
 起点课堂会员权益
起点课堂会员权益我们是怎么掉进个性推荐的怪圈?
本文围绕个性推荐展开了一系列的分析思考,并主要讲了独立因素推荐、融合因素推荐、推荐方式以及回声室陷阱等内容。

- 你刚在微信和朋友讨论AJ款式,看公众号就刷到了AJ的广告,淘宝首页也惊喜般地出现了AJ推荐;
- 晚上刷抖音总是刷个不停,感觉刷到的每一个视频都有某个点能戳中自己,你陷入寻找刺激的循环。
为什这些APP都知道你在想要什么且清楚你的兴奋点,是他们监控你的聊天记录?
不,是你的个人基础信息和行为数据告诉了他们你需要这些,他们就把你的需要主动给到你罢了。
那他们是怎么做到的呢?下面我们就来简单探讨下个性推荐。
这里是文章的结构图,图和文章可以对照看,方便理解。
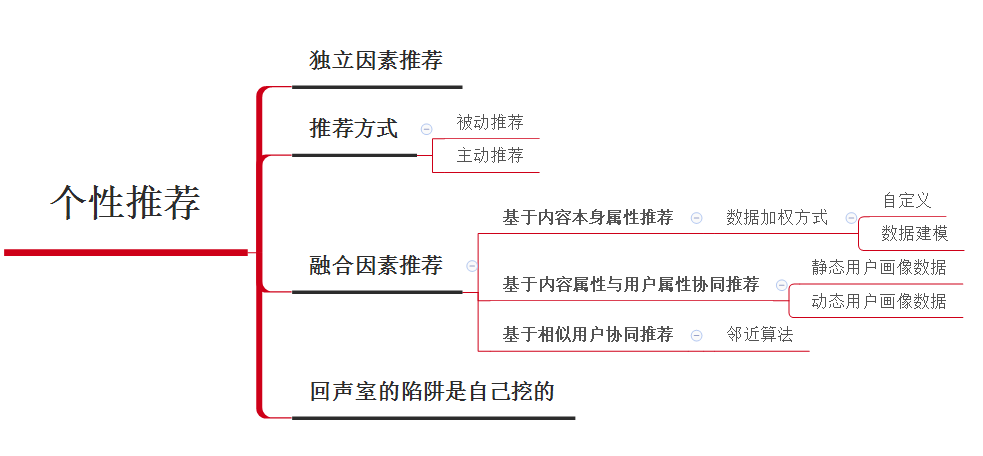
首先,个性推荐系统是为了解决信息过载,通过个性化推荐提高信息分发的效率和准确性,使得用户更有粘性而被广泛使用的系统。通俗的说他就是为了让你更爽,你要什么我就给你什么。
这很美好,但这里有一个陷阱,意思是你不要什么我就少点给你或者不给你——你也就失去了与你意见相左的知识领域接触的机会,单一的内容被推荐多了用户也会感到疲劳。
个性推荐用在电商领域来说应该叫“精准投放”——你想买什么淘宝就推荐给你什么,这像是双赢的感觉。
但对于内容领域(短视频等)来说,只推荐你有兴趣的内容,刺激你兴奋点的同时也让你接触世界的边界越来越窄,沉浸于自己营造的狭小的世界;难道我们进入这种回音室的怪圈之后就无法破解了吗?
