
 起点课堂会员权益
起点课堂会员权益
帮你梳理与“搜索”相关的后台流程
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..“搜索”,对于前台操作的用户来说,只是一个极其简单的动作。但对于后台来说,则需要拆成“如何才能支撑‘搜索’这个动作?”以及“我们要展示给用户哪些元素?”两个方面来考虑,才能更好地完成这个动作。

对于有确定购买目标的用户来说:如何能在海量商品中快速找到心仪商品呢?
搜索是必不可少的渠道,也在电商平台中占据着举足轻重的地位。
前端用户只是一个简单的“输入+搜索”的操作,后台就需要拆分出:“哪些逻辑可以用来支撑?”以及,“我们应该给用户展示哪些元素?”
今天,我们就来聊聊与“搜索”相关的后台流程。
一、搜索结果页布局
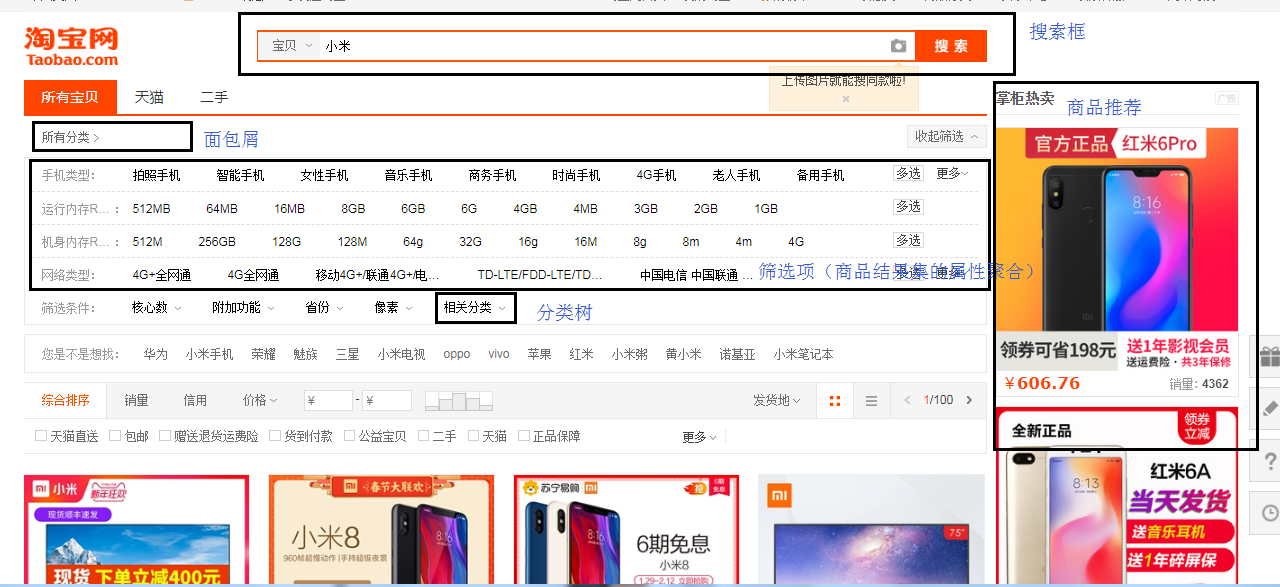
PC端的搜索结果页都包含哪些元素?
