
 起点课堂会员权益
起点课堂会员权益
语音交互设计探究——以车载场景为例
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。本文以车载场景为例,具体分析了其中的语音交互设计流程、原则与设计走查等内容。

从Siri 、Amazon echo Alexa、google home 、小冰、国内的叮咚、天猫精灵、小爱同学以及各种你听说过的,没听说过的。然而,随着技术的进步,语音交互将运用到越来越多的场景:
- 2017年5月10日,微软Build大会发布智能音箱Invoke,
- 2017年6月6日,苹果WWDC发布HomePod,
- 2017年7月5日,上午10点,百度AI开发者大会发布DureOS开放平台,
- 同一天,下午2点,阿里人工智能实验室发布天猫精灵,
- 2018年1月,百度DuerOS在CES 2018上惊艳亮相……
驾驶汽车是一项复杂的行为,好的驾驶体验需要综合考虑驾驶场景的各个因素。完全自主驾驶汽车的时代马上就要到来。当汽车能够实现完全自主驾驶时,对于汽车驾驶场景的概念将完全被颠覆—也许我们应当将精力集中在如何设计驾驶过程中的娱乐服务,或者将驾驶室设计成为驾驶员的工作台。不得不说的是,车载中控系统目前为止的体验都不太好,在完全自主驾驶时代到来之前,车载中控系统的体验设计还有很大的空间被提升。
一、基本概念
车载场景下的语音交互(后面简称VUI),追求驾驶者的使用体验,缓解甚至消除驾驶过程中带来的焦虑现象。车载VUI设计的基本理念如下:
- 安全:驾驶过程中几乎是眼、耳、手并行的多任务操作状态,VUI应该有助于驾驶者和车载产品更好的交互,并且不会分散驾驶的注意力。
- 便捷:每一次VUI交互都是方便且快捷的,打破语音交互的心理障碍,快速响应、流程简单、路径明确、最大限度较少每个任务的对话轮数。
- 愉悦:令人愉悦的声音和表达,自然的对话交流,流畅地完成每一个任务,用聪明的方式规避对话错误,达到一种“情理之中,意料之外”的境界。
二、设计流程
语音交互的设计需要模拟真实的对话场景,并根据场景来撰写对话和建立交互逻辑流程,最后通过调研来定义更加全面的表达方式,以达到更加自然合理的语音交互体验。
2.1 分析使用场景
VUI的应用场景已经覆盖了手机助手(以Siri、Google Assistant为代表)、智能家居(以Amazon Echo和Google Home为代表)、车载产品(以Carplay和Android Auto为代表)以及可穿戴设备(以AirPods、Apple Watch为代表)等领域。

语音交互的场景主要从物理距离、行为特征、用户目标三个方面来分析:
物理距离:在交互过程中用户与语音产品的距离。可以根据远近关系分为“近场”、“中场”和“远场”。
