
 起点课堂会员权益
起点课堂会员权益用户画像如何从搭建到应用实战?
用户画像是指根据用户的基本属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。那么,我们要怎么去应用这些用户画像呢?

一、用户画像是什么?
用户画像是指根据用户的基本属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。每一个标签及标签权重即为用户的一个向量,一个用户可以理解为超维空间的多个向量(标签)的和。即通过数据方式来描述用户,最终将一个用户表达为计算机可识别的用户,以此为基础实现用户画像应用。
二、用户画像应用
当一个用户可以被计算机全面识别理解后,我们就可以用来做精准营销、个性化推荐等基础性工作,其作用总体包括:
- 精准营销:根据用户特征,针对特定群体,利用短信、邮件、AppPush、App弹窗、微信公众号、微信群等方式进行营销。
- 用户统计:根据用户的属性、行为特征对用户进行分类后,统计不同特征下的用户数量、分布;分析不同用户画像群体的分布特征。
- 个性推荐:以用户画像为基础构建推荐系统、搜索引擎、广告投放系统,提升转化率。
- 行业研究:通过用户画像分析可以了解行业动态,比如人群消费习惯、消费偏好分析、不同地域品类消费差异分析。
三、用户画像如何提供以上能力
用户画像有以上应用,到底是怎么应用的呢?我们一个一个解释一遍。
1. 精准营销
根据用户特征,针对特定群体,利用短信、邮件、AppPush、App弹窗、微信群、h5等方式进行营销。如果没有用户画像,也能完成 短信、邮件、App push、App弹窗的运营,但是不能保证资源有效利用。
为什么这么说呢?在平台用户量低的时候,我们很容易做运营,我们将运营内容全量推送,发现召回率、转化率并不会很低。这是因为初期我们的用户都很精准,所以召回率转化率不会很低。但随着用户基数的逐渐增加,这种运营效果越来越差转化率越来越低。
因为随着用户量的增加,推送的内容只能打动那一小撮人,为了提升转化效率,运营位资源的有效利用,我们需要借助用户画像的能力。
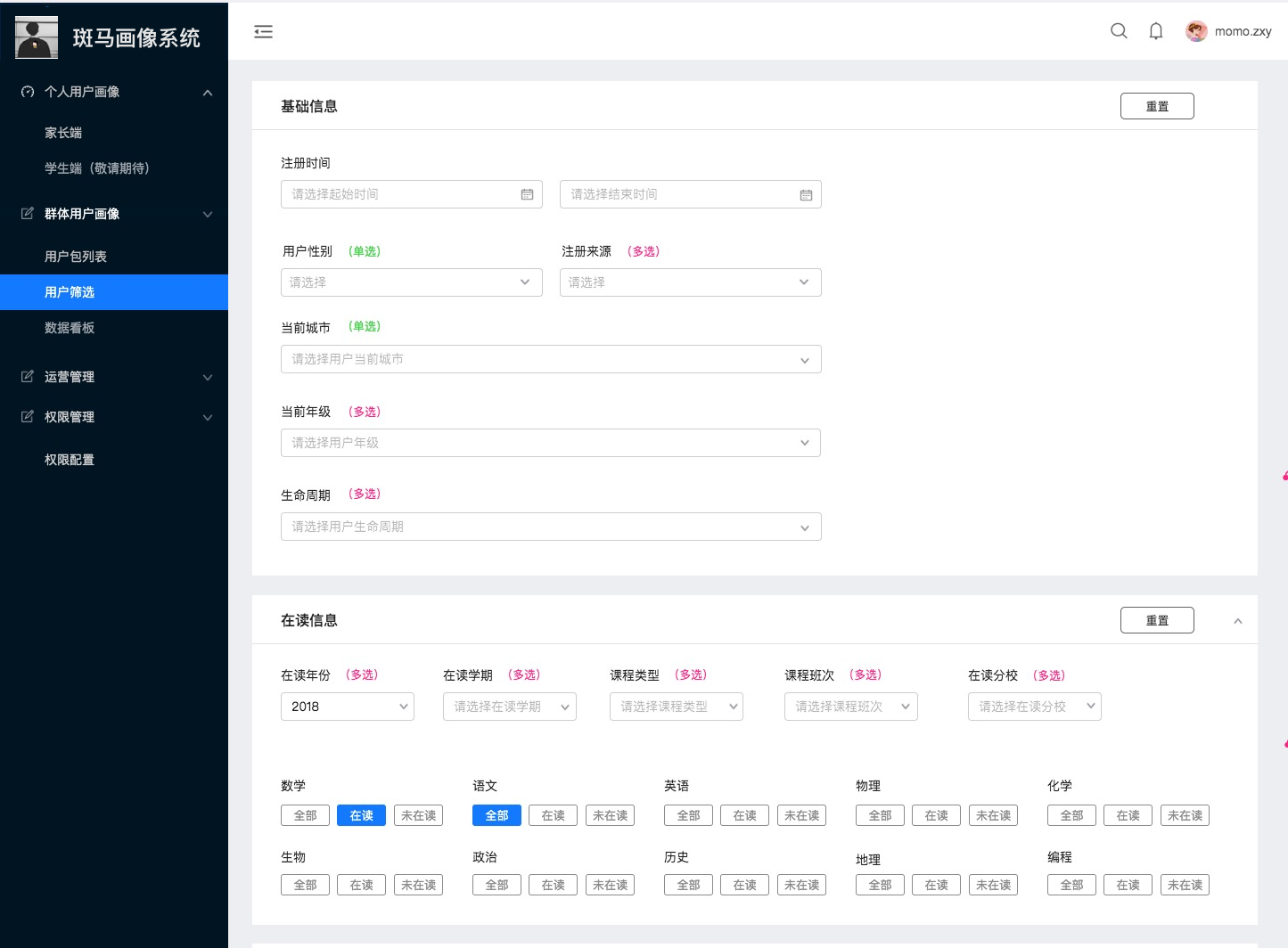
(1)分群运营
分群运营是此问题很好的解决方案,通过用户画像的标签筛选,筛选出不同的用户群,筛选出的用户群每个用户群都有一个唯一id。通过push或弹窗配置平台,输入用户群id实现精细化运营。
(2)自动化运营
我们让用户群的粒度无限小,最后会小到一个个体。我们针对每个个体去做push或者弹屏,运营效率还是太低了。基于用户画像的自动化运营就发挥了作用。我们一起看一下如何实现自动化运营。
