
 起点课堂会员权益
起点课堂会员权益关于流量分析体系的那点事
编辑导语:大家是否知道,什么是流量数据?为什么要做流量数据分析体系?又该怎样做流量数据分析体系呢?本文作者围绕这三个问题,为我们做出了详细地解答,让你知道关于流量分析体系的那点事。

1. 什么是流量数据
流量数据主要以用户访问产品/页面时,从启动到使用产品等一系列的过程都会产生许多流量数据。流量数据定义为用户访问产品时/页面时产生的数据,需要企业通过数据采集来获取数据。
2. 为什么要做流量数据分析体系
当前市面上居高不下的获客成本,对于新用户,可能仅打开一次app就流失。监测流量数据,诊断数据异常,改善业务逻辑,促进产品收益。
3. 怎样做流量数据分析体系
用户访问产品/页面时,从启动到使用产品等一系列的过程都会产生许多流量数据。流量数据大 都通过埋点上报产生,通过数据处理与加工形成质量高、易于分析的数据资产,经过数据分析为决策提供数据支持与洞见。
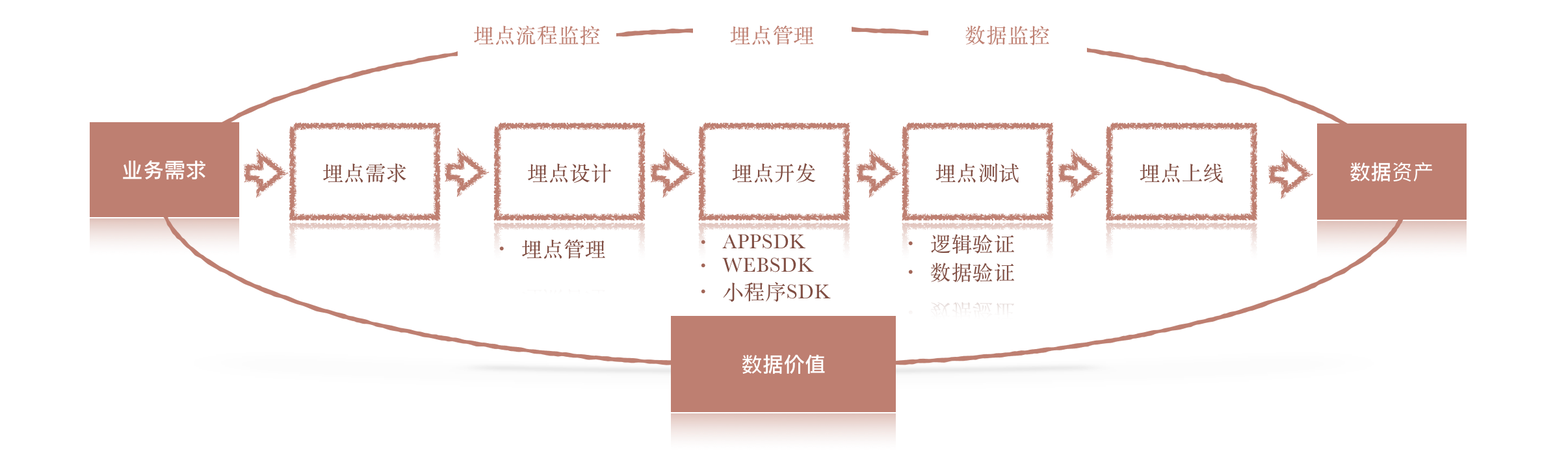
3.1 数据生产
3.1.1 业务需求——埋点数据需求
组里的DA同学收到的业务诉求常常是“期望能这个功能的使用情况”等,而此时如果仅给出一个功能使用uv、pv,是不够的,需要全方面的了解业务诉求,并将其抽象为埋点需求。
面对“期望能这个功能的使用情况”业务需求时,需要了解:
- 业务的短、中、长期战略,e.g.中长期战略为用户下沉;
- 为什么上线这个功能;
- 这个功能可能会影响其他功能。
了解后,根据业务背景、需求、目的,将其抽象为“埋点需求”。
- 业务的短、中、长期战略,e.g.中长期战略为用户下沉,用户下沉使用城市等级、收入金额等来划分;
- 为什么上线这个功能:了解到是为了提高用户粘度,需要监测使用该功能的用户留存、活跃天数。并通过对比分析得到与其他功能的差异表现;
- 这个功能可能会影响其他功能: 获得与该功能可能相斥的功能点,监测数据表现,避免“业务预期外”的侵蚀现象;获取期望相辅的功能点,监测数据表现,避免“出乎意料”。
3.1.2 埋点设计
设计埋点需求前,需要了解下事件模型(who、when、where、how、what),基于事件模型全方面的刻画埋点。
3.1.2.1 埋点要素
WHO:
