
 起点课堂会员权益
起点课堂会员权益如何设计智能语音助手?

随着人工智能的发展,智能语音也在不断取得重大的突破,那么设计一个智能语音助手需要交付些什么?和设计VUI时需要遵守哪些基本设计原则?来看看作者的回答。
近年随着人工智能的热潮,创新者纷纷围绕算力、算法、数据这AI三要素来对某个场景应用落地,其中智能语音在2016年被美国权威杂志《麻省理工科技评论》评为当年十大突破技术,2017年全球智能语音市场规模更已超百亿。
但技术的发展往往不是一蹴而就的,综观智能语音产业的发展历程,也算是曲折迂回,它大致可划分为四个阶段:
- 第一阶段是技术萌芽阶段(20世纪50~70年代),以孤立、少量的词汇为主的句子识别,并通过关键词匹配实现简单命令操作,其主要的标志是AT&T贝尔实验室开发的Audrey语音识别系统,它能够通过跟踪语音中的共振峰,当识别10个英文或数字时,正确率可高达98%。
- 第二阶段是技术突破阶段(20世纪80年代),语音识别和自然语言处理技术有了较大进展。智能语音技术研究由传统的基于标准模板匹配的技术思路开始转向基于统计模型(HMM)的技术思路,并再次提出了将神经网络技术引入语音识别问题的技术思路。
- 第三阶段是产业化阶段(20世纪90年代到21世纪初),智能语音技术由研究走向实用并开始产业化,以1997年IBM推出的ViaVoice为重要标志。自此,智能语音产品开始进入呼叫中心、家电、汽车等各个领域。比如,上世纪70年代由美国国防部远景研究计划局资助的,旨在支持语言理解系统的研究开发工作的计划DARPA。进入90年代后,研究重点已转向识别装置中的自然语言处理部分,识别任务设定为“航空旅行信息检索”。
- 第四个阶段是快速应用阶段(2010年以后),以苹果Siri的发布为重要引爆点,智能语音应用领域由传统行业开始向移动互联网等新兴领域延伸。在发达国家,大量的语音识别产品已经进入市场和服务领域并取得很好的效果,比如Siri、Cortana这类集成了视觉和语音信息的内置应用,或者像Amazon Echo、Google Home这样的纯语音设备。
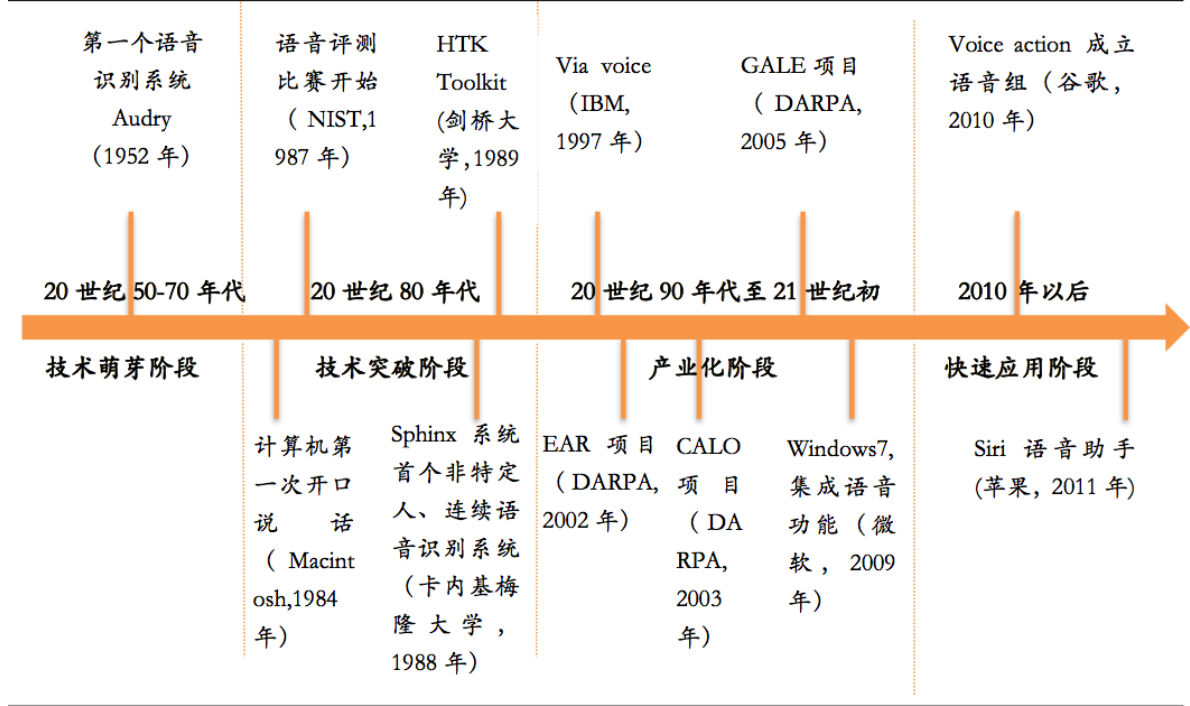
智能语音产业发展历程(来源:广证恒生)
而在人们的日常生活中,相信大家已经对Siri、小爱同学这些手机智能语音助手相当熟悉了,在不久的物联网时代,人机交互无处不在,语音作为人类获取信息最自然、便捷的方式,使用频率将会越来越高,当用户使用习惯后,智能语音将会融入人们生活的方方面面。
纵观计算机用户界面的发展,一般可认为是经历了从键盘,到鼠标、到触屏、到语音这样的发展历程,人机交互也逐步经历了基本交互、图形交互、语音交互、体感交互。在未来,即使技术已经应用到体感交互,语音交互依然会是体感交互中的重要环节。