- 近场交互:如灵犀 / Siri;手持设备,近距离输入语音,有反馈界面;唤醒方式一般为屏幕的点击或长按,也存在语音唤醒的情况。
- 中场交互:如车载;无需手持设备,处于能够触及的距离,有反馈界面;唤醒方式多为语音,也可以借助手势操作;由于距离较远,需要借助麦克风阵列达到良好的收音效果。
- 远场交互:如Echo;无需手持设备,处于不能触及的距离,可以没有反馈界面;唤醒方式为语音;由于距离较远,需要借助麦克风阵列达到良好的收音效果。
行为特征:用户在进行语音交互时,可能正在做着家务,或者开着车,也可能什么都没做;在这里可以把这些行为特征分为“专注于语音交互”和“专注于其它事情”。
- 专注于语音交互:一般发生在近场交互的情况下;用户手持设备,视线关注在界面上,耳朵关注于语音反馈。
- 专注于其它事情:一般发生在中场、远场交互的场景;用户一边处理着其它任务,如开车、烹饪等,双手以及视线可能正在被其它事情占用,如何让用户最小成本的完成语音任务是设计的重点。
用户目标:用户么每次语音交互的目的,可能只是随意的闲聊,也可能是目的明确的任务指令。
- 闲聊式:如调戏Siri一样,目的性并不强,对趣味性的要求更高。
- 任务式:这类对话,用户需要尽快得到想要的反馈,快速完成任务,清晰和简洁的反馈是最重要的。
车载环境的语音交互属于“中场”、“专注其它事情”、“任务式”的交互场景,设计过程中应该遵循这些场景特性。
2.2 建立用户故事
通过对驾驶场景下车载产品使用情况的用户访谈和问卷调查,知道用户在驾驶过程中想要完成什么任务;结合自身的优势和劣势,以及外部市场的机会和威胁,确立产品的技能范围,如导航、音乐、电台、电话等。
围绕这几个核心功能,设定主要场景描绘出用户在现有车载产品使用过程中的行为习惯、遇到的问题,最后提炼出痛点,找到解决办法,并寻找出适合VUI去解决问题的场景,用户故事地图的框架如图2-5:
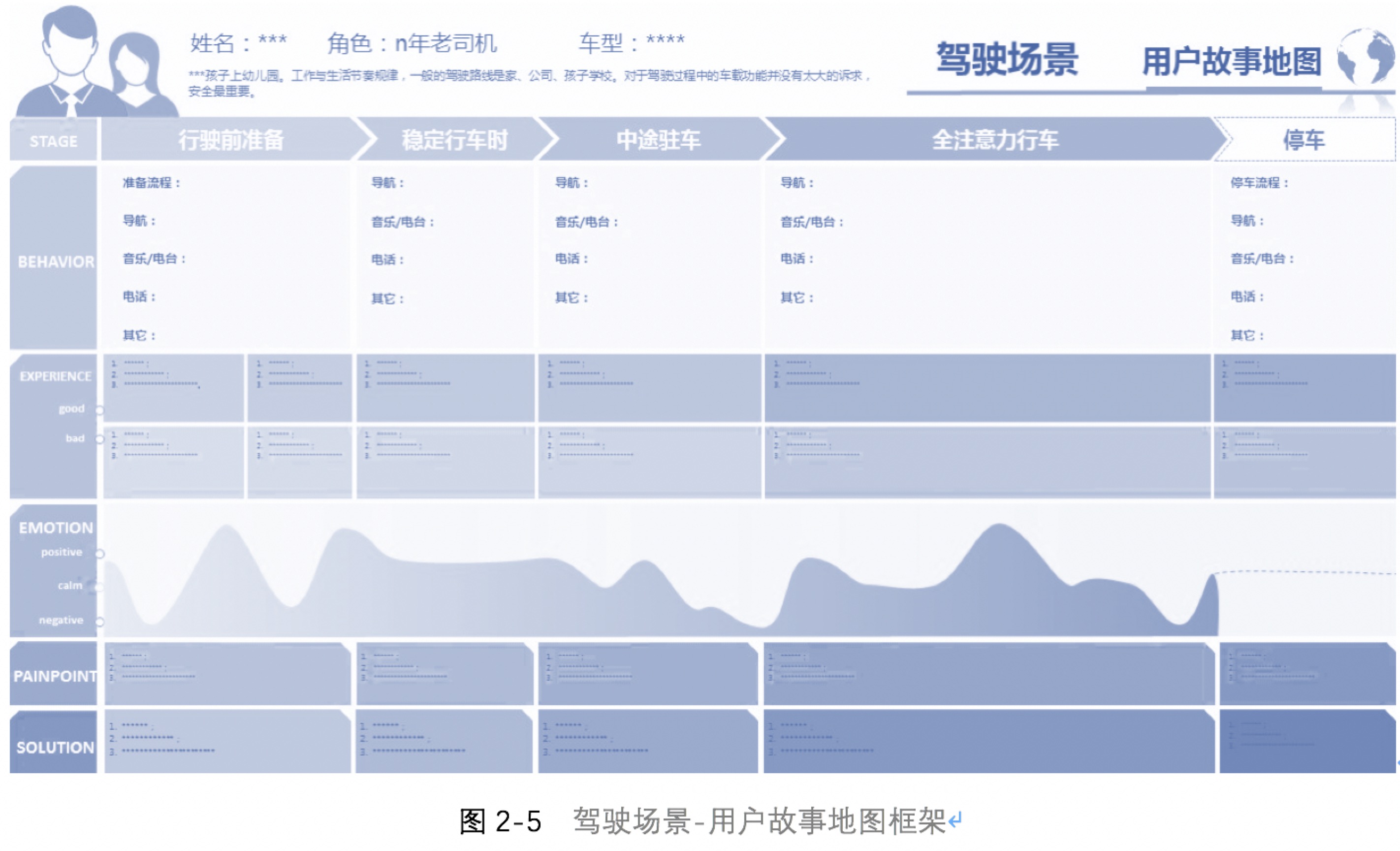
适合VUI的场景通常比较简单、直观,不需要太复杂性的互动。举个例子:你正在高速路上全注意力行车,这时你需要拨出一个紧急电话,但这会儿不方便用手操作手机……此时用户希望从技能中得到什么帮助、会做什么,将是VUI的基础和价值所在。而建立类似的用户故事有以下的方法和原则:
确认目的和功能:构建一个或多个情境,让用户觉得你的技能有用并且有使用的冲动。可以通过分析以下问题来确定技能的能力:
- 技能的目的是什么?用户为什么想要使用它?
- 用户在交互前、交互中、交互后分别会做些什么?
- 用户可以通过这个功能得到什么在其它产品上无法获得的体验?
创建用户故事:根据技能的目的和基本功能点,确认每一个交互行为节点
- 用户能够通过该项技能做到什么?不能做什么?
- 用户希望能够获得什么信息?
- 用户可以通过什么方式来使用这项技能?
