
 起点课堂会员权益
起点课堂会员权益
终极设计师指南:语音用户界面(VUI)
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..一个日益数字化的世界意味着,我们在设备上花费的时间可能比在彼此上花费的时间要多。而语音交互是否会成为我们与世界互动的主要方式呢?

“设置早上7:15的闹钟”
——“好的,呼叫Selma Martin 中”
“不是不是!是设置早上 7:15 的闹钟”
——“很抱歉。我不懂您在说什么。”
“哎~”(开始手动设置闹钟)
我们的声音形形色色,并且复杂多变。语音命令甚至更难处理——在人与人之间尤其如此,更不用说计算机了。我们构思、进行文化交流,以及我们使用俚语和推断意义的方式……所有这些细微差别都会影响我们语言的理解和表达。
那么,设计师和开发如何应对这一挑战呢?怎么才能建立人和AI(人工智能)之间的信任?
这时候语音用户界面(VUI)就有了用武之地。语音用户界面(VUI)主要是辅助用户的视觉、听觉和触觉,完成用户与设备之间的语音交互。
简而言之,语音用户界面(VUI)可以是任何事物,从听到您的声音时闪烁的灯光到汽车娱乐控制台。
请记住,语音用户界面(VUI)无需可视化界面,它完全可以是听觉的或触觉控制的(例如:振动)。语音用户界面(VUI)主要是辅助用户的视觉、听觉和触觉,完成用户与设备之间的语音交互。
虽然VUI种类繁多,但是可共享同一套设计规范,这套设计规范影响可用性。我们可以一起探讨这套规范,因此作为用户,可以分析日常的VUI交互;作为设计师,可以创造更好的体验。
一、发现——约束条件、依赖关系以及用例
我们与世界的的互动方式受到技术、环境以及社会限制的极大影响,例如:我们处理信息的速度。
将信息转化为行动的准确性,用来传达信息的语言/方言,以及该行动的接收者(不管是我们自己还是其他人)都会影响我们处理信息的数据。
在我们深入研究交互设计之前,首先我们必须要定义语音交互环境背景的构成。
1. 确定设备类型
设备类型影响语音交互的方式、原始语音输入和语音范围。
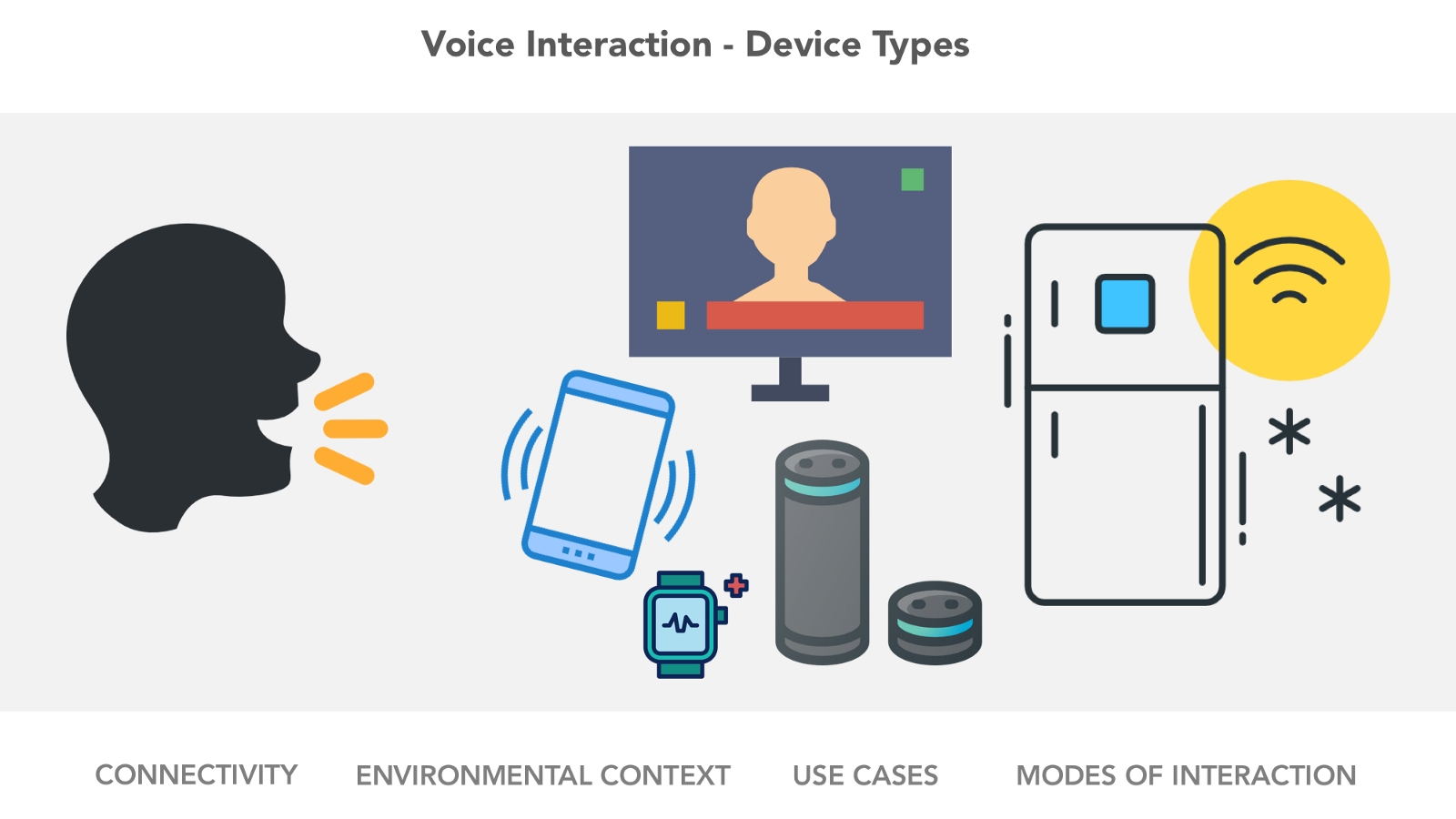
移动设备:
- 苹果、Pixels、Galaxies
- 连接——蜂窝网络、Wi-Fi、设备配对
- 环境背景对语音交互有重大影响
- 用户习惯于使用语音交互
- 允许通过视觉、听觉和触觉反馈进行交互
- 在各种模型中建立标准化的交互方法
可穿戴设备:
- 特定于用例,通常面向特定用例,如手表、健身带,或智能鞋
- 连接——蜂窝网络、Wi-Fi、设备配对
- 用户可能习惯于使用语音交互,但这种交互在设备之间是非标准化的
- 一些可穿戴设备允许用户通过视觉、听觉和触觉反馈进行交互——但有一部分没有明确的交互,比较被动
- 通常用户交互和数据消费都依赖于连接的设备
固定连接设备:
- 台式机、带屏幕的设备、恒温器、智能家居、音响系统、电视
- 连接——蜂窝网络、Wi-Fi、设备配对
- 用户习惯于在相同的位置使用这些设备并在习惯的基础上进行设置
- 类似设备类型之间的准标准化语音交互方式(台式机 VS 连接集线器,就像Google Home / Amazon Alexa VS 智能恒温器)
非固定计算设备(非电话):
- 笔记本、平板电脑、转发器、汽车信息娱乐系统
- 连接——无线、有线(不常见)、Wi-Fi、设备配对
- 通常主要输入方式不是语音
- 环境对语音交互有重大影响
- 通常在不同的设备之间有非标准化的语音交互方法
2. 创建用例矩阵
语音交互的三个主要用例是什么?该设备是否有一个主要用例(如健身追踪器)?或者是否有组合用例(如智能手机)?
