
 起点课堂会员权益
起点课堂会员权益豆瓣读书VS当当网:谈推荐策略如何定义理想态
推荐板块是用户习以为常的APP板块,从这一小小板块可以看出什么呢?

下图展示的是一个产品从发现问题到解决问题的整个循环,产品经理的工作都是围绕这这几个阶段展开的,本文将以豆瓣读书为例分析其在实际生产中的应用。
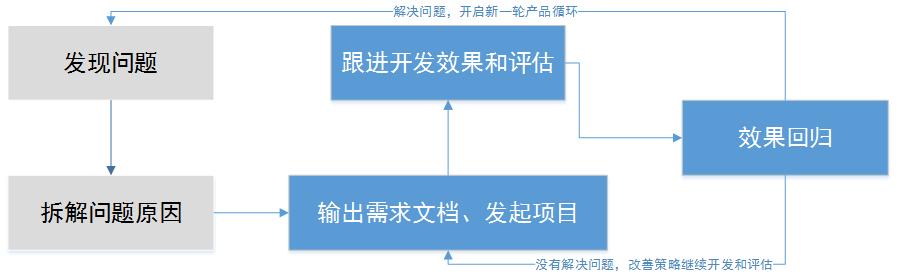
为什么要定义理想态

上图是PM发现问题的几种途径,理想态在其中各个途径中都起到了重要的作用,下面我们来详细分析。
首先我们需要明确理想态是什么,任何一个产品和策略的本质目标都是解决用户的问题,理想态即描述了在最佳解决问题规则下的输出结果。
比如滴滴,他的产品目标是为用户和司机提供一个平台,将资源(司机、乘客双方)最大化利用。那么滴滴的理想态就是乘客都能打到车;当然司机也是滴滴的用户,我们在这里只描述乘客的理想态。
如果我们将这种理想态转化为参数指标,也就是交易完成率=100%,这显然是不现实的。但是通过对未达理想态的case进行拆解,并merge过程指标的信息可以帮助我们分析平台未达理想态的原因。
意义一
帮助PM发现问题,找寻未达理想态的优化点。
还是滴滴这个例子,假设我们发现现在的交易完成率大概是95%~99%,我们在进行策略迭代和优化的基础是现有数据的稳定,而我们每天进行人工核实的话费时费力,所以我们基于交易完成率这个指标建立了指标监控机制,帮助我们衡量数据的波动情况。
意义二
通过对理想态的抽象,得到监控指标,并根据历史数据定义指标阈值,监控系统可以自动衡量指标的稳定程度,方便我们在指标变化不合理时快速发现问题,及时响应。
以上都是产品的核心指标,当我们新上一个策略时,策略也具有理想态。
比如一个新的运营策略是希望大家都能参与到平台的活动中,那么理想态就是所有的用户都看到了该活动push,都点击并且都参与进来。
这显然也是不现实的,但是我们可以提取出三个指标——活动push覆盖率、用户点击率、参与转化率。通过对这个指标的监控我们可以衡量策略的收益情况。
意义三
抽象理想态,在效果回归中帮助我们判断策略的收益情况,进而判断是否开启一轮新的产品循环。
那我们最后的一个目标主要作用在用户反馈搜集上,用户反馈的信息多频多维,而我们如何去其糟粕,取其精华呢?这根线就是我们对平产品理想态的理解。