参照如下图:
淘宝PC端搜索结果页
- 搜索栏:用户输入query进行检索,是用户寻找商品的一种快捷入口。从用户输入到展示商品列表之间的检索过程,也是本文重点要讲的。
- 筛选项:是商品结果集的属性的聚合,给用户提供在商品结果集内进一步按照各属性维度单独筛选的功能。
- 分类树:query相关的分类,以分类树的形式展现给用户。比如:输入“小米”既属于“3C数码”,又属于“粮油米面”。
- 面包屑:展现当前商品列表所属的分类路径,方便用户跳转至各上级分类,同时可在该分类路径下进一步检索,扩大或缩小检索范围。
- 商品列表:query搜索的结果集,涉及到商品的排序展示,是下文的重点。
- 商品推荐:根据用户当前或者历史的检索行为,进行商品推荐。
二、搜索流程框架
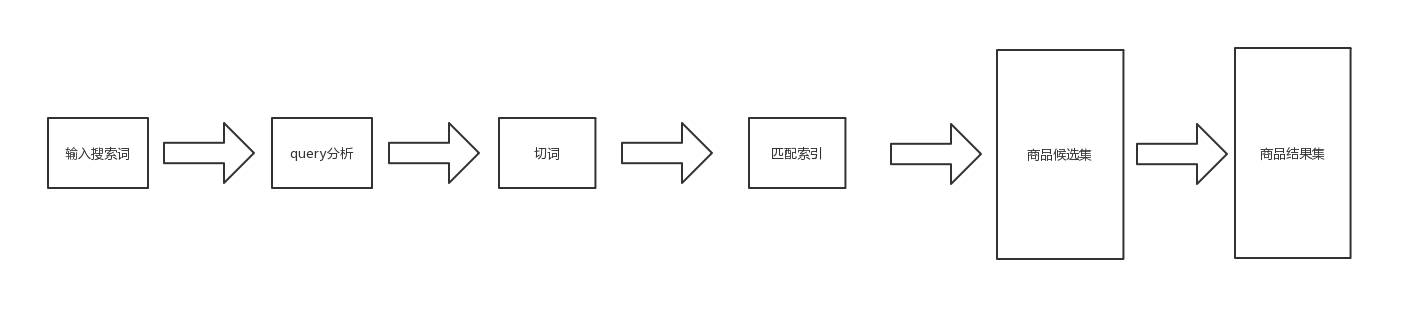
1. query分析
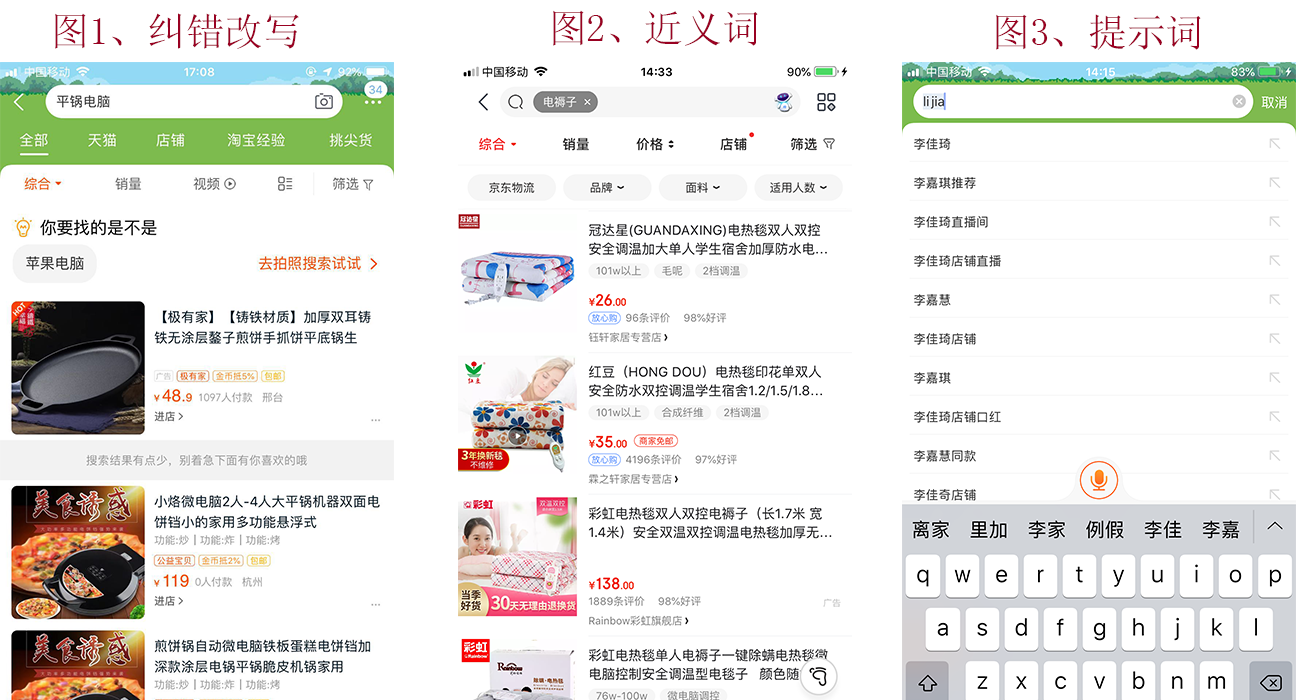
用户输入query,系统需要对query进行预处理,包括:改写纠错、近义词、query补全。
- 比如:用户输入“平锅电脑”,通过分析判断,用户可能想搜索的是“苹果电脑”。
- 比如:搜索“电褥子”,也可以匹配“电热毯”。
- 比如:最近抖音用户李佳琪以推荐口红走红,在TB输入“李佳”就有对应提示。
好的产品应当是让用户自行选择,而不是强制改写用户的输入。
有搜索结果则优先展示搜索结果,同时提示纠错后的词语供用户一键搜索。纠错和补全可以看作是与query做模糊匹配,从而返回一个相似的单词集合。
Apache开源的全文检索引擎工具包——lucence,就提供了该功能点的实现。大致思想是:给定一个包含大量正确单词的词典集合,与用户的query进行匹配,计算出编辑距离,距离越小则越相近。
编辑距离:是两个单词之间转化的最少变化次数。
比如:字符串“abcd”变为字符串“bcde”,需要删除a再插入e编辑距离为2。
编辑距离的定义简单,但是关于“如何降低算法复杂度?”,这个比较偏技术。产品同学了解思想即可,对技术有热情有兴趣的同学也可以研究下Lucence内的实现。
2. 分词
当用户的搜索词比较长,则需要将query切分成一个个单元。
比如:用户搜索“夏季仙女连衣裙”,如果用整个字符串做匹配的话,召回率就会很低。所以,需要分为“夏季”+“仙女”+“连衣裙”。
市面上有开源的分词工具包可以直接使用,比如:IKAnalyzer中文分词器。
