
 起点课堂会员权益
起点课堂会员权益手把手教你从0到1搭建AB测试系统(核心架构)
本文对AB测试做了相关的整体介绍。什么是A/B测试?为什么要使用A/B测试?A/B测试的架构是什么?

最近一段时间在负责公司内部AB测试系统从0到1的搭建,在实现中踩了很多坑,也做了很多竞品分析了解国内外的竞品通用做法。
借此机会总结下这段时间的经验并分享给大家,希望能让看到这篇文章的人少走弯路。
之所以命名这个题目是因为我小学的时候曾学过一篇文章叫《手把手教你从0-1搭建传奇私服》,一不小心就暴露了年龄哈哈哈,跟着教程确实搭建成功并且还有附近的人进入游戏,可是当时自己的电脑作为服务器的性能太差,运营一天就关闭了,伤感。
分析大多是从产品经理需要了解的宽度和深度来描述,具体的技术不会涉及很多。AB测试的系统里面细讲起来会比较复杂,这一系列文章的主要目的就是掰开了揉碎了结构化的把这点事说清楚。
闲话少叙,进入正题!
一、什么是AB测试?
引用VWO对AB测试的解释:
A/B testing (sometimes called split testing) is comparing two versions of a web page to see which one performs better. You compare two web pages by showing the two variants (let’s call them A and B) to similar visitors at the same time. The one that gives a better conversion rate, wins!
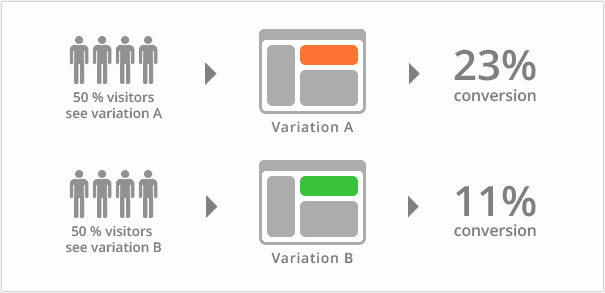
从图中可以看出,AB测试是对比两个或多个变体在同一地方好坏的方法,并且需要保证样本的同时和同质。
同时性:两个变体是同时投入使用的,而不是今天使用A变体,明天使用B变体,这样会有其他因素影响。比如,对于电商网站来说今天没有活动,而明天是双十一,在这个条件下我们不能判断变体B比变体A好。
同质性:两个变体对应的使用群体需要保证尽量一致。比如,想想一个极端场景:变体A里全是女性,变体B中全是男性,我们根本无法判断出来究竟是方案影响了最终效果还是性别。
为什么要使用AB测试?
先来看下最近挺火的一个概念:增长黑客。
俗话说:人挪活,树挪死。互联网想要成长也得挪一挪,我个人理解增长黑客的核心就是:变。
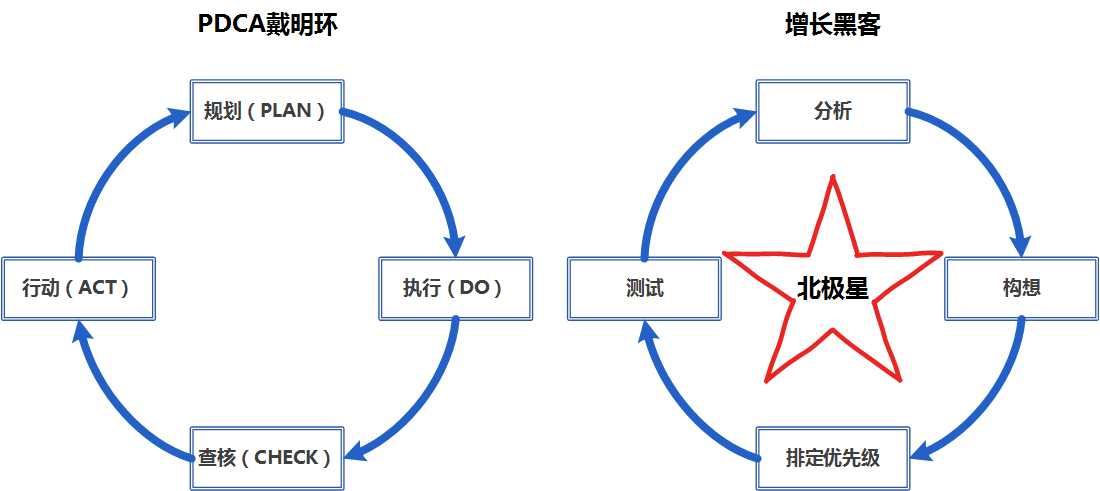
左边PDCA戴明环,这个四部的循环一般用来提高产品品质和改善产品生产过程。
右边是增长黑客环,是不是很像?
