
 起点课堂会员权益
起点课堂会员权益精细化运营的核心支持工具:决策引擎
编辑导语:决策引擎是一个工具,利用决策引擎可以支撑企业在客户管理(CRM)的各种决策,在决策引擎之上可以开发出各种不同的解决方案。运营要讲求精细化,要根据产品、用户、市场的具体情况制定具体的运营措施。文章主要分享了决策引擎在用户分层精细化运营领域的应用方法,希望对你有用。

我个人是不太喜欢“道法术器”之类的描述的,所谓强国之策无奇计,结硬寨打呆仗一直是我所笃信的策略和指导意见,但不得不说,前述的几个短文简单的描述了精细化运营的“道法术”,也就是为什么要做、到底怎么做、如何控制其不偏离整体目标的问题。抛开这些,个人觉得智能化商业化的决策引擎,算是改变了重人力职场作业模式的最重要的“器”。
在前东家时,有段时间,因项目和工作调整,负责了部门决策引擎的更新换代,或者叫救死扶伤。近期依稀想起来记得刚刚接手该项目时,囿于前人留下的SHIT MOUNTAIN CODE、无说明、无PRD等,作为一个接手一件事务,习惯性了解其全貌的铁头娃,着实有一段时间天天挠头。可以说无从下手,并不理解从怎么样的角度去切入。
基于后来的理解,大部分的决策引擎,或者说在市面上能买到的决策引擎,大都是基于Drools的二次封装,其基于JAVA语言。可能是理解过于粗浅,但在我理解上来说,其无外乎做到了两点:①(理论上的)业务及策略人员可无代码使用;②赋值效率明显提升;
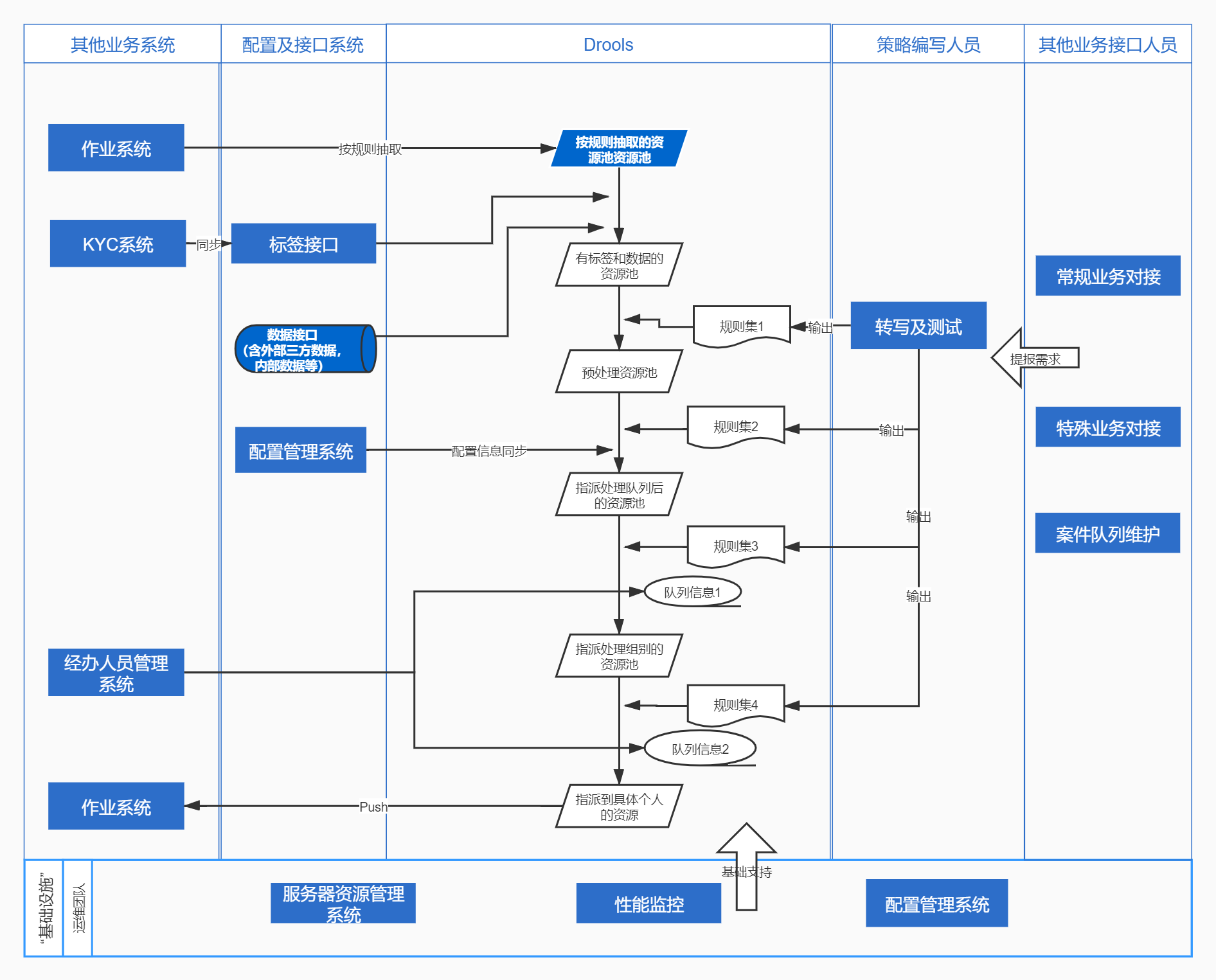
一个成熟可用的【决策引擎】,与其说是一个单独的系统,不如稍微扩展一下视野。其应该是包括Drools在内,包含KYC用户画像,KYE经办人画像,一个良好的配置中心,一个良好的展示页面(如稳定的电销系统/电催系统),以及一个稳定且健壮的策略/运营团队等。
在之后的业务需求中,任何一个环节和问题,都会引起最终的结果的偏差。
依稀记得当时遍寻适宜的教程而不得。要么流于形式,很显然是不知从哪里拾得的只鳞片爪的牙慧,要么就是伟光正但不解决实际问题的PPT,要么囿于一隅,很容易将自己的眼光局限在一小块。并不满足一个策略部门决策引擎产品经理的需求。
本文基于,DroolsWorkBench6.2/6.4版本。仅对SQL/IMPALA/HIVE/PYTHON有过了解,对决策引擎、Drools毫无了解的视角去展开。希望能为因为种种原因,在策略实施阶段,仍需要通过WorkBench编写伪代码的策略人员/数据产品人员提供一丢丢帮助,日行一善。如果有人看到了之后能少掉几根头发,希望少掉的头发能长在我的头上。
CSDN上’在风中的意志’大佬救了我不少头发,遥远感谢下。
一、什么是决策引擎及使用范围
决策引擎,对于业务人员来讲,在大部分语境和语义下,都是指在业务线中,可根据复杂的决策规则,起到路由作用,可以支持复杂决策流,决策树规则的,将案件/客户分发的一个工具。
最常见的使用范围有:
- 电销业务场景,尤其是‘热名单’分配;