比如用户和滴滴客服抱怨,说接他们的车里面卫生不大好、太脏乱了,而这个显然不是现阶段的产品目标,我们能做的最多也就是对司机进行教育。
又比如有用户说司机总是会取消订单,建议增加取消险之类的东西,这个在现有阶段也没有在我们理想态范围内,可能随着产品的阶段性进展,后续会纳入理想态,但是目前这个反馈不会起到什么作用。
意义四
确定产品目前的理想态范围,合理清洗用户反馈。
要注意的是,理想态不是一成不变的,随着产品目标和阶段的不同,理想态也会发生变化。
豆瓣阅读vs当当网——智能推荐版块
1. 分析产品(策略)目标
如下图,我们在进行一本书的搜索时,网页还会给我们显示“喜欢这本书的人也喜欢……”这一信息:

这个版块在各类产品中都非常常见,那么首先我们需要明确的是产品目标是什么,简单来说就是平衡用户、资源和环境之间的关系,提供最优的匹配策略。
1)用户角度:方便有趣
感兴趣:用户希望在这里看到的都是他所感兴趣的图书推荐,不会他搜索了村上春树的小说想着放松一下心情,但是下面给他推荐的是他最讨厌的数学课本。
低成本:方便是所有用户在所有平台的诉求之一。
- 首先用户希望看到的是图文并茂的展示方式,如果只是一些超链接,那么体验就会大打折扣,增加了用户的阅读成本;
- 其次用户希望他们感兴趣的书不需要过多的翻页和下拉就能看到,这是减少用户的操作成本;
- 同时用户希望我能迅速获取到足够的我所感兴趣的信息,不需要再进行跳转,比如这是买书的网站,就该显示给我书的价格,我可以迅速的决定是否进行详细浏览,这也是对操作和阅读成本的减少。
总而言之,用户关注的是时间成本,让他们用同样的资源做更多的事情。
2)平台角度:拉新促活,资源转化
高用户活跃程度:用户是每个产品的存在之本,高用户活跃程度可以从两个方面加强:提升用户基数,促进单一用户活跃程度。所以平台的首要目标是满足用户的目标,即方便有趣。
资源转化:一个产品能够发展壮大,生生不息那么一定形成了闭环。
抖音的生态闭环:高质高量视频素材>用户看视频>用户点赞、送礼物等>主播得到收益继续产出/用户自身从观看者变成资源输出者>高质量视频素材。
那么从图书产品的角度而言也形成了一定闭环。
- 营利性产品:“用户搜索浏览>用户购买>用户认为体验不错>用户再次进行搜索浏览”,所以营利型产品闭环在购买>再次搜索上,所以其目标是提高交易转化率和购买后再次搜索的比例,进而促进资金的流通和信息——主要是用户画像的丰富。
