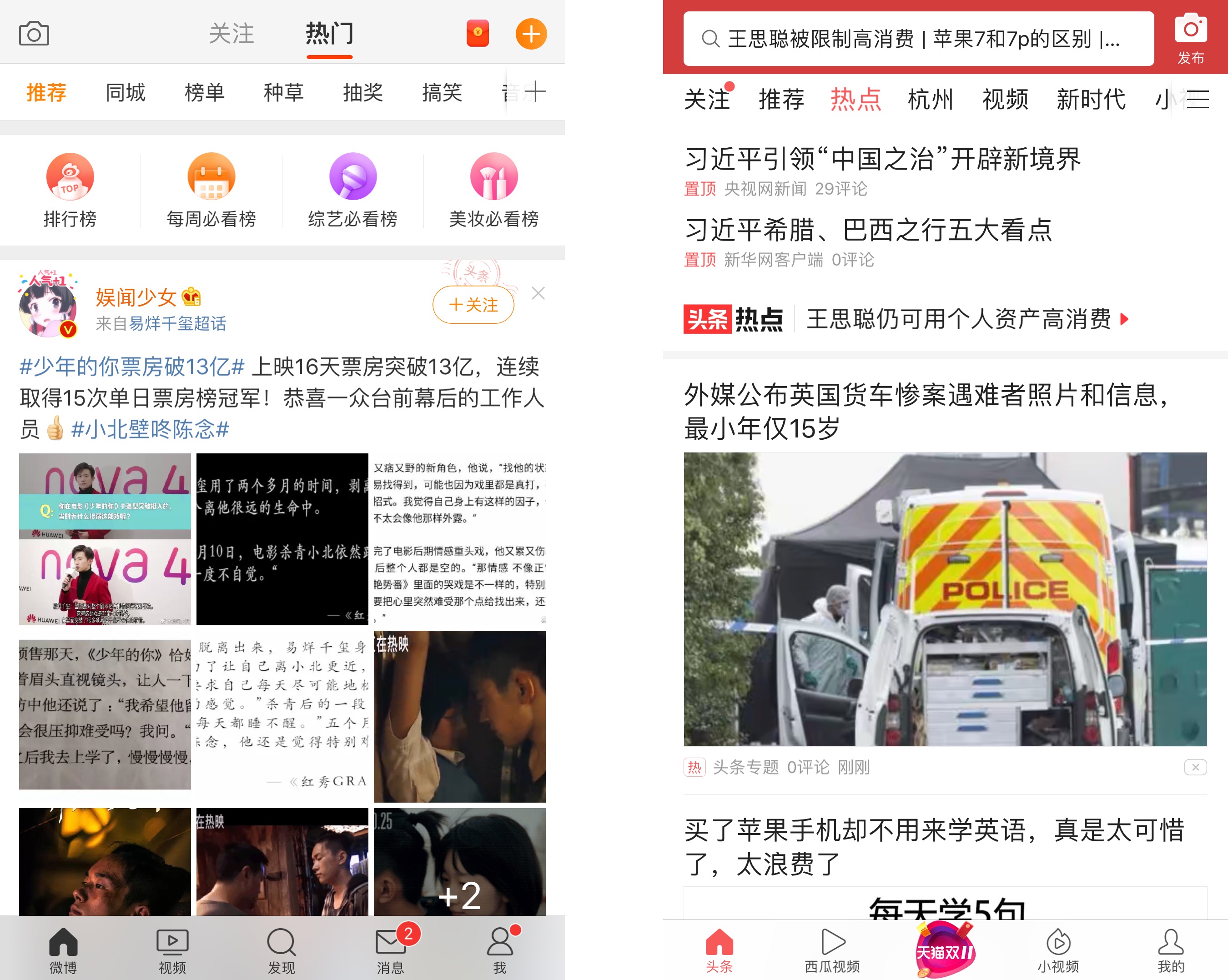
(左:微博,右:今日头条)
用户冷启动的指标可以关注新用户的画像指标(人均兴趣数、画像覆盖率、画像准确率等)及新用户活跃表现(点击率、留存等)。
假设一款国际APP,基于国籍和性别就能在一开始有一个比较好的推荐效果,它有什么办法获得这些信息?