2.3 设计听觉形象
人物画像可以帮助你设计、撰写UI对话,所以要尽早确定,这样就能更容易的决策出正确的用词、语法和句子结构。人工智能赋予了机器拟人化声音输出的能力,带来的语音设计材料。不同的声音带给用户的感受是不大相同的,低沉的声音给人“稳重,成熟的”的感觉,尾音语调向上的声音给人“愉悦,被尊重”的感觉。VUI产品需要被赋予听觉形象,下面是一些听觉形象设计的流程和方法。
设计流程:语音是不可见的,在声音形象的设计中必须先有“语音基础形象”设计师基于语音基础形象进行再具体的VUI设计。
- 定义形象:听觉形象其实和真人一样,有姓名、性别、年龄、职业、个性特点之分,同时也有声音的感觉,如柔和亲切、利落正式、有磁性等主观的感受,也有更加客观的音高、音强、音长、音质几大属性。不同的声音会被我们赋予不同的形象特点,根据内容/产品气质/品牌愿景定义产品的“听觉形象”。
- 挑选:去语音库里挑选具有定义的听觉形象的语音片段。比如如果要产生的听觉形象是“沧桑感”时,可以挑选一些单田芳老师语音片段。
- 训练:将大量语音片段交由技术人员进行语音合成训练。
- 微调:通过调整“语调、速度、节奏”使之给用户的感觉更接近于先前定义的“听觉形象”。
设计原则:
- 保持与“品牌情感”的一致性:在进行视觉设计时设计师要通过“色彩,形状”等设计元素支撑品牌情感,对与大型公司会要求他们的每一个产品遵循一致性的设计规范。进入“听觉形象”设计时代,当你的产品要使用语音交互时,确保产品的“听觉形象”与品牌情感保持一致,这将能够强化品牌给用户的印象。
- 保持与“用户场景”的一致性: 回想一下机场内的语音“尊敬的旅客飞往北京的T343航班….”,这种语音形象给用户“被服务的、受到尊敬“的感觉,与用户在机场的场景相一致。而在医院,起码在中国的医院,医疗资源与患者数量极不匹配,患者与医生更像是”求助关系“而非“服务关系”, 使用过于“服务化”的语音形象反而会给用户带来强烈的落差感。
- 保持与“内容”的一致性:“内容”本身是具有形象属性的,比如二次元的新闻如果用粗犷的男生读出来一定会很违和。因此在进行内容消费型设计时要充分考量语音所说的内容与“听觉形象”相匹配,避免出现违和感。但是在设计工具型产品时,不要频繁更换语音形象,这会分散用户注意力使效率下降。
2.4 撰写对话脚本
