
 起点课堂会员权益
起点课堂会员权益数据探索平台设计——“CheckStyle”
数据工具产品很重要,但是这方面的人才却很稀缺。本篇文章作者结合自己的数据产品经验,介绍了数据探索平台设计——“CheckStyle”。

在产品的庞大家族中,有一类很重要的产品,他就是工具产品,工具产品具备强服务性,并且使用场景时效性极强,高效便捷的工具极大的方便了我们的生活。
随着大数据时代的带来,在工具产品中又衍生出了数据工具产品,随着数据的增长,数据的价值也亟待我们去挖掘,各大公司正在积极挖掘数据价值,并组建自己的数据团队,包括数据分析师、数据科学家、数据产品经理、数据工程师等等。
在这样的契机下,数据探索平台应运而生,作为一款数据工具产品,数据探索平台核心功能便是数据开放和探索,支持数据分析师、数据科学家和数据工程师等数据团队成员和咨询、BD等业务团队成员,用他们习惯和擅长的工具,协同进行数据科学项目。
数据工具产品很重要,与此同时,这方面的人才却很稀缺。
数据工具产品经理不仅仅要求传统产品经理的基本能力,还对技术背景和大数据架构有一定要求,这里我们不妨看一下业界领先数据产品阿里云对数据产品经理的要求:
阿里云-高级数据产品经理
级别:P7\P8
地点:北京、杭州均可负责ApsaraDB数据库产品设计,ApsaraDB数据库服务是阿里云核心的数据类的产品,是阿里云最为重要的PASS平台之一。
工作内容:
1. 完成市场调研与竞争对手分析,准确定义数据库/大数据具有市场竞争力的产品
2. 规划产品的生命周期和交付形态,对项目结果负责
3. 关注用户体验负责,产出安全、稳定、易用的产品
4. 组织研发、测试、运维、运营的高效沟通
5. 支持业务团队完成营收目标要求:
1. 计算机科学领域(CS)学士或硕士学位
2. 对大数据架构基本了解,有一定的大数据架构经验
3. 了解以下Hadoop\Spark\HBase\MongoDB\Redis优先
4. 了解数据库基本理论、大数据基本理论、云计算
5. 程序员/DBA出身优先
6. 了解大数据方案优先
在我们平时阅读的文章中,也会看大数据技术相关文章:
类似于《Hadoop架构原理》以便于了解我们数据探索平台底层数据存储架构,从而更好的做数据开放和探索。
类似于《为什么Jupyter是数据科学家们实战工具的首选?》以便于了解我们数据探索平台用户的日常工作,以更好的迭代产品,让科学家们用起来更顺畅。
数据工具产品很重要,数据工具产品人才很稀缺,自然,数据工具产品文章也很少。
基于此,结合自己的数据产品经验,简单谈一下数据探索平台设计中的一个Feature,“CheckStyle”,和大家探讨,希望起到抛砖引玉的效果。
本文核心观点:
因为用户编写的代码可能存在质量差、性能低、不规范、语法错误等问题。CheckStyle将使用我们TD的规则库,通过平台和流程来保障代码质量,希望能尽早、尽快、无感解决故障隐患,以节约时间,提高效率,降低出错率。
短期内会通过代码样例,API半自动化实现,结合实践不断完善规则库形成闭环,最终实现自动优化。
同时在一定程度也可以提升用户的技能,这也是平台“自动化”的重要一步。
设计前的小故事
为什么想到设计“CheckStyle”这个Feature呢?
主要是昨天和一位数据分析师同学闲聊,听到她随口吐槽一件工作中的小事,见微知著,聊一下数据探索中的“CheckStyle”需求,和大家一起探讨哈。
对话大意:
“最近咋样啊?”省略N个字。
进入正题:
分析师:“实习生写的SQL真是令人痛心,一堆错。”
权:“一堆错?规范问题?语法问题?业务问题?性能问题?或者,都有?”
分析师:“都有,毕竟是实习生。”
果断先diss她几句,招人时咋不想清楚,有经验的好一点,没经验的就要做好培养的准备,而且必然是一段时间细致的培养,答复,虽然她也做了准备,但确实需要时间。
权:“那你现在咋办?”