- 电催业务场景,巨量案件分配及案件滚动拨打的实现;
- 风险管理场景,模型规则应用的配置等。
至少在我浅薄的认知中,决策引擎主要起到的就是【客户】这一核心资源的自动分配任务。
常规的决策引擎,不论是否支持“拖拉拽”的Fancy方式制定决策树/决策流,无论宣传语上提到自己支持多少种业务场景。绝大部分的决策引擎,都是基于Drools(基于Java的BRMS解决方案)优化、迭代、融合自己的一些业务经验,打包而成的东西。
相对于某些同业,仍然使用手工的方式去分配案件,算不清楚营收平衡需要多少客户,做不到新增登陆APP的客户及时问询购买产品意向来说,决策引擎已经算是较为高科技的工具了。
What’s more .决策引擎,个人感觉是通过常规的业务管理方式,已经很难再挖掘业务潜力之后,所自然而然的,基于精细化运营之后所需的一个产品,主要用于策略的频繁修改及客户资源的令行禁止,而不是一个常规管理手段都没有做好的BU,通过引入决策引擎,就可以翻身了。
一个良好的决策引擎,隐含所需的 KYC客户画像水平,KYE 员工管理水平,坦而言之,两者间能做到一个长处已经可以算作优秀,两个长处可以算作极品了。
KPI靠分解、分层、分类、分级,执行的时候靠定价、定级、定量、定责。做到这些决策引擎才能发挥最大作用。当然这个就不在文章讨论范围内了。
二、决策引擎的组成
一个常规的决策引擎的组成有:
- kmodule.xml:定义好的流程文件;
- *.drl:由策略人员修改的策略集文件;
- KIE结构:’通过KieServices对象得到一个KieContainer,然后KieContainer根据session name来新建一个KieSession,最后通过KieSession来运行规则’。
- (可能有)前段展示界面;
对于产品或者策略来说是不是看不懂。没事,我到现在也看不懂。这部分问题还是交给技术人员去考虑。
技术及组件相关的,在此我只想就个人经历着重提醒注意几个点:
- 还请稍微注意一下*.drl语法:如经典的no-loop 、static 是否循环判断等,对计算效率及最后结果是否是自己想要的有极大影响;
- 还请稍微注意一下'<groupid>/<artifactId>/kbasename’等:编写DRL规则文件时,如果使用的不是拖拉拽版本的决策引擎,针对此类字眼名称,烦请多次检查,否则打包时,会导致各种各样的报错频频;
- 标签少点、少点、少点:不论是风控决策引擎,或者是电销、电催相关的决策引擎;不论是从外部引入第三方的数据标签,或者是在自己的KYC/KYE中形成自己客户、坐席的标签;标签是有悄无声息地突然增多的倾向的。标签应用到决策引擎上,应当是有详尽完善的测试之后再进行的。此外,标签应当多一些类别,少一些数量。否则标签的不及时清理,又会堆积成新的屎山。
- 新的策略包上线时,不论有多困难,还请做一次上线测试,一次灰度测试:按之前的经验,假如说待判断案件有200万左右时,一次策略回滚,可能导致近12个小时无法生产,在这个时候,锅是甩不到运维那边计算效率低的。还请在上线前做一次上线测试。如果条件允许,配按量的灰度测试是极佳的;