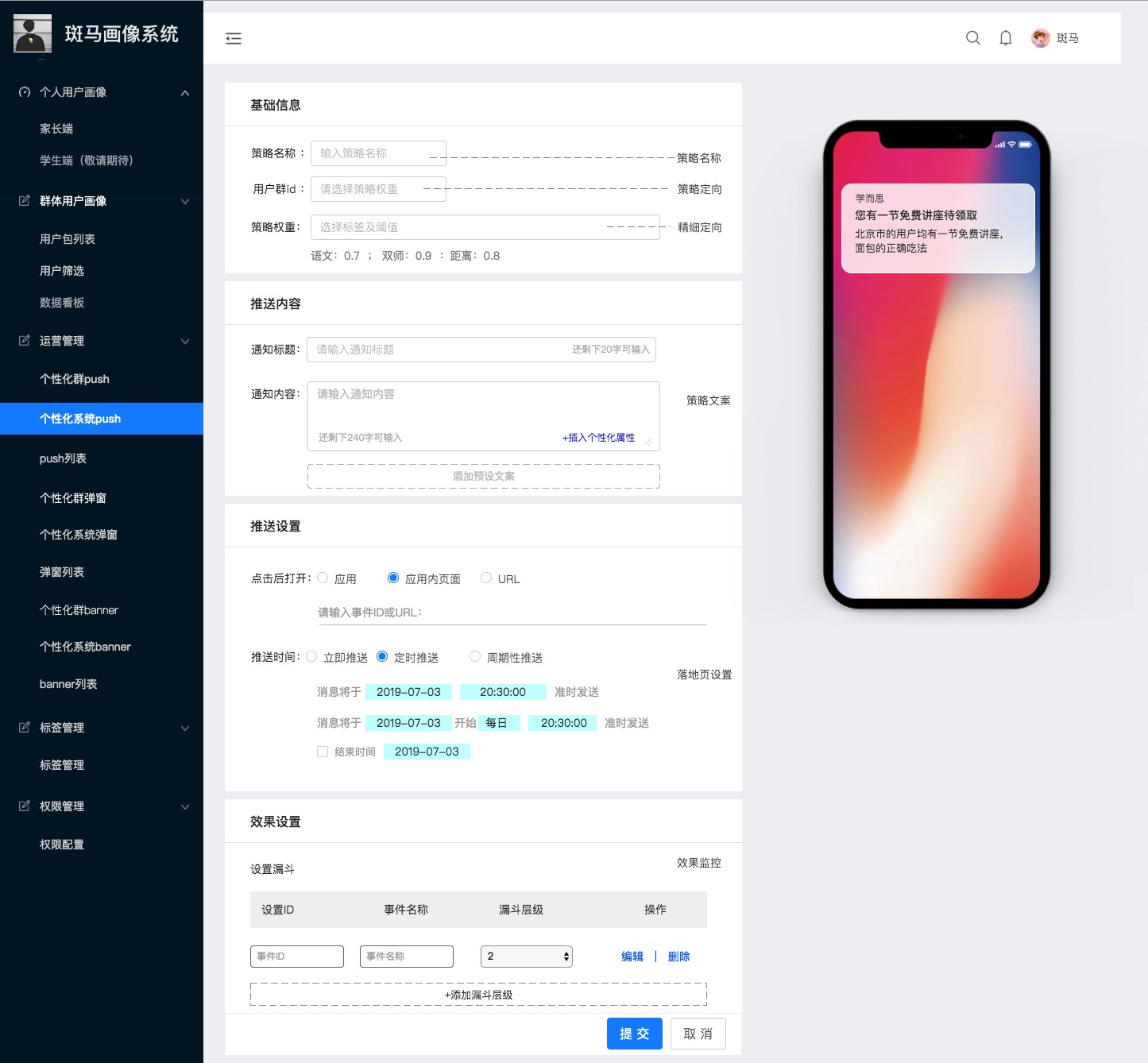
- 粗略定向(城市:北京;属性:新用户)此类设置为满足业务需求,比如暑假低价课的广告弹屏只针对没有购买过长期班的用户。这是通过事实标签来实现。
- 精细定向:设置偏好标签及标签值来确定精细用户群。原理很简单,给一个策略设定好偏好标签及标签权重后,相当于在空间中绘制出一个用户向量,我们用真实用户向量与此向量进行空间向量的余弦相似计算,或欧几里得距离计算相似性,最相似的则优先显示。如果相同相似则按创建时间倒叙展示。这样设定权重好处:可以很好的避免不同业务部门App内流量的争抢。只有设置的标签才参与计算,不是全部标签进行相似计算。
- 设定push文案
- push落地页
- 设定开始结束机制(时间控件)
举个例子:
背景:
- 暑期结束场景下的收心课;
- 针对没有报名暑假长期班的学员;
- 目标100w。
配置:
- 设置人群;没有购买2019暑期长期班的学员;
- 设置权重:数学:0.8,短期班:0.7,暑假:0.6,开学:0.5;
- 设置文案:亲爱的斑马家长你好,暑假愉快,学而思网校为您准备9.9元 10节暑假数学收心课;