(回音室效应:一些意见相近的声音不断重复,令身处其中的多数人认为这些声音就是事实的全部。)
我们先不急着解答,待我们逐步探讨下个性推荐的内容后,自己就能解答以上的问题;
独立因素推荐
独立因素推荐,就是推荐系统基于单个因素筛选的内容或商品推送给用户;我们在了解独立因素推荐的同时也了解下推荐的两种模式——被动推荐和主动推荐。
被动推荐
推荐是用户被动的接收信息,需要用户去触发而产生的推荐结果。
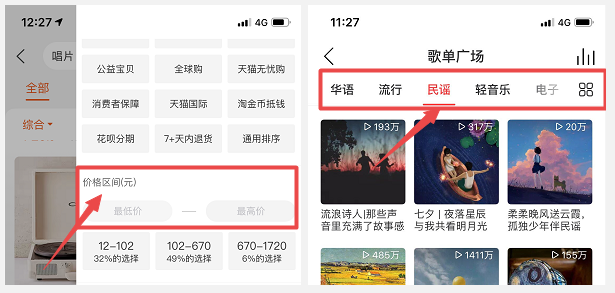
例如淘宝上用户依据价格区间的独立因素筛选商品,这种行为完全依据用户有意识的自主操作告诉淘宝我需要特定独立因素的商品,淘宝后台会依据你的输入信息进而对前端的你进行反馈。
假如用户不是选一个因素而是同时选择价了格区间+发货地区+品牌这三个独立因素时,这时后台进行筛选,把同时具备这几个独立因素的商品推荐给用户,这只是多个独立因素的简单物理标签相的加可以说还是属于独立因素推荐的范畴。(当然淘宝真实推荐结果更为复杂,因为有商品竞价排名,这些都会影响推荐的结果,目前是举例说明)
与之类似的还有网易云音乐的歌单广场,歌单广场将歌单分为了流行、民谣、电子等不同的类别,每一个类别就是一个因素,用户选择哪个因素的标签,后台系统就更新属于该因素的歌单的数据给到前端界面上展示,这类都是独立因素的被动推荐。
主动推荐
主动推荐,由系统定时更新数据并主动推荐到用户面前,用户打开界面就能接触到主动推荐的结果;如网易云音乐的热歌榜,抖音的人气热搜榜等就是主动推荐的方式。
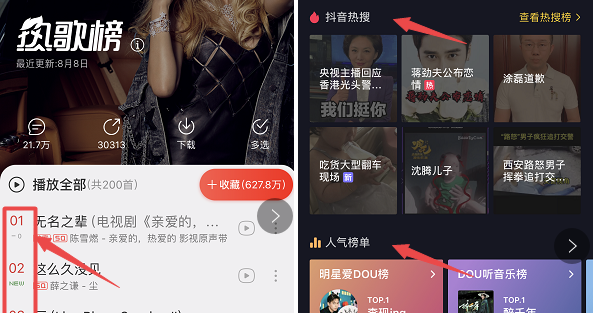
但这种热榜这种统一推荐的方式有一定程度的成马太效应——火的内容会得到更多的曝光越来越火,但大部分人喜欢的内容并不带代表每一个用户都是喜爱的,热门推荐满足用户从众心理的同时也忽略了用户的个性差异体验,所以就需要依据用户个性的推荐来弥补,随着用户对自我独特性的感知越来越强,需要个性化定制的需求也越来越明显。如何让特定的内容满足特定的用户,让用户开开心心的走进个性推荐的陷阱里就是接下来我们要讲的重点。
融合因素推荐
融合因素推荐就是将几个不同的因素依据特定算法融合而产生新的属性标签,并推荐到与该属性标签匹配的用户手机上。
我们把融合因素推荐分为基于内容本身属性推荐、基于内容属性与用户属性协同推荐、基于相似用户协同推荐这三种推荐方式。
基于内容本身属性推荐(推荐对象一般是所有人)
还是以抖音热门短视频为例,我们需要做的是依据内容的本身属性建立内容画像,用数据模型来表示内容的特征。