- 版本管理、版本管理、版本管理:现在大部分封装好的决策引擎已经可以提供版本管理和回滚的功能。但如果你使用的是裸露在外的DROOLS,还请自行做好版本管理的工作,以免之后领导突发奇想想回滚时找不到;
- 队列管理、队列管理、队列管理:不论是电销或催收、或者是风控决策引擎,合理的学习交行卡中心所做的队列管理思路是不会错的。在编写策略包时,要清晰的知道这一个策略,是将案件从案件池分到队列(队列可以包含虚拟队列或者所谓的’场景’),还是从队列分到个人;要做到金字塔原理中的MECE规则,即全覆盖和不交叉。如果你所编写的策略,队列混乱且交叉。只能祝你之后查错的时候好运,希望接手你工作的人不是200斤带金链子的我。
三、一个策略方的产品经理,日常应该更关心什么
抛开DRL文件,抛开测试类,抛开标签,抛开赋值语句。窃以为,对一个策略部门的决策引擎产品经理来说,以下的内容才是更应该花时间去考虑的:
1. 清晰、流畅、兼顾各方、高内聚低耦合的决策流
作为一个BRMS工具,某种意义而言,整个系统,都是为了更好地实现业务的决策流。但常规存在的问题是,对于业务而言,每一个部门、小组,对于客户资源分配,都有自己的一些考虑,任何系统方面的偏差几乎必然成为业务与产品之间龃龉的理由。
第二个方面,画在XIMND上的决策树,在DroolsWorkBench中,因为性能、规则编辑方式、甚至因为其他组件不全、甚至因为技术提供的Drools版本太老的问题,难以实现。甚至需要人肉去划分两个进程、决策表来处理同一个问题。此操作是反奥卡姆剃刀原则的。每多一个环节,就会多一分出错的可能性。
因此,策略部门的决策引擎产品经理,在编写DRL文件之前,最需要做的,是了解并排查当前决策流中的问题。大概率,当新增一个决策引擎,或者更换一个决策引擎时,当前日常决策流程中,是存在各种各样的问题的。在梳理过程中发现的各个组之间的客户冲突,请直接暴露给决策层,避免造成后续的问题。
再具体梳理决策流时,请注意各个层级之间的内聚及不同层级之间的耦合,尽管产品经理并没有在具体写实施代码(其实决策引擎除了初期开发外,DRL文件修改也主要是产品运营去写。),但是这个原则一定会在之后方便复盘、修改等等。
应当尊重现有工作流,并尝试改变不合理的工作流,而不是一味服从:在编写DRL文件,或者调整决策引擎时,决策引擎的产品经理,是比其他任何人更能发现现有的决策流、工作流的问题的。可能是重复判断、可能是队列交叉,可能就是两个判断流之间有空隙等等。
可以尊重现有的工作流,但也请在有余力的时候,进一步清晰化决策流;否则屎山代码的积累,会变成一个击鼓传花的游戏,问题总会在一个人手上爆炸,你无法知道自己不是那个倒霉蛋。
2. 注意与其他系统之间的交互和协同
