
 起点课堂会员权益
起点课堂会员权益在数据清理中,更好的数据胜过更高级的算法
数据清理的步骤和技术因数据集而异,我们没有办法在一篇文章中穷尽所有会出现的问题。这篇文章介绍了数据清理的一些常见步骤,例如修复结构性错误,处理丢失的数据以及过滤观察值。

更好的数据>更高级的算法
数据清理是每个人都要做的事情之一,但很少有人专门讨论这件事,原因很简单,这不是机器学习的“最性感”的部分。而且,没有什么可供挖掘的隐藏技巧和秘密。
但事实上,数据清理可能会加快或中断整个项目进程,专业的数据科学家通常在此步骤上花费很大一部分时间。
他们为什么要这么做呢?机器学习中存在一个很简单的事实:
更好的数据胜过更高级的算法。
换句话说,输入垃圾数据,得到的也是垃圾结果。
如果我们的数据集经过了正确的清洗,那么即使是简单的算法也可以从中得到深刻的启发!
不同类型的数据需要不同的清洗方法,但是本文中阐述的系统方法可以作为一个很好的学习起点。

删除不需要的观测结果
数据清理的第一步是从数据集中删除不需要的观测结果,包括重复或不相关的观测结果。

1. 重复的观测结果
重复的观测结果最常见于数据收集期间,例如:
- 合并多个来源的数据集时
- 抓取数据时
- 从客户/其他部门接入数据时

2. 不相关的观测结果
不相关的观测结果实际上与我们要解决的特定问题不符。
- 例如,如果我们仅为单户住宅构建模型,则不希望对其中的公寓也进行观测。
- 这时候,我们也可以在上一步的探索性分析中判断出来。我们可以查看类别特征的分布图,以查看是否有不相关的类存在。
- 在做工特征工程之前,我们也可以检查是否存在不相关的观察结果。
修复结构性错误
结构性错误是在测量、数据传输或其他的“不良内部管理”过程中出现的错误。
例如,我们可以检查拼写错误或大小写不一致的问题。这些主要和分类特征有关。
这是一个例子:
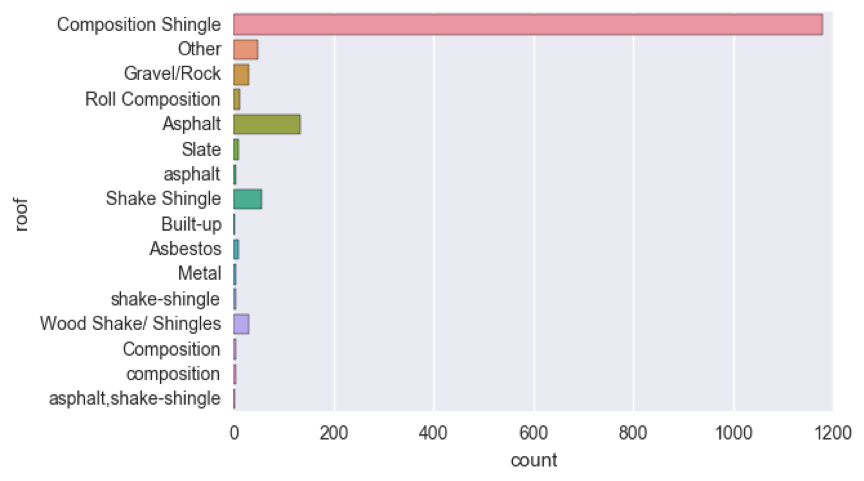
从上图中可以看到:
- “Composition”与“composition”相同
- “asphalt”应为“Asphalt”
- “ shake-shingle”应为“ Shake Shingle”
- “asphalt,shake-shingle”也可能只是“Shake Shingle”
替换错字和大小写不一致后,整个分类变得更加整洁:
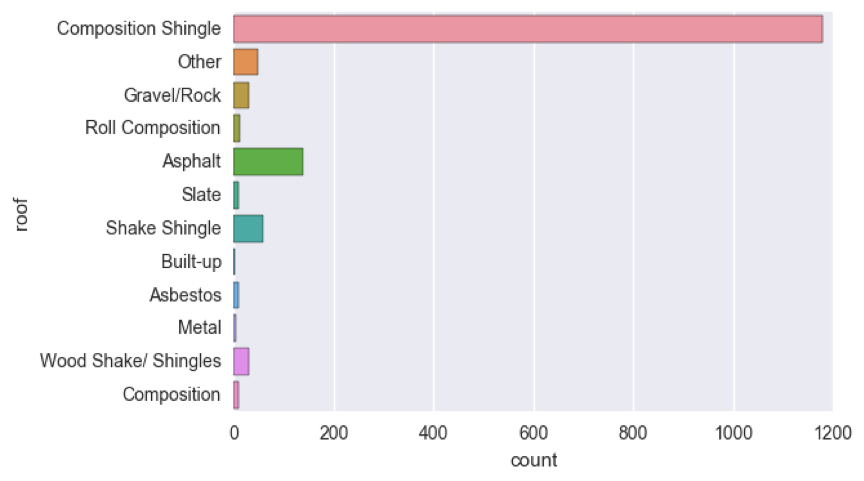
最后,检查标签错误的类,即实际上应该相同的类。
- 例如:如果“N/A”和“Not Applicable”显示为两个单独的类,则应将其合并。
- 例如:“ IT”和“ information_technology”应该是同一个类。
过滤不需要的异常值
异常值可能会导致某些模型出现问题。例如,线性回归模型对异常值的鲁棒性不如决策树模型。
通常,如果我们有合理的理由要删除异常值,则可以提高模型的性能。
但是,在证明异常值无用之前,我们永远不要仅仅因为它是一个“大数字”就删除它,因为这个数字可能对我们的模型有很大帮助。
这一点很重要:在删除异常值之前必须要有充分的理由,例如不是真实数据的可疑度量。

