
 起点课堂会员权益
起点课堂会员权益项目复盘:如何避开从0~1构建AB Test过程中的坑(上)
编辑导语:ABTest,简单来说,就是为同一个产品目标制定两个方案,通过日志记录用户的使用情况,通过结构化的日志数据分析相关指标,从而得出更符合预期设计目标的方案,最终将全部流量切换至符合目标的方案。本文作者通过自己的经验,分享给我们应该如何避开从0~1构建AB Test过程中的坑。

最近设计完成了一个用于信息投放的ABTest功能,正好总结梳理下,避免大家踩坑。
AB实验大家都听过,互联网公司里更常见,开始讲内容之前通俗的介绍下AB概念:你在做产品规划设计时,想出了一个改版方案(姑且称为版本B),但不确定这个改进的效果是否比老版本(称为版本A)效果好。
于是想对比下这两版本的效果,所以你把用户群体(假设100人),其中10%的流量分配给B方案,90%的流量分配给A方案,持续一周后,查看数据;如果版本B效果比版本A好,那就准备全部上线,如果版本B效果不好,那就下线或重新做实验。
(手绘人群分流示意,请谅解)
故事讲完了,可能很多人觉得很简单,不就是之前学的生物化学里的单一变量嘛,如果这样想,那么你的AB实验应该是做错了。
一、AB实验中的典型问题
先看下AB里的几个核心问题:
- 怎么划分人群,是随机划分还是依照什么规则确保人群划分的合理?(AB实验里的分流逻辑);
- 实验结果出来了,我怎么判断这个结果可信不可信(AB实验里的显著性差异);
- 实验结果出来了,实验组数据好,我怎么判断是不是真的好(AB实验里的第一类错误);
- 实验结果出来了,实验组数据差,我怎么判断是不是真的差(AB实验里的第二类错误);
- 实验结果出来了,好多个维度数据,我怎么衡量实验结果(AB实验里的衡量指标);
- 实验结果出来了,但是一组AB实验我总觉得不靠谱(AB实验的AB组,称为AA组以及AABB组)。
解决上面6个问题,就从逻辑上完成了AB实验方案的规划,剩下的就是产品设计了。
二、如何合理的划分人群
1. 什么是人群划分(分流)
这个问题是AB实验里最关键的分流逻辑。
AB实验最关键的是保证变量,是的,这一点和生物化学里的单一变量法一样了,除了你产品要实验的点不同外,其实人群也要保证一样,这个一样不是说流量或比例一样,而是人群特质一样。
举个例子:BB霜厂家做总人数1200人的AB实验,1号BB霜投放给了一波600人的女生群体(即人群A分流50%),2号BB霜投放给了另一波600人男生群体(即人群B分流50%),流量划分一致,实验结果发现人群A的接受度很高,结论:1号BB霜更受市场欢迎!
这个结论可信么,不可信,因为本身人群特质就不一样,这里和流量1:1没关系,流量的比例多少不会影响AB实验结果,男生拿到BB霜接受度肯定不高(莫要牛角尖,说男生拿到送女朋友之类云云),这个例子说明的是人群特质对实验结果的影响。
2. 如何进行人群划分(分流)
首先我们公司是内部有专门的人群分流系统,主要默认的分流算法是uid+hash因子 计算md5取模,根据结果判断是落在哪个实验分桶里,该系统可以直接对接使用,所以此处不赘述。
本次主要讲下对于没有科学分流系统的公司如何处理?