抛开机械化地看待系统、看待工作;深觉得任何一个策略人员、数据分析人员、或者产品经理,都应该确实的理解一个问题,任何业务,尤其是一线作业人员较多的业务,系统之间的衔接和补充,甚至是比有多少个系统更重要的问题。重复造轮子拓展自己权限边界当我没说。
根据经验,会与决策引擎会产生交互的系统有:
前端展示即作业系统、标签集市或数据管理系统、配置管理系统、(有可能)大数据平台、(有可能)智能外呼机器人等,当然,还有最主要的系统,人。
因此,出于解决生产问题考虑,会有如下一些问题需要考虑:
决策引擎的日志需要保留到怎么样的一种程度,或者日常作业的数据可以仅保留在作业系统的数据库中;如何减少代码的使用量地,可扩展地与标签集市发生交互;当计算资源不足时,如何妥善的分解决策流,更高效地使用计算资源等等。甚至,需要考虑,如何编写完善的文档,当一线作业人员对自己手里的案件有疑问时,可以妥善的处理疑问。
3. 成本、效率
当所使用的数据有外部引入的数据时,或在整个体系中需要使用收费的外部服务时,就会明确牵扯到成本的管控问题。即使是仅出于自己安全考虑,也应当注意到每一笔调用的费用带来了什么。成本是否可控,是否有足够的性价比。
四、我所建议的学习路径
基于之前的不堪回首的经历,如果你是一个新人的策略部门的决策引擎管理员,建议采用以下的流程去学习熟悉(仅针对非可视化非商业化的产品):
- LESSON1:JAVA基础了解。如果之前对于代码,仅有谭浩强C语言级别的了解。甚至C语言课程都没有看过,建议花1天时间,稍微了解一下类、变量、继承的概念。
- LESSON2: DROOLS基础了解。DROOLS WORKBENCH尽管是基于JAVA的产品,但其核心概念KIE结构毕竟是单独的一个内容。建议花1天时间,了解KIE结构,了解SESSION、容器、类的感念。
- LESSON3:决策流梳理。类似于上述的内容,请酌情花一段时间,去了解各个组之间的决策流,了解不同组别对客户的需求、或者队列的差异。并根据实际情况,生成自己的构想。
- LESSON4:自己动手去做测试。不论DRL构想有多优秀,除非使用ECLIPSE或者其他IDLE,在本地对自己的DRL文件进行测试,不然很难认知到自己的设想的错误。请在任何版本更迭之前,做好测试及确认工作。
五、最后的碎碎念
不得不说,决策引擎的产品运营,相对于其他系统来说,考虑到其对生产的巨大影响,及与其他诸多系统的交互,及产品经理与诸多组别的交互,是非常考验人耐心及细心的系统。另外,不论是运维的问题或者是系统的宕机,又或者是策略的翻来覆去,甚至是前人留下的屎山代码都会造成可能的生产事故。不了解情况的人,会认为均是你的问题。因此,建议有选择的时候,慎重选择决策引擎的产品运营角色。
此外,不得不说,决策引擎运营的久了,整个思路确实也更加相信控制论,这可能是管理决策引擎带来的思路上面的改变。
祝愿所有管理决策引擎的倒霉蛋少掉点头发。
本文由 @肥柴周 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









您好,可以加V交流吗?