创建一个用例矩阵是非常重要的,它将帮助你确定:
- 为何用户与设备交互?
- 交互的主要方式是什么?
- 什么是次要的?
- 什么是好的交互模式?
- 什么是必不可少的?
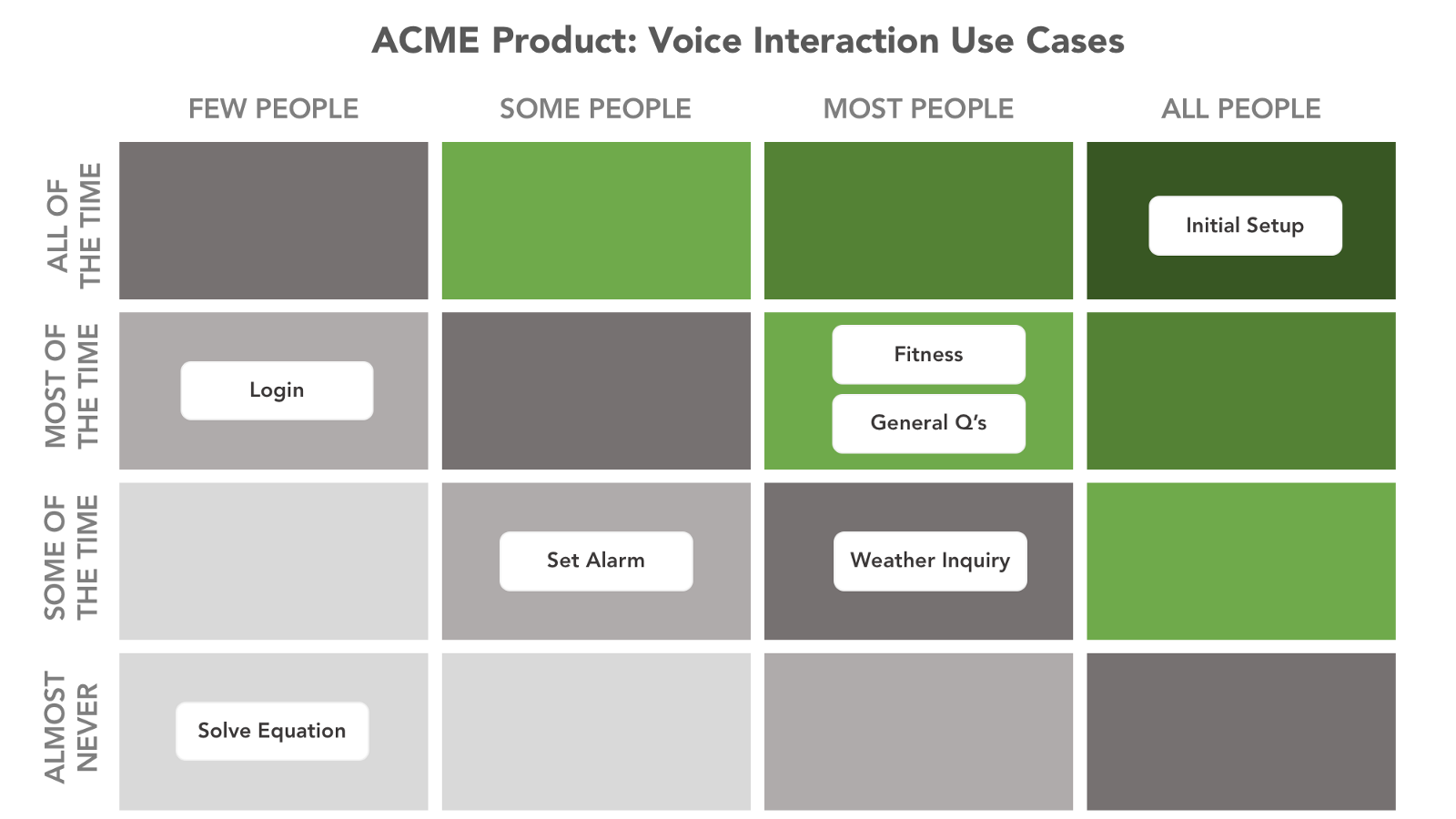
你可以为每种交互模式创建用例矩阵。当应用于语音交互时,矩阵将帮助你了解用户当前使用或想要使用语音与产品交互的方式,包括他们将使用的语音助手的位置。
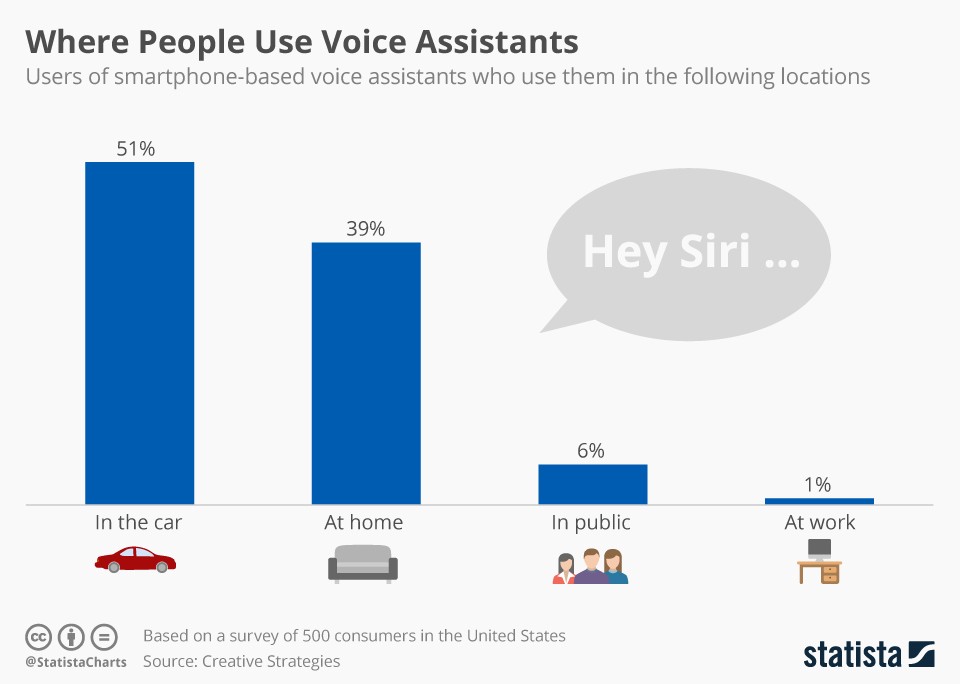
3. 按顺序排列交互模式
如果实施用户研究去验证用例(抑或是可用性或定性/定量分析),那么通过给交互模式排列次序等级就变得十分有必要了。
如果有人告诉你:“如果我能跟电视交流让它换频道,这真的是太酷了!”