- 非营利性产品:“用户搜索浏览>用户阅读图书>用户输出图书信息>用户再次进行搜索浏览”,所以非营利性产品闭环在用户从观看者变成输出者上。因此要提高产品点击率,以及用户从观看者变成输出者的转化率。但是沉默的永远是大多数,此类平台对用户的信息抓取能力是不如营利型平台的,因为用户没有必要建立账户,大量用户是以访客身份浏览的,所以更多的是促进图书信息的丰富。
2. 当当vs豆瓣:示例说明平台目标引起的展示差异
我们以当当网和豆瓣读书为例说明两者差异,以下是我在两个不同网站中搜索《运营之光》后得到的结果。
当当网:

豆瓣读书:

下面我们来进行差异分析,说明平台性质不同带来的推荐模块上的差异。
1)占据版面的不同
由于当当网主要是以盈利作为其根本目的,其推荐类图书的透出率越大越好。所以我们可以看出在经常购买商品一栏有五本图书展示,在“购买此商品的顾客还购买过”一栏实际上是有6*10也就是60本图书的展示,当当网的一本书智能推荐结果有65本。
后者是在豆瓣上的搜索结果,可以看出一本图书对应的智能推荐只有7本,就算占据所有的版面也只有10本,远远小于当当。
2)推荐维度的差异
首先我们来看一下两者给智能推荐版块命名上的差异,当当网命名为了“经常一起购买的产品”、“购买此商品的顾客还购买过”,豆瓣命名为“喜欢读xxx的人也喜欢”。从命名上看当当的智能推荐提供更泛泛、不具有指向性,也就是更多维,豆瓣的命名就限制了其推荐图书也是定位在与搜索图书类型、关键字、作者等存在一定关联的书籍上。
从具体的推荐上来看,在当当网截图的十本书里有三本是属于和搜索书籍“八竿子也打不着”的,所以其推荐结果会更智能和多元;而在豆瓣的搜索结果中推荐的7本书都和搜索书籍具有强相关性。
3)排序结果的差异
我们分析一下当当网的智能搜索排序结果,“经常一起购买的商品”一栏完全是按相关性强弱进行的排序,而后一栏中不同维度占展示结果的比例各页均不相同,我在此不截图了,感兴趣的可以自己搜索一下。
《运营之光》为例,其智能推荐结果6页,第一页强相关性图书/所有展示图书占比是100%,也就是说此页是更为聚焦和单一维度的;第二、三页的占比是70%;第四、五、六页中占比是50%或者60%——也就是说随着翻页次数的增加,用户操作成本变大,相应的结果曝光率会变低。
当当会显示更多针对用户非目的性浏览需求输出的结果,目标是刺激用户的消费。