即谁参与了这个事件,唯一标识(设备/用户id),可以是匿名的设备id(idfa\idfv\android_id\imei\cookie)、也可以是后台生成的账户id(user_id,uid)、也可以是其他【唯一标识】。
现在很多公司都有自己的唯一设备id(基于某个策略产生的唯一标识),e.g.阿里有OneId。埋点时,该参数通常使用 业务所用的唯一id;在埋点设计文档中,如果没有特殊处理,无需特别声明。
WHEN:
即这个事件发生的实际时间。
该时间点尽可能精确,有利于行为路径分析行为排序,像神策会精确到毫秒。如果公司内已有数据统计sdk且该埋点使用,则无需特别说明。
WHERE:
即事件发生的地点。
可以通过ip地址解析国家、省份、城市;如果期望更细致的数据,如果住宅、商业区等,需要额外地理信息数据库来做匹配。地点信息和时间信息一样,是每一个行为事件都需要上报的信息,基本上会是统计sdk的预设字段,也无需特别说明。
HOW:
即用户用某种方式做了这个事件,也可以理解为事件发生时的状态。
这个包括的就比较多,可以是进入的渠道、跳转进来的上级页面、网络状态(wifi\4g\3g)、摄像头信息、屏幕信息(长x宽)等。
而如使用的浏览器/使用的App,版本、操作系统类型、操作系统版本、进入的渠道等 经常设置为“预设字段”,也无需特别说明。
WHAT:
即用户做了什么,结合用户行为/操作以及业务所需的数据粒度,需要通过埋点尽可能详细的描述清楚行为,也是埋点设计文档最为重要的部分。
如搜索(搜索关键字、搜索类型)、观看(观看类型、观看时长/进度、观看对象(视频id))、购买(商品名称、商品类型、购买数量、购买金额、 付款方式)等等。
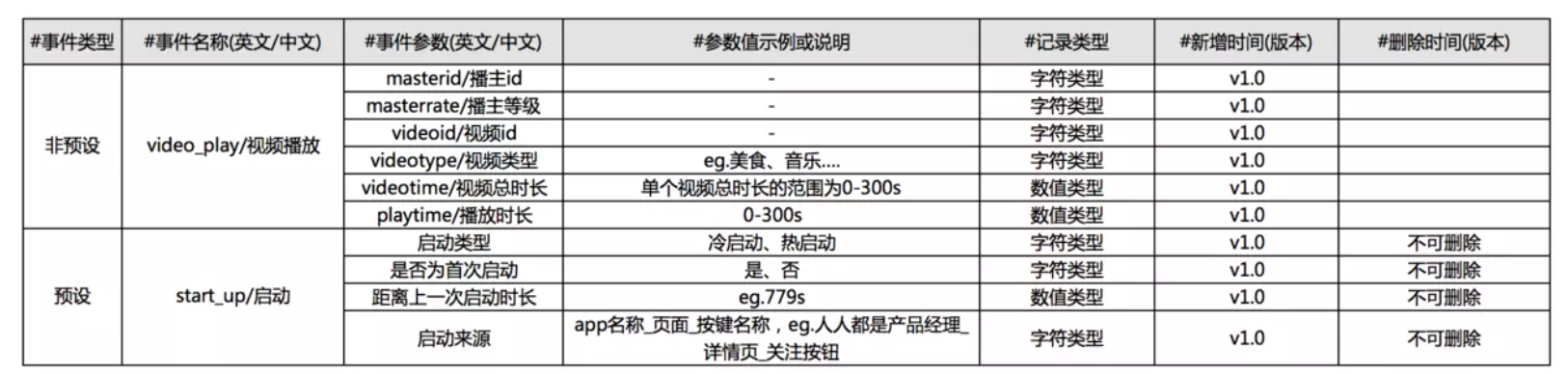
3.2.2.2 埋点示例
以“启动”事件、“播放”事件为例,设计埋点。
3.1.3 埋点开发
埋点在形式上,支持代码埋点、可视化埋点、全埋点。代码埋点时,可以客户端埋点,也可以服务端埋点;统计SDK,APPSDK、webSDK、小程序SDK、H5SDK等。
可视化埋点、全埋点背后对应的是统计SDK针对“某些事件”的自动上报,埋点开发相关知识点可以查看历史文章。
统计SDK是埋点开发提效的工具,填写需要上报的参数即可,统计SDK的格式大都基于事件模型,较为通用的事件模型可以参考神策分析。
3.1.4 埋点测试验收