互联网的好处就是能对数据能够有更加深层次的挖掘和记录,经过对整体数据的分析提出能够达成自己的目标的解决方案,然后排期、测试,根据测试数据再进行分析依次循环,如下图:
观察力惊人的你一定还发现了增长黑客里边有个红色星星是干啥的?
增长黑客里叫北极星指标,他的作用是:
- 重点抓取;
- 明确优先级;
- 提高行动力;
北极星指标举例:

详细介绍北极星指标的文章可以看这篇:如何选择正确的数据指标?
上述说了这么多概念,主要是为了让大家对AB测试的背景有个基础的认知,接下来重点说AB测试。
二、AB测试的架构
我会从四个方面:管理后台、分流引擎、结构数据、对接方式来解构如果想要做一个AB测试系统需要准备哪些。
这篇文章的目的是为了让大家有一个宏观的了解,详细的功能性阐述会放在后续的文章中。
下面这张是宏观的脑图:
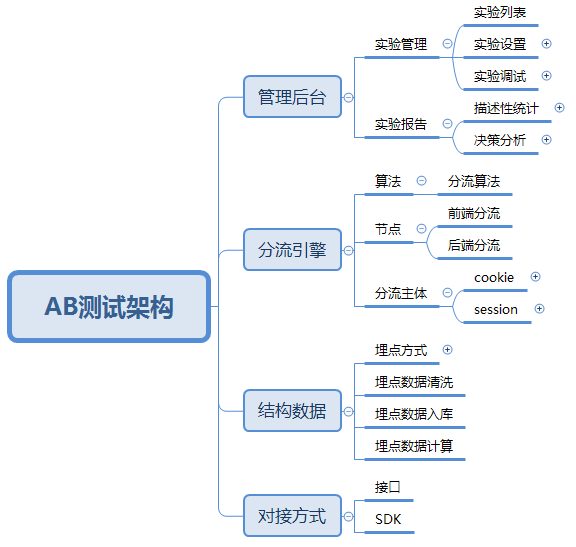
1. 管理后台
我们习惯定义每一个AB测试都属于一个独立的实验,方便管理和查看统计数据。
在管理后台当中可以创建、管理实验,还可以在实验进行中、结束后查看实验数据。
举例国外和国内分别做的比较好的AB测试平台的实验架构:
国外:Google 的 Optimize。Google的实验架构一共有五层:
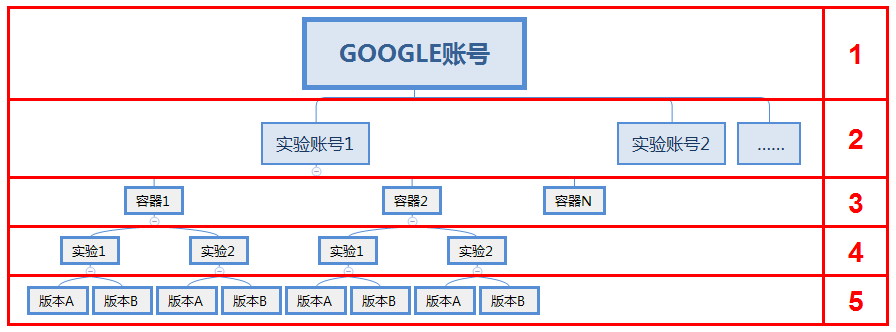
国内:吆喝科技。吆喝科技的实验架构一共有四层:
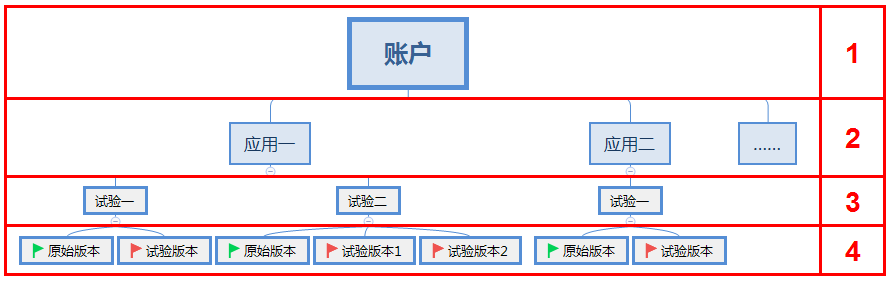
为什么有这么多层?
其实真正看实验的是最下面那两层,实验下面绑定不同的变体(或者叫版本)。
上面的层是为了更好的管理账号,他们作为商业软件需要更灵活的适合不同公司的情况,各位按需即可。
2. 分流引擎
AB测试一般又称为桶测试,为啥叫桶测试呢?奥秘就在分流这块!