但是,不同的分词工具运用的分词算法不一。以机械分词算法为例——一种基于字符串匹配的分词方法,它可将待分析的字符串与机器词典中的词条进行匹配,假如在词典中找到某个字符串,则匹配成功。
除了通用词条,跟产品业务相关的词汇我们也需要尽可能的补充完善进词典。
这里我们介绍一下机械算法中的“正向最大匹配算法”和“逆向最大匹配算法”。
正向最大匹配算法:从左到右逐个组合扫描词与词典中的词条进行匹配,如果匹配成功,则把这个词切分出来,继续匹配剩余的字符串。
那么如何做到最大匹配呢?
让我们来看一个例子:
待匹配词条:string data=“仙女连衣裙夏季”,通过字符串截取函数截取对应需匹配的词条。
词表:array dict=[“仙女”,“仙女连衣裙”、“连衣裙”、“夏季”]。
从data[1]开始扫描,到data[2]的时候,发现:“仙女”在词表中有,但是还不能将该词切分出来。因为“仙女”是dict[2]“仙女连衣裙”的前缀。
继续扫描发现:data[5]在词表中有,但是还不能切分出来。
扫描data[6]发现:在词表中没有“仙女连衣裙夏”,这个词条也不是任何一个词的前缀,则切分出前面最大的词——“仙女连衣裙”。
以此类推,最后得到的词组为:[“仙女连衣裙”,“夏季”]。
逆向最大匹配算法:先定义一个最大分割长度5,从右往左开始分割。
以data[5]表示“连衣裙夏季”,data[4]表示“衣裙夏季”。
从data[5]开始扫描,若不在词表中,去掉最左边一个字,得到data[4],直到发现data[2]在词表中,将词语拆分出来,此时待匹配词条变为“仙女连衣裙”。
匹配data[5]时,若发现词表中有,则切分出来,分割结束,得到的词组为[“仙女连衣裙”,“夏季”]。
3. 索引匹配
索引:可以理解为是一种数据结构,是基于数据表中的某一列创建的,存储了列值以及和表行的对应关系。
例子我就不多说了,不清楚的同学可以自行谷歌。如果没有索引,在查询时,需要对数据库表做全表扫描并做文本匹配,这是不现实的。
创建商品后,系统会将商品名称分词并且建立索引形成索引库,必要时也可以将商品类目、品牌引入索引库中。将用户query的分词词组与索引库进行匹配,得到商品候选集。
4. 商品侯选集
首先,匹配出query相关的类目以及与query文本相关的所有商品,以类目+文本为最高优先级对商品进行排序,类目和文本相关性一致的则根据权重排序。
影响权重的因子包含:“商品近30天的销量”、“评论平均分”、“上线日期”、“店铺得分(文描,评论,物流)”等。
给所有因子影响权重的比例定义一个系数,需要根据实际业务运营策略制定。