埋点测试验收,需要从逻辑、数据 两方面测试验收,以确保埋点的正确性、顺序性、完整性。
- 正确性:确认数据是否上发,并检查上方数据内容格式是否与需求文档一致;
- 顺序性:数据上报的顺序正确,间接性验证埋点代码的正确性;
- 完整性:针对各场景均需要测试,确保不同来源、不同场景下均有数据上报。
埋点平台通常均有针对性测试的模块,像umeng可以注册测试设备后,查看埋点的测试数据,埋点上线后也需要进一步观察数据是否有异常。
3.2 流量数据的加工
3.2.1 数据质量的保障
经过数据处理的埋点数据,需要保障 完整性、准确性、一致性、及时性。
- 完整性:完整性是指数据的记录和信息是否完整,是否存在数据缺失情况,是数据质量最基础的保障;
- 准确性:指数据中记录的信息和数据是否准确、是否存在异常或者错误的信息;
- 一致性:指在多处数据记录中,数据一致;
- 及时性:保障数据的及时产出才能体现数据的价值。
3.2.2 数据模型
有了埋点数据,通过数据处理,该过程就不详细讲了。
数据标准化后,通常会存在于三张表:事件表;用户属性表;目标对象表(三张表仅是按照使用表的目的而言,为了提高查询效率等,通常会将三张表按照事件过程再拆分)。
基于这三张表的查询模型,将可以支持一般数据量级的各种分析模型,超大数据量下查询速度会降低,如需提高查询速度,则需要通过存储换查询,例如将高频查询结果进行缓存、设置数据加速等。
- 事件表:每条记录描述一个用户在某个时间点、某个地方、以某种方式完成某个具体的事件;
- 用户属性表:主体为用户,每一个用户有一条记录,属性包括了用户属性(包括平台、网络、服务商、手机型号、地域等等自然属性;也包括用户等级、是否为大V等非自然属性),通过用户可以关联到事件表分析。
- 目标对象表:主体为目标对象,目标对象通常是一个业务的主要载体,比如短视频APP,目标对象为视频(id),通过目标对象可以关联事件表分析。
3.3 流量数据的应用
3.3.1 常用流量分析
3.3.1.1 事件分析
事件分析法常用语研究某行为事件的发生 对产品价值的影响以及影响程度,通过研究与事件相关的所有因素来分析用户行为事件变化的原因。
在日常工作中,运营、市场、产品、数据分析师等不同角色的业务同学,常常根据实际工作情况关注不同的事件、以及事件对应的指标。
例如:上周来自北京的用户拍摄视频的去重用户数是多少?