分析师:“能咋办,遇到问题解决问题,一个个看呗!”
权:“那个人力量有限啊,你时间有限,而且我们也只能说熟练使用SQL,不能说精通,大多数场景能搞定,遇到一些问题也需要查,这种事最好交给机器做,产品化。”
分析师:“有意思,说说看。”
权:“我想想,写篇文章总结一下,大家一起探讨吧!”
对话基本结束。
一段简短的对话,一件工作中的常见的小事,但可以挖掘的点很多。
下面说一下我的想法,“CheckStyle”。
一、“CheckStyle”是什么?
1. 背景
工作中类似的问题太多了,用户编写的代码可能存在质量差、性能低、不规范、语法错误等问题。
这里的用户包括:咨询、分析师、工程师、科学家等。
这里的代码包括:SQL、Python、Scala、R等。(SQL、Python、Scala、R皆为编程语言)
2. 具体场景
这么一说大家感受可能不深。
我们再来看几个鲜活的例子,看一线中的具体场景:
1. 前段时间一位数据科学家同学因为输出数据集目录命名不规范,导致和DSS的时间分区功能冲突。
数据科学家在我们印象中已经比较专业了,但依然有可能发生偏差。
其实“是人就可能会出错”,因此需要相应的规则和流程来约束,减少出错率。
2. 前天看到一篇Python性能提升的文章,大意如下:
Python 是机器学习领域内的首选编程语言,它易于使用,也有很多出色的库来帮助你更快处理数据。但当我们面临大量数据时,一些问题就会显现,因为在这样的量级上,工作进程中加入任何额外的计算都需要时刻注意保持效率。
在默认情况下,Python程序是单个进程,使用单 CPU 核心执行。而大多数当代机器学习硬件都至少搭载了双核处理器。
这意味着如果没有进行优化,在数据预处理的时候会出现「一核有难九核围观」的情况,超过 50% 的算力都会被浪费。在当前四核处理器(英特尔酷睿i5)和6核处理器(英特尔酷睿i7)大行其道的时候,这种情况会变得更加明显。
幸运的是,Python库中内建了一些隐藏的特性,可以让我们充分利用所有CPU核心的能力。通过使用Python的concurrent.futures模块,我们只需要3行代码就可以让一个普通的程序转换成适用于多核处理器并行处理的程序。

测例是将1000张图片被传递到深度神经网络之前将其调整为600×600像素分辨率的形式。
优化前在酷睿 i7-8700k 6核CPU上,运行时间为7.9864秒,在这样高端CPU上,这种速度让人难以接受,优化后运行时间降到1.14265秒,速度提升了近6倍!
