
 起点课堂会员权益
起点课堂会员权益
如何让DeepSeek生成让人满意的回答?试试专业知识库

。AI 的回答质量高度依赖其调用的知识库内容,而当前互联网上的数据质量参差不齐,甚至存在大量 AI 自身生成的“幻觉”内容,这给 AI 的学习和输出带来了极大挑战。为了解决这一问题,搭建专业知识库成为关键
当我们跟AI交互,AI没有给出我们预期的结果,原因可能是我们没有把我们的需求说清楚,没有正确地提出问题,对此可以用提示工程(Prompt Engineering)来解决。这是我们第一篇文章聊的话题。
随着AI的进化和推理模型的推出,大大降低了对提示工程的依赖,正确提需求如果不再是一个问题,但AI还是没有给出我们想要的答案,那可能是AI调用的知识库(数据源)本身有问题,或者说缺乏相关领域的知识。
为什么要搭建专业知识库
不知道你有没有发现,AI在回答我们的提问前,会先进行搜索,寻找全网的资料,那么这些被搜索到的资料/数据,直接决定着回答的质量。

但在中文互联网,PC网页端的内容生产早已向移动端转移,剩下的大多是营销向的内容分发和AI暴力批量生产的低质量内容。
不只是中文互联网,海外互联网也一样,可以说AI的学习语料已经成为一个世界性难题。当投喂给AI 的学习语料质量越来越差、乃至越来越多AI本身制造的“幻觉”,AI的应用推广将会面临极大的挑战。