History of Computer Interfaces
语音这种交互方式之所以能够迅速发展,得益于语音得天独厚的优势。

因此,语音用户交互界面(英文:Voice User Interface,简称VUI)设计正逐渐走进了产品经理和交互设计师的视野,如何运用产品和设计思维拓展智能语音的应用场景,探索和应用新的交互方式,让技术和人文相融合,使产品更好地服务于用户,这成为产品经理和交互设计师未来值得探讨的话题。
但目前无论是国内国外,探讨这方面的文章少之又少。因此小编想谈一谈设计一个智能语音助手需要交付些什么,和设计VUI时需要遵守哪些基本设计原则,以供大家参考。
一、智能语音VUI项目的交付物
有产品经理从业经验的人都会清楚产品经理经常撰写的文档有BRD、MRD、PRD等,那么若要设计一个VUI项目,那么它的交付项又应包括什么呢?一般来说,它包括了以下四种交付物:
1.示例对话
示例对话是系统和用户之间可能产生交互行为的预设对话,对话看起来就像电影剧本一样,包括两个主要角色之间来回往复对话。在设计示例对话时,要针对用户可能出现的各个场景去设计出多种不同示例对话,多种不同的示例对话可以让用户听起来感觉不那么死板,因为假若只设计一种,用户每次都会遇到相同的反馈,这样会让人听起来更像是一个机器。
此外,还应该考虑到一些异常情况,这样让用户问一些偏门的问题也得到回复,大大提高了用户对系统的预期。
所以设计示例对话和设计后台系统比较类似,以设计电商后台系统为例,用户在前端点击“退货”操作,这时已购买商品所处的时间节点可以分为未出库、已出库但没发货,已发货、已收货这几种情况,针对每一种情况都要作出相应的处理,如果没有仔细考虑就很难得到一个稳健实用的系统了。

