
 起点课堂会员权益
起点课堂会员权益广告策略产品(3):推荐系统的排序策略那些事儿
推荐策略是每个产品都会涉及到的问题,是根据时间顺序推荐还是根据一定的比重推荐,这关乎着流量分配和用户留存。本文作者对推荐系统的排序策略进行分析,与你分享。

Hi 我是策略产品经理Arthur,上一篇文章给大家分享广告eCPM最大化期望收益建模核心问题之一的广告竞价问题,今天给大家继续分享一下另一个问题:预估排序问题。
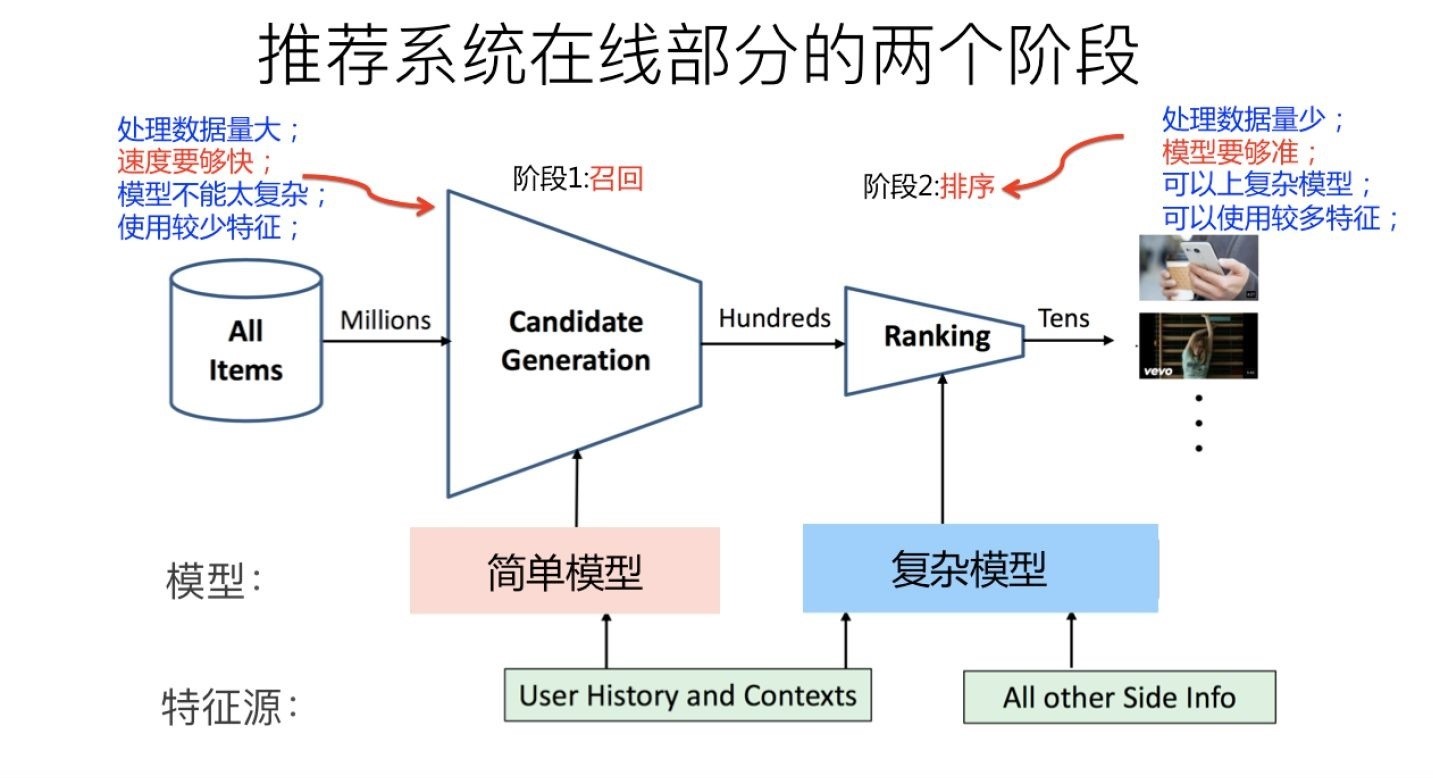
排序是评估一个无论自然推荐还是推荐系统都会涉及的问题,基于用户兴趣推荐展示内容准不准的关键模块,在这里顺带提一下,从召回到粗排到精排再到重排序的整个链路搭建,一般大型的头部互联网公司,因为item物料的丰富与推荐内容多样性的高要求,所以需要将每个步骤都搭建完善。
但是对于某些物料item整体偏少,例如某些线上中小学课程教育推荐系统,总体课程item数量也就不到100的话,那么连召回链路都不需要搭建,只需要简单的搭建一个排序系统即可,因此需要基于业务考量来做系统搭建。
我们这里的分享会介绍完整的系统搭建,下面的排序都以小红书推荐。
今天我们先来介绍粗排,主要分成几个部分来介绍:
- 排序是什么&有哪几种排序方式
- 排序的目标与评估标准
- 排序的主流策略&方法枚举介绍;
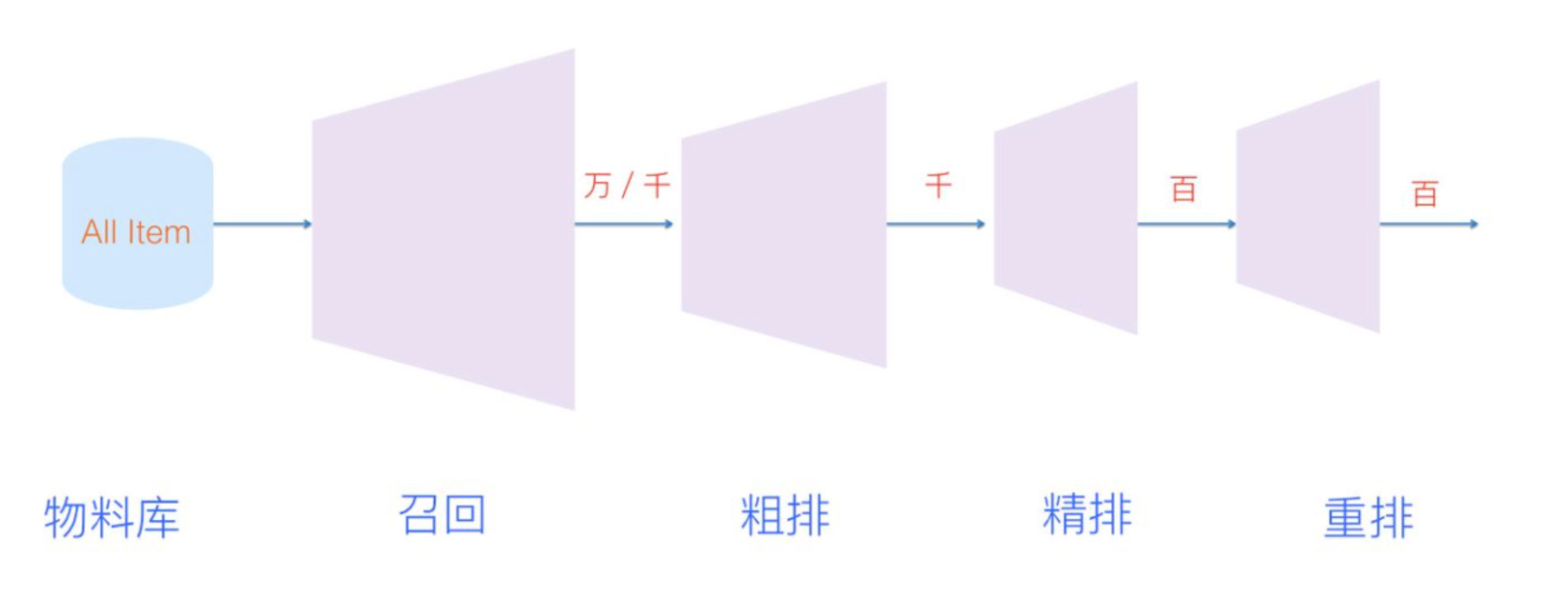
一、排序是什么&排序模块分类
前文也提到了排序相较于召回要处理的物料item更精炼精准,模型的选择更加复杂,使用的特征也更加丰富,相较于召回数以十万甚至百万量级的物料到排序阶段可能已经只剩下数千到数百的水准;排序模块的作用就是从很多候选的item中挑出最好的一个或者多个进入到展示逻辑中。