先解释一下变体和桶的关系:
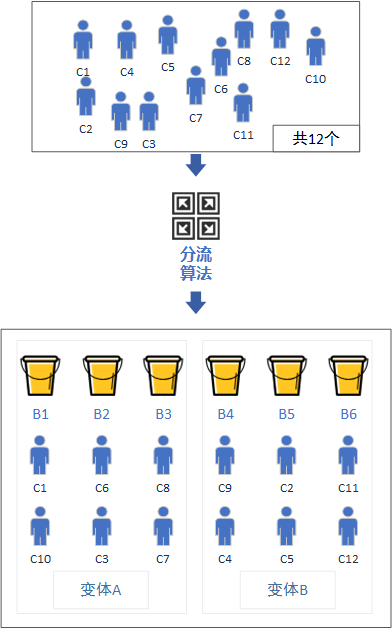
为了方便计算,假设现在有12个人(Customer),我们给12个人进行编号,C1~C12;有6个桶(Bucket)我们编号为B1~B6。
每个用户在访问实验时,会先进入到分流算法中,由算法来决定分到哪个桶里面,都分完后最理想的是每个桶里正好有2个人。(实际上基于大数定律原理,数据量越大分配的会越平均)
那么现在,假设每个变体的流量是50%,变体A我们假定对应的是三个桶B1、B2、B3桶,变体B也是对应的是B4、B5、B6桶。
实际上有没有发现,变体A选中的概率是50%,所以只要对应任意三个桶即可:
- 算法:保证分每个桶分到的越随机越平均越好。
- 节点:前端分流和后端分流
- 分流主体:Cookie、Session
国内的AB测试一般采取的是Cookie分流,Google采取的是Session分流。
3. 结构数据
- 埋点方式:主要是数据的采集和上报
目前市面上常用的埋点方式为:代码埋点、可视化埋点、全埋点(或者无埋点)
- 数据仓库:埋点数据的清洗、计算、储存。
结构数据的准确性决定了,AB测试数据分析准确性,如果你所在的公司埋点没有搞起来,并且无法保证数据的准确性,我劝你还是不要做AB测试浪费时间 [尴尬又不失礼貌的微笑]。
4. 对接方式:业务方接入到AB测试的方式
对接方式更偏技术,但是从产品的角度需要知道不同方式对AB测试竞争力的影响。
如果是商用的AB测试软件SDK肯定是首选,因为你不可能每次都与业务方对接接口,并且SDK里面是会包含埋点的。
如果只是内部使用,并且是初步搭建AB测试系统,最好还是选取接口的方式,方便快捷并且比较稳定。
5. 从访问到产生实验统计数据的流程
上面是拆分了不同的模块做了简单的介绍,下面介绍一下用户从访问到产生实验统计数据的整个流程。
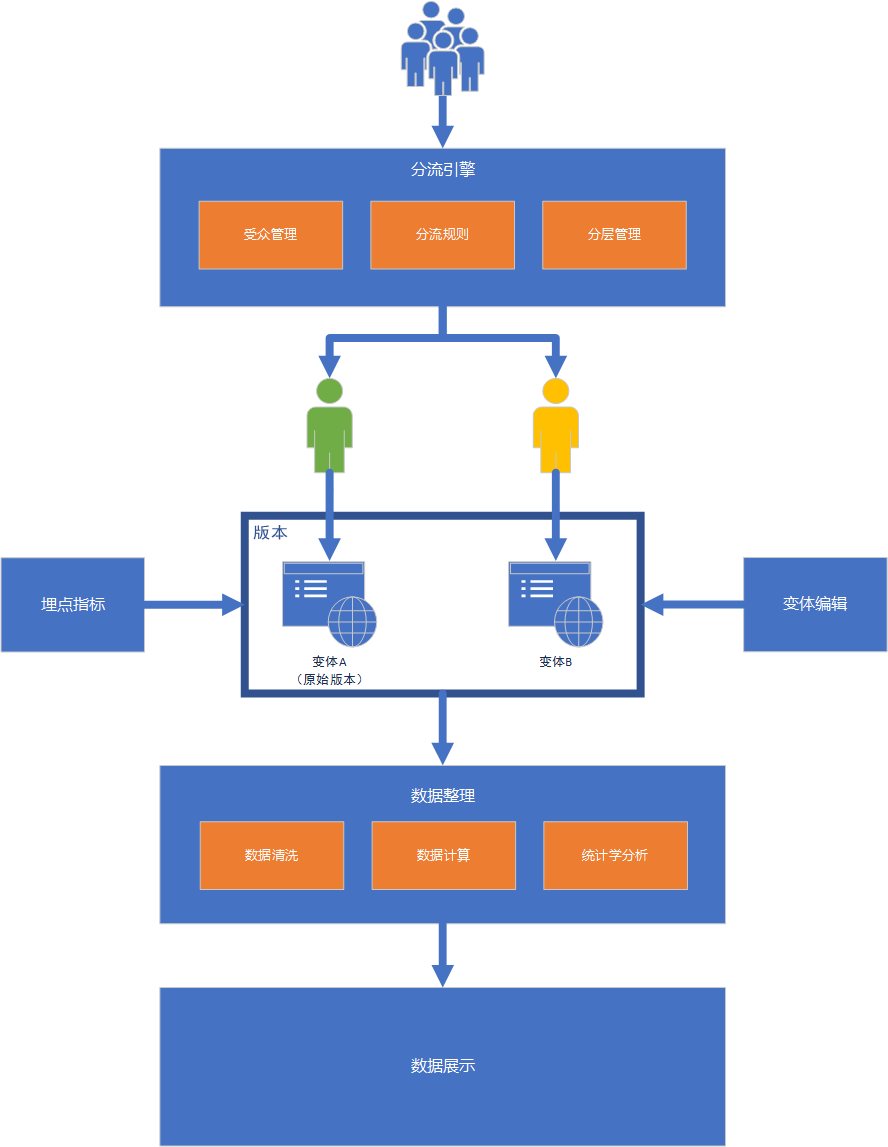
1. 分流引擎:当用户来到实验时会通过分流引擎把流量一部分分到变体A,一部分分到变体B。
注:在分流引擎中会有一些模块拆分,这些会在后续的文章中详细讲解。
2. 变体展示:为了方便理解,假设我们本次实验每个变体流量均为50%,则所有访问本次实验的将会有50%的概率看到变体A,有50%的概率看到变体B。
注:实验对应的每个变体的流量是可以通过管理后台进行配置的。
3. 埋点指标:业务端或者AB测试服务提供端采集预先定义好的“埋点指标”。埋点指标的意思是,能证明此是否达成了所设定的北极星指标的具体数据。
4. 数据整理:针对埋点指标进行清洗、计算。
5. 数据展示:对应到管理后台中是实验报告,是对本次实验结果的集中展示。包括描述性统计分析和决策统计分析。