看完之后确实是拍手称快,又get了一项新技能,使用Python的concurrent.futures模块做性能优化,节约时间,提升效率。
同时想到之前我想落地线下消费标签使用的一份poiid数据集,代码早早的写好,然而排队等待集群资源运行就等了1天。
查了一下原因,也没有大任务阻塞集群,确实是大家的任务很多,一个接一个。
3. 解决问题
想要解决,从供需两端考虑:
- 供给端,扩展集群资源,这个我们正在做,升级到新集群。
- 需求端,大家任务多,集群资源有限,必然存在矛盾,这时可以评估任务的优先级,保证紧急任务优先处理,另一方面,总体任务数量和顺序优化后,我们也可以对单个任务的运行时间和效率进行优化,优化代码,做性能提升,从而提升整体运行效率。
要想优化代码,做性能提升:
- 会对用户有更高的技能要求,督促用户自我提高,在这方面TDU有也相关技能课帮助提高,但毕竟术业有专攻,是不是应该降低用户的技术门槛,让其更专注于在具体业务和场景中探索数据价值。
- 学习需要时间,且学无止境,不建议让用户承载过多的负担。
因此,代码性能提升我可能更倾向于平台侧智能管理,平台自动优化提升性能,并info给用户相关建议,感兴趣的用户可以参考info自我提升,进一步学习并反馈规则给TD规则库,形成闭环不断优化。
不感兴趣的用户可以直接忽略优化info专注业务,平台自动优化运行,做到无感体验,不知不觉中提升整个集群任务的运行效率。
4. 未来趋势
未来趋势也应该是朝“自动化”方向走。
现在我们Data ATM数据提取平台的运行机制类似,前端展示极简的界面,用户拖过简单拖拽完成任务的输入输出,后端是将用户选择的模块转化为SQL在提交到GP网关(Greenplum数据库)。
即降低用户的技术门槛,让其更专注于在具体业务和场景中探索数据价值。
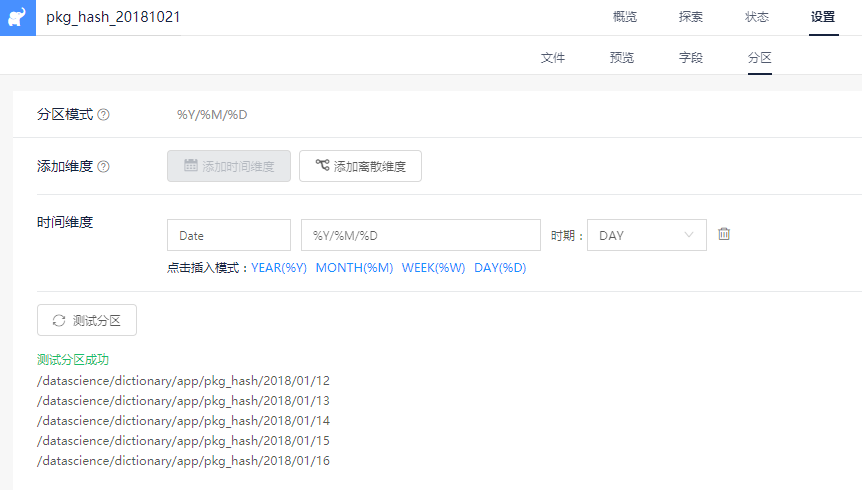
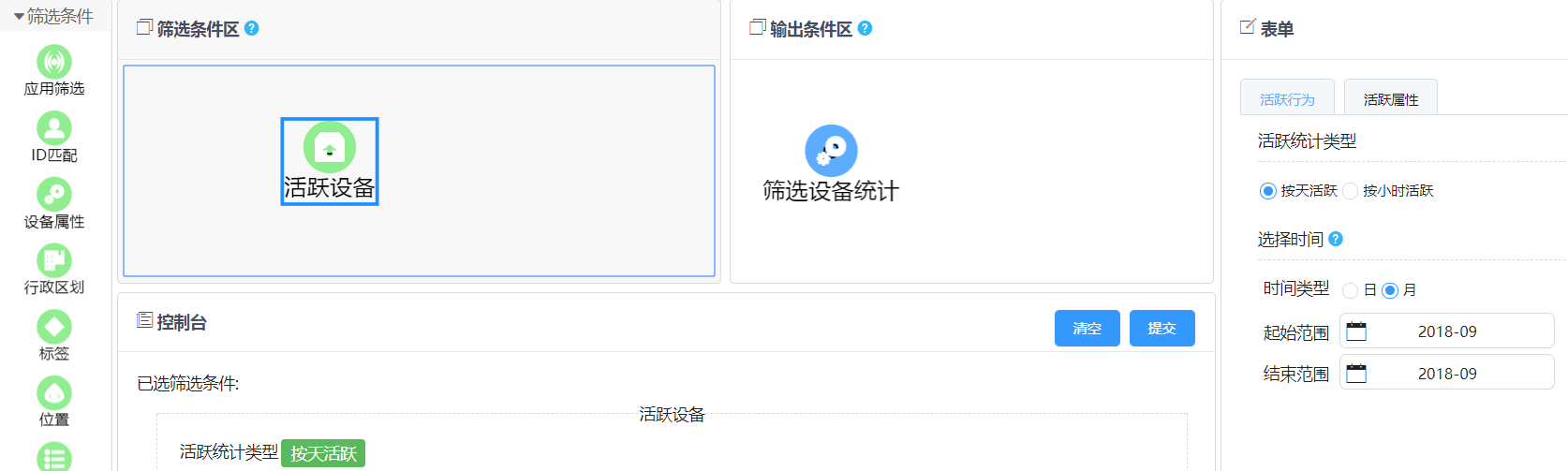
以计算2018年9月APP活跃设备数统计为例:
在用户操作层面,用户可以感知的就是简单拖拽活跃设备和筛选设备统计两个功能模块,然后选择时间2018-09,仅此而已,完成数据提取。
大大降低用户的操作门槛,这也是我们数据提取平台的初衷,让业务人员(销售、咨询等)在不懂SQL等语言时也能通过简单拖拽完成数据提取,让其更专注于在具体业务和场景中探索数据价值。
数据提取平台,作为一款数据产品,简单易用的背后是什么?
