
 起点课堂会员权益
起点课堂会员权益
如何提升语音的可发现性,让小白用户也能轻松使用?
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
为什么要提升语音可发现性呢?因为很多时候,用户不小心说错话语音并不懂得纠正,而且语音的自然感知力度也不如视觉交互。本文为了解决这些问题,进行了一些思考。
在很早的时候语音就已经深入人们的生活,siri算是比较早的被人们熟知的语音助手,每天早上匆忙要离开家之前都会说:“Hey Siri,今天天气”,比起解锁找到天气应用,点击打开,查看天气情况,路径缩短很多。
我认为这就是语音最大的优点,缩短使用路径,直达用户目标,所以智能化可持续性学习的搜索方式会是它比较重要的一种手段。那么首先让用户逐步熟悉了解语音的使用方法,才会真的将这种方便实用的交互方法融入人们的日常生活。
为什么想从语音的可发现性角度来思考方案呢?第一点,当前的语音错误后的提示很不友好,用户说错后也不知道要如何纠正;第二点,语音无法通过视觉呈现,自然感知力度不如视觉交互。
那么我们从哪些方面提升语音的可发现性呢?这就要来捋一捋出行时,语音、载体、用户之间发生的触点在哪里,在什么步骤容易出现问题。
一、触点:语音的载体
用户在什么场景下接触到语音,这个语音的载体包含哪些部分,都是非常关键的。
这里不对用户进行定位,主要是出于这样的考虑:现阶段为语音起步阶段,年龄、性别的区分仅代表着接受新交互方式的难易程度。所以此阶段应当是不断探索语音更为方便的场景,让人们逐步认识到语音的便捷性。
那么现在普遍使用语音的场景有以下几种:
- 家中:音箱、电视盒子、电视遥控器、手机
- 车内:中控、后视镜、HUD、手机
- 公共场合:服务机器人
这些场景下的载体有这形式:
- 有屏幕
- 无屏幕
公共场合的服务机器人这里我们不讨论,他们的业务性比较强,是强业务主导的交互流程,和人们日常生活中使用语音的场景完全不同。那么就是家中有屏无屏和车内有屏的语音交互讨论。
二、当前语音技术存在的问题
不论何种场景,语音的技术都是类似的,实现的原理也都是一样的。这里举例一些语音技术存在的问题:
1.必须唤醒
唤醒的花样很多,有唤醒词、快捷唤醒词、oneshot,业界外的人肯定不了解这都是什么东西,更可况我们想要推广的广大用户呢。
这里解释下,这些唤醒方式之间的区别:
唤醒词:最为基础的唤醒方式,一般是有固定的2-4个字作为唤醒词,比方说“你好小度、小爱同学”等,机器收到这样的语音信号,就开启录音,这时候用户可以随意说话,机器将录音文件拿去识别,这就是全部的识别的过程。
快捷唤醒词:由于每次操作都需要说唤醒词才可以控制,所以快捷唤醒词应运而生,有些又叫他hotwords,实现方式都是一样的。选取会比较常用的几个词汇,比方说“上一首、下一首、增大音量、返回主页”等,同样作为唤醒词,不过和唤醒词不同的是,这里只有唤醒,唤醒后识别到相应操作命令,直接执行,没有后续的识别。
oneshot:同样,设定几个词作为唤醒词,比方说“导航到、我要听”,机器收到这样的语音信号,就开启录音,这时候用户可以随意说话,不过相比较唤醒词增加一步,机器会对录音进行裁剪,裁剪到唤醒词后那一段就是用户自由说话的命令,再拿着裁剪后的音频文件去识别,就和使用唤醒词操作一样的效果。
2.录音过程中,杂音、交谈的话语可能会被录入
唤醒语音后,会进入录音状态,识别是将录音的音频拿去识别到唤醒词后面的那一段音频,录音是无差别录音的,虽然现在有各种降噪技术,但是人们对话的声音机器是无法区别的。
3.语义不能完全覆盖全场景
想让机器理解这段话,就需要语义理解。现在的做法还是依靠人工的录入,无法灵活理解。
4.对话系统不够灵活,很多执行完一个任务之后就退出,还需重新唤醒
当前语音对话系统虽然有不少多轮对话的场景,比方说在导航选择地点时,用户可以说“下一页、第二个”或者某个地点分词进行选择,但是看其本质,依旧是在导航情境下的单轮对话,选择某地之后就进入导航退出语音。最主要考虑的问题点还是第二个问题无法解决。
三、家中的场景
家中的场景是语音交互的最好场景,网络的稳定程度、安静的环境、自由的使用环境,都使得语音在这一场景中具有非常大的吸引力。
在这一场景中使用语音的载体除了音响其他都有屏幕,电视盒子、遥控器都可以配合电视屏幕使用。手机、电视都带屏幕,但是提示方式不能和车载设备类比,使用场景不同有很大的不一样。