排序主要包含粗排、精排以及重排序三种排序方式。
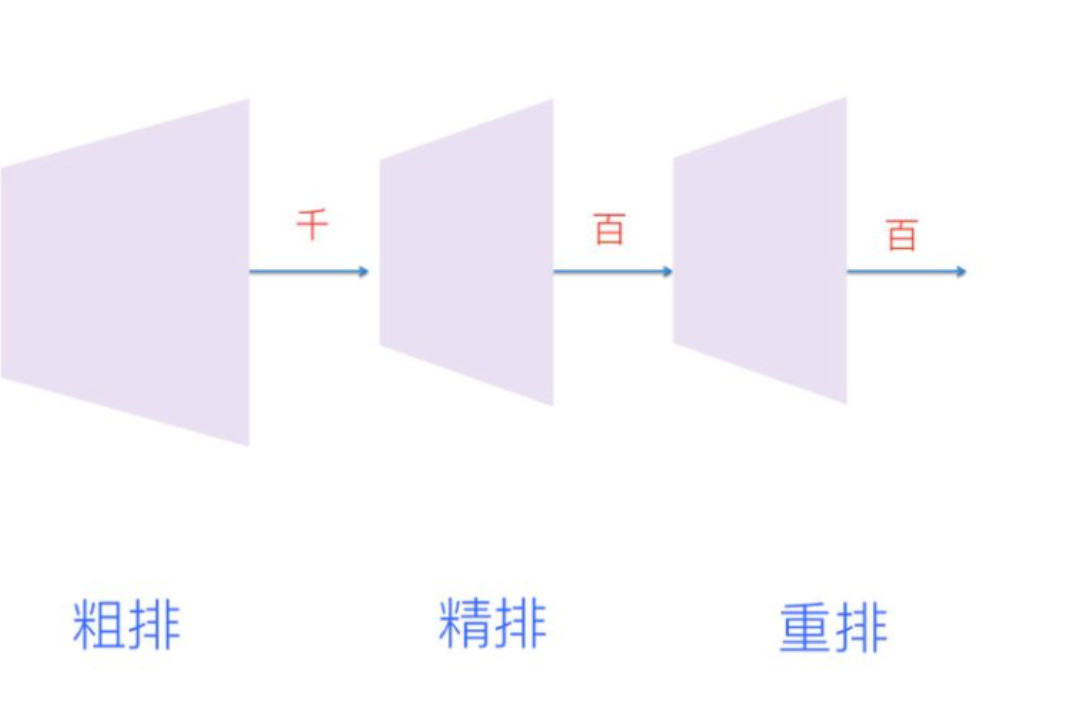
粗排(Pre-rank):粗排其实在排序链路中是一个比较尴尬的定位,在绝大多数的场景下粗排其实类似于召回巨大量级item与精排之间的item过滤器,类似精排的影子,其使用的模型复杂度一般会类似精排或者弱于精排,绝大多数使用离线简单的特征数据(例如离线客户画像、行为等),给精排输出精炼的物料内容预估简单的点击率CTR,降低精排直接对上万物料处理的系统算力问题+耗时问题;
精排(Rank):最纯粹的机器学习排序模块,目标只有一个根据所有的信息(最复杂的排序分类模型+实时在线行为而数据+离线特征)输出最终准确的CTR预测排序item(在广告场景下就是eCPM的排序,即bid*pCTR*1000), 预测的小红书笔记/视频被点击的结果“精炼”,准确度也明显高于粗排;
重排序(Re-Rank): 重排序的作用其实是帮助排序从纯粹的“单点最优”往“全局最优”做迈进,在精排考虑的小红书笔记并未考虑到context上下文之间的关系,比如用户喜欢看美食笔记,整体排序预估下来会给客户推荐满屏的都是图片类似的笔记,这样体验非常不好,因此为了保证在一个推荐队列中的笔记新颖性和多样性,会在重排序做各种考虑上下文Context的过滤,在不尽量不破坏精排final_score的基础上做局部重构,保证全局最优;
二、排序的目标与评估标准