采用算法或规则分流,算法分流也分为在线分流和离线分流。在线分流是指根据当前线上目前的实时特征进行划分,结果更加精确;离线分流是指根据T+1或T+N(具体N根据不同公司不同业务来确定)的特征进行划分。条件允许情况下,推荐前者。
核心思路主要是拿到用户的唯一标识,对用户的唯一标识进行杂散后重新分配。
不同产品唯一标识不同,但一般都有用户Uid,简单方式可以用规则对uid采取奇偶数划分;另外一种引入算法,如Hash算法(一般翻译为散列、杂凑或音译为哈希,其输出是散列值),对uid进行哈希处理。处理后根据业务要求,加入分桶逻辑,判断具体的uid落在哪个分桶内,完成科学分流。
3. 如何设计人群划分(分流)
分流的本质是分桶,划分到不同桶内。所以实现逻辑上明确后,产品设计上其实很简答,参考思路如下:
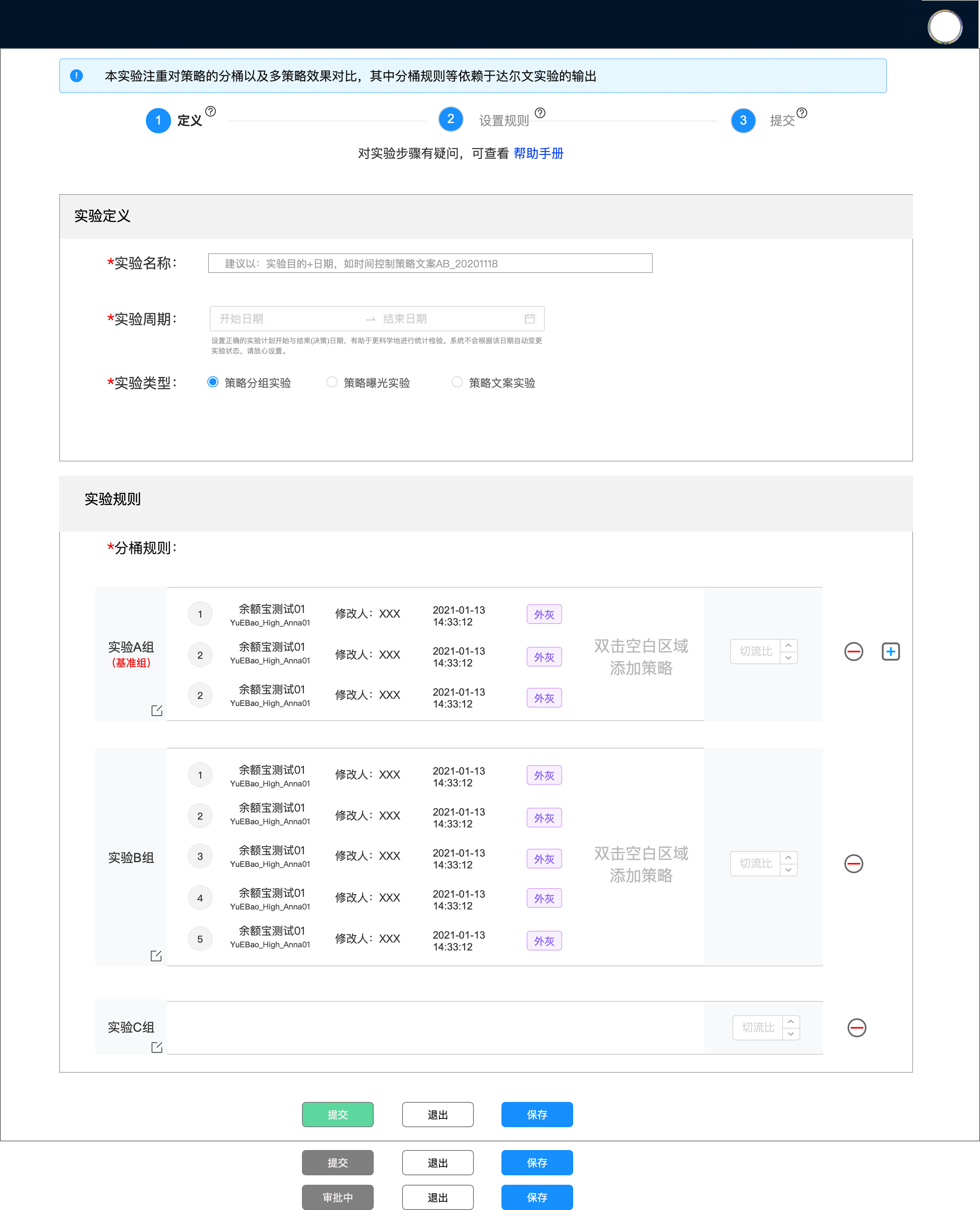
(axure草稿版交互,人群分桶示意,参考看就好)
三、如何判断结果是否可信
1. 结果差异是不是明显(显著性检验)
判断实验是否可信就是AB实验里的显著性检验,由于AB实验对用户进行了分流、抽样,不同实验组之间的差异本身就存在随机性。
所以存在一个显而易见的问题,实验的结果是随机波动导致的还是真实可信的差异?检验差异的统计显著性就是帮助我们判断这个差异是真实的效果,还是仅仅是由于分流抽样带来的随机的差异。
之前听韩瞳大佬的课程时,了解到一个抛硬币的例子,浅显易懂,借由该例子解释下:想验证一个硬币有没有被动了手脚,应该怎么做?