- 设置落地页:www.banma.com;
- 时间设置:2019/08/23-2019/08/24。
图示:
2. 用户统计
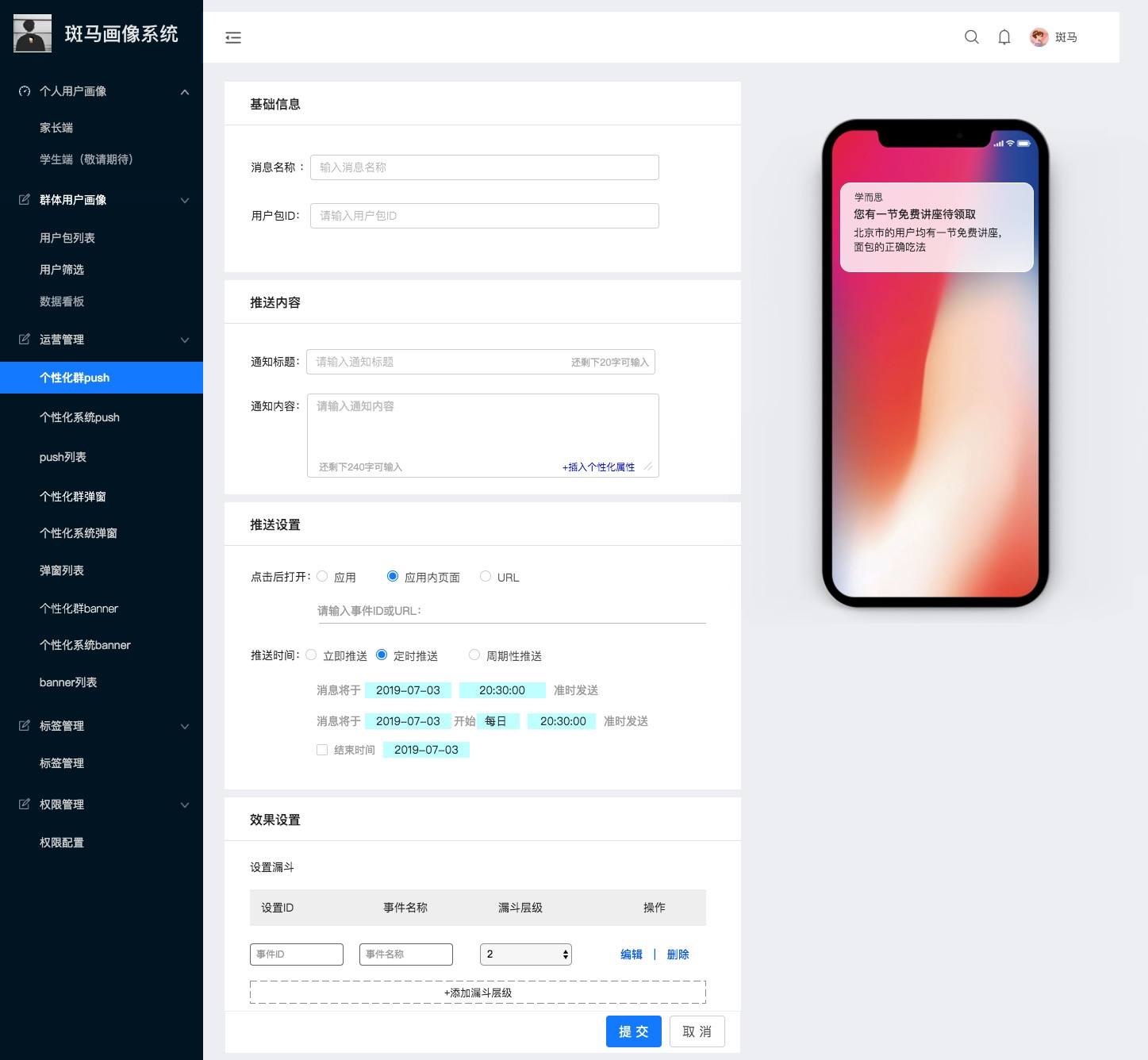
根据用户的属性、行为特征对用户进行分类后,统计不同特征下的用户数量、分布、走势等。
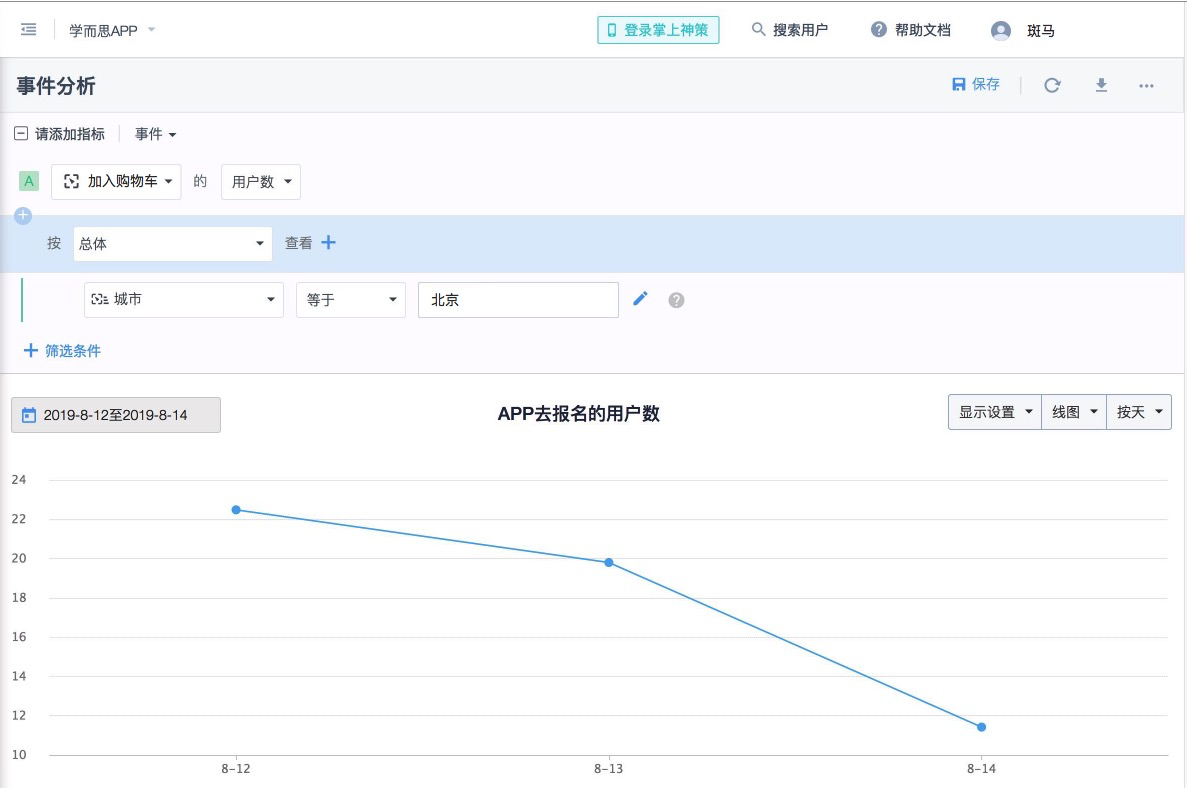
这里不做多阐述,参考神策。截图大家参考下,数据已脱敏。
北京的-完成加入购物车操作的用户数的趋势
3. 用户组成
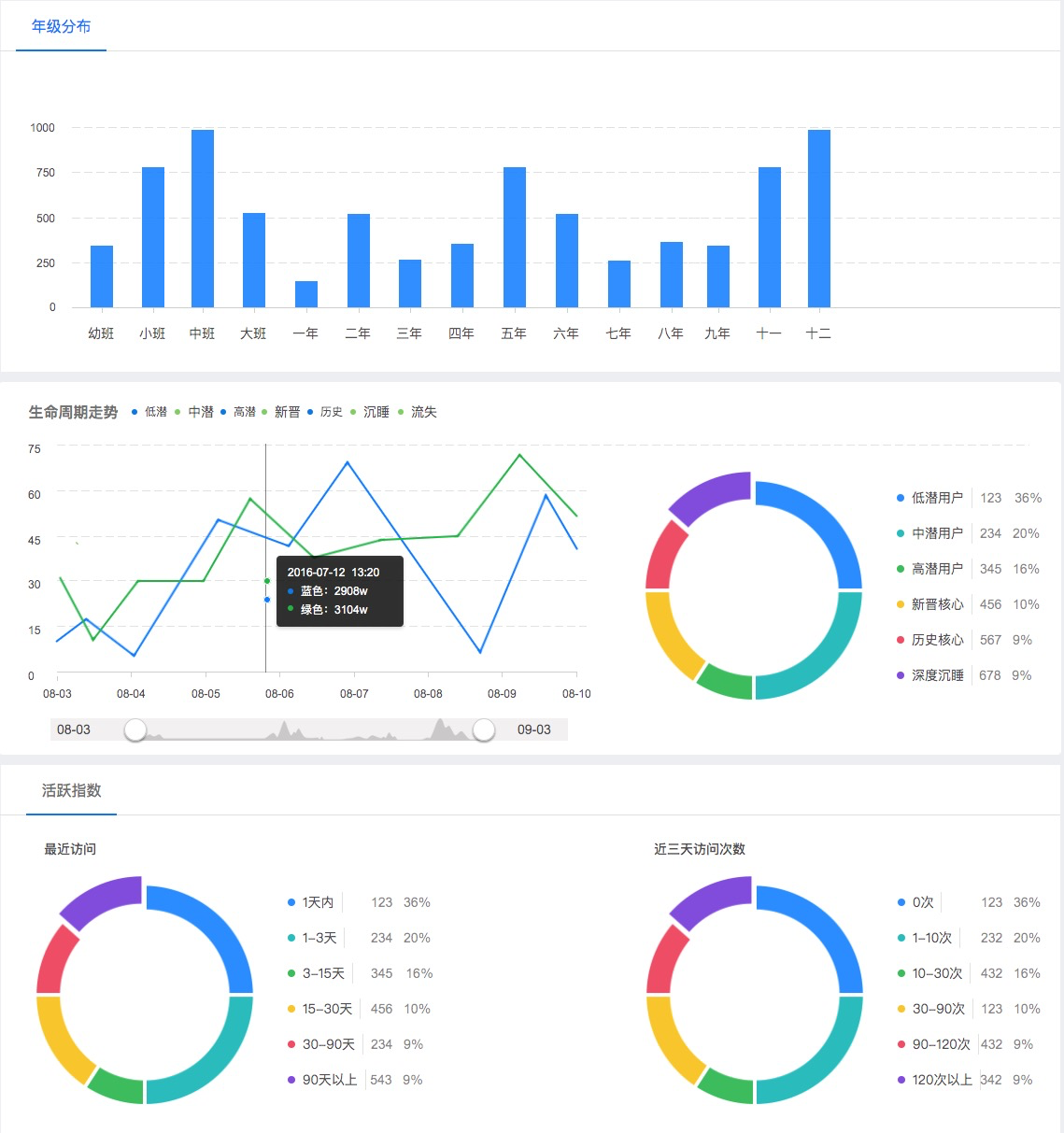
4. 个性推荐
个性推荐:以用户画像为基础构建推荐系统、搜索引擎、广告投放系统,提升转化率。
这里重点介绍一下推荐系统,其他与推荐逻辑大同小异。
推荐系统一般都分为召回和排序两个阶段。因为全量物品(Item)通常数量非常大,无法为一个用户(User)逐一计算每一个物品(Item)的评分,这时候就需要一个召回阶段,其实就是预先筛选一部分物品(Item),从而降低计算量。
海量 Item——召回(粗排)——候选集合——排序(精排)——排序列表——规则(多样化推荐)——推荐结果。用户画像除了用于最终匹配评分,还要用于在召回。
那用户画像是如何做召回?