前面举了一个例子,如果小红书笔记推荐核心优化指标如果是CTR(点击率,为了方便理解我们先构建单一目标优化,多目标一般还会包含人均曝光笔记数、笔记互动等),那么核心排序的方式就是对于点击率CTR的预估,按照最终预估pCTR_Score的情况进行排序。
1. 排序学习的目标:后验CTR
精排学习的目标的范围一般是所有存在曝光的样本。有曝光但没有点击的是负样本,有曝光也有点击的就是正样本。在其他目标中可以以此类推:比如转化率(CVR)预估,点击了没转化的是负样本,点击了,也转化了就是正样本。
2. 排序所依赖的特征工程
特征所做的事儿其实就是讲推荐系统中达成学习目标效果的特征内容,特征工作的基本思路是,先通过人工预判有效特征->离线评估重要度和覆盖率->训练模型离线评估->在线实验。总的来说在比较低的层面,充斥着大量的数据清洗、处理或者归一化等,并且实现ETL(Extraction-Transformation-Loading),推荐系统当中的特征选取是一件非常重要的事情。
例如,如果希望整个小红书推荐系统笔记点击率较高,推荐美食和旅游,选取用户侧特征就更多侧重用户的购买力、饮食偏好、地域、考虑笔记特征的时候就需要看文章context内容,位置、价格等,特征工程整体是一件收益较高的事儿,但是一般需要有经验丰富的专业人士人工前置预判有效特征。
3. 排序的评估指标:AUC
排序可归类为一个二分类问题,其核心要解决的就是小红书笔记曝光后是否点击的问题,即“曝光点击与曝光未点击”,可以通过二分类问题的混淆矩阵(内容偏多,如果点赞收藏超过100,后续单独输出笔记介绍),通过来对预估模型效果进行评估。
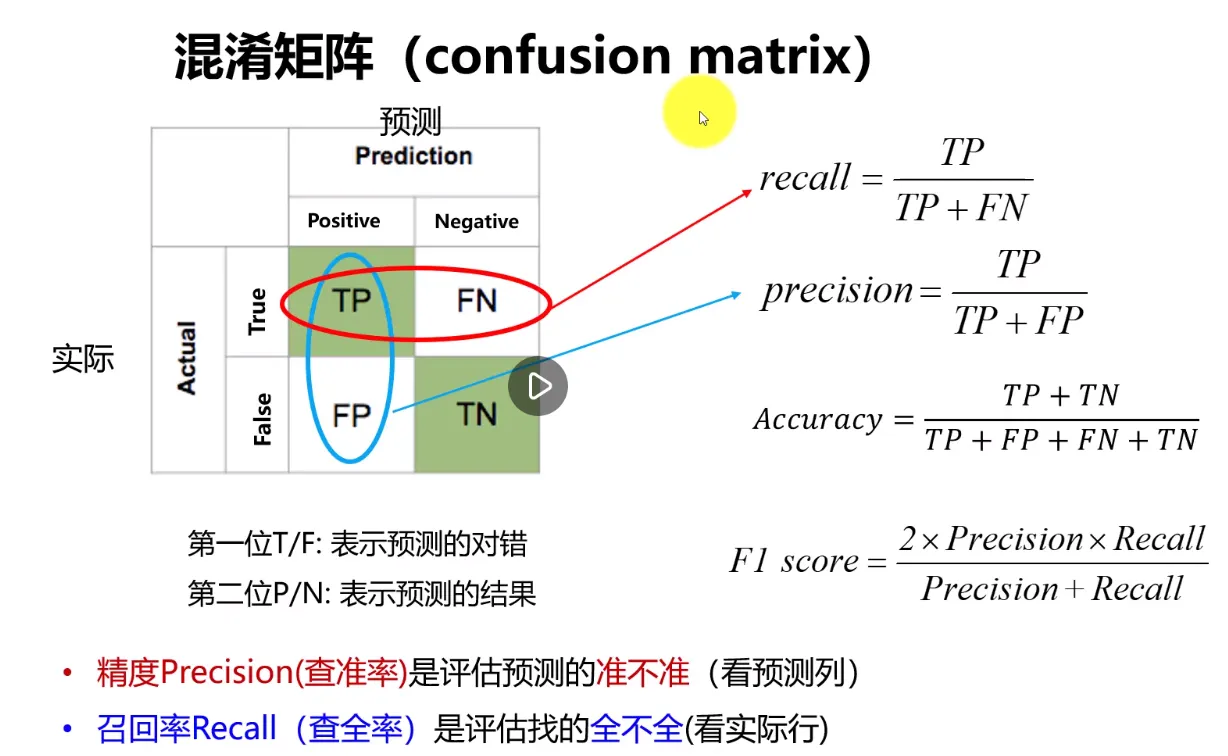