那么你真的需要深入了解:他们真的会用么?他们了解这些限制吗?他们真的知道自己使用这些功能的倾向吗?
作为设计师,必须了解用户胜过他们自己。你必须质疑他们交互的方式,因为有替代方案可选。例如:假设我们正在研究用户是否会与电视互动。在这种情况下,可以大胆的假设语音交互只是诸多交互手段之一。
用户有多种手段可选:遥控器、配对的智能手机、游戏手柄或连接的物联网设备。因此,语音交互不一定是默认的交互方式,它只是众多方式之一。
因此问题就变成了:语音交互变为主流交互手段的可能性有多大?如果不是主要的手段,那会是次要的吗?或者第三?这将向前推进你的推断和交互假设。
4. 技术限制实例
把我们的语言转化为行动是一项极其困难的技术挑战。通过时间、连接和训练,调优的计算引擎可以听懂我们的话并作出适当的动作。
不幸的是,我们生活的世界无线连接并没有想象中的广泛(如:互联网),也没有无限的时间。我们希望语音交互能与其他习惯的交互一样直接:视觉上的和触觉上的——即便语音引擎需要复杂的处理和预测建模。
以下是一些实例流程,展示了我们在演讲过程中识别的过程:
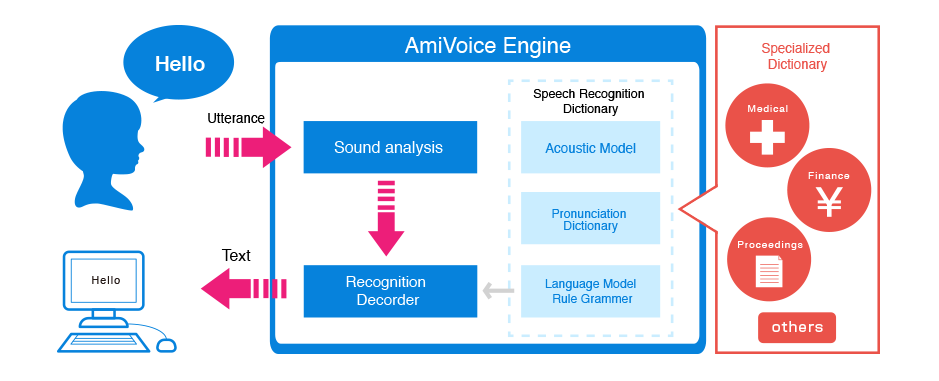
正如我们所看到的,许多的模型都需要使用的词语、音调、音色来进行不断的训练。
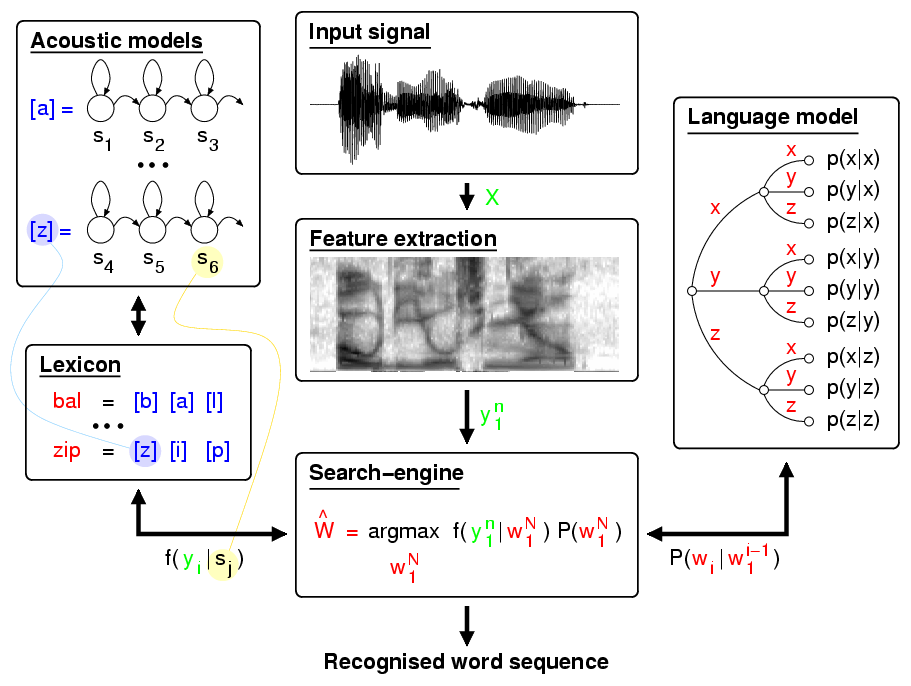
每种语音识别引擎都有一些技术限制,在构建语音交互体验时,必须考虑到这些限制。
分析以下分类:
- 连接水平——设备是否始终连接网络?
- 处理速度——用户是否需要实时处理语音?
- 处理精度——如何权衡准确度与处理速度?
- 语音模型——当前模型的效率怎么样?能准确的处理整句还是简短的单词?
- 备选方案——如果无法进行语音识别,备选方案是什么?用户有其他的交互模式选择吗?
- 结果误差——处理过程中一个错误的命令会不会导致不可逆的结果?语音识别引擎是否能够避免这种不可逆的错误?