在确立了技能范围和用户故事之后,不要立即开始逻辑设计,对话应该是自然的、多样性的,用刻板的逻辑将语音设备与用户的场景台词串联在一起显然不合理。因此,你需要列举出诸多可能存在场景,考虑到意外状况,去草拟撰写对话草稿,甚至找真人模拟场景对话,尽量覆盖到每一个状况。下图是一些对话撰写的例子:
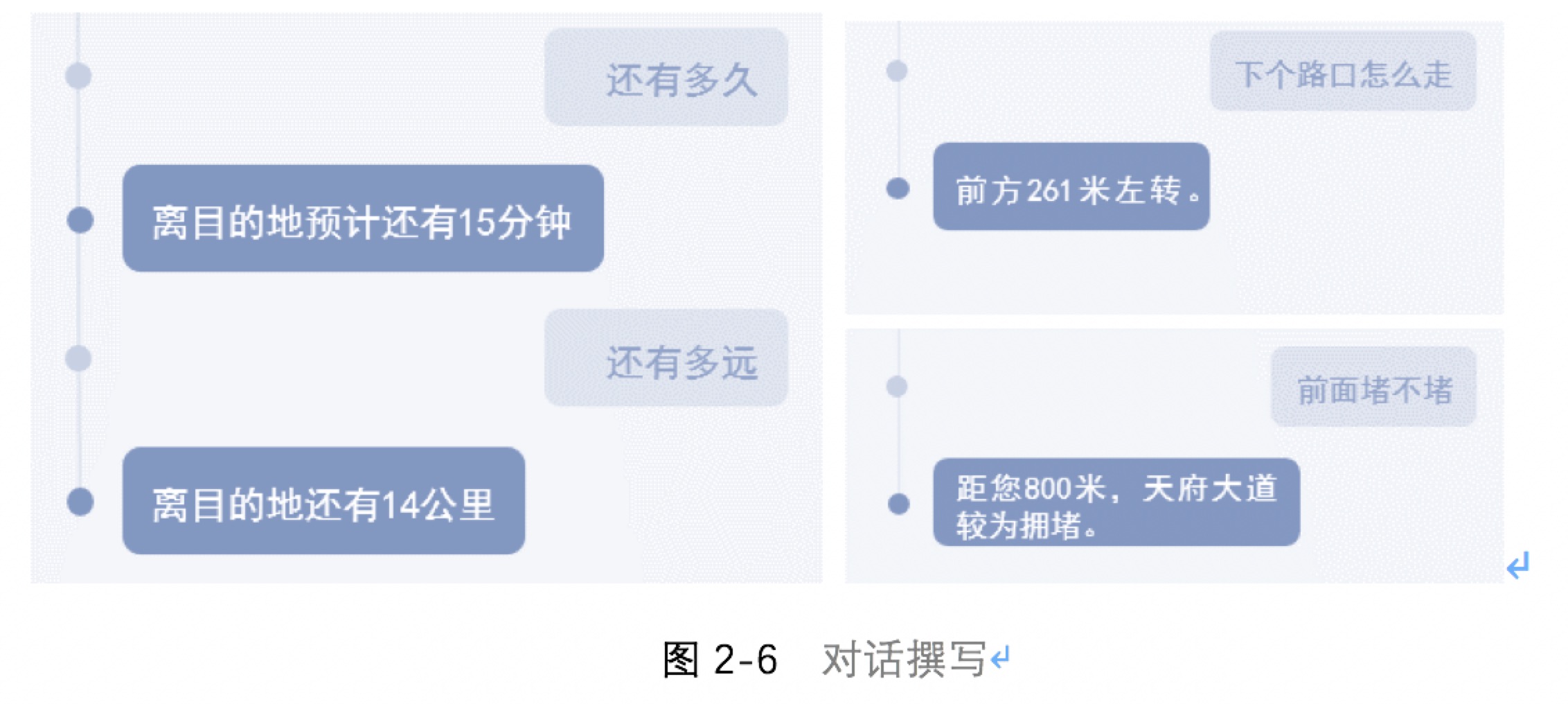
对话脚本的撰写可以帮助我们挖掘一些容易被忽略的细节,而如何反馈和引导对话的进行也是VUI设计的重点和难点,后文中会详细说明反馈设计的原则和方法。
2.5 建立交互框架与流程
要建立VUI的框架与逻辑,首先需要理解人与人的对话框架,匹配到人机交互的对话场景,以确立每次反馈方式;然后围绕用户的意图以及系统的每次判定节点展开逻辑流程的建立。
交互框架:想像一下你想让别人放点音乐,这段对话的交互节点是怎样的,是不是先叫他名字,对方听到了给你一个回应“干嘛呢”,然后你可以继续说出你的需求……我们将交互节点提炼出来,如下图所示:
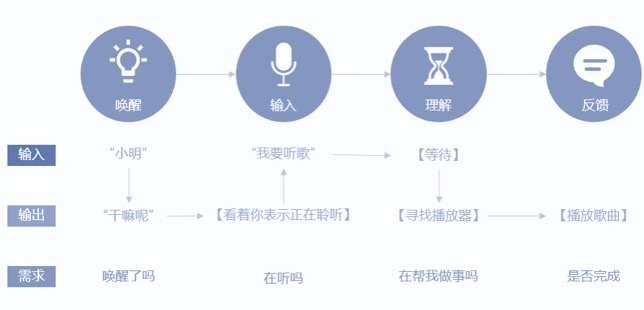
图2-7 对话框架
(1)唤醒
“唤醒”是技能的触发动作,目前主流的唤醒方式有以下3三种 – 实体按钮、虚拟按钮、语音唤醒,如图2-8,每种唤醒方式各有特点,在车载环境中一般采用按钮+语音的多重唤醒方式。同时,唤醒之后的反馈形式也有多种,具备显示屏的设备可以有动效、文字等反馈,不具备屏幕的可以有灯光、音效、人声等反馈。不同的反馈方式的舒适度和响应时间密切相关,如图2-9所示。

图2-8 唤醒方式
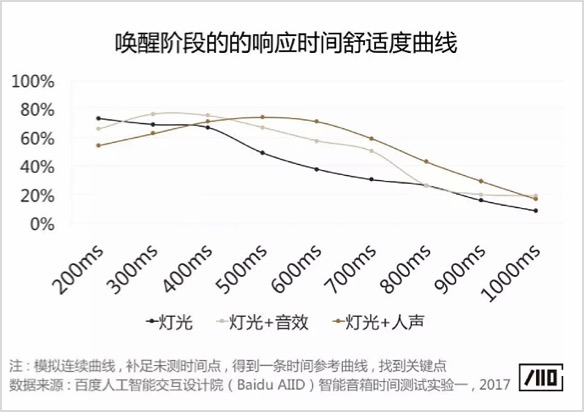
图2-9 唤醒反馈方式与响应时间舒适度曲线
(2)输入
用户输入的语音内容是否被设备的接收,亦是用户比较关注的问题,在反馈设计中应该匹配当前场景且不让人反感。具备显示屏的设备可以有动效、文字等反馈;不具备屏幕的可以有灯光(在用户输入时一般不要有声音的干扰)等反馈;也可以没有反馈。

图2-10 输入时的反馈
(3)理解
“理解”是机器识别、解析语音内容,并求解答案再生成语音的过程;也是机器的认知过程。这个过程耗时可能会较长,重点在于消除用户等待的焦虑以及不确定性。具备显示屏的设备可以有动效、文字等反馈,不具备屏幕的可以有灯光、音效、人声等反馈,如图2-11所示。不同的反馈方式的舒适度和响应时间密切相关,如图2-12所示。
图2-10 理解时的反馈
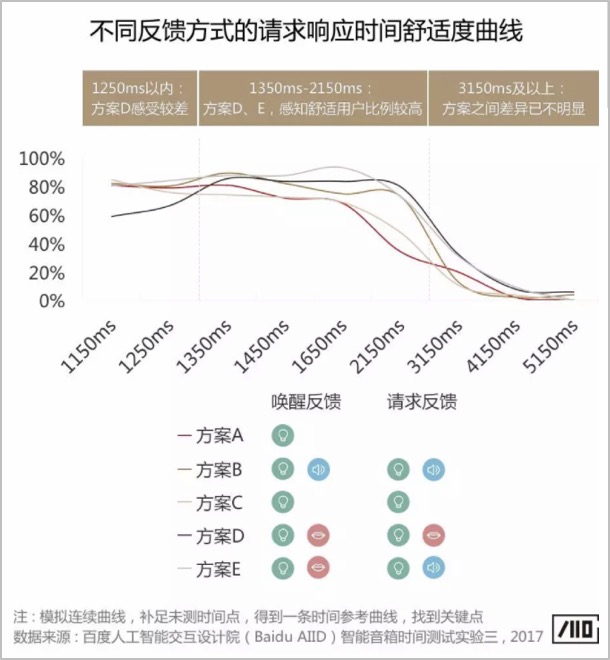