而豆瓣的排序策略则不显著,在体验中发现了一些将强相关性和弱相关性(相对)位置颠倒或者顺序相反的情况,理应这是一个应该优化的策略点。
但是其重要程度显然没有盈利网站高,主要原因是不存在翻页行为,操作成本低,用户一目了然,且不存在过多的营销需求,所以放在什么位置对其曝光率影响实际是不大的。
4)信息展示的差异
当当的信息展示主要也是从购买的角度出发,高亮价格,并会多展示出作者的名字和出版社。而豆瓣的信息展示就非常少,我认为可以加上豆瓣标签便于用户对该书的类型有快速了解。
具象产品理想态
注:我们在这里先不涉及资源的转化率相关问题,仅对平台的拉新促活进行分析。
通过上述对用户和平台目标的拆解和详细例子的分析,我们总结出两种不同产品的理想态。
豆瓣读书
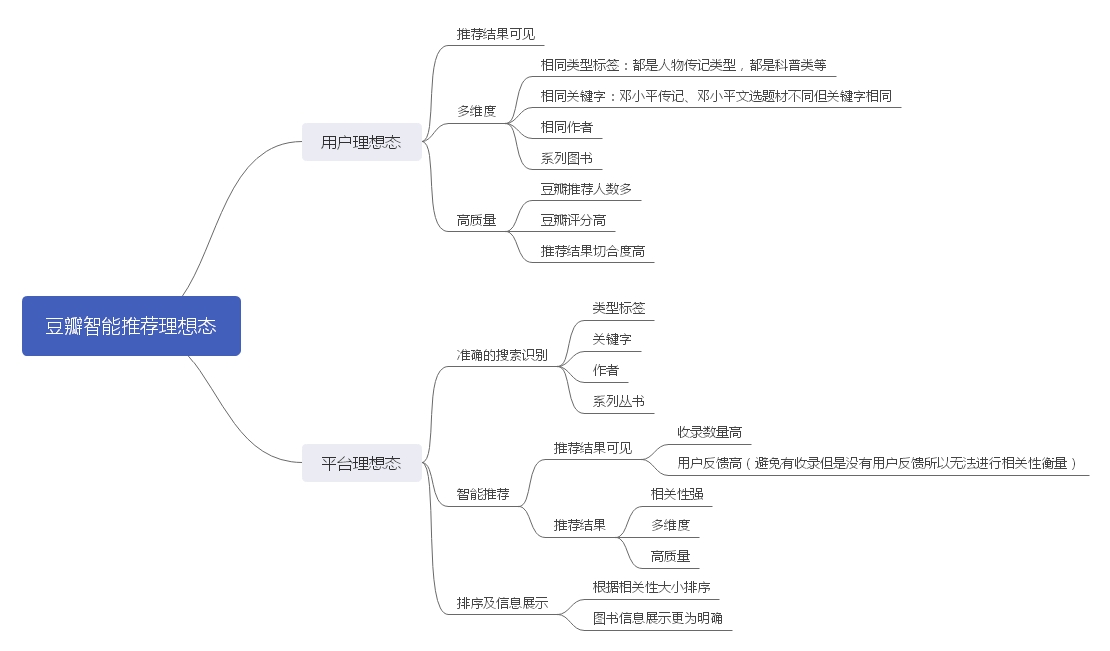
通过理想态分析可以看出来豆瓣阅读实际上用户和平台的理想态差异是很小的,追求的都是在目的性浏览下的高质量以及高切合度的图书推荐。
也就是说平台主要做的是“基于内容的推荐”,就是将内容系统下的数据进行很好的分类。
这一推荐结果的精度主要依赖完整的内容知识库的建立,如果内容知识库丰富度不够或者格式化建立不好,其搜索结果也会大打折扣。同时由于用户的登录需求不高(沉默的永远是大多数),大多数用户以游客身份浏览,留下来的数据就比较少,推荐结果的扩展性就比较低。
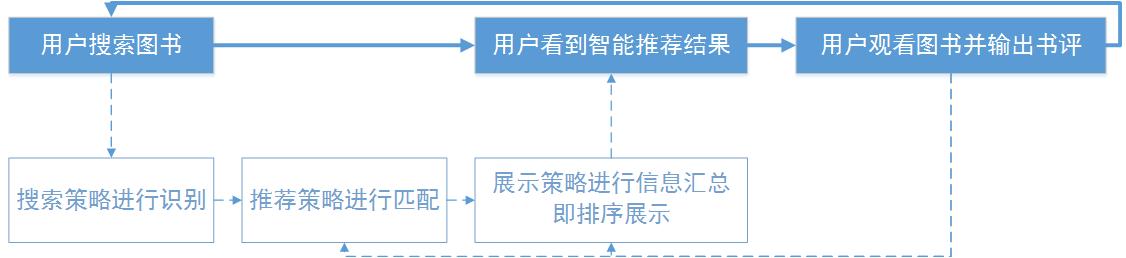
由于用户数据比较少,所以在上图闭环中没有显示出来。针对“基于内容的推荐”的平台更着重于用户的输出,即“标签”“评论”“打分”这些作用在“项目”上的信息,帮助丰富数据库内的格式化信息,平台的目标着重于对每本书画像的更了解其次是对用户画像的理解。
当当网
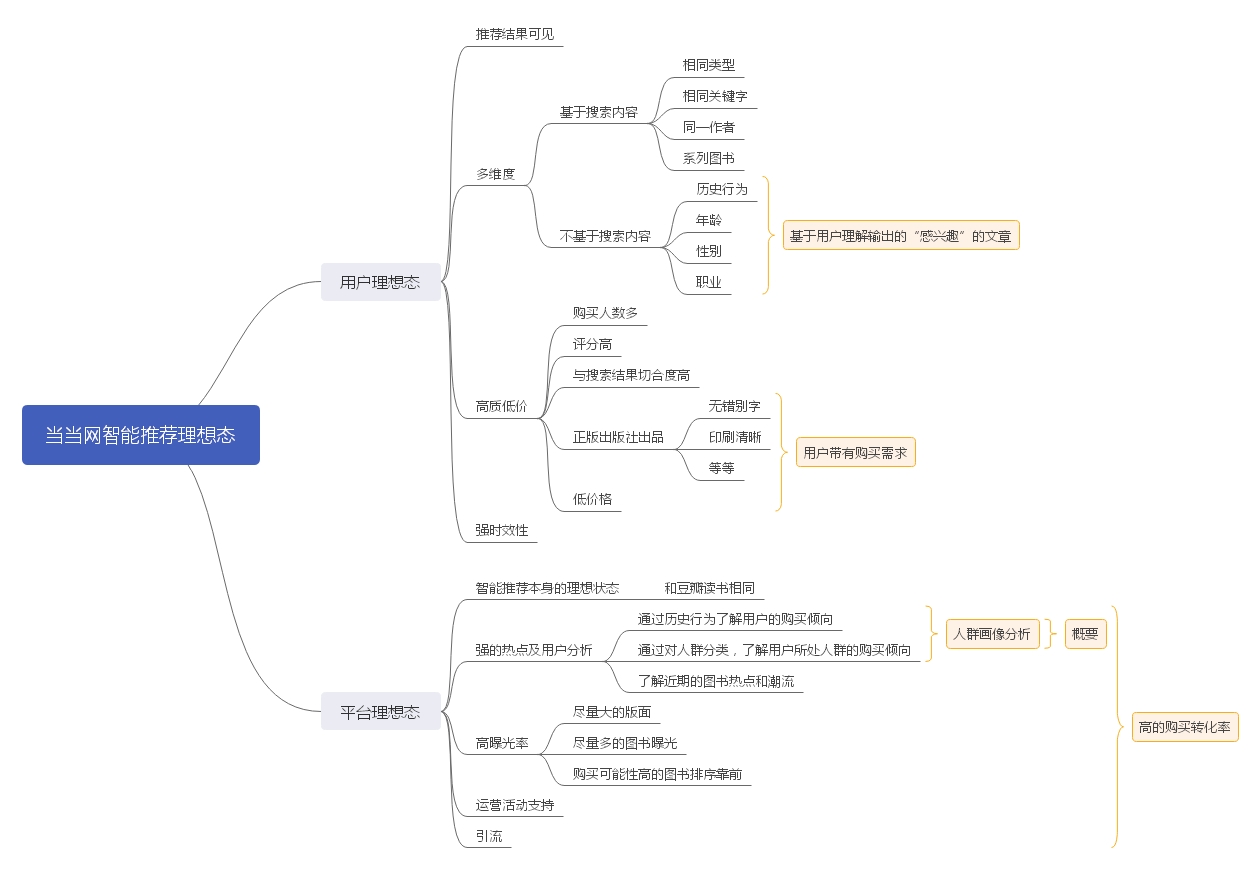
通过上面的分析我们可以看出来:和豆瓣相比,当当网的用户理想态以及平台理想态都有“购买”这一因素的存在,这就需要跳出基于内容的基础智能推荐,而是对用户心理具有准确把控,以及对当下热点的敏感程度提高,我们通过当当网的闭环来加深以下理解。
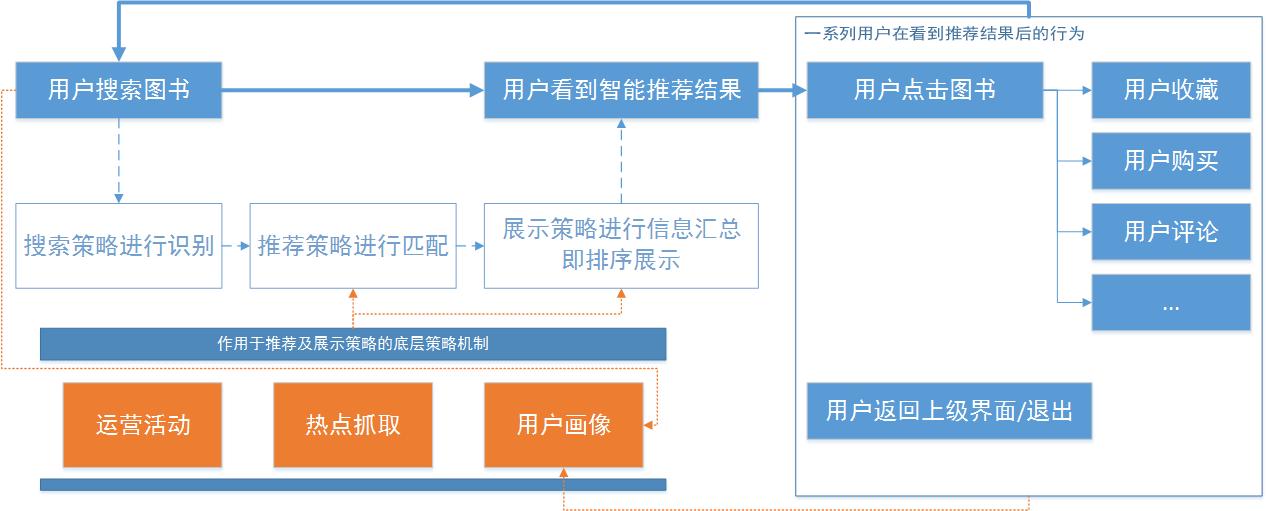
我们可以分析当当的智能推荐策略是有以下几个方面:
- 基于内容的推荐:和豆瓣相同,基于完整资源库建立以及细粒度的格式化信息搭建;