可以看到图中混淆矩阵从整提上拆分了实际值Actual和预测值Prediction,实际值又分为True和False,对应小红书笔记优化上对应的真实点击与未点击,预测值分为Positive和Negtive,表示的是笔记预测点击结果的正确与否。
TP(True Positive)在混淆矩阵中的意思就是模型预测该笔记被点击并且实际也被点击,即预测正确;因此FN、FP都可以得到对应的关系,TN(True Negtive)在混淆矩阵的位置就是预测不被点击实际也是曝光未点击的结果(预测正确了所以是True);recall-召回率 、Precision-精确率和Accuracy-准确率对应的代表如图片所示,核心用来评估预测的准不准以及全不全的问题。
除此之外,在得到评估指标AUC曲线之前,我们首先要计算ROC曲线,所有的测试集中对每个样本(此处代指小红书笔记)都需要做出一个实际值的预测,可以是(0,1)的范围,大于阈值判定成正例,小于则被判定为负例。
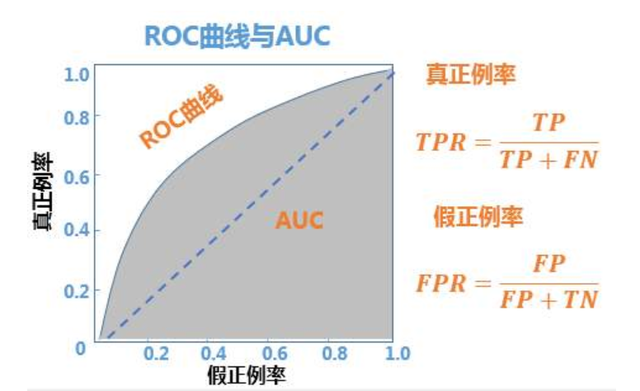
如果按照预测值从大到小排序,并且从大到小选择预测值作为分类阈值的话,就可以得到对应的P和R指标。图片中的TPR(真正例率)表示所有应该被预测为被点击的笔记样本,被正确预测为点击的比例;而FPR(假正利率)表示所有应该被预测不被点击的笔记被错误预测成为点击的比例。
我们以假正例率为横坐标,真正例率为纵坐标绘制一条从(0,0)到(1,1)即可得到一条曲线,我们称之为ROC曲线,我们通过ROC曲线下方的面积来评估一个模型预测的好坏与否,这个面积就叫做AUC(Area Under ROC Curve)。