图2-12 理解反馈方式与响应时间舒适度曲线
(4)反馈
这里语音交互过程中最重要的环节,除了让用户得到想要的反馈之外,还应该让用户轻松、自然且有效的接收到反馈信息。下表是根据置信度(Confidence)不同划分的反馈的类型和应用场景。
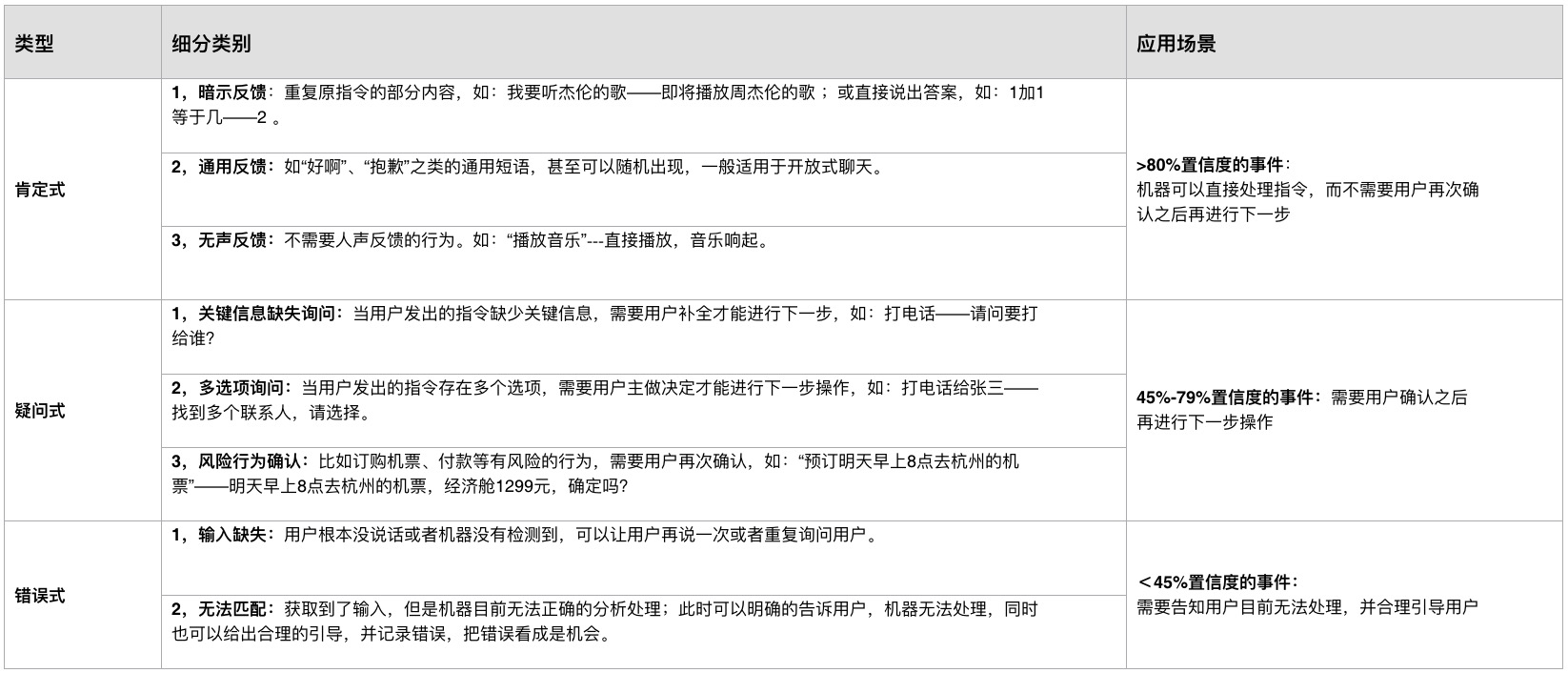
(5)端点检测
由于这端点检测是一种描述计算机何时开始和结束语音的方式。用户在说话时会有停顿,那么语音引擎在检测到用户停顿多久之后开始识别,停顿5秒是一个比较合适的经验值;短了,会在结束说话之前切断用户;长了,用户会怀疑系统是否听到。用户唤醒语音后,一直不说话,那么语音引擎在检测到用户不说话多久之后直接退出语音识别,未说话10秒是一个比较合适的经验值。
交互流程:对话表面看起来似乎是杂乱无章,无规律可寻的。但是在自然对话中我们几乎是无意识地遵循着某些规则与惯例,比如:对话是轮流进行的、是上下文串联在一起的。人-机对话中,机器是服务于人类的;用户的每一个指令,机器都需要去判定以及作出最好的回应,并且允许指令的多样化表达;机器的每一次任务执行,几乎都能允许用户 “取消”、“修正”、“催促”、“返回上一步”、“打断”、“要求重复”、“其它类型指令”、无关信息或者保持沉默。用户的每一次语音指令后面都跟随一次判定节点,围绕用户意图以及机器的判定节点展开交互逻辑的建立,如图2-13。
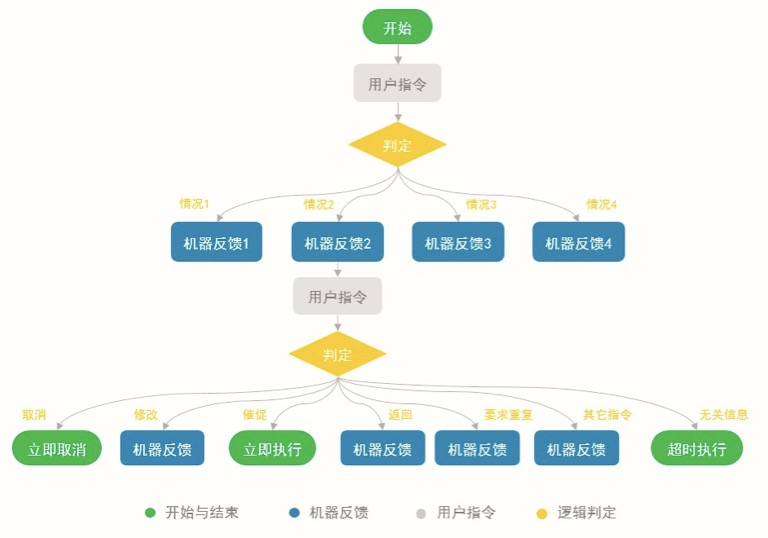
图2-13 交互流程建立
2.6 定义意图、表达方式、插槽
这里分析的是用户说的内容,这些内容的语音结构可以概括为“唤醒词+意图表达+插槽”,如图2-14所示。

图2-14 语言结构
意图:代表了你的技能具备的能力;比如一个导航的技能可能会包含五个意图:设置目的地、展示路线、说明路况、取消和退出等。
表达方式:用户所说的那些能够表达他们意图的话语,包括大量单词、短语、句子。比如说,在表达导航这个意图的时候,用户可能会说“帮我导航”“导航去科大讯飞”或者“我要导航”等等,这些表达方式分类整理成意图表达库,如图2-15。
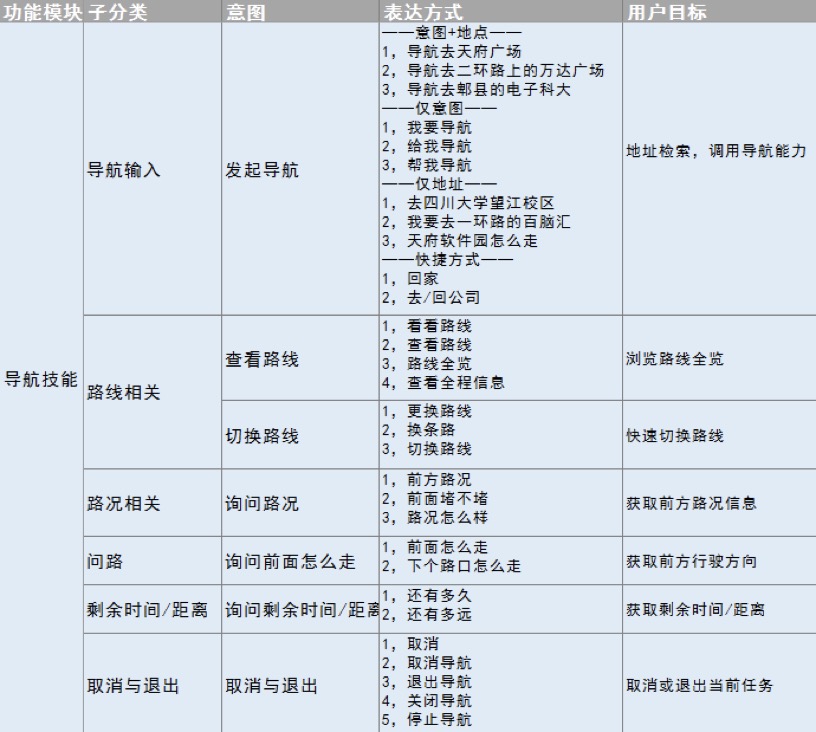
图2-15 意图表达库示例
插槽:是指定义某些意图的关键信息类别,例如“导航去科大讯飞”——“科大讯飞”就是一个地址名插。我们将不同属性的信息进行分类,如图2-16。每个类类别的信息都有自己的库,如城市名称库、日期库等等。