- 环境测试——语音引擎是否在复杂环境下进行过测试?例如:如果我构建汽车的信息娱乐系统,相比智能恒温器我会设想更多的干扰环境。
5. 非线性
此外,我们还应该考虑用户能够以非线性的方式与设备交互。例如:如果我要预订网站上的机票,然后不得不按照网站的步骤进行——选择目的地、选择日期、选择座位、看选项等等。
但是,VUI 有更大的挑战,用户可以说:“我们想乘坐商务舱飞往旧金山”。现在,VUI 必须从用户那里提取所有相关信息,以便利用所有的航班预订数据。但最后排序的结果可能是有倾向(某一种排序方式)的,因此 VUI 有责任从用户那里提取相关信息(或通过语音或视觉进行补充)。
二、语音交互用户体验
以上,我们研究了约束条件、依赖关系、用户案例,那么,现在可以开始深入一些研究语音交互相关的用户体验了。
首先来研究设备如何知道何时该收接收我们的语音。
对于上文,下图说明了基本的语音交互流程:
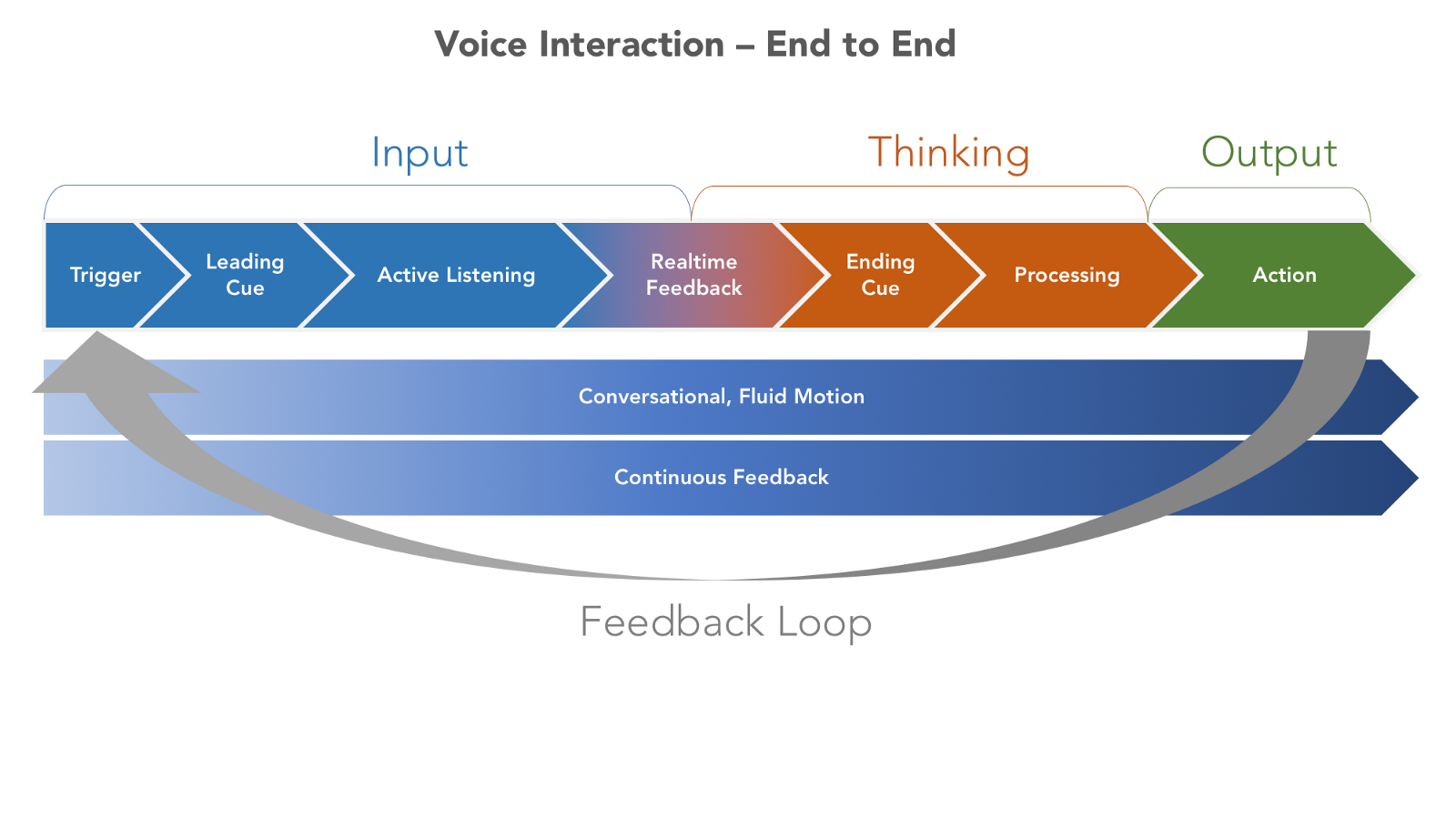
表现为……
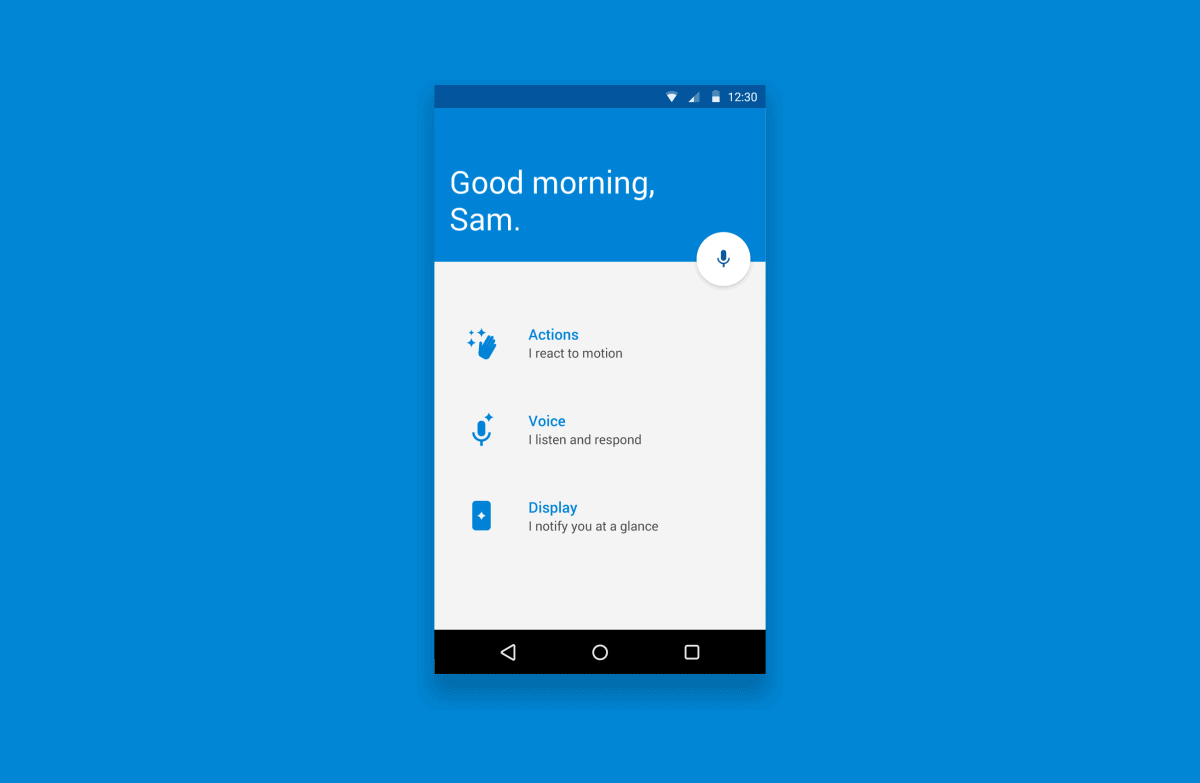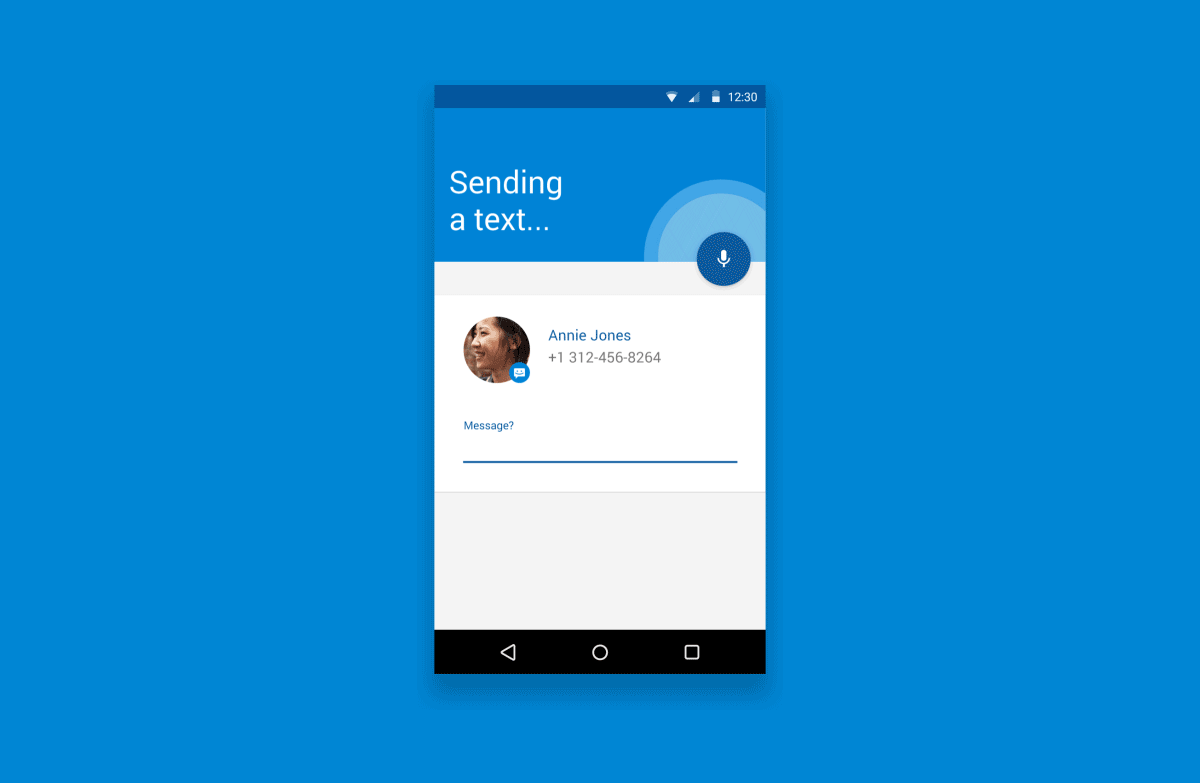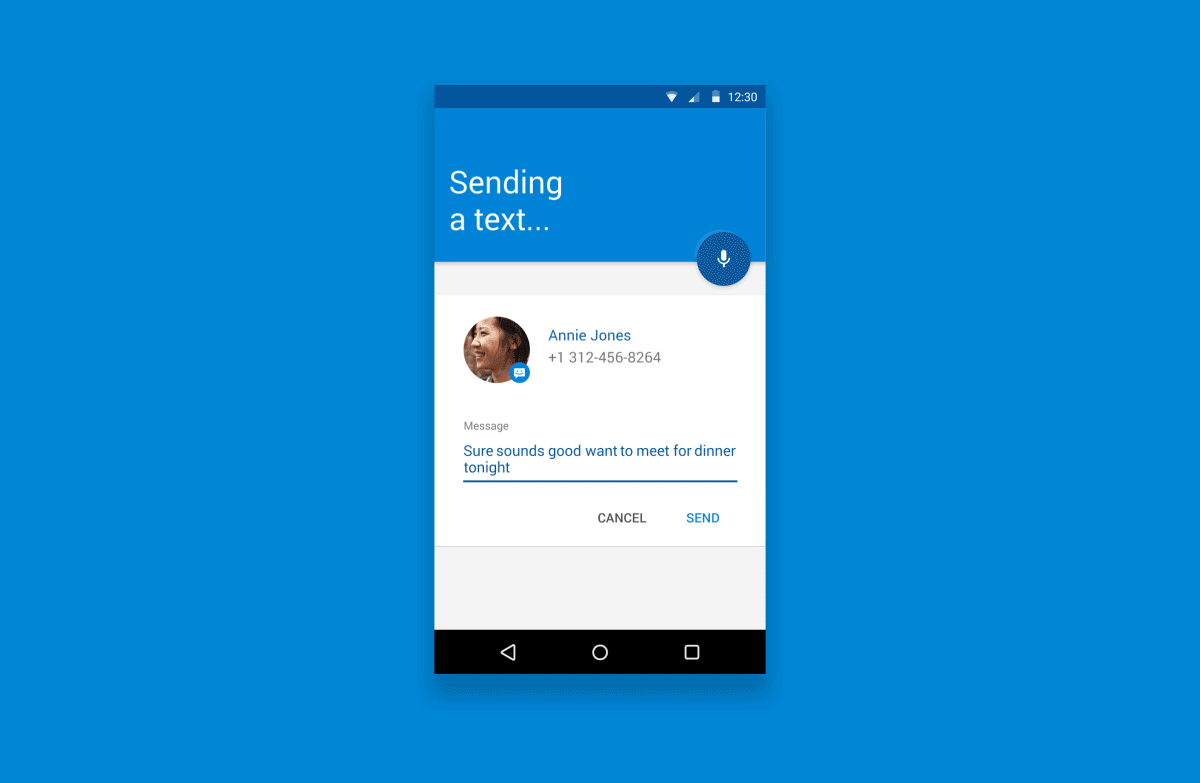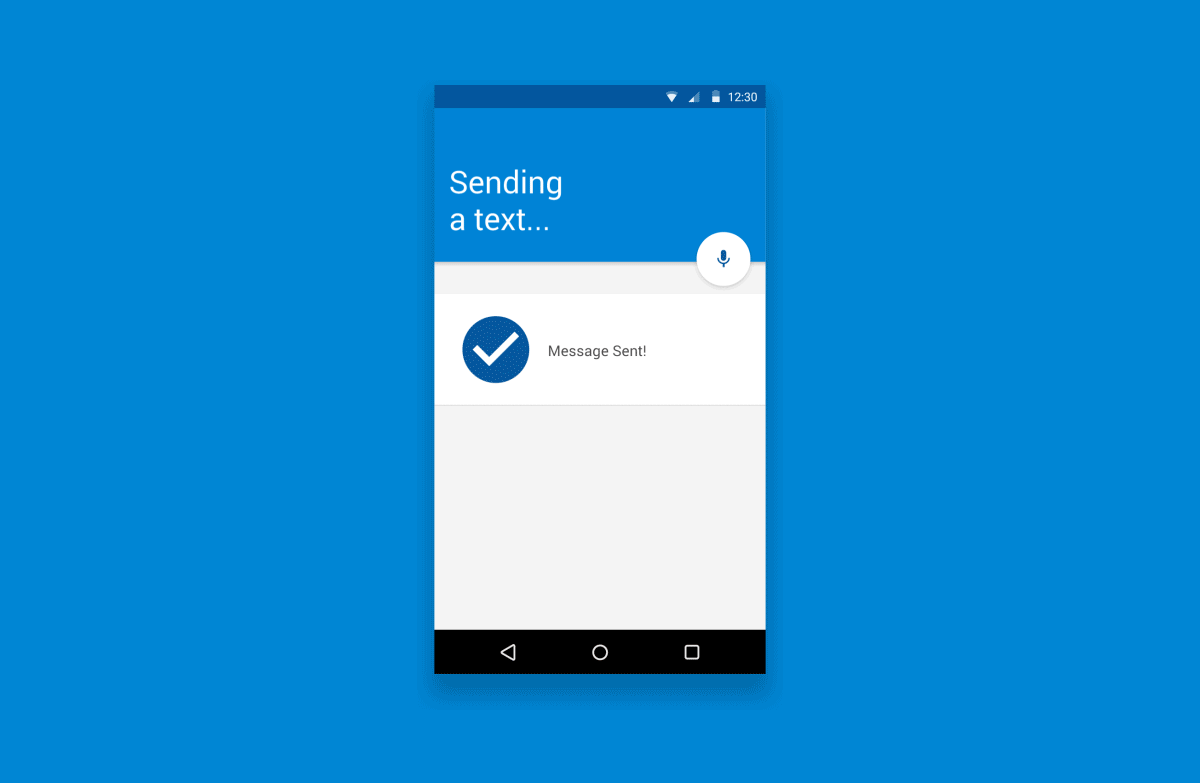
1. 触发器
语音输入触发器有四种类型:
- 语音触发——用户说出一个短语,提示设备开始处理语音(如:“Ok Google”);
- 触觉触发——按下按钮(某个键或键盘输入)或切换控制(例如:麦克风);
