
 起点课堂会员权益
起点课堂会员权益公众号影响因子的可行性分析:公众号文章“被引量”指标

文章从学术论文中的“参考文献”说起,延伸出了一个可衡量公众号文章质量的指标“被引量”,脑洞很大,其中的思考方式不妨我们来学习一下。
学术论文有一个必不可少的部分,叫做“参考文献(References)”,在这个模块里你要把你在本论文中引用观点的来源标注出来:

参考文献作为论文的一个重要部分,一方面表示了该篇文章是基于什么样的研究基础展开的;另一方面,对于被引用的论文,被引量代表了该文章的影响力和价值。
学术领域无人不知无人不晓的汤森路透基于文章的被引量会发布一个期刊引证报告,报告的核心指数称之为影响因子。
影响因子(Impact Factor,IF)是汤森路透(Thomson Reuters)出品的期刊引证报告(Journal Citation Reports,JCR)中的一项数据。 即某期刊前两年发表的论文在该报告年份(JCR year)中被引用总次数除以该期刊在这两年内发表的论文总数。这是一个国际上通行的期刊评价指标。
影响因子现已成为国际上通用的期刊评价指标,它不仅是一种测度期刊有用性和显示度的指标,而且也是测度期刊的学术水平,乃至论文质量的重要指标。
谷歌学术也采用了相似的H指数作为学者和期刊评价的标准:
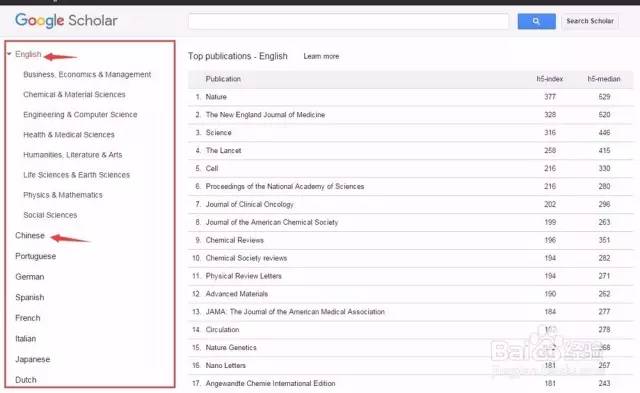
所以我在想,公众号的文章可不可以引入这么一个“被引量”指标,用以评价一篇文章或者一个公众号的水平呢?
学术文章的被引量很容易计算,因为国家有明确的法律法规和标准,只要有足够全的学术文章便可以计算出某篇文章的被引量。
对于公众号来说,计算被引量所需要的数据也是完善的。
首先,功能层面
2017年6月6日,公众号开放了“插入全平台已群发文章链接”的功能
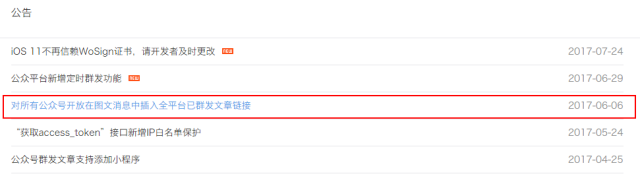
这个功能的开放为添加“参考文献”提供了可能。
然后,数据层面
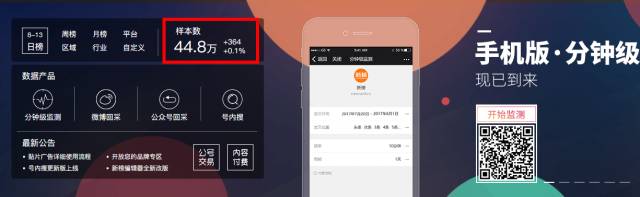
目前内容创业服务公司新榜保持每天对44.8万个公众号文章的采集工作,几乎包含了所有活跃的公众号。这部分公众号的文章在新榜数据库是可检索的。
最后,技术层面
要获取文章的“被引用”情况,首先需要知道文章的被引用的情况,然后需要知道文章的来源(即公众号)。
而这两个数据,也是全部可以得到。
文章引用行为的获取
我们打开一篇“引用了”其他文章的公众号文章,F12检查文章的源代码可以看到,文章是以超链接的形式出现的:
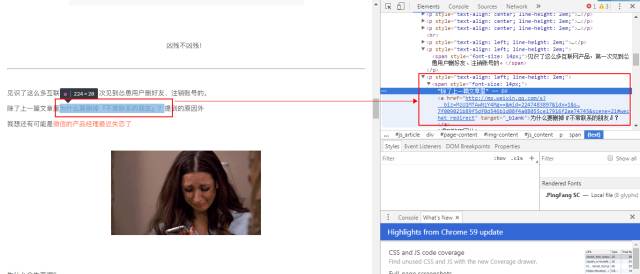
所以在采集文章时,如果在源代码中采集到
<a herf = “http://mp.weixin.qq.com/s?__biz********************* “>文本</a>
的字段,则可以认为此处有“引用”行为。
引用来源分析
找到了文章的引用行为,我们需要对被引用的文章进行分析,分析的核心在就于这篇文章的链接,也就是刚才herf后面的那一串。
幸运的是,微信在链接里保存了我们需要的所有数据。
以刚才那篇文章的链接为例:
http://mp.weixin.qq.com/s?__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
我们把链接分为三部分:
http://
mp.weixin.qq.com/s
__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
了解链接组成的同学们应该知道,前两部分是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部分。
在链接里,“?”后面的部分是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
- __biz
- mid
- idx
- sn
- chksm
我们这里只用到前两个参数:
- __biz可以认为是微信公众平台对外公布的公众帐号的唯一
- idmid是图文消息id
通过__biz参数可以获得公众号的ID数据,是唯一识别的,目前技术上可以转化成账号的;
通过mid参数,我们则可以定位到文章的ID,也是唯一识别的。
到此,对于文章引用行为技术层面的问题都已经解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用账号所有文章的被引量计算账号的“影响因子”,可以使用SCI的计算方法,也可以使用GoogleScholar的H-index的计算方法。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎么受待见的事情,因为“被引量”这个指标已经作为一种评价标准,引用自己的文章给自己+1这种行为不是很好看。
负引用这件事在学术领域还不那么严重,一篇论文的结论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体很多时候传递的是价值观。比如某篇文章观点偏激,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论今天的收益如何、多少阅读量才能开通流量主。
我们每天仅有的几分钟阅读时间里,有一半浪费在那些“耸人听闻”但毫无营养的标题党上,反而那些报道事实、传递价值的深度内容或因为文字太长、或因为标题不够吸睛,被淹没在这爆炸的信息海洋中。
是时候该有人站出来做点什么了,比如给内容行业也加入一个让死学术圈欲仙欲死的“影响因子”。
作者:野蛮人诺基亚,公众号:喜新(ID:noyanjiu)
本文由 @野蛮人诺基亚 原创发布于人人都是产品经理。未经许可,禁止转载。









受教了
观点好新奇! 😉