我们先看一下用户画像的用户偏好表存储(用户画像有好多个表,文章画像构建部分会 具体讲解):

当我们购买完成一个带有标签id1,标签id2,标签id3的课程后,一般在购买完成页会有交叉销售场景,我们通过用户偏好表的标签及权重,基于用户相似,或Item相似的协同过滤算法,召回一部分课程。这就是粗排的过程。简单理解就是找到用户喜欢的其他课程。
协同过滤:基于用户相似推荐:欧几里得距离公式 userid1 与 userid2 =√ [(标签id1-标签id1)^2+(标签id2-标签id2)^2+···(标签idn-标签idn)^2]
5. 行业研究
行业研究就很好理解了,我们经常听到马爸爸拿一些标签,说明这个地方人喜欢买什么?为什么喜欢买?那个地方人喜欢买什么?为什么喜欢?
最经典的就是每年的年终总结H5,这里不多赘述此内容。
四、用户画像的搭建
1. 标签管理系统搭建
(1)什么是标签管理系统?
标签与用户画像的关系,在介绍什么是用户画像时候就已经说过。
我们说一下什么是标签管理系统:
一般来说,将能关联到具体用户数据的标签,称为叶子标签。对叶子标签进行分类汇总的标签,称为父标签。父标签和叶子标签共同构成标签体系,但两者是相对概念。
用户画像的本质就是使用不同的标签来描述表达用户,那这些标签是需要我们事先准备好的。每个用户都有成千上万的标签,我们维护这么大量级的标签,我们事先一定要构建健康的标签体系。
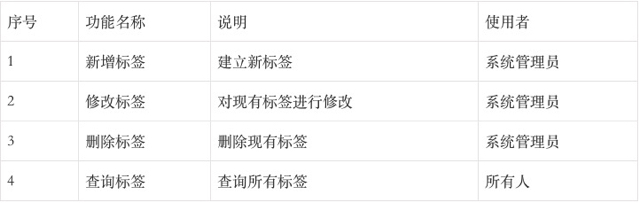
所以标签管理系统要支持对所有标签查询、修改、删除、新增等功能,主要包括两个模块:标签树和标签查询。
- 标签树:以树形结构呈现标签之间的层级和逻辑关系,并且可以对任意层级的标签名进行修改、新增和删除;
- 标签查询:对某一时间段内的标签进行查询,可以实现自定义查询及条件查询,并实现标签下的用户数的统计功能。
(2)标签管理系统功能列表
(3)标签管理系统页面
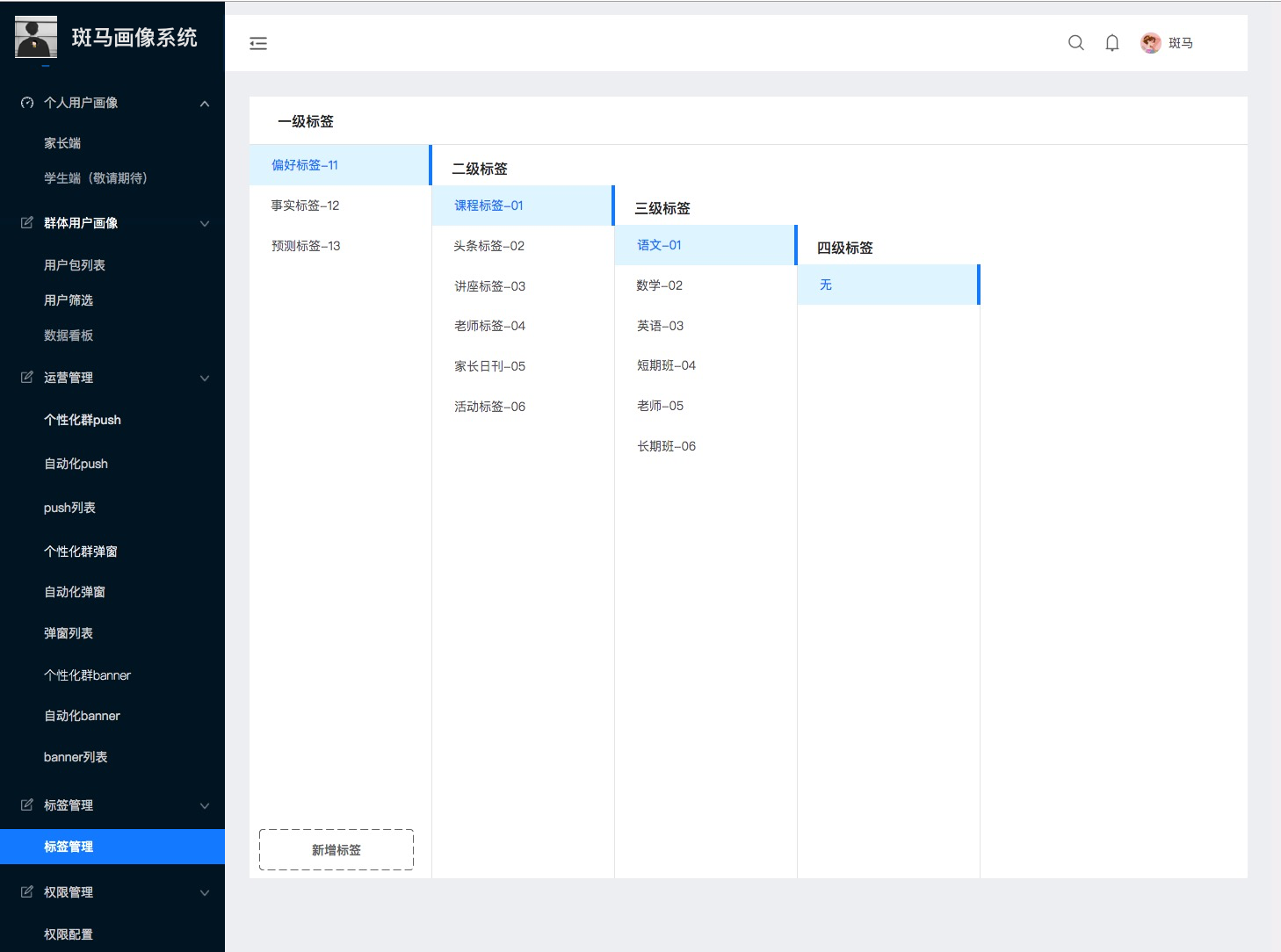