- 动作触发——在传感器前挥挥手;
- 设备自触发——预定设置触发设备(汽车提醒司机确认某个任务)。
作为设计师,你必须了解哪些触发器与设计相关,并且讲这些触发器从相关到不相关进行排序。
2. 引导提示
通常,当触发设备时,会有一个听觉、视觉或触觉提示。


这些提示应该遵循以下可用性原则:
- 实时性——被触发后,提示应该实时展示,即使这会中断当前的流程(只要这个中断不是破坏性动作)。
- 简洁短暂——提示应该几乎是瞬间的,特别对于老用户。例如:两声哔哔声比“好吧,贾斯汀,你想让我做什么?”更有效。引导提示越长,用户的话越可能与设备提示冲突。这一原则也适用于界面提示,屏幕应立即转换为监听状态。
- 清晰——用户应该知道他们的声音什么时候开始被监听。
- 一致——提示始终相同,声音或视觉反馈的差异会让用户觉得困惑。
- 区别——提示应该与设备的常规的声音和视觉效果有所不同,并且不应在其他环境中使用或重复。
- 补充提示——如果可能的话,利用多种交互方式来表示提示(例如:两遍哔哔声,一次灯光变化或一个界面提示)。
- 初始提示——对于初次使用的用户,或者当用户不知所措时,你可以显示提示或建议,方便继续进行语音交互。
3. 反馈用户体验
反馈用户体验对于成功的语音界面是至关重要的,它允许用户将他们认为一致且立即确认的语音,被设备摄入和处理;反馈还允许用户纠正或者肯定他的行为。

以下是一些有助于提供 VUI 有效反馈的交互原则:
- 实时、响应式视觉效果——这种视觉反馈在本机语音设备交互中最常见(例如:手机),它可以在多个声音维度上创建即时的认知反馈:音调、音色、强度和持续时间——这些都可以改变实时响应的方案。