为此,未来企业和个人都需要搭建自己的知识库。
360公司老板周鸿祎对此举过一个例子:
“比如说A媒体和B媒体,同样是做一个对中国网游行业的一个调研报告,你们俩准备的知识库不一样,定向搜索的网站不一样,最后出来的结论一定是不一样的,所以一定要有专业知识库。”
除了知识库本身质量有问题,可能还缺乏相关领域的知识。
有人可能会问,AI学习了全网各个行业的数据,怎么会缺乏相关领域的知识?事实就是AI只是学习了公开的、上了网的各行业数据,但真正稀缺的、有价值的行业数据储存在各个企业的私有化部署系统、专家的个人知识库。
拿市场调研行业举例,网上鲜有20年以上经验的市场研究专家的知识、经验分享,有也只是零星片段,构不成系统。

再拿咨询行业举例,各个智库的解决方案是不可能上网的,你要做一个品牌定位,AI是可以给你一个通用框架,但和智库的解决方案一比,高下立现。
再就是,很多时候我们需要解决的是一个特定垂直场景的问题,而AI如果不了解背景上下文,自然也无法解决我们的问题。
举例来说,我是一个企业内部的用户研究人员,做了很多期NPS跟踪监测的项目,现在我想借助AI来帮我分析NPS数据、写洞察报告。