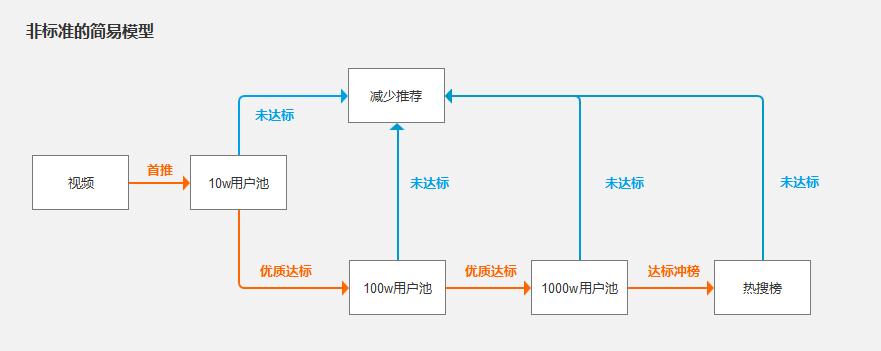
由抖音热搜榜可看到,我们把点赞数排名在前30的视频放上热搜榜。
当然决定点赞数的因素除了视频内容本身的类型及质量外,很大的关键还在于平台给多少人推荐了这个视频,即有多少人可以刷到了这个视频。平台判断一个视频是否值得推荐给更多的用户群体,又与历史用户对视频的交互行为息息相关。
例如:
短视频平台将一个审核过后的新视频先推荐给10w人的基础用户池进行播放展示,如果这10w人有很多人进行完全播放、点赞、评论、转发等操作,平台就判断该视频为优质内容进而推荐给100w、1000w的用户池如此类推。
如果该视频在10w的展示量中大部分用户对该视频不感冒,很少播放完或点赞,就会减少该视频的展示量或不会再推荐给更多的用户。
这形成一个优质内容能得到更多展示劣质内容减少展示的良性循环。(用户池也分不同种类的用户池,举例用非真实数据)
这样判断一个视频能否进入到下一个用户池的标准就成为了关键,现实中这个标准是根据模型动态变化的,现在我们先进行标准的静态分析这样便于理解;根据下面初级的算法公式可看到一个视频的优质程度与用户对这个视频的喜爱程度成正比,我们先用用户的喜爱程度这个特性来反应视频的优质程度。
视频优质度=用户喜爱度 X 视频质量基数 X 题材类别基数 X 平台广告基数
影响用户喜爱程度的独立因素有用户对视频的平均播放时长、点赞、评论、分享、关注以及不感兴趣等操作,每一个操作都会为一个独立因素增加数值;而且每个独立因素对与平台判断用户对视频的喜爱程度的重要性是不同的,如分享>评论>点赞。我们用权重来表示,对喜爱度高的因素进行数据加权,数据加权一般有两种常用方式:
自定义加权:产品经理、运营经理依据平时的数据报表人为的定义这些独立因素和设置权重因子的数值,这种方式比较直接也比较简单,但他局限于团队的自身经验,没有经过大数据的验证与现实还是有较大的偏差。
数据建模:数据建模简单的说就是将时间变量、独立因素、权重因子通过特定的算法公式进行计算得出该视频的一个优质度数值。根据这个数值进行推荐和排名,随着时间变量的改变,独立因子、甚至是权重因子也会依据一定的函数关系进行改变,整个模型的输入和输出都是动态变化的,而且我们不断的采集用户行为数据用来训练模型使其更加接近现实预测的数值。
基于以上信息我们就可以粗劣的得出一张反映用户对视频喜爱程度的参考表,该表也可以反映出视频的优质程度;
用户喜爱度=(播放时长量+点赞量+评论量+分享量 – 不感兴趣量+…)X 权重因子 X 衰减因子

(正常情况下,需要对各个指标做线性方程回归分析,确定各个指标具有独立性后,再做权重分析,以上面表格是非真实数据)