2.流程图
当编写完各种示例对话后,就应该开始写流程图了,流程图是用来展示VUI所有可能发生的路径的图示。比如一轮对话后,流程图需要展示下一个状态分支的所有方式,方式不一定要罗列所有的交互或示例对话,它也可以是功能的分组、文本的分组
等。
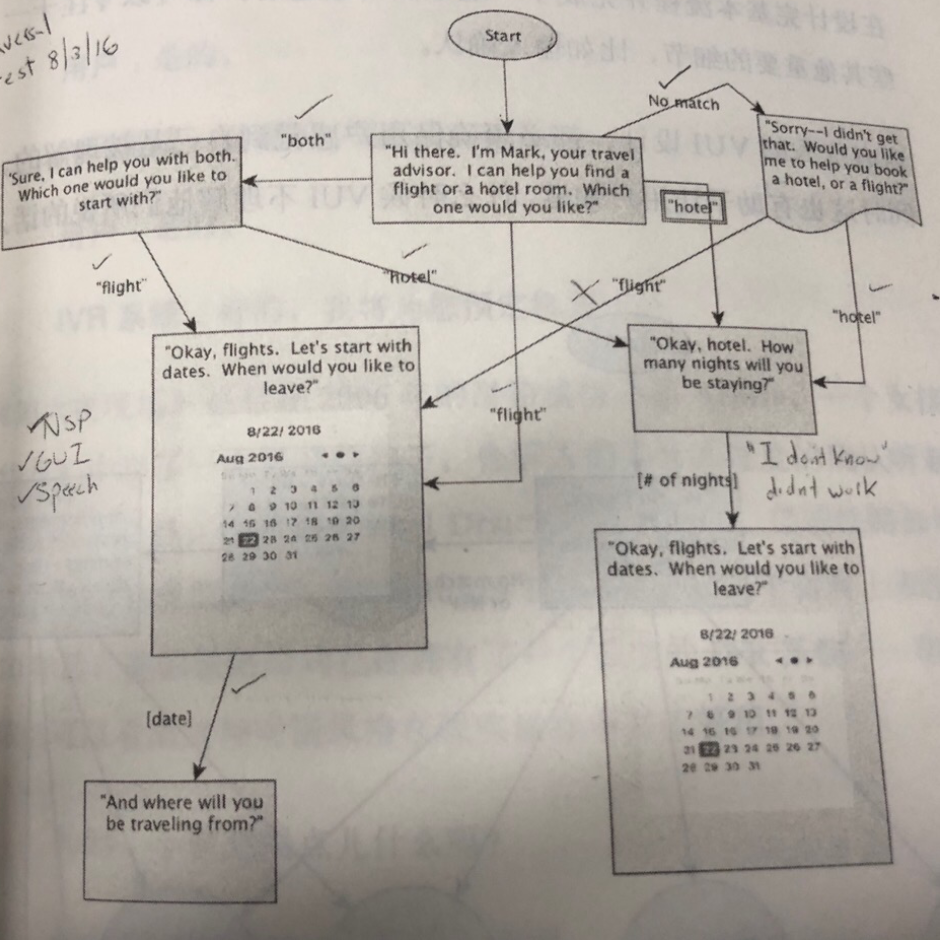
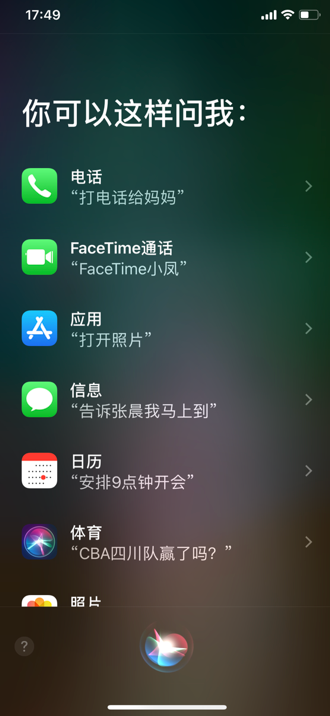
3.提示列表
由于语音技术的限制,目前还没有无所不知无所不能的语音系统,所以设计一个提示列表是相对必要的,它可以让用户知道系统真正能做的事有哪些。如果没有屏幕可以使用配音演员或语音合成来播放提示列表,如果有屏幕则可以多模态展示,将视觉和听觉相结合,如Siri、Cortana。
4.产品原型
如果这是一个多模态产品,有屏幕,支持触摸交互,这个产品原型就和普通的产品原型一样了,比如用Axure制作的低保真产品原型。
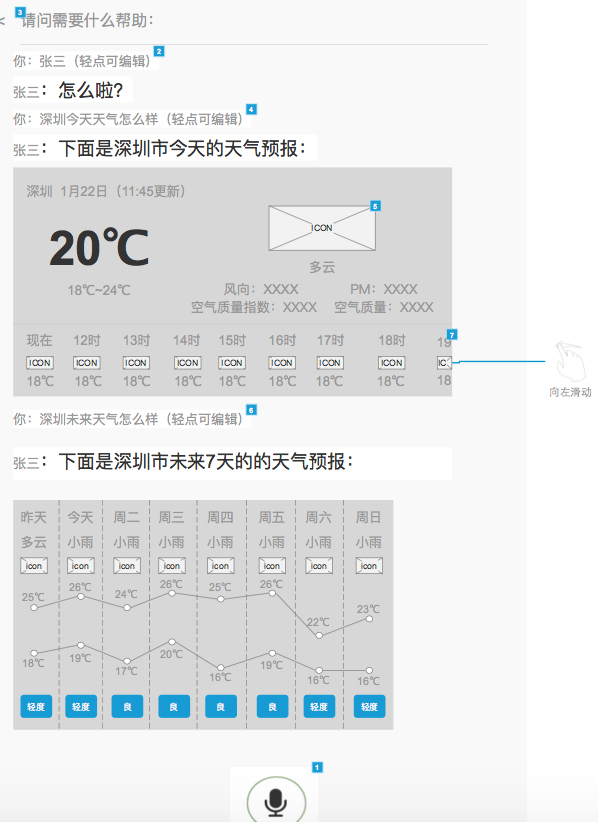
二、智能语音VUI的基本设计原则
在设计完基本的流程并完成一些示例对话后,就可以开始专注一些重要的细节,这样才能让系统更加健壮和人性化。
细节一:确认策略
有人可能会问确认策略到底是什么意思?其实,在人与人的沟通中,每个人都是渴望被理解的,但是人与人沟通也会经常出现理解错误、听不清楚、词不达意等种种问题,这些都需要倾听者去和对方确认自己所理解的意思是不是就是对方所想表达的意思。
因此在设计VUI也往往需要向用户进行确认,而系统良好的确认策略可以确保用户体验,保证对话的流畅度和准确度,让用户知道系统已经理解了自己的话。在考虑确认策略的时候,往往需要考虑以下几点:

过度的确认虽然可以保证信息的准确性,但是也会让人厌烦,因此选用合适的确认策略方法也是非常重要的,它能更有效率地保证信息的准确性,以下就是一些常见的确认策略的方法。

细节二:是采用命令-控制模式还是对话模式?
VUI一般都是采用“命令-控制模式”,每当用户想说话的时候,必须给出明确的指令,但是随着用户对系统的对话性要求升高,另一种更自然的轮流对话设计模式越来越普及,如何把这两种对话模式合理利用起来也是设计者需要考虑的问题。

为了让对话更加人性化,一般在对话模式中加进一些对话式标识,让用户了解到交谈的进展和情况,让对话更加自然,用户的参与度也会更高。
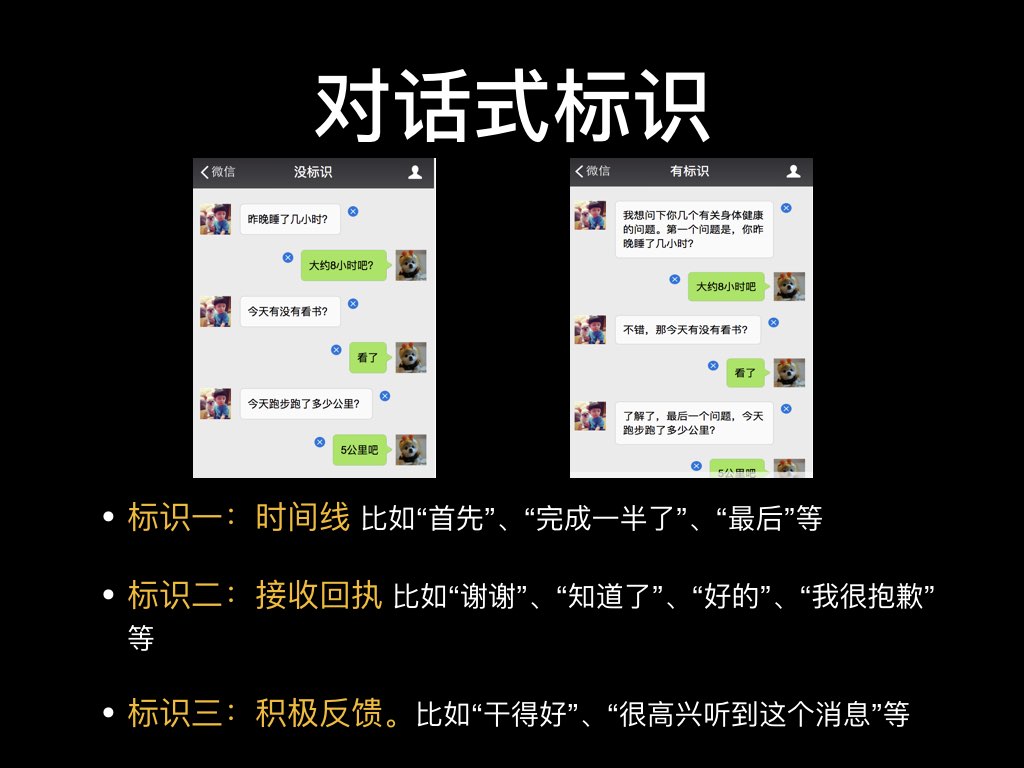
加进对话式标识的最佳例子莫过于是2018年谷歌I/O大会中Google Assistant和理发店之间的语音互动了,下面是双方之间的对话。