- 基于内容的协同过滤:协同过滤会分析系统现有数据,结合用户表现数据,对指定用户对此类信息的喜好程度进行预测;比如“啤酒加尿布”,就是通过分析指导美国爸爸总是会一起购买这两件商品,通过调整商品位置增加啤酒销量;
- 基于用户的协同过滤:通过用户对不同内容的行为,评测用户之间的相似性,基于用户相似性进行推荐。
我们可以看到当当聚焦到了用户身上,基于内容的协同过滤以及基于用户的协同过滤都需要对用户心理具有很好的把控,所以历史信息主要作用于丰富人群画像,这是资本压力下的必然结果。通过用户出揣测来刺激消费,同时其推荐结果也受到较多因素的影响,比如当今热点、图书销售情况、运营活动等等。
抽象产品理想态
对产品理想态的抽象指标会随着产品阶段不同,以及策略目的不同而发生改变。在此仅做浅显讨论,希望帮助读者建立抽象理想态的框架。
针对上述推荐策略而言,我们需要明确的包括但不仅限于以下几种:
- 用户对搜索结果的满意情况
- 用户的购买转化情况
- 推荐结果是否可见?
- 关键词定义是否准确?
- 排序是否合理?
- 推荐图书和搜索图书的切合度情况
- 运营图书的透出情况
关键目标实际上是明确用户对推荐结果的满意情况,也就是说点击率,当当网中还有购买转化率,这应该是智能推荐系统的核心指标。
但是为了方便我们定位各个过程的运转情况,遇到case时进行快速定位分析,我们需要对核心指标进行细粒度的拆解,并建立过程指标。
对核心指标拆解
用户总点击率>用户对排序结果第>位图书的点击率>用户对排序结果第二位图书点击率……
购买转化率>用户对排序结果第一位图书的购买转化率>用户对排序结果第二位图书的购买转化率……
细粒度的拆解可以帮助分析推荐结果排序情况是否合理,建立过程指标包括搜索结果可见率,关键词匹配度,热点图书、运营图书透出率等。
建立过程指标的作用
- 建立监控体系,实时监控产品稳定性;
- 出现问题时快速定位;
- 在效果回归中衡量策略的收益情况;
- 作为规则抓取case进行分析,从而对策略进行迭代优化。
本文由 @Crystal 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unplash,基于 CC0 协议









小姐姐 小白在其他平台上看过你的视频 但还是没有学会怎么写这样文章 555 不知道从何下笔