还是看这个例子:
作业转化为SQL语句,然后提交到GP网关,SQL语句大致如下:
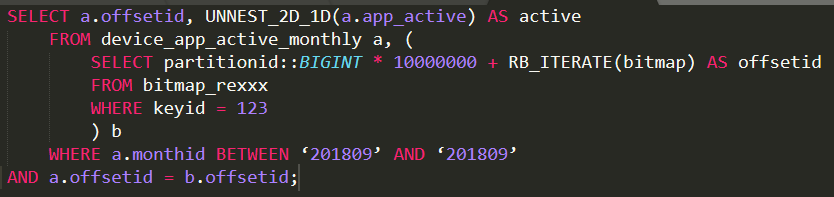
我们做了什么?
- 模块的封装,对应底层数据集,如活跃设备模块对应device_app_active系列数据集;
- 选项的封装,对应底层数据集相应字段,如2018-09时间对应数据集的monthid;
- 作业的封装,将作业所有条件转化为SQL语句;
- UDF(User Defined Function,用户自定义函数)的定义,复杂操作通过UDF实现并优化;
- 数据结构的定义,使用Bitmap,大大提升计算效率;
- 数据库选型,使用GP,提升整体效率。
- ……
好的工具,真正让用户易用,易用背后的逻辑我们沉淀,我们做的多,用户想的少。用户专注于数据业务,让业务方和工具平台都发挥最大的价值。
发生上述这些问题,有些可能是初出茅庐不谙世事的实习生,无经验,技能上的短板、未养成好的规范,也可能是现在玩转业务,熟练SQL的高级数据分析师,毕竟学海无涯,技能上的盲点永远存在。
还可能是用户有相关经验,但就是百密一疏,或者写代码一时随意, 最终结果将会因为一人疏忽造成整个集群任务队列效率低下,或者之后运用时出现意想不到的错误。
相关问题还是需要严格的约束,从平台和流程层面管控。
将数据探索任务中遇到的各种问题整理后,结合开源规范,一起作为我们TD的规则库。
综上在此严格定义一下CheckStyle:
CheckStyle将使用我们TD的规则库,通过平台和流程来保障代码质量,希望能尽早、尽快、无感解决故障隐患,以节约时间,提高效率,降低出错率。
短期内会通过代码样例,API半自动化实现,结合实践不断完善规则库形成闭环,最终实现自动优化。
二、为什么要做“CheckStyle”?
在说完什么是CheckStyle后,再来说为什么要做CheckStyle就很清晰了。
1. 动力
因为用户编写的代码可能存在质量差、性能低、不规范、语法错误等问题,通过CheckStyle可以尽早、尽快、无感解决故障隐患,以节约时间,提高效率,降低出错率。
同时在一定程度也可以提升用户的技能,完善我们TD规则库。
这也是平台“自动化”的重要一步。
2. 阻力
代码样例的梳理和准备。
规则库的制定,包括常见问题和开源规范的梳理。
产品研发侧的设计和研发,DataCloud已经停止迭代,综合考虑DSS需求池和研发资源的现状,现在有支持新集群等紧急需求在做,本需求相对而言优先级低一些,可以后续排期考虑。具体研发细节可以一起讨论。
三、怎么做“CheckStyle”?