在家中,人处于一种相对比较舒适、静止的状态,他有精力或者时间去仔细看屏幕上的文字提示,那么这样的有屏载体需要有比较多的比重出现说法提示,或者下一步的引导,用户数据收集的比较齐全的时候,也可以做新老手不同的操作引导。
智能音箱虽说不带屏幕,但是需要通过手机设置连接家中wifi,这样才可以获取云端资源,这里做交互引导的时候需要注意,用户唤醒是通过智能音箱操作的,那么在手机上可以做按钮点击唤醒音箱语音,但不能给用户一种幻觉:可以通过手机对话。
四、车内的场景
车内的载体不论中控、后视镜、HUD还是手机都是有屏幕的,这就意味着可以依靠屏幕传达部分信息给到用户,那么这里就涉及到多模交互。何时看屏幕、何时听语音是比较好的。这全看用户心情,当然我们也要做到良性引导。
根据后台用户使用语音的数据来看,导航是使用频次最高的一个领域,其次是音乐、电台、天气。所以从导航、音乐入手让用户先了解语音的基本使用方法。
上篇《语音交互中重要的引导设计》已经展示了几种引导方法,不过还是有不足,比方说在首页的位置放说法引导,其实经过一些用户测试,发现那种方法并不是万能的,很多用户都不会去看有什么说法。
所以我们应该按照使用语音的先后顺序进行引导:唤醒、识别。那么如果跳过新手引导的用户,至少要先告诉用户如何唤醒使用:

如果忽略这句TTS,也没关系。在首页的语音卡片上,常驻这样一句话,提示用户如何唤醒语音。
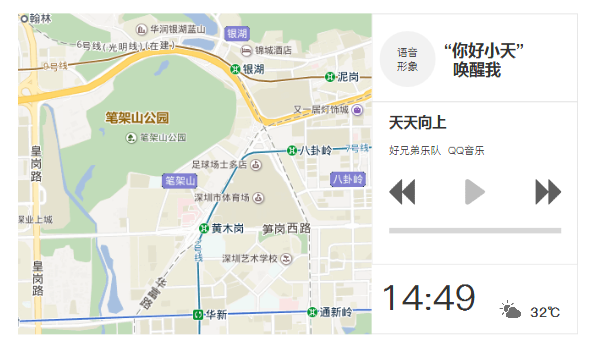
不过这种方法其实都是比较被动的,等待用户去发现,去探索,如果语音自己开始对话,又会被吐槽智障,或者受到惊吓。所以最初的产品策略应该比较保守一点,毕竟在智能车机上语音只是一个很小的一部分,过多的打扰到用户真的会有困扰。
这是我列的如何循序渐进的教会用户使用这样的唤醒方式:
- 第一步:基本操作:导航去哪里,听什么,给谁打电话
- 第二步:唤醒进行音乐操作,提示她“下一首”可以不唤醒使用
- 第三步:当用户发现有些可以不需要唤醒使用的,但是不知道在哪种情况下使用,那么就设置一个对话:
U:你有什么不需要我唤醒就可以说的?
天:全部唤醒词罗列,同时安利免唤醒的概念
升级方案:用户肯定记不住,当他有疑问询问
U:快速导航是免唤醒吗?
天:不是哦,导航中能免唤醒操作的有这些,您可以到哪里查看…
高级用户:找到自己习惯的操作方式,只记住那几个免唤醒词,有了固定的使用操作模式
之所以想要对快捷唤醒词作那么多的引导,主要是出于当前技术限制,唤醒是无法避免的,但是高频操作如果不采用快捷唤醒词实现的话,对用户来说更为麻烦,每次必须唤醒,就只说那么一个指令,语音的存在是为了满足用户懒惰的心理,用户但凡觉得有点麻烦的时候就会逐渐减少语音的使用,而这个节点就是我们需要花功夫去细化方案的地方。
五、一些感想
关于第二个问题点,开了个脑洞,在车内,如果搭配人脸识别、上下文理解,是不是可以去判断用户何时对机器说话呢?
首先,人们日常对话时,我要和谁说话基本都会面朝谁,哪怕眼神不会转移,但是面部还是会配合对话者转过去,这里就可以通过人脸识别看用户唤醒后是否将面部转过来。
第二点,因为在开车时,注意力肯定是高度集中的,有时候可能是不会转动面部,但是人们日常的对话遵随的这几个准则:所说的话是自己相信的真实信息、所说的话满足交际中所需的信息量、所说的话和当前对话相关、说话清晰明了。
所以我们可以根据录入的人们说话的内容判断上下文联系,进而判断是否在和机器对话。
如果是不相关的内容其实是对机器说的,那么此时喊下唤醒词也是符合常理的,可以对比两人对话,一人突然说了其他的话题,另外一个人没有意识到是对自己说话的,那么说话者肯定会要喊那人名字。所以一个丰富且符合常理的语音状态反馈非常重要。
以上是我对于当前如何提升语音可发现性以及未来可用技术解决的问题一些探讨。
语音其实不能只限制在车载或者是家居场景,因为随着人工智能的发展,想让一个机器智能,肯定会有越来越多感知外界的技术:语音、图像等,但是机器想要陈述或是表达,必须要用到语音,所以语音是将来人工智能的一种输入感知的入口。所以如何更好理解人们说的话是非常值得研究的。
作者:青绛,微信公众号:慕七和大胖
本文由 @青绛 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash ,基于 CC0 协议
















11