- 音频播放——确认语音的解释。
- 实时文本——文本反馈将在用户说话时逐渐显示。
- 输出文本——在用户完成语音后,转换和修改文本反馈,在将音频确认或转换为行为动作之前,将这视为第一层的纠正处理。
- 非屏幕视觉提示(灯光,灯光模式)——上面提到的响应式视觉效果,不仅限于数字屏幕,这些响应模式也可以以简单的LED灯或灯光模式体现。
4. 结束提示
该提示意味着设备停止接收用户语音,并且开始处理命令。许多相同的“引导提示”原则,也适用于最终提示(即时、简短、清晰、一致和区分)。
不过,还有一些其他原则也需要注意:
- 充足的时间——确保用户有足够的时间完成命令;
- 适应时间——被分配的时间应该适应用例的预期响应,例如:如果用户被问到“是”或“否”的问题,则结尾提示应该在一个音节之后期望合理的暂停;
- 合理的暂停——上一刻接收的语音有合理的停顿时间吗?计算这个时间非常复杂,但也取决于交互用例本身。
三、会话式交互
像“打开我的闹钟”这样的简单命令,不一定需要冗长的对话,但更复杂的命令却需要。与传统的人与人交互不同,人与 AI 的交互需要额外的确认、冗余和纠正。
更复杂的命令或迭代对话通常需要更多次语音交互、选项验证,以确保准确。更为复杂的是,用户常常不知道该问什么,也不知道该怎么问。因此,VUI 的工作就是理解消息,并允许用户提供上下文。
- 肯定性——当 AI 确实理解语音时,它回复肯定消息,同时这条消息也确认了对语音的理解。例如:人工智能不是说“当然”,而是说“当然,我会把灯关掉”——或者“你确定要我关灯吗?”