我们不妨参考借鉴一下同行,挑选国内外的两款优秀竞品,这里选择国外的Dataiku DSS和国内的阿里云数加:
1. Dataiku DSS 实践
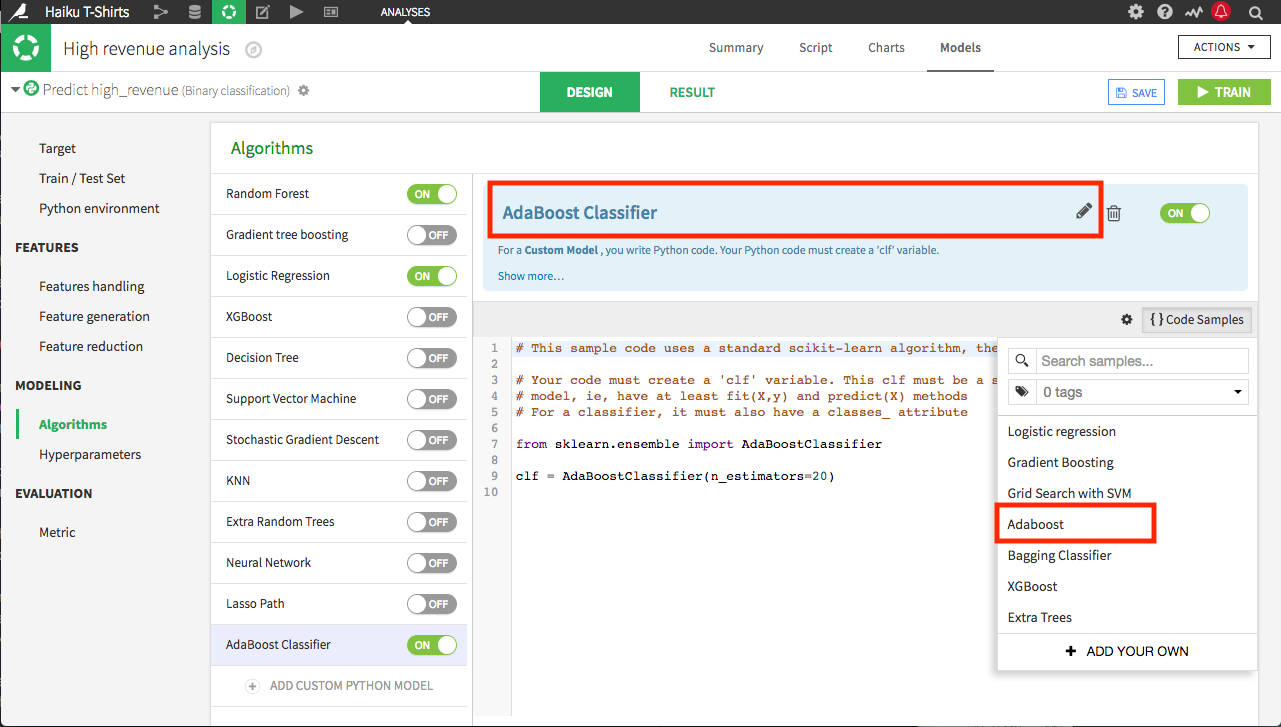
Dataiku DSS还处于一个相对早期的状态,在“CheckStyle”这一块的实践主要是Validate和code samples:
- Validate功能会检查查询语法错误和Schema的一致性问题。
- code samples功能则是插入代码样例,供用户参考编辑。
2. 阿里云数加 实践
我和阿里云的同学们沟通过,确实是踩过了很多坑,在推广过程中碰到大量的SQL优化问题,我们的结论也一致,无论是通过培训还是其他方式,其实都远没有系统固化规则更好,用系统流程化的方式解决问题是平台能够规模化的核心要素。
数加也确实走在行业的前列,基于IntelliJ IDEA开发插件MaxCompute Studio,MaxCompute 编译器是新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。
定制化开发,更加灵活,功能强大。
本篇主要介绍以下两点:
(a)MaxCompute Studio会对代码进行静态编译检查并给出修改建议,同时有计算健康分体系,提交有错误的脚本会被扣计算健康分,导致以后提交任务的优先级被下调。
(b)使用MaxCompute SQL,规范代码,预防预期外的错误,并对代码运算效率进行优化。
2.1 MaxCompute Studio
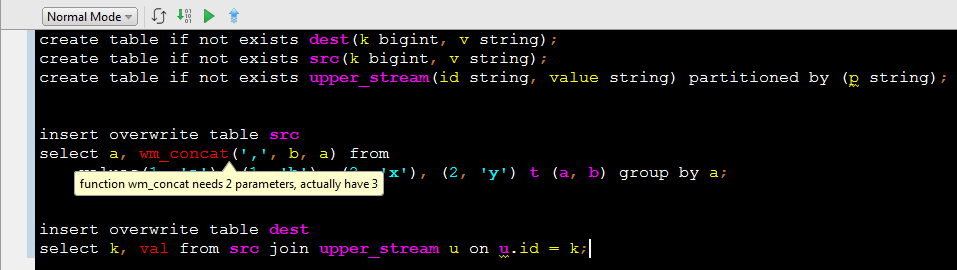
如上图,静态编译发现第一个 insert 语句中的UDF wm_concat函数参数错误。

如上图,鼠标停止在错误或者警告上,会直接提示具体错误或者警告信息。如果不修改错误,直接提交,会被 MaxCompute Studio 阻拦。