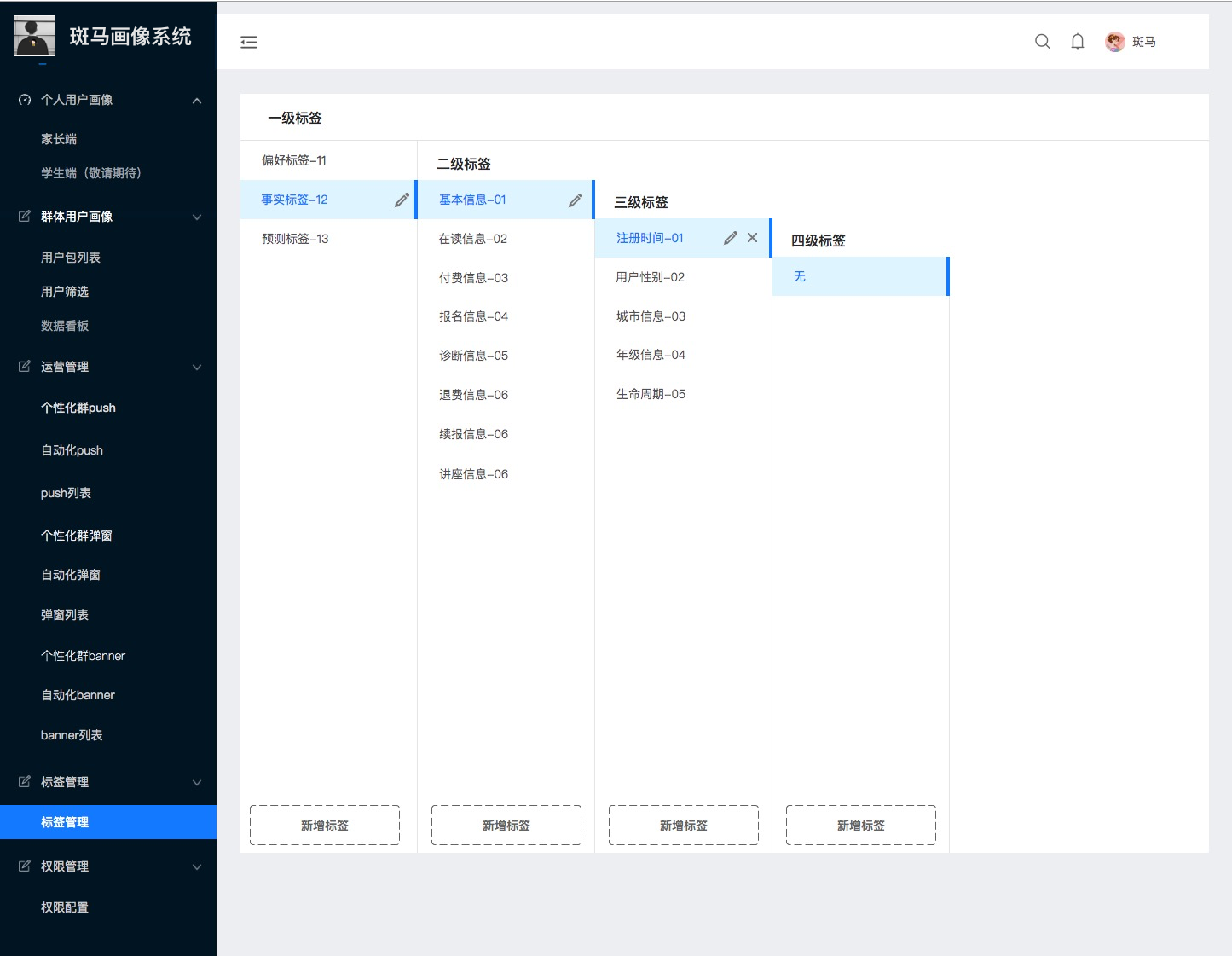
(4)标签体系构建
1)偏好标签
偏好标签简单理解就是用户对不同标签的喜爱程度,通过用户与标签的行为类型、行为权重、行为次数、时间衰减来计算。后续具体讲解如何进行计算,偏好标签是做推荐及策略方向最重要的标签。
2)标签梳理
该类标签梳理很简单,在我们数据仓库中有不同的内容表。
比如课程数据库表结构:上课地点、上课时间、老师、价格、大纲、评价……
比如教师表结构:教师名称、有无教师资格证、年龄、学校、性别、评价……
这里每一个字段就是一个偏好标签,当然字段值也是标签。因为用户与这些内容发生关系,间接是与这些标签放生关系。
偏好标签是固定的,不可编辑修改,数据来源于平台内全部内容的表字段及值。
3)事实标签
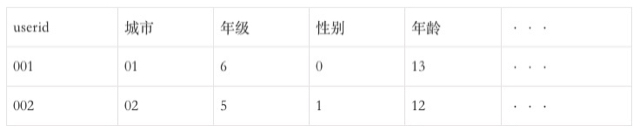
- 信息标签:用户的基本信息标签(城市、年级、年龄、性别……)
- 业务标签:来自业务的标签(在读、非在读、长期班、短期班、语文、数学、英语……)
- 规则标签:自定义的规则(低潜、中潜、高潜、核心)
4)标签梳理
用户基本信息,用户业务信息,工作人员定的规则,比如:低潜用户,中潜用户……
5)预测标签
这种标签是根据机器学习预测的标签,比如:流失预测,虎跃预测,转化预测等等。
6)标签梳理
很简单,就那么几个想预测啥就添加啥。标签之间具有层级的逻辑关系,1级是2级标签的父级,2级是1级标签的子级,以此类推。
偏好标签不可编辑,数据来源于不同内容的表字段。事实标签与预测标签当子级有内容则父级不可删除,但可编辑。只有下一级没有任何子级的情况下可以进行删除操作。
2. 标签权重计算
这里的标签权重计算特指偏好标签。
画像的用户偏好标签存储结构:

这里的每一个用户每一个标签下的值就是标签的权重,这节讲解的重点。
这个标签权重影响着对用户属性的归类,属性归类不准确,接下来给予画像对用户进行推荐,精细化运营也就无从谈起。
(1)基于TF-IDF算法计算
1)算法思想