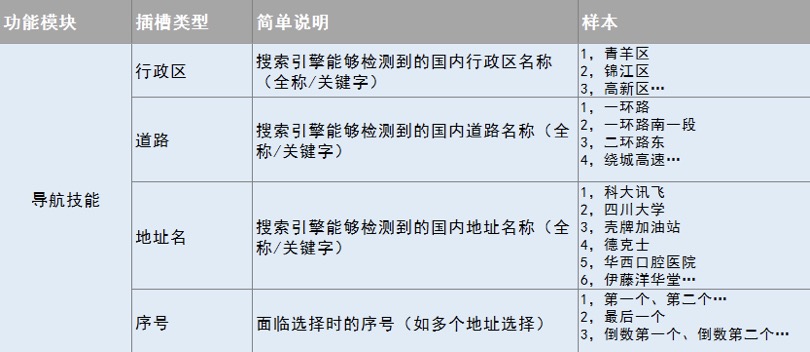
图2-16 意图表达库示例
三、设计原则
语音设备需要以一种自然对话的方式进行感知、认知以及输出自然语言,在VUI设计过程中需要遵循以下原则。
3.1 保持简洁
“简洁”的汉语释义是指简明扼要,没有多余的内容。尊重用户的时间,提供简洁的反馈语言、反馈界面(如果有屏幕的话)以及完成任务的最短路径,不要阻碍用户。
简洁的反馈语:用户能够轻松理解机器在说什么,同时感到舒适。过长的语言内容会让用户很难抓住重点,并且难于记忆,下面有一些保持语言简洁的方法:
- 一口气测试:对于没有逗号隔开的单句话,如果能够用正常对话的语速把这句话一口气读出来,表示长度是适合的。如果你需要换气,就要考虑精简。
- 避免重复:有屏幕的设备,应避免在屏幕上显示和语音内容完全重复的信息,图形界面应该提供语音以外更多的信息,利用视觉反馈,帮助用户更加快捷的完成任务。
- 插槽数量控制:对于包含多插槽信息的语句,插槽的数量能够被用户很好的接受不了和理解,这个可以招募一定数量的用户来进行测试,一般情况下插槽数量不超过三个。
愉悦路径:最短完成任务的路径,同时也要准备其它的替换路径,因为用户可能没有一次性给出所有必要信息。
3.2 保证明确
“明确”的是指表达得清晰明白而确定不移,使听者几乎不用思索便能听懂。保证明确的表达,有以下方式。
避免开放式问题:开放式问题可能会混淆用户或导致用户以您不期望或支持的方式回答问题。例如,问“你喜欢什么?”太开放了。即使是像“香蕉或苹果”这样的问题,也可能会出现“是”的回应。
提供明确的选项:不要问一些自己都无法回答的问题,让用户纠结于如何回答,特别是在车载场景下的对话,一定要避免用户过长时间的思考。以来电为例,机器可以询问“接听还是挂断?” 。
明确的陈述句:不要说一些模棱两可的话语,让用户产生疑惑。比如“正在为您拨打电话”比“我可能在拨打电话”更加明确。
3.3 自然的交流
鼓励用户自然的表达同时机器也要给出自然的反馈,让对话更加自然有以下方法。
用户自然的表达:同一意图包含多种表达方式,在语音交互中需要支持识别更多的表达方式,让用户自然的表达。
机器自然的反馈:不要告诉用户应该怎么说,甚至是一句一句的教用户;尽量不要使用难于理解的专业术语;增加同一含义的表达丰富性,减少机械感。
3.4 推进对话