修改完毕后,再次提交,便可以顺畅运行。
2.2 MaxCompute SQL
基于SQL,使用MaxCompute SQL,规范代码,预防预期外的错误,并对代码运算效率进行优化:
(a)代码规范,如别名,即子查询必须要有别名。建议查询都带别名。
(b)预防预期外的错误,如精度问题,Double 类型因为存在精度问题,不建议在关联时候进行直接等号关联两个 Double 字段。一个比较推荐的做法是把两个数做下减法,如果差距小于一个预设的值就认为是相同,比如 abs(a1- a2) < 0.000000001。
(c)代码优化,如分区裁剪,对分区列指定过滤条件,使得 SQL 执行时只用读取表的部分分区数据,避免全表扫描引起的数据错误及资源浪费。
3. TD 实践
具体落地可以先从SQL语言及相关用户入手,后期视情况慢慢推广:
1. 代码样例的准备,结合日常工作中的常见作业,总结提炼几套常见的代码样例和常用语法。
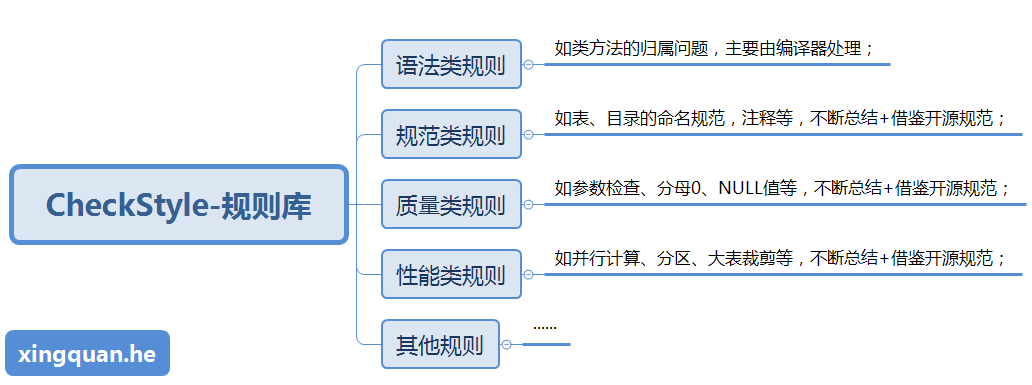
2. 规则库的制定,包括常见问题和开源规范的梳理,目前规则可以分为以下几类:
(1)语法类规则,如类方法的归属问题,主要由编译器处理;
(2)规范类规则,如表、目录的命名规范,注释等,不断总结+借鉴开源规范;
(3)质量类规则,如参数检查、分母0、NULL值等,不断总结+借鉴开源规范;
(4)性能类规则,如并行计算、分区、重复计算、大表裁剪等,不断总结+借鉴开源规范;
(5)其他规则。
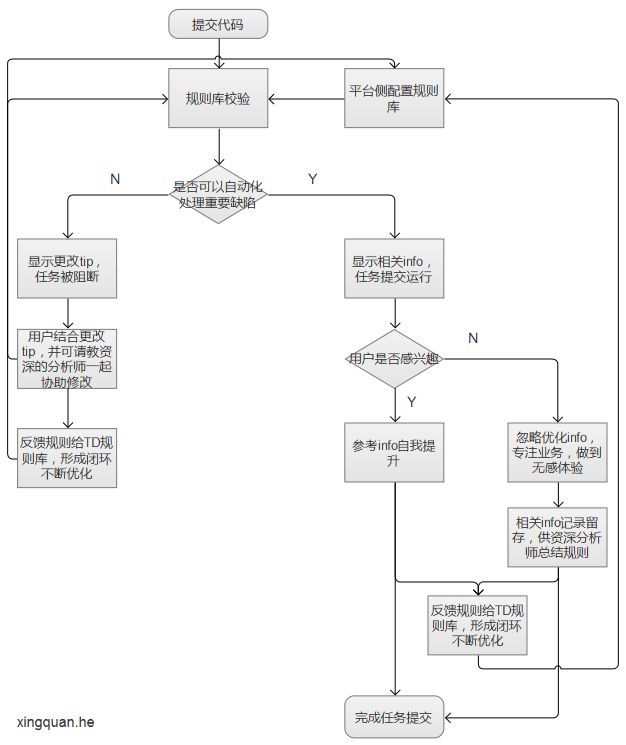
3. 产品研发侧的设计和研发,整体流程:
(1)平台侧配置好规则库;
(2)用户提交代码后,结合规则库进行校验;
(2.1)平台可以自动化处理重要缺陷,显示相关info,任务提交运行;
(2.1.1)感兴趣的用户可以参考info自我提升,进一步学习并反馈规则给TD规则库,形成闭环不断优化;
