
 起点课堂会员权益
起点课堂会员权益工业开源实时数据库浅析
在工业互联网快速发展的前提下,生产现场投放了大量的设备,比如监控、传感器等等,这些设备产生的实时数据能反映设备的情况和生产进度,而对这些数据的处理和分析,则需要数据库的支持。

在工业领域, 生产、测试、运行阶段都可能会产生大量带有时间戳的传感器数据,这都属于典型的时序数据。时序数据主要由各类型实时监测、检查与分析设备所采集或产生,涉及制造、电力、化工、工程作业等多个行业,具备写多读少、量非常大等典型特性。
写入吞吐低:单机写入吞吐量低,很难满足时序数据千万级的写入压力存储成本大:在对时序数据进行压缩时性能不佳,需占用大量机器资源维护成本高:单机系统,需要在上层人工进行分库分表,维护成本高查询性能差:查询速度慢,尤其是海量实时数据的聚合分析性能差
一、工业互联网时序数据库的需求与痛点
主要问题可以汇总如下:
- 写入吞吐低:单机写入吞吐量低,很难满足时序数据千万级的写入压力;
- 存储成本大:在对时序数据进行压缩时性能不佳,需占用大量机器资源;
- 维护成本高:单机系统,需要在上层人工进行分库分表,维护成本高;
- 查询性能差:海量实时数据的聚合分析性能差。
需要支持的特性:
- 功能稳定
- 高效的数据写入
- 高效的数据查询,包括最新数据和历史数据
- 可云化部署
- 可私有化部署
- 线性扩展
- 高可用
- 便于连接大数据平台
二、数据源需求
从数据源角度,设计人员可以从下面几个角度分析在目标应用系统里面的适用性。
- 总体数据量巨大
- 数据输入速度偶尔或者持续巨大
- 数据源数目巨大
三、架构
随着时序数据库产品的引入,减少了组件数量,降低架构的复杂度,同时降低了存储成本,提升业务响应实时性,降低了人员要求,释放了业务创新能力。
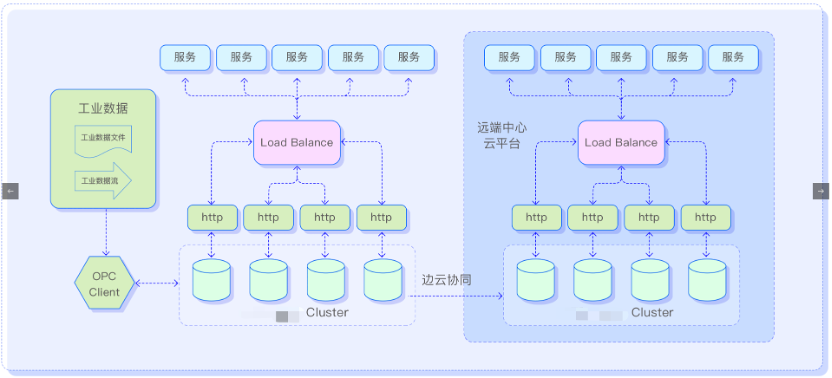
四、收益与价值
高性能,可以支持百万级别的并发写入、万级的并发读取,大量聚合查询时依然有高性能表现高可用,可支持集群部署,可横向扩展,不存在单点故障,为生产环境稳定运行提供基础低成本,数据库对硬件资源要求低,数据压缩率高,平均至少节省 70% 的硬件资源充分利用时序数据的特点,高度一体化,具备消息队列、流式计算和缓存的功能,大幅简化架构易上手,使用 SQL 进行数据库操作,简单易学,支持复杂查询,减少开发难度和运维压力。
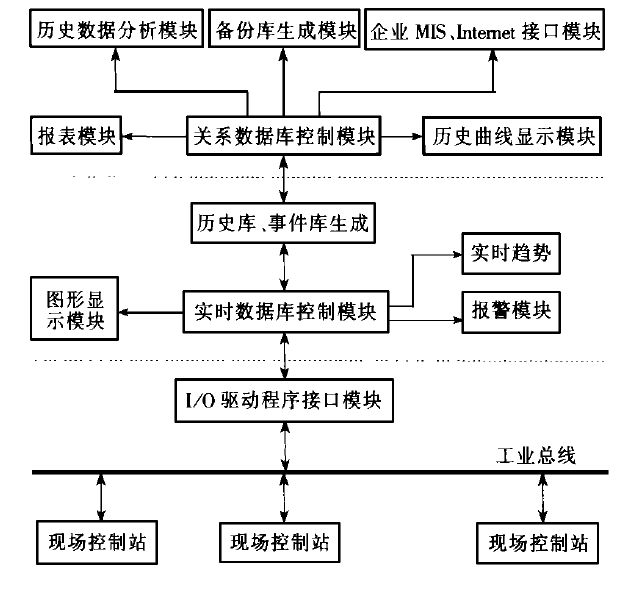
五、系统分析
实时数据库是数据和事务都有定时特性或显示的定时限制的数据库在结构和功能上是根据实时数据库的性质以及实时数据在使用方式上的特点而设计的其中一些功能是标准的关系型数据库所不具备的。在本系统中根据实时数据库的结构和功能特点将实时数据库设计分为实时数据库结构设计和实时数据库管理程序设计两部分。
六、收益与价值
- 高性能,可以支持百万级别的并发写入、万级的并发读取,大量聚合查询时依然有高性能表现
- 高可用,可支持集群部署,可横向扩展,不存在单点故障,为生产环境稳定运行提供基础
- 低成本,数据库对硬件资源要求低,数据压缩率高,平均至少节省 70% 的硬件资源
- 高度一体化,具备消息队列、流式计算和缓存的功能,大幅简化架构
- 易上手,使用 SQL 进行数据库操作,简单易学,支持复杂查询,减少开发难度和运维压力
七、行业应用
在工业互联网快速发展的大背景下,工业生产现场投放了大量的设备传感器和监控系统,二者提供的实时数据能够反映设备的状态和生产的进度,其中的大多数据都是按照时间顺序形成的实时数据,这些海量实时数据有着多样化的分析需求和重要的参考价值。
未来希望数据库可以提供更复杂的流式计算、查询分析以及监测预警等能力,可以为产品的可视化运维、预测性维护、远程智能管理等方面提供数据依据,从而降低人员、时间等成本,加速工业化与信息化的深度融合,促进复杂重型装备制造业的转型升级,产生社会经济效益。
本文由 @Nate 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