- 修正性——当 AI 无法解读用户意图时,应使用修正选项进行响应,允许用户选择另一个或重新对话。
- 善解人意——当 AI 无法满足用户的请求时,它应该因缺乏理解而获得所有权,然后为用户提供纠正措施,同理心对于建立一种更和蔼可亲的关系非常重要。
四、拟人化交互
将类人特征赋予语音交互,会在人与设备之间建立一种关系。这种拟人化以各种方式展现:灯光模式、反弹形状、抽象球形图案、计算机生成的语音和声音。


拟人化是指给事物(非人类实体)赋予人类特征、情感或意图。

拟人化在用户和机器之间建立了一种更紧密的联系,这也可以跨越具有类似操作平台的产品(例如:谷歌的助手、亚马逊的 Alexa 和苹果的 Siri)。
- 个性化——为交互带来额外的维度,允许事物的虚拟人格与用户建立联系和共鸣,有助于减轻语音处理错误的负面影响;
- 积极性——积极鼓励重复性的互动和肯定的语调;
- 信心和信任——鼓励更多的互动和复杂的对话,因为用户更有信心结果是积极的,从而增加了价值。
五、端到端的交互
语音交互应该是流动的和动态的(彼此一言一语的对话)。当我们面对面交谈时,我们常会使用大量的面部表情、音调变化、肢体语言和动作。语音交互的挑战在于,在数字化环境中捕捉这种不固定的交互变化是很困难的。
如果可能,整个语音交互体验感觉应该像是一种有益的互动。当然,更多短暂的互动,如:“关灯”并不一定需要一个完整的关系。但是,任何一种更强大的互动,如与语音助理一起烹饪,确需要长时间的对话。

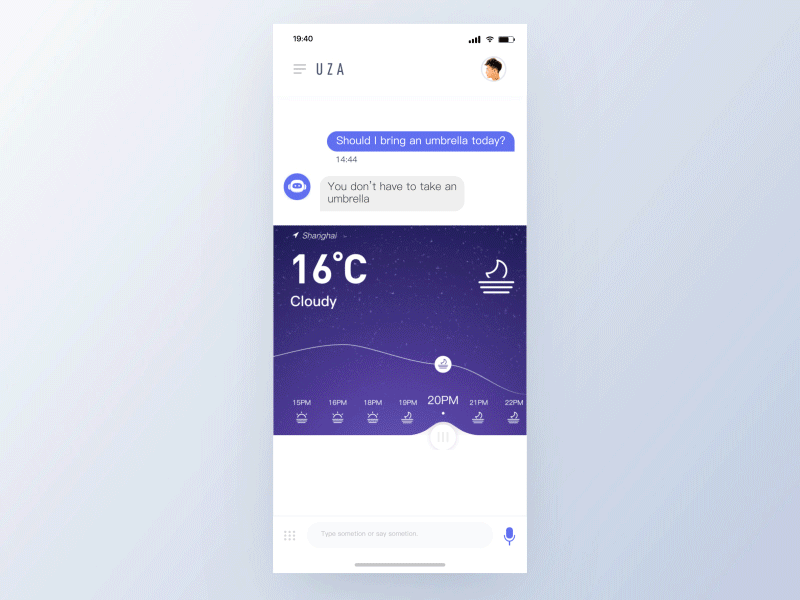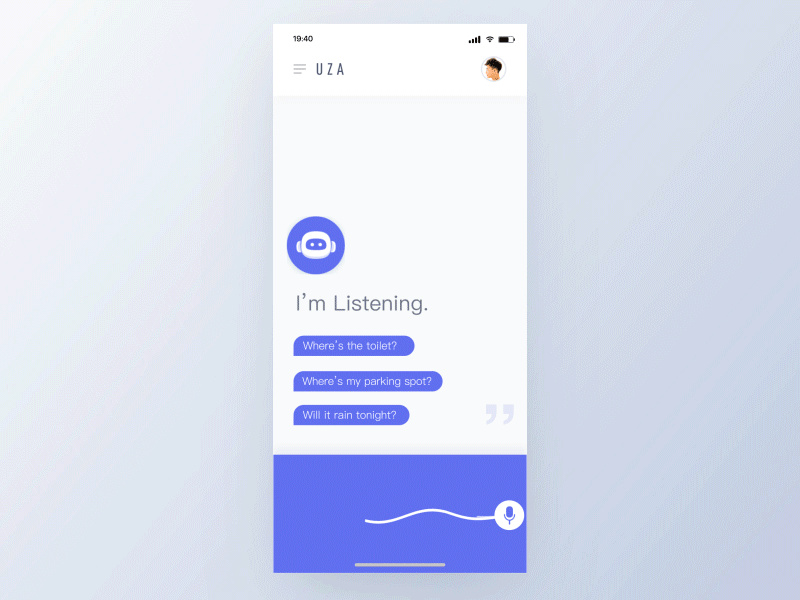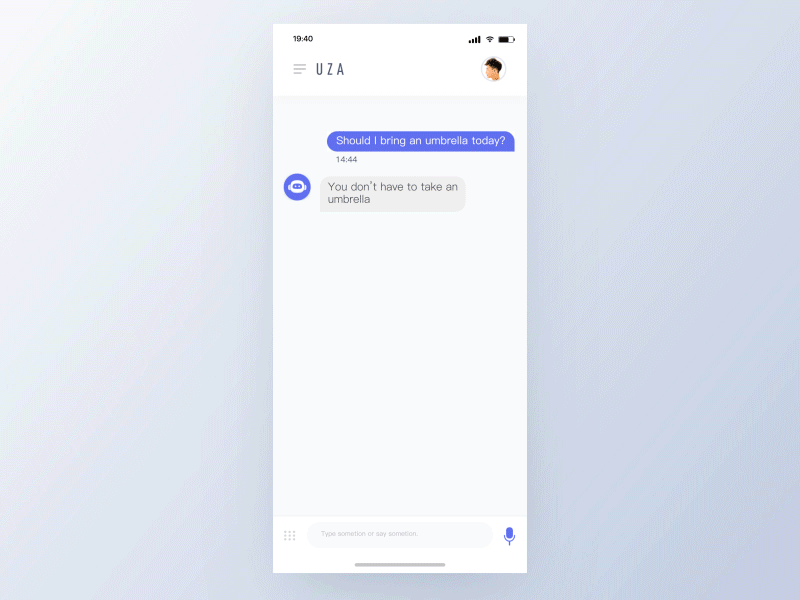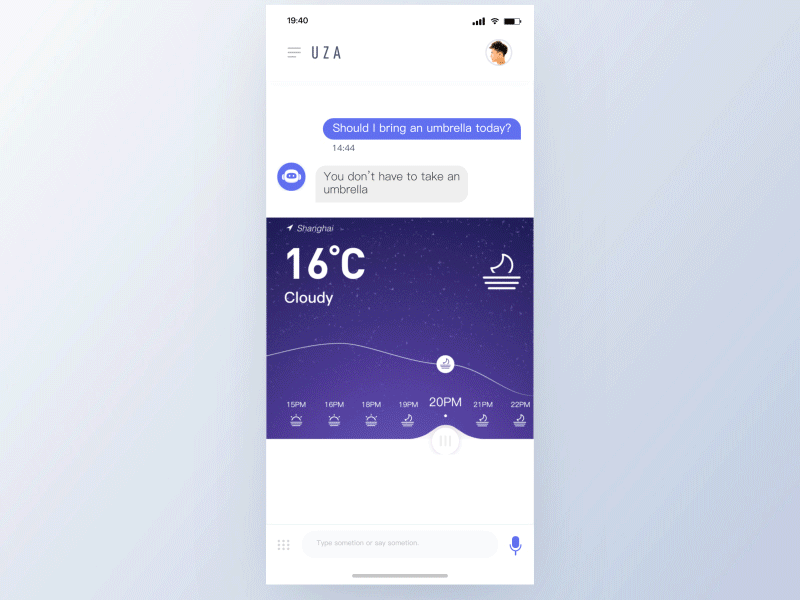