处理缺失的数据
在机器学习应用过程中,数据缺失看上去是一个很棘手的问题。
为了清楚起见,我们不能简单地忽略数据集中的缺失值。由于大多数算法都不接受缺失值,因此,我们必须通过某种方式来处理这一点。
1. “常识”在这里并不灵验
根据我们的经验,处理丢失数据的两种最常用的推荐方法实际上都不怎么有用。
这两种方法分别是:
- 删除具有缺失值的观测值
- 根据其他观察结果估算缺失值
删除缺失值不是最佳选择,因为删除观察值时会删除信息。
- 缺失值本身可能会提供一些参考
- 在现实世界中,即使缺少某些功能,我们也经常需要对新数据进行预测
插入缺失值也不是最佳选择,因为该值最初是缺失的,但如果我们将其填充,无论插入缺失值的方法多么精确得当,总是会导致信息丢失。
- 同样,“遗漏”本身几乎总是有用的,我们应该告诉算法是否存在缺少值。
- 即使我们重新建立了模型来估算值,也没有添加任何实际信息——这样做仅仅在增强其他功能已经提供的模式。

丢失数据就像丢失了一块拼图。如果将其放下,就好像在假装不存在拼图槽;如果进行估算,那就像是试图从拼图上的其他地方挤一块儿进去。
简而言之,自始至终,我们都应该告诉算法,缺少值是因为缺少可提供信息。
具体怎么做呢?告诉算法该值一开始就已丢失。

2. 缺少分类特征的数据
处理分类特征缺失的数据的最佳方法是简单地将其标记为“缺失”!
- 这样做实质上是在为该特征添加新的类。
- 告诉算法缺少该值。
- 满足了技术需求,即要求没有任何缺失值。
3. 缺少数字数据
对于缺少的数字数据,应标记并填充值。
- 使用缺失的指示变量标记观察结果;
- 为了满足没有任何缺失值的技术需求,用0填充原始丢失值。
通过标记和填充,从本质上讲,我们可以让该算法估算缺失的最佳常数,而不仅仅是用均值填充。
原文作者: Mahbub Gani
原文链接:https://elitedatascience.com/data-cleaning
本文由 @碧绿色的小兔子 翻译发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