- 显性方式:如前文所说,让用户填写、引导或激励的方式都可以。
- 隐性方式:用一些性别/国籍点击差异特别大的内容来猜用户性别、国籍,再开始有偏向的个性化推荐。
这类隐性探索,选取物品需要有技巧:
- 热门:有一定的认知度,物品过于生僻,得到的结果大部分必定是“跳过”。
- 代表性和区分性:物品与物品之间要有区分度,能表征用户的不同兴趣。
- 多样性:由于人的兴趣多种多样,要注意尽可能覆盖,避免“无可选”的尴尬。
物品冷启动思路
利用物品内容推荐:
- 物品相似推荐:找到和新物品属于同一类的内容,新物品搭上“顺风车”,进行相似推荐。
- 物品相关推荐:基于专家的知识来建立起物品的信息知识库,建立物品之间的相关度。如知识图谱,通过一个已知节点和关系找到另一个节点,进行拓展推荐。
- 例如某用户喜欢“周冬雨”(节点),周冬雨是电影《少年的你》的主演,通过这层关系关联到节点“少年的你”,因此将《少年的你》推荐给用户。
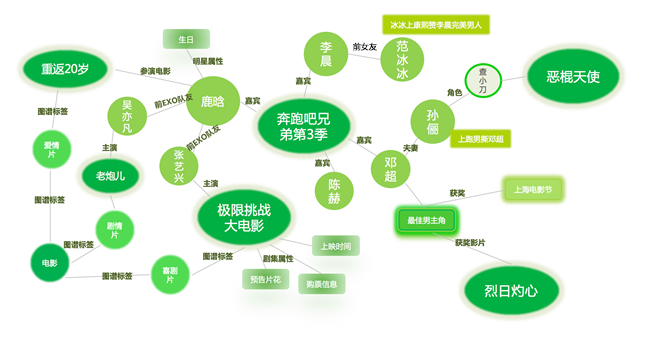
(图片来源于网络)
相关算法简介
期间涉及的常用算法有哪些?假设A用户是新用户,只有少量画像。
- UserCF:基于用户的协同过滤,通过用户行为计算用户的相似度,找到和A用户相近的B用户,给A用户推荐B用户喜欢的物品。
- ItemCF:基于物品的协同过滤,通过用户行为计算物品的相似度,找到和物品a相似的物品b,将物品b推荐给喜欢物品a的用户A。
- ContentItemKNN:基于内容的过滤,根据物品的内容特征计算内容的相似度,找到和物品a相似的物品b,将物品b推荐给喜欢物品a的用户A。
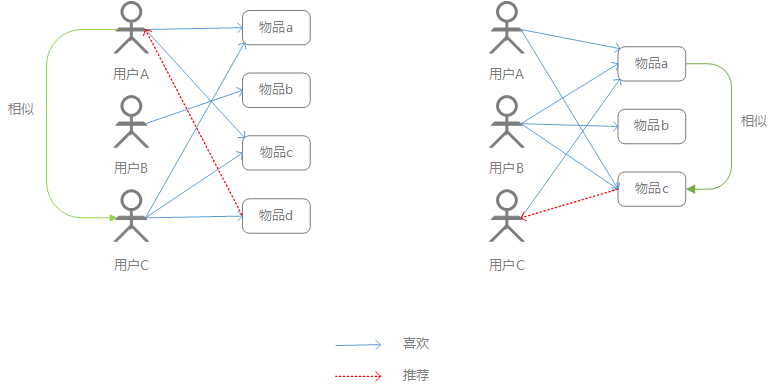
(左:UserCF,右:ItemCF)
UserCF和ItemCF使用的是同一份用户行为数据,只是统计维度不同。如下图简单示例(1表示用户点击了该物品),UserCF是横向计算用户的相似度,ItemCF是纵向计算物品的相似度。
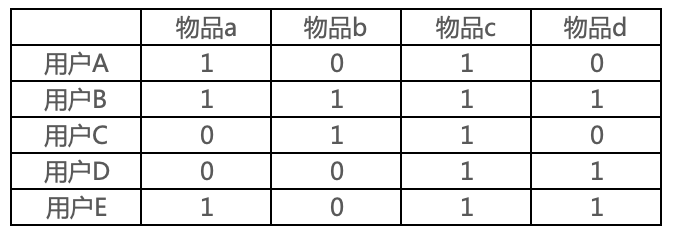
UserCF、ItemCF在冷启动问题上都有“第一推动力”的问题。
UserCF,要让新物品先出现在用户展示列表,才有可能让更多的人对这个物品产生反馈,物品才能扩散出来,所以有一个第一推动力的问题,即第一个用户从哪里发现新物品。
ItemCF是隔段时间计算用户行为(日志庞大,较耗时)从而计算出物品相似度(如果大量用户看了物品a,同时也看了物品b,即认为这两个物品是相似的),输出一个物品相关度矩阵,新物品加入时并不会自动加入这个矩阵表,也需要有用户先发现这个新物品。
ContentItemKNN利用物品的内容特征计算物品相关表,可以频繁地更新相关表,没有第一推动力的问题。但它忽视了用户行为,从而忽视了用户行为中所包含的规律,结果精度低,新颖度高,效果一般不如协同过滤。但如果用户行为强烈受某一内容特征的影响,内容过滤算法有亮点。
前文提及的第一推动力问题,即物品冷启动问题,也称“新物品试投”,有什么办法解决?
新物品试投是“物品找用户”。如果是“用户找物品”,容易出现马太效应:热门分类曝光多,长尾现象严重。物品找用户的方式有两种:
- 随机试投
- 兴趣试投
假设我们定义曝光500次以下的物品是新物品(资讯类产品一般还有时间限制,如6小时内),将新物品和用户表征为多维向量,计算向量的距离,对较活跃用户分发,在冷启动阶段排序加权和重排限制。物品在冷启动阶段会有一个趋于稳定的点击率(或其他综合指标),该点击率是它后续流量分配的依据——根据小流量的点击率表现,表现好的物品进入下一个更大的流量池,表现差的物品被淘汰或降权。梯度流量分发策略是比较常见的个性化推荐“赛马机制”。
用哪些指标评估物品冷启动效果?
- 模型准确度
- 单位试投次数
- 有效分发覆盖率
- 物品优质率
- 新物品推荐表现(点击率、时长等)
另外一点,还需要注意用户的上下文信息,包括时间信息、空间信息,走一些强规则。
例如电商APP,新用户在夏天登陆,就不应该推出羽绒服;在中秋节登录,就不应该推出端午节的资讯。但这不仅是在冷启动阶段,在整个推荐场景都应该留意用户的上下文信息。
备注:参考文献《推荐系统实践》项亮 编著
本文由 @张小喵Miu 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









赞 ~
谢谢😄