
 起点课堂会员权益
起点课堂会员权益
懂你的推荐算法,推荐逻辑是怎样的?
 B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
作为一个喜欢思考人生的美男子,我时常感慨,现在这个年代,人们上网获取信息的成本真的好低。智能手机,人手一台,打开3G就能上网,百度一搜,什么都有。当然百度上搜出来的大多数可能并不是你想要的,但这并不妨碍上面的论点成立。也正是因为成本太低,人们反而不愿意主动取获取信息,于是各种各样的推荐系统有了大展身手的机会。
推荐在生活中是一个再平常不过的事情,你失业了,有人会给你推荐工作,你失恋了,有人会给你推荐姑娘。但是在我们这个机器远没有人类聪明的时代,这些事情要是交给机器去做,你就得设计出一套机器能理解的算法出来,这就是所谓的推荐算法。大家看到算法两个字不要慌,以为我又要搬一个大东西出来吓唬人。你可以把算法看做现实生活中的办事流程,它规定了你第一步干什么,第二步干什么,只要你按它说的做,就可以把事情办好。举个例子,你现在要做一个电影推荐APP,我们来看下整个过程是怎样的。
在推荐算法中,我们第一步要有一大堆要推荐的东西。也就是说,你的电影首先要足够多,才能满足不同用户的需求。算法再精准,最后发现推导出来的结果,在你的数据库中并没有,就悲剧了。第二步是要有用户的行为数据。这个也是越多越详细越好。这时候你要把看了哪部电影,看完没有,评价怎么样悄悄的记下来,上传到后台服务器。经过长期的积累,这些数据将为你以后的精准推荐奠定基础。
有了上面的数据基础,我们就可以进入正题了。推荐算法有不少,我们今天介绍一种最基本的叫做协同过滤算法。它的核心思想是物以类聚,人以群分。具体可以分为基于用户的协同过滤算法和基于物品的协同过滤算法。我一直觉得专业领域起这种高大上的名字,是用来过滤智商的,因为很多人看到这里就不打算往下看了,哈哈。
先看第一种基于用户的协同过滤。可以简单理解为我虽然不认识你,但是我通过查看你的朋友圈都是些什么人,根据人以群分的道理,他们喜欢的很可能就是你喜欢的。
假设从历史数据上来看,用户A喜欢《捉妖记》、《大圣归来》,用户B喜欢《栀子花开》、《小时代》,用户C喜欢《捉妖记》。那我们就可以简单认为AC二人口味相似,可以归到一个朋友圈里,C极有可能也喜欢A所喜欢的《大圣归来》。
这是最简单的情况,实际上仅仅用喜不喜欢来评价感兴趣程度是远远不够的,用户不可能看完还填个调查表选择yes or no,但是会通过一些其他行为比如影评、是否收藏来反应他们的喜欢程度。机器只能理解量化的东西,所以在算法中,这些行为会转化成相应的分数。比如完整看完的,给3分;看完还给了正面评价的,给5分;看到一半就怒删的,给负10分。这样每个用户都会有一个电影评分表,在计算两个用户相似度的时候,把这些数据代入下面这种专门计算相似度的公式,就能得到二人口味的相似程度。
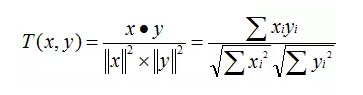
现在我们要给用户D推荐电影,分别计算AD、BD、CD的相似度,找到跟D最相似的用户,然后把他喜欢的,都推荐给D,就行了。(下面的公式叫做余弦相似度公式,通过计算n维空间中两个向量的夹角余弦,来表示相似度,大家感受一下就好,感兴趣的可以去问google。)
第二种是基于物品的协同过滤。基本思想是假设甲乙是相似的物品,那么喜欢甲的人,很可能也喜欢乙。还是上面的例子,现在假设用户E喜欢《栀子花开》和《小时代》,那我们可以推导出,喜欢《栀子花开》的用户(B和E)都喜欢《小时代》,那基本可以确定两部电影是相似的,下回来个用户F,他喜欢《栀子花开》,那我顺便就把《小时代》推荐给他,他可能比较容易接受。
大家可能要问,我的APP第一天上线,没有这些所谓的用户行为数据怎么推荐啊。这就是推荐算法面临的冷启动问题。这时候可以用基于内容的算法了。你可以事先把所有电影归个类,战争片归到一起,喜剧片归到一起,动画片归到一起。用户H看了一部喜剧片,你就把所有喜剧片推荐给他。显而易见,这种算法简单粗暴,当然命中率也最低。
真正的推荐系统会综合运用各种算法,加之机器学习和人工调优的不断改进,所以是非常复杂的。
#专栏作家#
给产品经理讲技术,微信公众号(pm_teacher),人人都是产品经理专栏作家。资深程序猿,专注客户端开发若干年,对前端、后台技术略懂,热衷于对新的科技领域的探索。
本文原创发布于人人都是产品经理,未经许可,不得转载。

















一些帖子热门的刷新逻辑是怎么样的呢 推荐逻辑又是咋样的呢
666
6666很有趣