比如:运营希望多曝光一些服务优质的店铺,则店铺维度的因子权重比例就高。如果运营想多曝光一些爆款商品,则提高商品各项因子的权重比例——截取商品候选集的topN做综合排序得到商品结果集。
如下图:
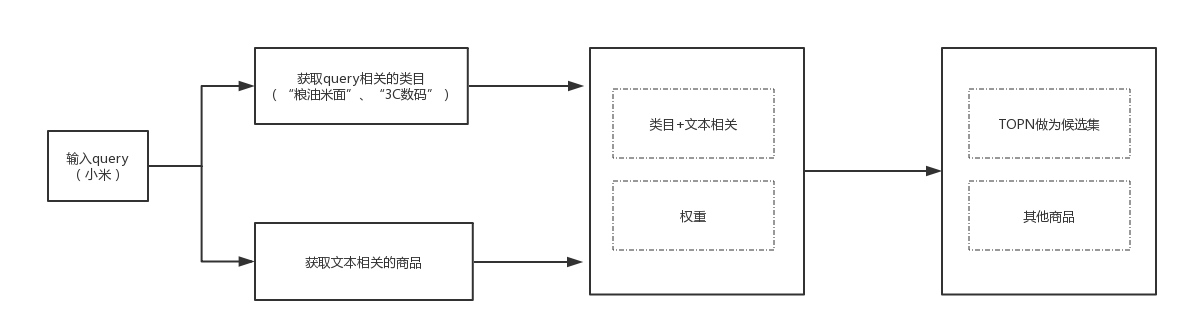
商品候选集选取流程
5. 综合排序
从商品列表中提取出三部分 :
- 同类目人工干预置顶
- 售罄或差评商品沉底
- 其他部分待排序。
通过点击率预估模型对待排序商品重排序,并区分同类和其他类目。
影响点击率预估模型的成分有:
- 店铺因素(店铺近期订单量,评分,物流,PV,UV)
- 商品因素(销量、价格,与同类商品价格差)
- 用户本身特征(近期购买,浏览,收藏)
- 实时特征(当天商品被浏览,加购等)
- 季节因子
对同类目的商品优先提取品牌和商品词符合的做前置(比如搜索小米插座 品牌:小米,商品词:插座)。
最后合并各个分段结果如下图:
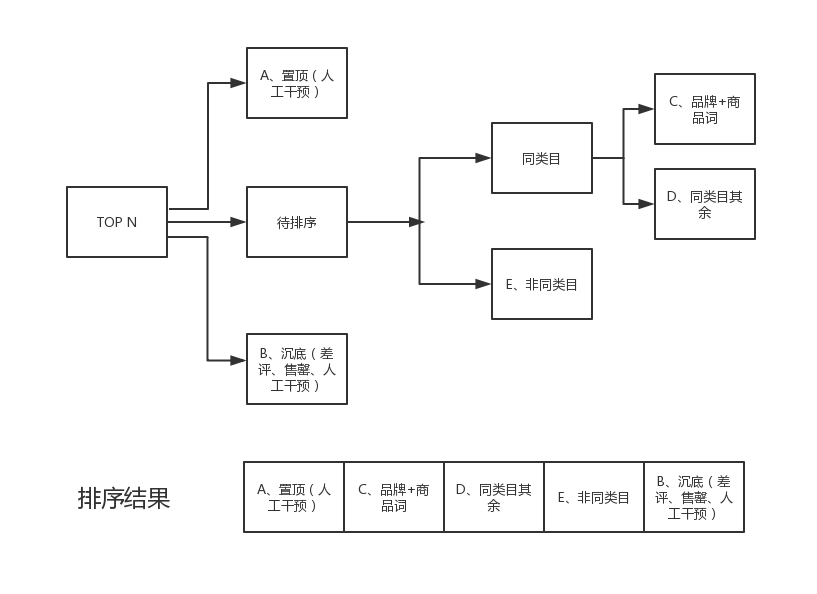
综合排序流程
以上梳理了搜索流程中的一些关键节点,而如何提高搜索引擎的用户体验呢?
核心和难点在于:理解用户,进而高效的帮助用户找到目标商品。
这就离不开运用各种机器学习和自然语言处理技术进行语义分析,不断尝试各种搜索引擎排序算法帮助用户找到更优质的商品。
通常大型电商平台的搜索团队都是偏技术配置,业务型的产品虽然不需要深度学习算法与数据模型相关的知识,但是基本概念和思想最还好是要掌握。
以上是我的分享,欢迎交流。
本文由 @雷大胖子 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议











可以请你喝杯咖啡,咨询几个问题吗?我是一个在三线城市的开发,有些电商后台封面的一些问题甚是困扰
请问一下这些东西应该是产品经理来设计,还是开发自行解决?
请问老师,分词得到的词组中,各个词是否还有权重之分?以及下面的问题,类目和文本相关性是如何判断?
请教一下您,类目和文本相关性如何判断
es使用的文本相关性算法TD/IDF
请教一个问题,电商的首页搜索,输入关键词后,进行匹配的时候,我们程序匹配的商品名称。请问商品类别的值及产品属性值是否可以参与匹配,如果参与,三类结果应该如何排序啊
可以,其他属性只要建好索引,搜索的时候都可以匹配。 结果集排序就要看你们自己的策略了,有些以类目为最高优先级。
还是困惑,能否举一个普遍的排序逻辑啊,希望能加我微信:jiyuetian1pk110,一起交流下