整体来说所TPR 越高,同时 FPR 越低(即 ROC 曲线越陡),那么模型的性能就越好。AUC一般评判标准理想情况是1(理想态,模型一般达不到),在0.5到1之间是模型一般会达到的效果水准,一般比较好的就在0.85-0.95之间,一直低于0.5就可以卷铺盖走人啦,因为随机猜测0.5的比例都比这个高;后面模型预估排序效果的好坏都可以通过AUC这个指标来进行效果判定。
三、排序的主流策略&方法枚举
了解完排序的目标和评估标准之后我们在基于这个大的框架了解一下排序目前主流的策略。
首先建立一个概念就是排序的整体目标是根据业务不断变化的,最早期,业务目标比较简单需要聚焦的时候,就会选择某一个指标来作为优化(单目标优化),例如CTR,到了中后期的时候,发现单一目标对整体的提升有限&并且容易造成排序Cheating作弊的时候,就需要引入多目标排序的方式了。
例如小红书文章需要考虑CTR点击率之外的点赞、收藏以及评论情况,小红书视频需要看完播率(如果看完播率的话,就由二分类问题变成了一个回归问题了)等;
3.1 算法框架 LR:pointwise、pairwise和listwise
LR是比较简单的线性模型方式,通过学习用户的点击行为来实现对于CTR的预估。利用逻辑回归的方式构建推荐算法模型,具体模型公式如下:
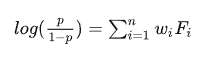
公式当中,p代表的是用户喜欢某个标的的概率,Wi代表的是权重,学习模型的参数(前期可以人工调整,后期最好做成自适应类型);Fi是特征i值;通过上面的公式计算给用户推荐的笔记iteme -p值;然后最终按照p值的score打分大小降序进行排序。
1)PointWise单点法