事件分析是围绕事件表而来的。描述的是一个用户在某个时间点、某个地方、以某种方式完成某个具体的事件。
3.3.1.2 漏斗分析
漏斗分析重在过程,现代营销观念也认为控制了过程就控制了结果。漏斗分析是流程分析,它能够反应从起点至终点各阶段用户转化情况。
狭义上是以用户为单位将步骤串联起来,进入后续步骤的用户,一定是完成了该漏斗前序步骤。广义上的漏斗分析,仅仅是用漏斗这种形态来描述,即将液体从大口导入,从小口漏出。
例如一款游戏产品 用户从激活到购买皮肤:激活app、注册账号、进入游戏、玩游戏、购买皮肤。
漏斗分析应用:
(1)全流程监控转化过程:对于业务流程相对规范、周期较长、环节较多的流程分析,能够直观地发现问题。
多维度切分找到低转化的问题点——这里以广告的点击,因而关注“广告的曝光->点击”的漏斗分析。
(2)通过对比不同渠道的该漏斗过程,可以找到最佳投放广告的渠道:如下图展示可以看到baidu的总体转化率高于全部 6个点,明显优质。当然实际的场景中,还需要结合更多的价值衡量标准来筛选优质渠道。
(3)对比分析不同用户群体的漏斗,从差异角度找优化点。这里以新增用户的关键行为转化过程为例,通过漏斗分析找到用户群体的差异性,再根据差异性做更细粒度的引导。
关键行为的转化漏斗如下“启动app->登录->进入直播间->直播互动->送礼物”,通过对比查看不同国家,发现中国与总体在后两个转化中差异大于1%,尤其是在进入直播间->直播互动,当然差异的背后还可以进一步的洞察,更好的利用这个差异点。
3.3.1.3 留存分析
留存分析是一种用来分析用户参与情况的分析模型,考察进行初始行为的用户中有多少人会进行后续行为,能有效衡量产品对用户价值。
通过留存分析,延长用户的生命周期,增加每一个用户生命周期价值。针对新用户,可以描述出由不文明的那个的用户转化为活跃用户、稳定用户、忠诚用户的过程。
留存分析可以:
(1)了解新用户的同期群
上周上线了新版本,目的是提升新用户留存,通过对比上线前的同期群留存表现,发现新版本没有明显变好。
(2)找到目标用户
长期留存的用户是忠实度较高的用户,反过来可以结合用户属性分析得到“什么样”的用户,自身留存较好。
(3)找到用户视角的产品核心价值
同一批用户,通过什么样的行为后,留存提升了。
留存分析在衡量用户粘度的时候,还需要结合用户访问天数(一定周期内),留存相同的工具型、内容型产品,通常工具型的用户访问天数低于内容型的。
3.3.1.4 路径分析
app日志按照用户的使用过程、使用频率,可以呈现出“明确的”用户现存路径。通过路径的指标表现,发现路径问题,使用户尽可能短路径体验到产品核心价值。
路径分析可以:
(1)在路径分析中,常常会发现产品/运营设计之外的使用路径,尤其是发生在大型产品上。产品、运营均清楚自己负责的模块,与其他模块的配合协作过程较模糊,甚至不清晰。
此时的第一反应是“用户的真实操作是这样么?怎么会,超出了我当前自己产品的认知”。基于事件的事序数据展示,将能够解决这个问题。
(2)多维度切分找到关键路径上的用户群体:如上发生A->B路径的用户有谁?他们在对应时间点是如何使用产品的,是在怎样的网络条件下?
(3)此外,路径分析还可以用来展示用户流向,操作A行为的用户中有多少流失了,又有多少操作了其他行为,其他行为的占比达致为多少?
3.3.2 报表
流量数据多以报表形式展示。清晰的展示展示关键数据,完整的描述数据故事,往往对看板制作有较高要求。
流量数据具有标准的数据结构,这有助于提高流量数据看板制作的效率——通过沉淀常用数据数据分析模型的图表,快速形成看板。
3.3.3 行为标签
行为标签数据是用户画像、用户分群的基础数据,而流量数据是行为标签的主要数据来源。行为标签由于处理方式不同,分为以下几种:
- 事实标签:通常也称为规则标签,是基于用户行为数据和规则产生的标签,e.g. 无效用户—“APP启动后没有使用核心功能”;新增用户—“7日内的新增”;
- 模型标签:是通过数据模型得到的标签,e.g. 消费能力高;
- 预测标签:和模型标签一样,也是通过模型得到,但不同的是预测标签是对未来的预估,e.g. 潜在流失用户。
本文由 @cecil 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









产品l
现在收集用户数据的工具 有多少是自己企业创建,多数是依靠第三方工具