用户标签权重,是由该标签对用户本身的重要性与该标签在业务上,对用户的重要性共同决定的。
标签本身对用户重要性是通过TF-IDF计算得到的,业务权重是通过用户对标签的行为来决定的,即:
- 用户标签权重 = 业务权重* TF-IDF权重
- 用户标签权重 = 行为类型权重 * 行为次数 * 时间衰减* TF-IDF权重
2)简单理解
就是用户对一个标签,会有不同行为触达,不同的行为有不同的难度,比如:购买行为大于搜索行为,搜索行为大于浏览行为。所以不同行为就会有不同的权重,行为越难代表越喜欢,权重越高同理行为次数越多也代表越喜欢。
标签对这个用户来说越稀有代表越喜欢,喜欢程度会随着时间的增加而逐渐降低,通过这个公式计算标签权重。
3)行为类型权重
用户浏览、点击、搜索、收藏、分享、下单、购买等不同行为对用户而且有不同重要性,一般使用层次分析法定义一个基本行为权重。
4)行为次数
这里的行为次数表示每一种行为的次数。
5)时间衰减
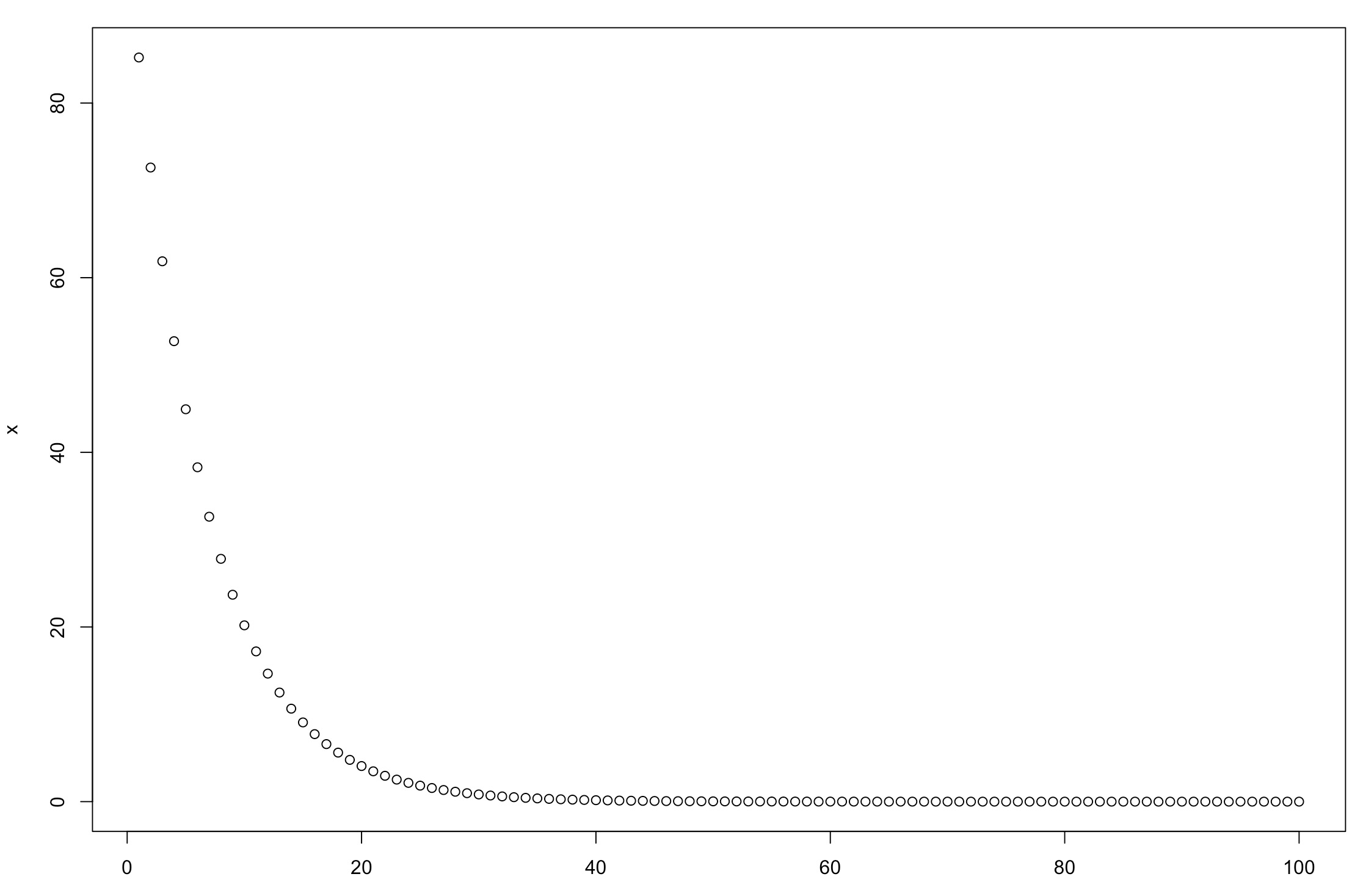
时间衰减是指用户的行为会随着时间的流逝,用户偏好会不断减弱。在建立与时间衰减相关的函数时,我们可套用牛顿冷却定律数学模型。
牛顿冷却定律:
较热物体的温度F(t)是随着时间t的增长而呈现指数型衰减,其温度衰减公式为:F(t)=T×exp(-α×t)。
- T:初始温度
- α:衰减常数即冷却系数,是自己定义的数值,一般通过回归可计算得出
- t:时间间隔
冷却系数如何计算呢?
冷却系数是自己定义的数值,一般通过回归可计算得出。例如:初始温度100摄氏度,1小时后的温度为85摄氏度,即 85=100×exp(-α×1),求得α=0.16。
在这里我们用R语言来模拟一下这个冷却曲线:
wendu<-100*exp(-0.16*t) t<-c(1:100) plot(x)
t<-c(1:100)
plot(x)
6) TF-IDF
TF-IDF = TF*IDF
TF:
这里我们用 N(P,T)表示一个标签T被用于标签用户P的次数。
TF(P,T)表示这个标记次数在用户P所有标签标记次数中所占的比例。