根据以上思路我们可以对视频进行优质程度和类型的评定,有了内容画像现在只需找到对这个视频内容感兴趣的用户把视频推送给他就行了,下面就是我们要说到的基于内容属性与用户属性的协同的推荐。
基于内容属性与用户属性协同推荐(推荐给特定属性的人)
我们通过采集一个人的基础信息和行为数据来对一个用户做定性分析,得出一个用户在互联网及现实中的各种特征,所有特征整合在一起就成为一个代表现实中用户的虚拟画像。
构建用户画像数据会用到静态和动态两类数据:
- 静态用户画像数据:我们在注册APP时通常会输入姓名、年龄、性别、允许获取位置、这些基础信息相对稳定。
- 动态用户画像数据:用户在平时生活对手机产生的操作行为,如你玩过的游戏、关注的公众号、消费记录,有没有房贷车贷发过红包买过保险,这些行为最后都会变成几千个事实标签,用这些事实标签构建模型计算用户的行为偏好。
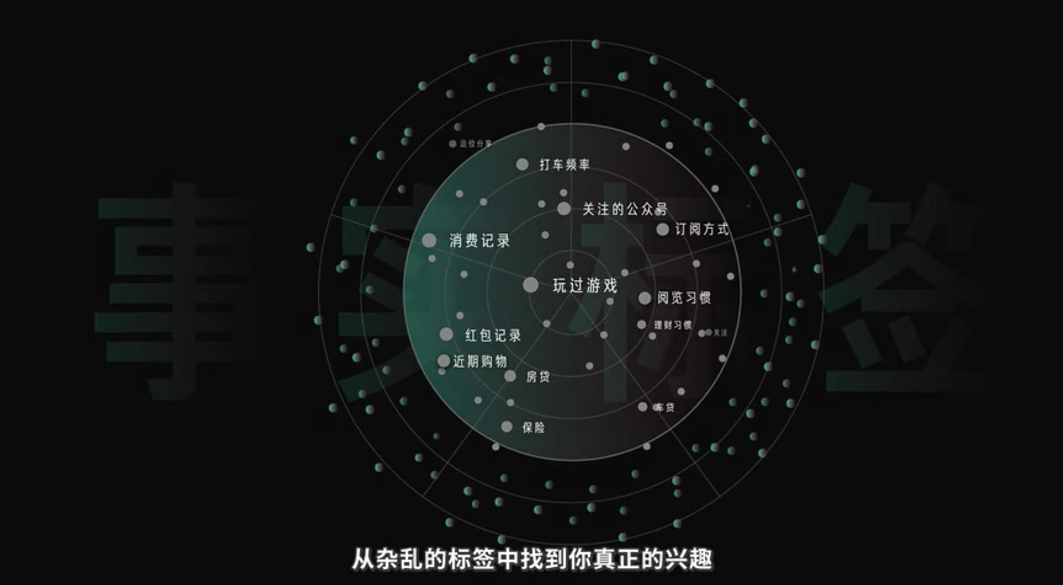
(图片来源于回形针PaperClip)
还是用上面提到的用户对视频的喜爱度的情况为例。
当用户刷抖音看到一个标签为美女类的视频点了一个赞,并不意味着该用户就喜欢看美女可能是不小心点的,这就需要更多的行为来判断该用户对美女类视频的喜爱程度;根据前面提到的初级公式:
对美女的喜爱权重=(播放时长量+点赞量+评论量+分享量 – 不感兴趣量+…)X 权重因子 X 衰减因子
除了点赞、评论、分享,关注了某作者这些行为外还有一个时间的限定,短期行为无法代表长期兴趣,单次行为的权重会随着时间流逝不断衰减,用户每次打开美女类内容都会生成一个兴趣权重,把一段时间内你所有的美女类兴趣权重进行累加,再用S型函数标准化就能得到一个0-10区间的兴趣值,标签值数值越高,就代表用户对美女就越感兴趣程度。
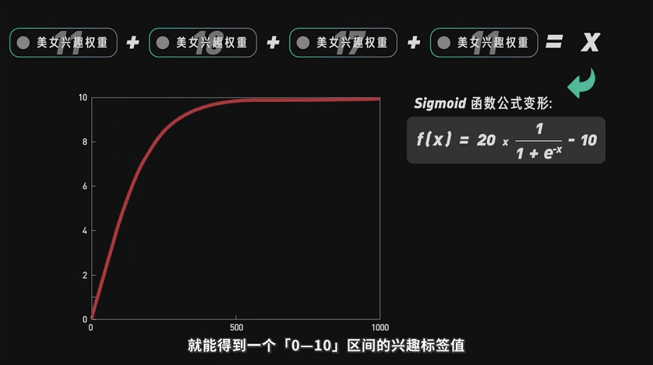
到了这里平台已可以计算出用户对某一类视频的喜爱程度和厌恶程度,同时也对视频做了分类处理,可直接根据用户的偏好将视频推荐给用户。
平台除了可以计算出用户在内容兴趣上面的权重外还可以在消费能力、社交偏好等方向进行建模计算,进而得出一个交为完整的用户画像。

另外通过行为直接推荐视频的效果往往不如通过同类视频推荐,找到和你一样的人,把他们的浏览记录推荐给你,往往比直接猜你喜欢什么效果更好!
基于相似用户协同推荐(人以群分)
如何找到和你一样的人
根据以上思路,我们在用户的美女喜爱偏好权重、社交偏好权重、消费能力权重等多个维度建立模型,计算用户的偏好,之后将这些偏好反映的权重值转化为特征向量!