基于单点打分,对参与排序的每一篇小红书文章都会得到Score(相对分数),只要和用户匹配的业务目标(指代CTR点击率)越近的item,得分Score就更高。单点计算的结果就是构造简单,模型能够实时更新,计算量也比较小。但是输出的排序列没有考虑到排序之间的item笔记也会存在影响,没有考虑全局最优。
2)PairWise配对法
对参与排序的小红书笔记item两两比较,计算和目标优先级得到排序的结果,如果参与排序的笔记有三篇A、B、C。理想排序是”A > B > C”,我们希望通过两两学习的关系“A > C”,”B >C “和“A>B”的方式来得到最终的目标A > B > C的方法,模型的精度有所提升效果优于PointWise方法,但是样本构造的成本比PointWise要更高,如果无法构造所有的Pair对会造成所有模型存在偏差。
3)ListWise列表法
讲整个的item笔记的序列看做一个样本,对参与排序的item中的每一个预测出一个在目标列表中的位置。一般来说ListWise 排序的精度最高,但是构造样本的成本最高,需要ranking的算法基于排列来计算Loss。
总结:推荐场景之下常用的建模方法是PointWise居多,正负样本对构造方便快捷,用户正向行为的item点击可以记为1,未点击记录为0,当然需要去除作弊点击、误触点击的样本;其次,推荐场景用户没有准确意图,相对排序精度要求要微弱于搜索query,而且PairWise、ListWise方法构造样本难度大成本高,目前用的会相对来说较少一点。
3.2 模型的选择
推荐系统基于上述的PointWise单点法,产生了一些代表性的基于PointWise的排序模型。如DNN、Attention、多任务学习等都被移植到了推荐系统的排序上。毕竟是属于算法模型部分,这里策略产品只做一些简单的介绍。