有效的语音交互体验将受益于以下原则:
- 短暂的——无缝处理不同状态之间的转换,用户应该感觉到他们没有等待时间,且助理在为他们工作。
- 生动的——鲜艳的色彩传达喜悦和未来主义,它为互动增添了一种未来主义优雅的元素,鼓励重复性互动。
- 响应式——回应用户输入语音和手势,给出关于正在处理信息的提示,并允许用户查看语音、意图是否被准确的解析。
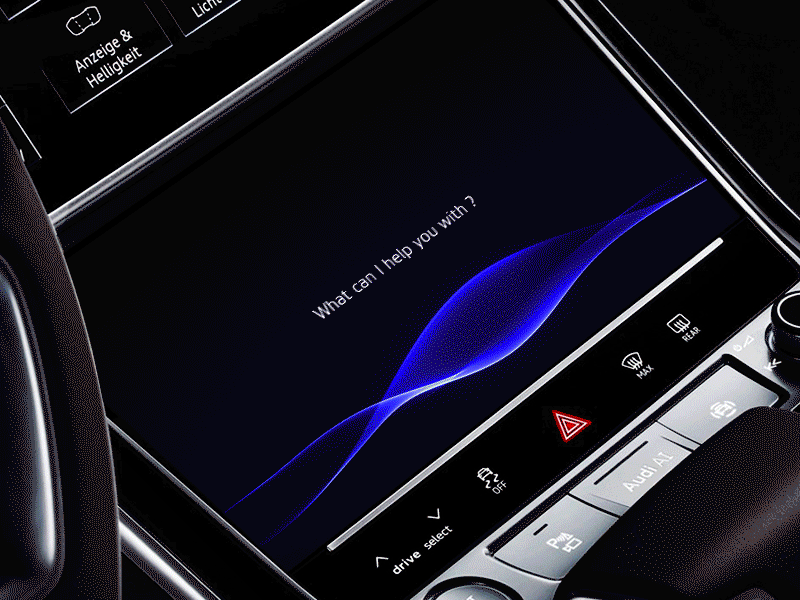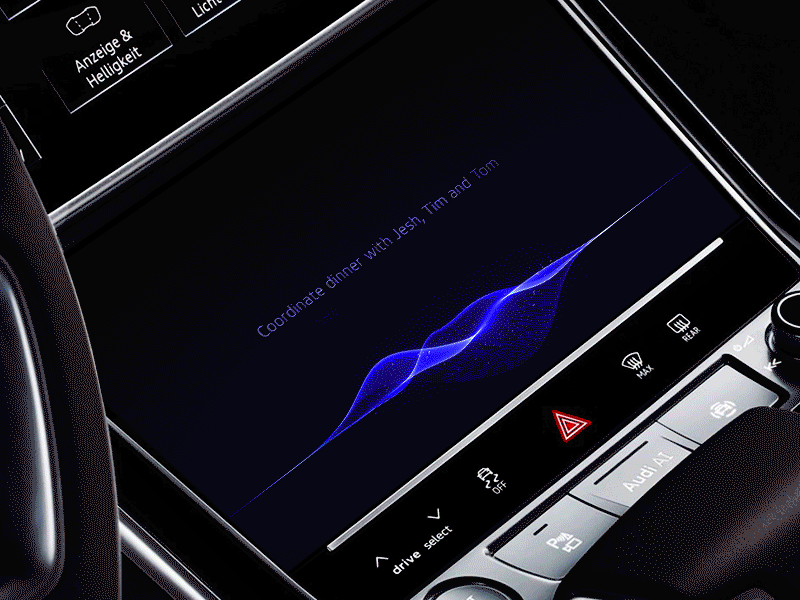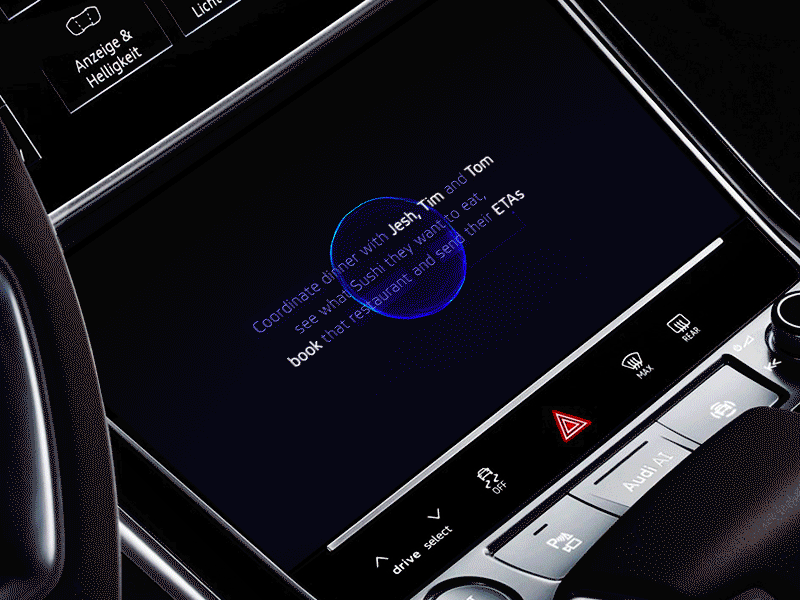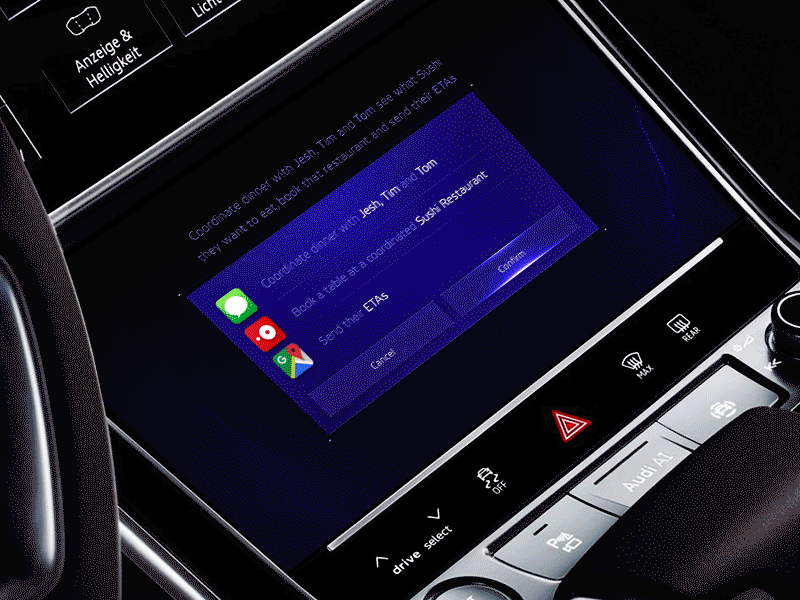
六、结论和资源
VUI 非常复杂,且有多个方面,通常是复杂的混合(多种交互手段)交互。
事实上,它还没有一个全面的定义。不过要记住重要的一点——一个日益数字化的世界意味着,我们在设备上花费的时间,可能比在彼此上花费的时间要多。VUI 是否会成为我们与世界互动的主要方式吗?让我们拭目以待。
与此同时,你是否打算构建一个世界级的 VUI?
作者:Justin Baker
原文链接:https://medium.muz.li/voice-user-interfaces-vui-the-ultimate-designers-guide-8756cb2578a1
译者:Anne
本文由 @Anne 翻译发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议







- 目前还没评论,等你发挥!