在语音交互过程中,机器需要促进对话的进行推进对话,通常有以下的方法。
用户引导:一般用于新手引导,告知用户功能范围等。
提问:明确提出问题可以指导用户接下来该如何说,但也要准备用户会答非所问。
先抛出一个答案:当用户回答的信息不全时,有时可以为主动为用户做出一个选择,推进任务的进行,同时允许用户更改。
3.5 符合语境
VUI设计也要尽可能地利用用户的语境,通晓对话的来龙去脉(上下文),并具备用户情景意识(如用户所在地点、用户是否首次使用等)。
记忆上下文:多轮对话并记住上下文,如“今天的天气怎么样?”——“明天呢?”,机器需要知道用户问的是明天的天气。这就是支持用户的一些省略表达和代词的使用。
情景意识:考虑用户处于什么样的情景。如:用户已经知道该如何使用产品,那么就不再需要反复给用户一些新手帮助和引导,除非是用户主动提出的。
3.6 轮流交谈
VUI设计也要以用户为中心,当轮到用户说话时,不要贸然强行打断。当机器正在说话时,用户可以进行打断。
3.7 有意识地引导用户注意力
听觉输出是时间线性的,不易记忆的,但我们往往能够记住一句话结尾,也就是听觉范畴的 “近因效应”,所以我们通常把重点信息放在末端。比如“导航去天府广场,全程28.2公里,预计需要30分钟”,记得最清楚的基本都是“30分钟”。
3.8 把“错误”转化为对话UI中自然的一部分
VUI设计中会出现“无法识别”、“无法匹配”等各种错误情况,如果只是做一些简单、机械的处理应对,会让用户对产品产生极大的怀疑。下面是一些处理错误的办法。
分类处理错误:把错误类型进行分类,采用不同的反馈策略:
- 没有获取到输入:可能用户什么都没说,或许系统完全没有检测到,这类情况可以不需要任何反馈。
- 获取到信息,但无法识别:这种情况可能是背景噪音、或是多用户造成的。如果没有连续的上下文,可以采取通用提示“你说的什么?”,“我没听清”或者“再说一遍”之类的语句;如果有连续的上下文,可以根据具体的内容来提示,如“你选的第几个”,“我没听清是第几个”等等。
- 识别了用户输入,但不具备处理能力:这种情况需要告知用户,并给出一些提示。比如“这个我不会,但是我可以……”
- 错误识别信息,并具备处理能力:这种情况做好能够将错误的识别结构复述出来,并询问用户。比如用户说的是听音乐,机器却识别成了打电话,那么可以询问用户“你是要打电话吗?”