加入了对话式标识的Google Assistant表现的流畅自然,一句“嗯哼”的通用确认更是出乎所有人的意料,让人类丝毫没有注意到自己其实是在和AI对话。
细节三:异常错误如何处理?
谷歌的设计主管ABI JONES说过:
“当你与人类交谈时,永远不会出现不可恢复的错误状态。”
而系统总会发生错误,若没有对应的异常处理,则是不可恢复的错误,这会降低用户对系统的期望值,因此如何优雅地处理错误是每一位设计者需要着重考虑的。


细节四:其他的一些设计原则
美国著名语言哲学家格赖斯,在《Logicand Conversation》(1975)一文中认为在人们交际沟通过程中,沟通的双方都在有意无意地遵循着合作原则,以便更加高效率地完成交际任务,他提及到在谈话中往往遵守的合作原则中的四个范畴:

因此,若要打造一个更加类人的VUI,符合合作原则可以让用户免受困惑和挫败,因此,下面说到的一些基本的设计原则也需要持续打磨和优化,以便符合合作原则。


最后,虽然VUI在方方面面都在模仿人类的沟通方式,但是VUI更像是一个工具型产品,让它更像人的目的是为了让系统更高效地解决用户的问题,上面提及的概念基本上都是来自互动式语音应答(IVR)的经验总结发展的,充其量只是VUI设计的冰山一角。
倘若有机会,下一篇文章还会对每一个细节具体展开陈述,还有阐述诸如应该如何处理否定、如何应对不同语境、应怎么设计唤醒词等进阶技巧,或者是对语音识别技术的技术介绍。
作者:——,多年互联网产品设计经验,曾从业过多款不同行业的产品策划和运营。
本文由 @—— 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 unsplash,基于 CC0 协议









请问下对于语音助手怎么量化功能迭代效果呢?日活和留存感觉波动太大了
请问文章如何转载?
学习了,写的很好,刚好自己正在做智能客服,但是加进对话式标识只能做到一轮
很赞的读书笔记哦~ 最近也在看这本书 一直没有时间整理 后面也要学习 做成ppt的格式 方便阅读
请问什么书?
请问这是哪本书?
语音设计提几点建议,抛砖引玉
1.边输边译功能,给予用户实时反馈。衡量语音转化成文字是否准确和语义连贯流畅
2.黑色浮窗,拒绝阻断提醒。明显感知正在说话。可以让用户大声更响亮集中和沉浸体验
3.Ai化,将传统手势行为模拟成语音指令,提升App科技馆
4.根据声纹强弱判断用户是否说完,说完之后直接触发下一个行为
5. Spoken language understanding,结合上下文深入语义理解,关键词特征提取 语义逻辑理解 意图识别
针对第四条,VAD端点检测可以实现
强烈期待下一篇文章
写的不错,用心了,期待下一篇
说的非常好,持续关注,超赞👍