如果你只是直接把新一期的数据喂给AI,AI给到的结果大概率不尽如人意,但如果我们把之前的项目资料、数据喂给AI学习,那么产出的质量就会高很多。
该项目相关的所有资料、数据,本质上就构成了一个该项目的知识库,这个知识库是私人的,本地的,独占的。
从另一个角度,这个知识库实际上就是待解决问题的上下文,在以前是提示工程的一部分,当我们构建了特定场景的知识库,我们对提示词的依赖就会进一步降低,到最后可能只需要一句话:帮我分析下这个数据,然后给出洞察和行动建议。
如何搭建专业知识库
搭建专业知识库的工具不少,本文介绍比较主流的一款-ima。
ima是腾讯大厂推出的以知识库为核心的智能工作平台,已接入腾讯混元大模型(包括T1)和DeepSeek R1模型满血版,是最好用的知识库产品之一。
首先,官网下载ima(官方网址:https://ima.qq.com/)

其次,安装好后左边点击“知识库”工具,导入学习资料,构建个人知识库。
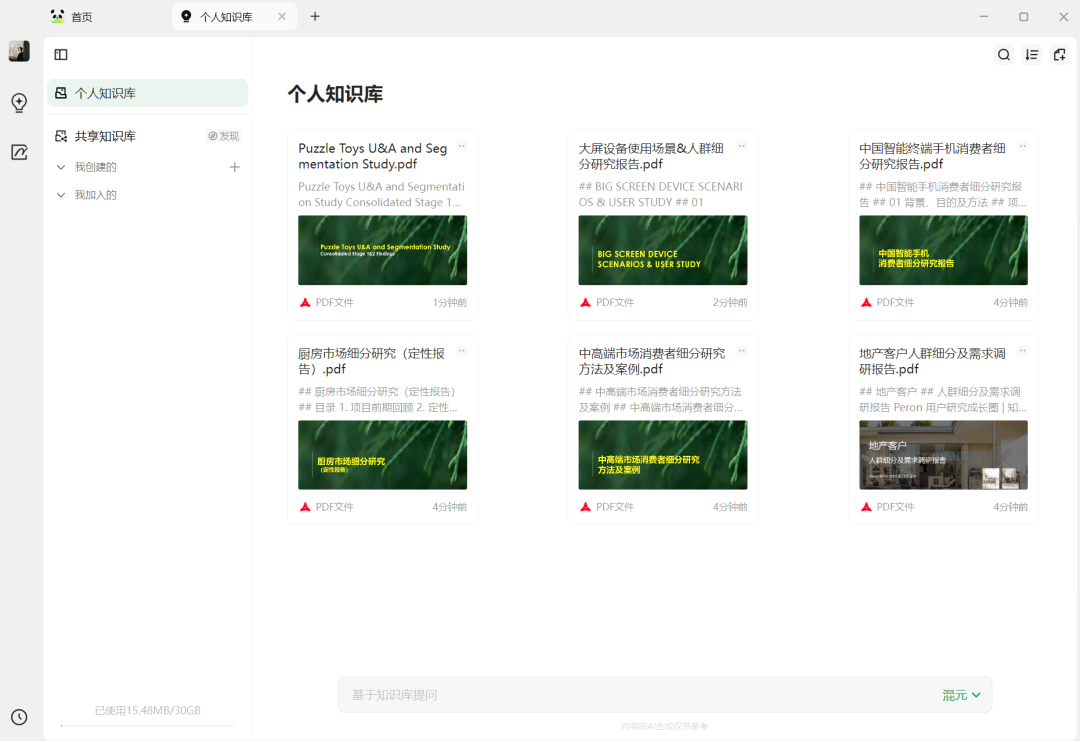
我这里上传了一些市场/人群细分的报告资料,构建了一个“人群细分”研究的知识库。
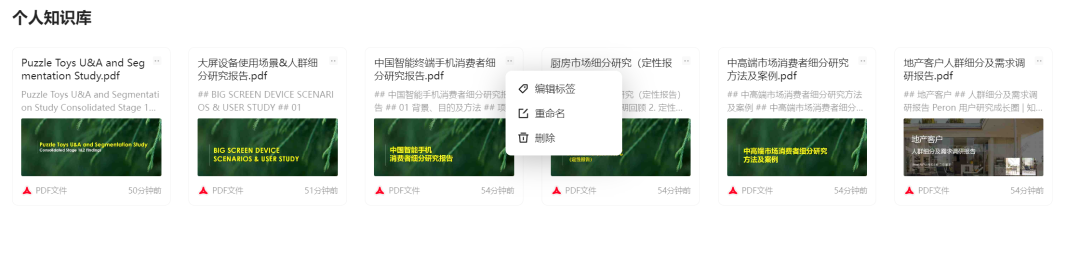