- 无限次抛掷,然后记录正反面数据,看下正反面比例;
- 这件事前提是大家均知道,正反面的概率分别是50%。
在证明之前,统计学上有个概念原假设和备择假设,原假设即想要证明的假设,备择假设即不想证明的假设。所以在这个例子里,我们做如下假设:
- 原假设:硬币没有被动手脚
- 备择假设:硬币被动了手脚
那么假设硬币的数据如下:

你是不是觉得结果不好判断,或者自己心里的判断很主观,到底偏移多少算正常的,偏移多少算不正常的?这就是显著性检验要解决的。
再给出答案之前,还需要知道AB实验里的四种数据情况:

表格中的两个错误是什么情况下发生的呢?
第一类错误:也就是比如抛掷1000次,600次正面,400次反面,数据看起来不正常,但是实际上是统计学里正常的情况,如果继续抛掷1000次,可能就是510正面,490反面了,也就是之前的抛掷恰好处于自然波动范围内了;
第二类错误:也就是比如抛掷10次,5次正面,5次反面,数据看起来正常,但是实际上统计学里已经不正常了,如果继续抛掷1000次,可能这个硬币就变成800正面,200反面了,也就是说由于抛掷次数过少导致的。
讲到这里,就是显著性检验的作用了,用于判断到底是否是正常的波动。
- 如何评估是否出现了第一类错误:采用P值
- 如何评估是否出现了第二类错误:采用Power值
2. 怎么判断结果是否明显(检验方法)
1)先来解决第一类错误
这里非统计学概率学伙伴要问,什么是P值,那么来解释下。AB实验的基础是统计学里的假设检验里的知识,核心思路如下:
- 当样本量足够大足够多时,把实验对象分为两组,如A组和B组。由于数量够多够大,理论上可以认为AB两组的样本特质一样,即样本无差别;
- AB两组投放同一个产品,对B组投放的产品做了改动,A组无改动(统计上称B组为实验组,A组为对照组);
- 假设该改动没有影响(统计学上称之为“原假设”:即最初的假设条件);
- 假设该改动有影响(统计学上称之为“备择假设”:即原假设的对立假设,包含一切使原假设不成立的命题);
- 观察B组的实验数据,在统计学和概率学的计算下,原假设成立的前提下,判断B组数据出现的概率。根据这个概率是否处于置信区间范围内来判断,原假设是真还是假。
(手绘p值示意,请谅解)
如图,在统计学上,参考原假设来判断其出现概率称之为P-Value,即p值。
P值指的是比较的两者的差别是由机遇所导致的可能性大小。P值越小,越有理由认为对比事物间存在差异。一般统计学认为,P>0.05称“不显著”;P<=0.05称“显著”,P<=0.01称“非常显著”。
P<0.05,就是说结果显示的差别是由机遇所致的可能性不足5%,或者说,别人在同样的条件下重复同样的研究,得出相反结论的可能性不足5%。
但是很多AB实验里容易搞混一个词,因为AB实验里经常用“显著”来描述,所以容易出现“差异具有显著性”和“具有显著差异”两个词混用,其实二者意义不同。
前者是指其p<=0.05,即可以相信两个事物完全相同的概率还不到5%,因此可以认为两个事物确实存在差异,这个结论如果是错的,错误的概率≤5%。
后者是指两个事物的差别确实是比较大的,如苹果和西红柿差别很大,因此可以认为“有显著差异”,但小苹果和大苹果差别不是特别大,但如果AB实验统计学上的p值≤0.05,可以认为两者“差别有显著性”,但不能认为是“有显著差异”。