6. 变体编辑:对不同变体实际功能需求的开发。这个模块是发生整个实验开始之前,需要定义好每个变体究竟是以什么方式展示给参与实验的用户。
比如:变体A用红色按钮,变体B用绿色按钮。
如果把所有的信息全部都写进一篇文章可能大家对这篇文章剩下的操作就只剩收藏了,加之平时写文章的时间毕竟也比较有限,所以就把它拆分成了一个系列。
本次只是先将AB测试做整体介绍,后续再分开做某一模块的详细介绍。大家可以在留言中给自己感兴趣留言,疑问比较多或者更多人感兴趣的地方会优先更新。
万一此篇文章看的人很少也没人回复,只能按自己的节奏逐步更新,就全当总结归纳罢了。
水平有限,欢迎各位大神来砸场讨论!谢谢!
本文由 @ 任秀明 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









SDK里面都包含啥呢?
新手在,看不明白,期待大神的进一步更新。
写的太好了,啥时候更新
老哥有时间可以更新2了
感谢分享!另外请教一下,描述性统计和决策统计这块,一般的开展维度有哪些呢?按我理解:
1)描述性统计:更多的是对实验设定的指标做基础值观测,包括组内指标的众数、分位数、方差等
2)决策统计:基于上面的数据对比,增加一个显著性校验,基于校验结果来说明实验和参照组哪些指标差异较大
为什么就没有第二篇啦~
分流算法可以补充下吗,我们目前是对移动设备做哈希,但还是会有偏差,不知道是不是样本量的问题
试验的状态怎么搞?
老师好
赞,坐等更新
想问下如果ab测试的是功能模块,那怎么上架appstore?一直没明白,求解答,谢谢
好文!点赞,很干货,楼主在自己公司内部搭建自家的AB测试,想必公司规模达到数量级了。
不过,一般团队来说很难有精力和资源来搞自己的AB测试系统,推荐下Testin云测A/B测试:http://ab.testin.cn,标准版免费,不用自己折腾啦 😉
给机智的小编加鸡腿
啥时候更新呀,对分层管理和埋点最感兴趣了
老师,请教下,AB测试,最主要就是变变变,提高转换率,完成北极星指标?
老师不敢当哈。
功能那么多,资源又有限,不可能一步到位,需要借数据证明是增长、降低还是不变,从而给下次迭代提供参考。
如果你是电商行业,你的北极星指标就是转化率,是GMV,这要看整个公司的战略方向。
不停的实验,不停的朝着北极星目标前进。
写的不错。中小电商企业有必要做 AB测试吗?
公司的能力:从统计学角度来讲,只要参与实验的独立用户超过1000,实验周期15天,实验结论是可信的。所以对公司的用户量级是有要求的。
公司的意愿:增长黑客绝不是哪个员工拍脑袋想做就能做的,得是公司老板有数据驱动的意识。
公司的资源:公司愿意投入成本去做这件事,并且得有耐心。
独立用户超过1000,这个1000是怎么定的?