(2.1.2)不感兴趣的用户可以直接忽略优化info,专注业务,做到无感体验,相关info记录留存,供资深分析师总结规则并反馈规则给TD规则库,形成闭环不断优化;
(2.2)平台无法自动化处理重要缺陷,显示更改tip,任务被阻断,用户可以结合更改tip,并可请教资深的分析师一起协助修改,修复代码后才可提交,并在此检验规则,同时将规则反馈给TD规则库,形成闭环不断优化;
(3)完成任务提交,不知不觉中提升整个集群任务的运行效率,最终实现尽早、尽快、无感解决故障隐患,以节约时间,提高效率,降低出错率。从长远考虑,将自研和借鉴市场上的SQL Studio,定制化开发,更加灵活。
综合考虑DSS需求池和研发资源的现状,短期内可能还是:
- 准备代码样例;
- 在实战中总结规则,结合开源规范不断完善规则库;
- 对用户进行规则库和代码样例的相关培训,并结合TDU的优质教育资源,进行专项技能提升(备注:相关培训可以视用户的兴趣和时间酌情参与,但最好有几位资深分析师全程深入学习,以备在关键时刻提供相关指导);
- 同时根据规则在平台侧封装相关API供用户使用,结合实践不断完善规则库形成闭环,最终实现自动优化。
最后,引用曾鸣老师的一段话:
“未来创业很重要的一个方向就是把传统上大家认为必须由人来做的服务,把它中间越来越多的环节拆解,变成可以在线化、机器化、智能化完成的任务。”
个人认为,这也是数据工具产品的发展方向,复杂工作简单化,简单工作智能化。
以上便是我关于“CheckStyle”的初步想法,欢迎大家一起探讨。
作者:楚权(MR.Quan),东北大学2016届毕业生,TalkingData高级数据产品经理,热爱数据&产品&技术,不断挑战自我。
本文由 @楚权 原创发布于人人都是产品经理。未经许可,禁止转载。









真的好厉害!
看到这篇文章,直感叹自己,真的是老了。
哈哈,此话怎讲。
这么年轻,就已经做到这样了,我们80后快玩不动了。。。
向前辈学习~