TF(P,T)= N(P,T)/Σ N(P,Ti)
N(P,T):打在某用户身上某个标签的个数
Σ N(P,Ti):该用户身上全部标签的个数
Ti 该用户全部标签个数
IDF:
IDF(P,T):表示标签T在全部标签中的稀缺程度
如果一个标签出现的几率很小,同时被用户标记某个用户,这就使得该用户与该标签T之间的关系更加紧密。
IDF(P,T)=Σ Σ N(Pi,Ti)/ΣN(Pi,T)
Σ Σ N(Pi,Ti):全部用户的全部标签之和
ΣN(Pi,T) :所有打T标签的用户之和
7)计算方式
举例子:
用户“斑马”,对于标签“语文”的标签权重计算:假设我们之前定义 冷却系数α=0.16。
行为表:
2019-08-22

2019-08-23

2019-08-24
用户“斑马”对标签“语文”的权重:
2019-08-22:语文=2*0.1+2*0.2+3*0.6+1*0.5+1*0.9=3.8
2010-08-23:语文=3.8 *exp(-α*1)+1*0.1+1*0.2+2*0.6+1*0.5+0=5.067718
2010-08-23:语文= 5.067718*exp(-α*1)= 4.318424
3. 标签存储
(1)事实标签
1)基础信息表
2)事实标签-在读信息表
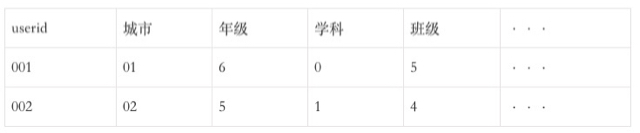
3)事实标签-报名信息表
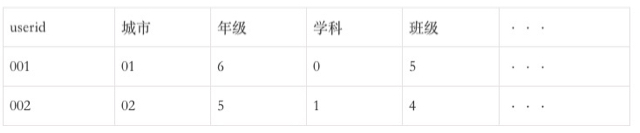
4)事实标签-规则信息表

(2)偏好标签&预测标签
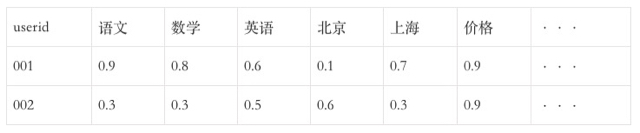
本文由 @斑马 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










F(t)=T×exp(-α×t)这个公式里的“×”是乘号吗?还是未知变量“x”啊?
学习了
想知道怎么找到合适的时间衰减系数
学习了,感谢分享!
vx:13126701193