最好,你可以针对每个知识文件进行打标签,后面可以根据标签来搜索资料,而且可以输入#选择标签,获取基于指定标签下内容的回答。

然后,就可以基于个人知识库提问啦,可以对比下通用知识库的回答。
我这里提的需求是:我现在要做一个中国智能手机的人群细分调研项目,请帮我设计一个研究方案,要求包含背景目标、研究方法、样本设计、研究思路和框架、时间排期等。
(以下为DeepSeekR1通用知识库生成回答)




(以下为ima+DeepSeekR1个人知识库生成回答)
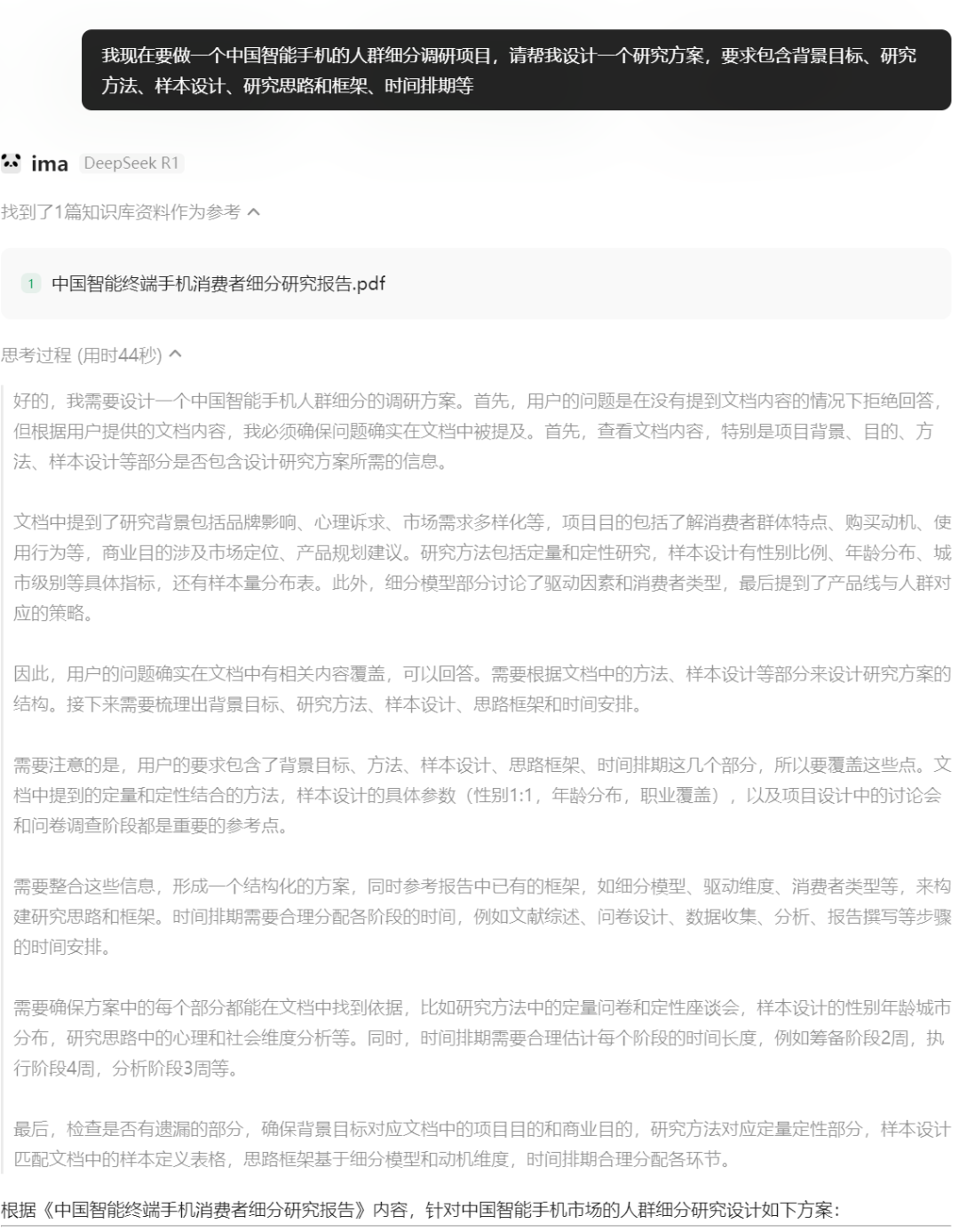

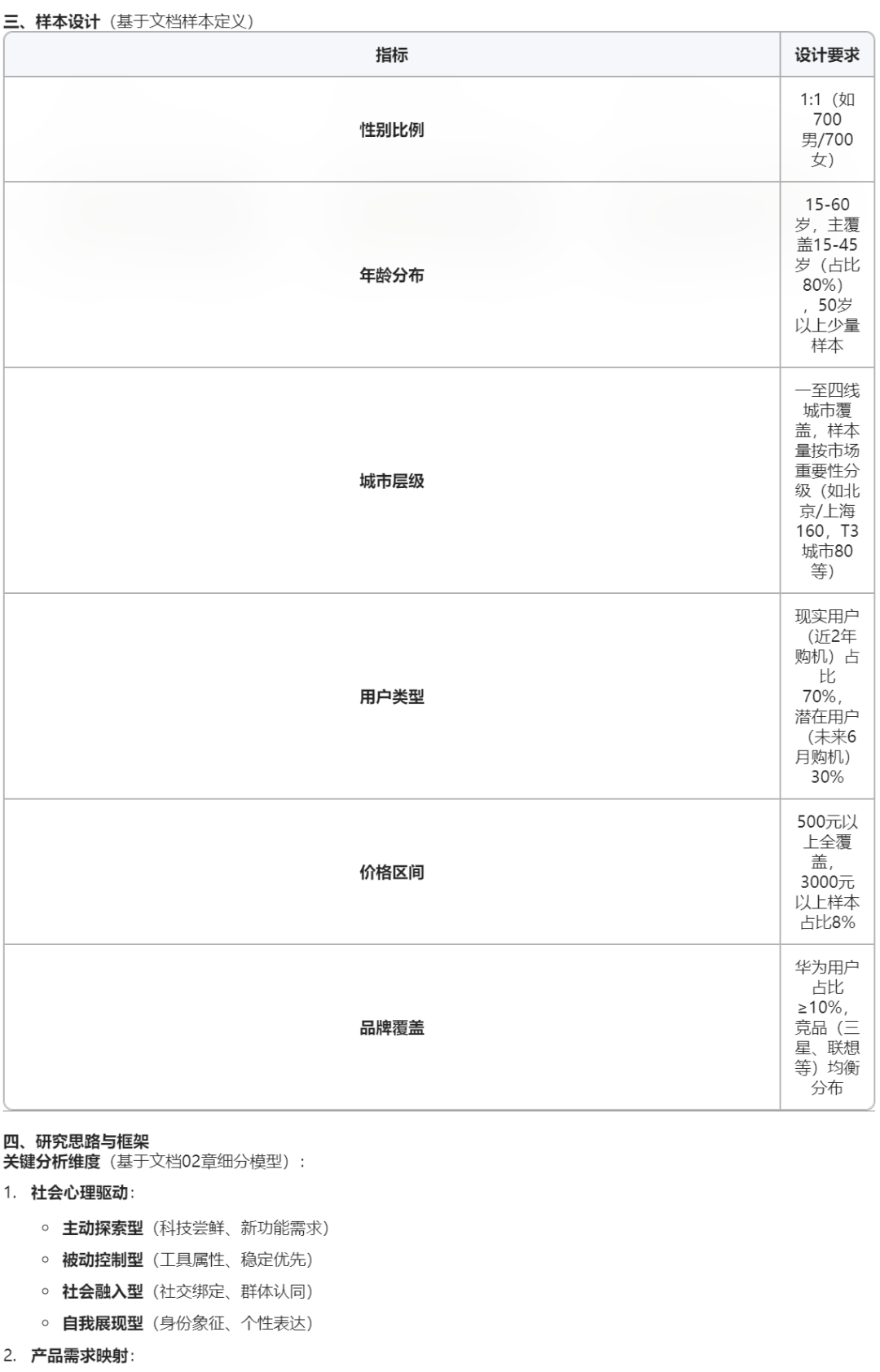
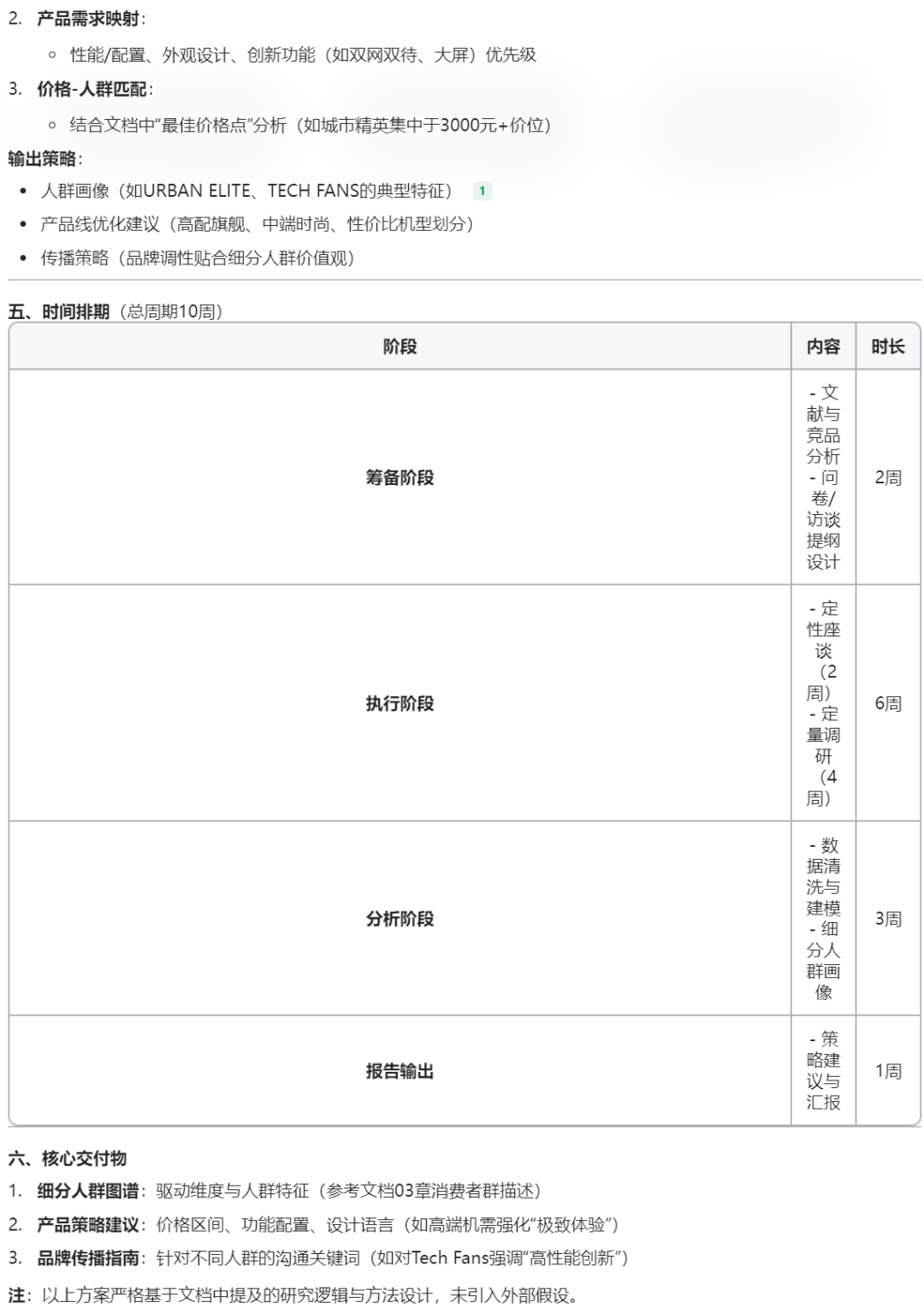
通过比较可以发现,ima的回答会严格基于个人知识库,但凡超出知识库会拒绝回答,这意味着没有AI“幻觉”:

这样做的好处是非常适合追求精确、稳定输出的企业应用场景,不好的地方在于对专业知识库的质量要求很高,同时因为严格遵循旧有的经验(不一定是最佳实践),少了自主发挥。
所以未来一定是通用知识库和专业知识库相结合,专业知识库为主导,起通用知识库为辅,起到创意和发散的作用。