及时提供帮助:当用户出现困惑、没听懂、没听清或者不知道该怎么说的情况,可以提供相应的帮助。比如用户说“我没听清”,那么机器可以重复一遍之前说的话;也可能是说出像是”帮助“或”我不知道“之类的话。
四、设计走查
完成一套VUI设计之后,如何知道自己做得对不对、好不好?下面有一些简单的测试方法:
- 自己念出来:每完成一组对话撰写之后,自己可以找个独立空间把它们念出来,因为你很有可能撰写对话时采用书面语言,所以通过念出每段对话能够帮你找到表达不合适的地方。
- 找人演练: 找到一些团队以外的人,按照已经设计好的VUI和他们进行对话演练。对流程多测试几次,应该就能发现一些问题,例如哪个对话任务完成起来有困难,或是用户与语音交互的场景中,听者的感受如何。之后也可以搜集一些主观反馈,例如他们在哪里卡住了,在什么地方感觉不顺畅。
- 用模拟器检验:如“谷歌的在线模拟器”,输入对话文字,让系统运行读出来。也可以采用讯飞的AIUI平台,搭建技能之后查看效果。做了这些工作之后,你会逐渐发现先自己会越来越能够掌握撰写对话的技巧。
除了上述的一些测试办法,下列走查清单为你提供了一种快速检查方法,帮助你在产品在上线前确保已经准备好:

最后,VUI不再局限于手机,它已经扩展到智能家居、车载、可穿戴设备甚至更多领域,不同的场景和设备有它们自身的属性和特征,VUI的体验设计也需要符合相应的场景和设备。不过,所有体验设计的核心目标都是易用和带来愉悦的。
参考内容
[1] Google对话式交互规范指南
本文由 @Rinoa 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议

















学习了 ~
感谢分享学习~
就在隔壁楼,可以认识一下
哈???什么楼
咱们是同事哈,下面留言的是微信吗?
想请教一下,通过上面的分析场景、建立故事、建立框架及流程后,那最终输出给开发进行实现的产出物,一般是什么?是2-15或2-16的意图表达库么?
需要更加具体和全面的语料表。
能展示一下是什么样的么?可以加你微信学习下么?
作者是科大讯飞谁?
哈哈哈,做翻译机的
跟xianling他们一个组?你在成都还是合肥?
她就是xianling
哈哈哈,对,她就是xianling,你又是哪位哇?
你好,文章写得很棒!可以认识下你吗,我们团队正在做一个关于车联网语音通讯(社交)产品,我的社交账号:1003424247
可以, 435026029
good work
thanks~
写的不错
继续努力~