1)DNN系列:微软的DSSM双塔模型
在召回策略部分已经给大家分享过,属于大家的老朋友了,核心还是在推荐场景下围绕用户和待推荐的小红书笔记构建两个Embedding向量,同时构造哦政府样本模型去做训练区分;线上提供服务的时候用请求用户User去和笔记Embedding向量去计算余弦相似度,排序分Score来做最终结果的呈现。
2)Attetion系列:阿里云DIN
注意力机制Attention与推荐系统的融合的开山之作,模型结构比较简单解决问题的场景也比较容易理解,感兴趣的朋友可以自己找一下论文了解一下。
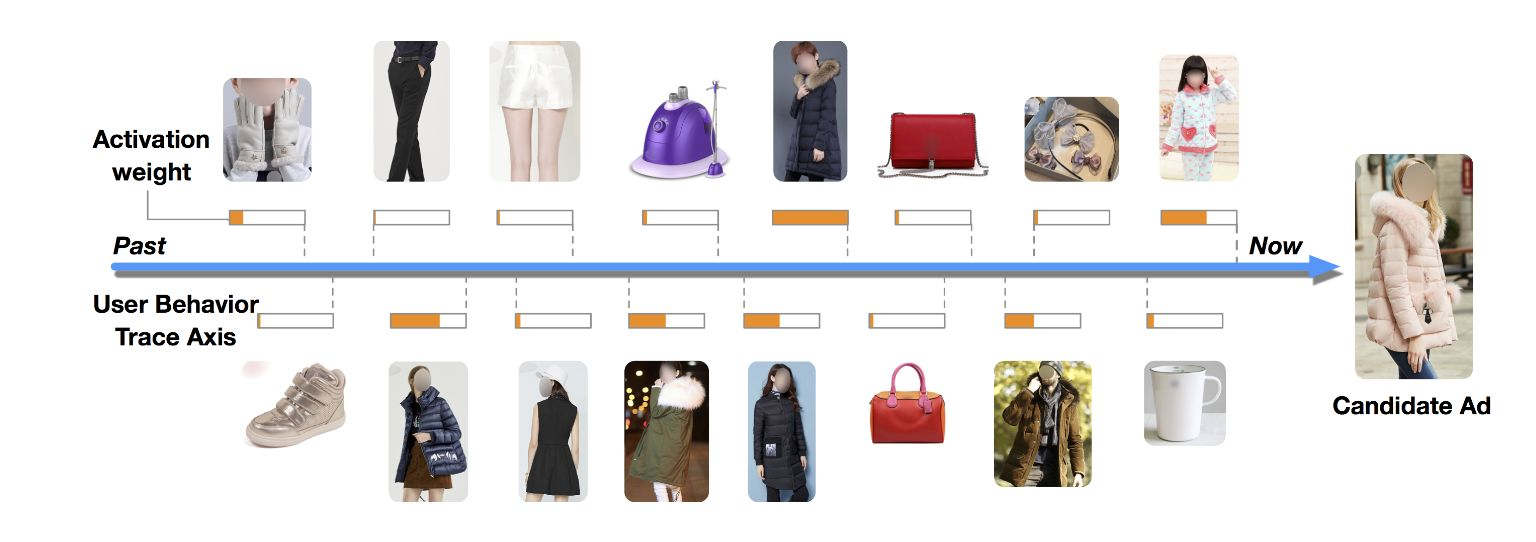
输入的特征最重要的就是用户发生实时正向行为item的embedding,会直接在网络中对这个item物体做pool池化操作;比方用户在浏览大衣感兴趣的时候,那么就不希望对用户行为中的杯子、包等item给不相关的物体更大的权重,维持对于大衣相关cat类目的权重,这个行为item和目标item之间的权重是自动学习得来的,也是随时会发生变化的,这个就是Attention的整体思路;
整体来说以上就是推荐系统在排序方面的介绍,核心是帮助广告策略产品经理入门了解排序策略需要知晓的工作内容,帮助大家简历职业壁垒,而不是让大家从事算法工程师的工作,深度的去理解广告策略建模的两个核心问题竞价问题与排序问题,这样作为产品才好结合建模目标去实现业务的需求,也更加理解广告收入如何去做优化。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










策略产品交流与学习欢迎关注作者主业