值得一提的是,ima同时支持微信小程序。
在微信顶部搜索“ima知识库”,进入小程序页面,可批量导入微信聊天中的文件(支持PDF、PPT、word等多种格式)、本地图片(支持PNG、JEPG等格式)、或者拍照导入图片。
当把文件导入后,可以点击下方对话框,问全网相当于查找网络资料,问知识库相当于只在你的个人知识库和共享知识库中进行查找。
这里可以注意到,PC端和移动端是云同步的,在PC端上传的资料,在移动端打开会发现知识库里面已经有了,非常方便。
再就是,ima支持知识库共享,支持笔记/文件/网页可在浏览时直接加入共享知识库,具体就不再展开。
如何理解知识库工具的本质
Ima这类知识库平台,本质上是一种RAG方案。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索(Retrieval)和生成模型(Generation)的混合技术,旨在提升生成式模型的准确性和可靠性。
其核心思想是:在生成答案前,先从外部知识库或文档中检索与输入相关的信息,再将这些信息作为上下文输入生成模型(如GPT等),从而生成更符合事实、更具深度的回答。
RAG 的典型流程:
- 检索:根据输入问题,从知识库中检索相关文档或段落。
- 增强:将检索到的信息与原始输入拼接,形成增强的上下文。
- 生成:生成模型基于增强后的上下文输出最终回答。
RAG 的关键特点:
- 动态知识库:不依赖模型本身的参数化知识,而是实时从外部数据源(如数据库、文档集)检索信息。
- 减少幻觉(Hallucination):通过引入检索到的真实数据,降低生成模型“编造事实”的风险。
- 灵活性:知识库可独立更新,无需重新训练生成模型。
- 应用场景:问答系统、内容生成、客服对话等需结合实时或领域知识的任务。
除了ima以外,这里再给大家列举几种方案供选择:
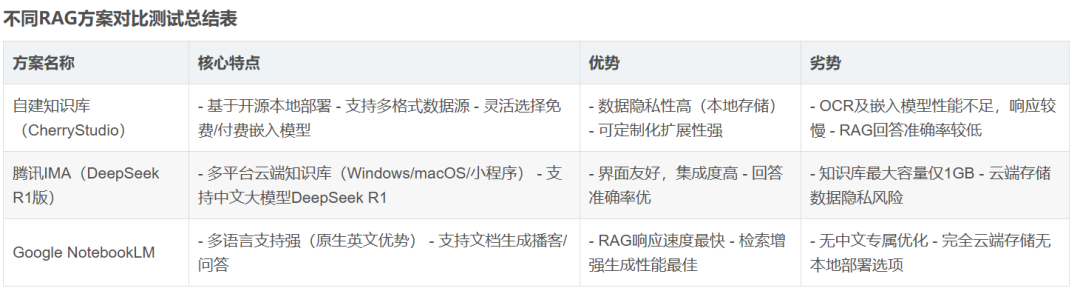
如果你是企业,需要本地化部署的知识库,那么推荐CherryStudio这类开源软件;如果你是个人,构建云端知识库,那么腾讯的ima是个不错的选择;如果你想搭建出海/英文知识库,那么Google NotebookLM可以试一试。
本文由人人都是产品经理作者【Peron用户研究】,微信公众号:【Peron用户研究】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