如,我们把用户对美女的喜爱权重为8,社交偏好权重为5,消费能力权重为2,将向量理解成多维空间上的一个坐标,通过把每个用户的向量坐标代入余弦公式和距离公式中,就能计算出和你相似的人,进而把用户分类。
(这里用到的是邻近技术:利用用户的历史喜好信息计算用户之间的距离空间中的点越近越相似。)
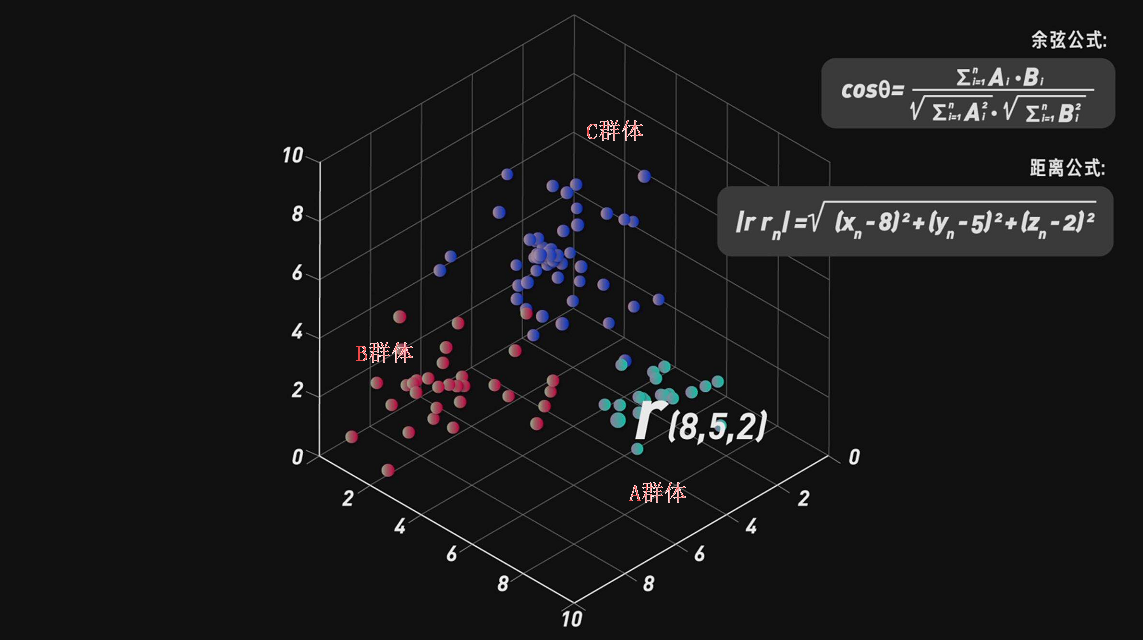
这样广告主或平台就可以依据与你相似群体的消费记录和喜爱偏好给你推荐商品或视频,这也恰巧就是你喜欢的类型。
需要说明的是,微信淘宝们采集的行为数据不仅仅对应你的账号,更与你的手机唯一识别码绑定在一起,这意味着你就算不注册不登陆,你的行为数据一样会被采集。同时广告平台也可以根据你的手机识别码在其他APP上为你投放广告,这样你在刷抖音的时候也能看到淘宝的AJ广告了!