好了,这里解释了p值以及在判断p值过程中的两类错误。综上,所以判断实验结果是否可信的可以通过判断P值来判断。
2)再来解决第二类错误
什么是power值,那么来解释下:接上面的硬币实验,也就是硬币的数据看起来正常(也就是数据好像符合原假设),但是结果确是硬币实际上不正常,我们犯这个错误的概率,称之为二类错误概率值,而power值即称为统计功效,也就是不犯这个错误的概率。
一般情况下,power值在80%或90%以上,认为是可信的,可以接受的。
四、其他衡量方法
听完后是不是觉得AB没有那么简单了,别担心,上面的逻辑研发会从代码层面搞定或Python里有现成的函数,产品经理梳理好逻辑就行。
另外还需要额外说明下,AB实验的衡量方式还有“通过样本估计整体”、“置信区间”两种方法,不过多阐述,感兴趣的可以自己百度下,效果殊途同归。
好了,这次就先到这,由于太耗时,下次在写一篇AB Test(下)讲解下AB的衡量指标以及AA组、AABB组的问题。
作者:楠神,公众号《音波楠神》
本文由 @楠神 原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自 Unsplash,基于 CC0 协议










写的非常棒,点个赞,有个问题想请教,既然有了AA试验,还有必要做显著性验证么? 如果要对A/B test的记过做显著性验证,是否是通过A(A1、A2、A3、A4)& B(B1、B2、B3、B4)来求P值的方式作为判断标准,如果没有显著性差异,是否可以认为是测试项没有统计学上的差异,需要引入新的具有显著差异测试项?(但对于只需要对有限方案做出最优选择的测试目的来说,AB等效,即随便选一个就行,判断其差异是否有意义)。
多谢认可,针对你的疑问有几点解释如下
1、AA实验的目的是为了验证AB中无法区分的是否是随机波动导致的问题,AB实验中的P值指的是比较的两者的差别是由机遇所导致的可能性大小,所以理论上P值也只是从概率学的角度给出的建议值,当然如果P值很小,基本上大概率认为是显著性差异导致而不是随机波动,但,也只是大概率而已
2、P值一般只是用来验证AB实验中的第一类错误,即α错误,你如果想验证AB到底有没有问题,你是不是需要继续验证β错误,即第二类错误,一般用power值验证,也是概率层面的。所以可以看到,AB实验结果出来后,你需要数据分析来不断验证和校验你的结果看看对不对
3、AA是纯对照组,脱离概率角度,从生物学的单一变量的角度来辅助你验证AB实验的正确性
4、P值计算方法网上有很多,你也可以直接用Python中的现成的模块计算
明白了,显著性检验检目的是为了验证 此次A/B实验是否是因为随机因素影响而造成的实验结果,确保实验的有效性;AA实验是为了尽可能的消除这种随机因素,确保单一变量的有效性。
是的。这里不方便直接贴微信,你可以先关注我的公众号 后台回我
好嘞
能否加个微信,以后能多请教。
很强,增长、策略产品运营必学知识点。
我有个疑问,应该是备择假设是想要证明的假设吧
对的,标准理论上是的。由于备择假设是研究者希望通过收集证据予以支持的假设,一般情况下,建立假设时,先建立备择假设在确定原假设。自己比较熟悉的情况下,自己能区分开就行。不过还是多谢你的严谨