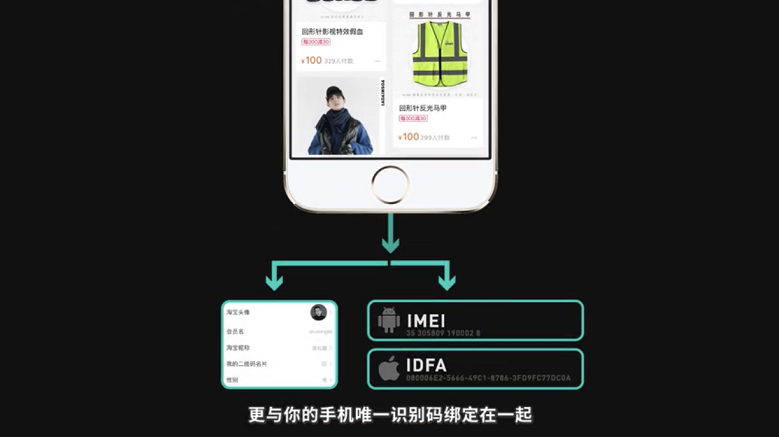
总的来说,你的一切上网行为都会在手机上留下操作的痕迹(基础信息和行为数据)。平台采集到这些历史痕迹进行数据清洗——结构化数据——建模分析,计算出你的行为偏好,根据你的偏好或同类人的偏好向你推荐商品和内容。
这也就是为什么你刚在微信和朋友讨论AJ款式,刷公众号就刷到了AJ的广告,淘宝首页也惊喜般出现了AJ推荐;晚上刷抖音总是刷个不停,感觉刷到的每一个视频都有某个点能戳中自己。
那么陷入回音室的怪圈又是怎么回事呢?(回音室怪圈:只推荐你有兴趣的内容,让你接触世界的边界越来越窄,沉浸于自己营造的狭小的世界)
回音室怪圈的陷阱是我们自己挖的
由个以上个性化推荐机制的流程可知,你现在的行为数据将决定你将来会接收到什么样的内容,从这个角度看个性化推荐的结果完全取决于你自己本身的倾向。
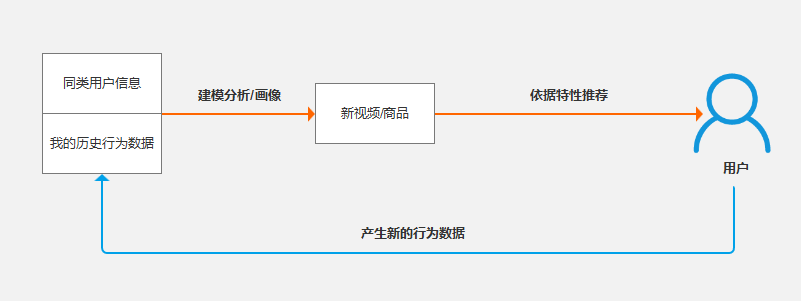
如果你刷抖音时能包容那些和你意见不同的人,能耐心看完或评论互动,那么根据个性推荐的机制,你的内容信息流中既有自己喜欢的内容也会有自我认知之外的内容,不用担心个性化推荐会把你留在回音室里面。
相反,如果你只接受那些你认同的意见或人,不能包容异己,将与自己观点不对等的内容拉黑处理,长此以往你的信息流里就会只剩下你喜欢的内容,沉浸在自己打造的回音室里。
个性推荐只是依据你的习惯做出的推荐结果,让你掉进回音室怪圈里的还是你自己。
参考书籍:《个性推荐》
用例及图片来源于:回形针PaperClip
本文由 @瓶盖 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议









iPhone用户还可以在设置-隐私-广告中关闭IDFA码来限制这些APP对你的数据采集
而且根据个人信息安全规范,商业平台的所有广告标签都应该避免精确定位到个人以保护用户的隐私安全
写的很不错,涨知识了
写的很棒,真的很棒,希望能多写几篇,或者私下交流一下
谢谢😊
你好看完分析之后有几个问题想请教一下
1微信聊天内容会存储在本机,为保护用户隐私腾讯服务器不会存储,那么腾讯广告平台是如何获取并分析“用户想买AJ”呢?
2微信聊天内容有AJ,淘宝属于阿里系,阿里广告平台如何获取“用户想买AJ”,然后首页推送AJ商品呢?
这道题首先要用排除法,首先排除聊天内容是用语言聊天
共享账户信息方向考虑试试
你好,感谢你的阅读和讨论
1、其实你聊AJ只能代表你有想了解AJ的冲动,采集这个冲动并不是通过你的聊天记录,而是你带着这种冲动在其他APP上留下的行为痕迹,比如在UC浏览器上搜索AJ、在微博上流量AJ的照片,在抖音上看一个AJ视频点了赞等,这些行为都会被捕捉到;
2、阿里投资了UC,也有30%的新浪微博股权,腾讯也投资了各种APP,他们在数据上应该都有合作,上面的那位网友【小权】说的一个方向很对,共享账户信息,还有一些专门做采集数据的公司会和广告平台合作,现在是 得数据者得天下;
推荐系统很大,我也在学习了解,以上也是基于现有知识的想法,欢迎讨论[握手]
有可能都是从输入法获取相关数据?