
 起点课堂会员权益
起点课堂会员权益聚类算法简析(一):朴素贝叶斯算法的场景案例
本文作者通过一些场景案例,带领大家了解一下朴素贝叶斯算法作为聚类算法中的一员,如何来区分各类数组。

通过一组参数模型来区分互斥群组中的个体十分常见,我们可以使用朴素贝叶斯分析来应用于这种场景,取决于模型的相似矩阵算法常常运用在估算决策论框架的矩阵中。
一些已经存在的聚类分析技巧是从一些特定的有限制的场景中提取出来的,这些结论很好地应用于区分两类不同数组之间的比较关系。
本文我们通过一些场景案例,来了解一下朴素贝叶斯算法作为聚类算法中的一员,如何来区分各类数组。
简介
最近几年,各种各样的分类算法在统计学著作中被提出。
回溯近代理论中涉及的各类著作,1971年科马克、1973年安德伯、1974年埃弗里特、1975年哈迪更均有涉猎。然后,大部分的算法均有限制,因为这些算法只能在某些特定场景中才能应用。
乌尔夫(1970)提出假设,观察到密度函数中具有一个有限的参数矩阵。然而,一旦参数矩阵中的组件数量不确定,则会出现问题。
沃尔夫认为这个矩阵很有可能存在一种概率,这种假说即为:当一个组件和另外两个组件矩阵出现互斥时会产生分离。
由此我们可以将聚类分析重新构建一种模型,观察对象的参数形成互斥群组,并且在朴素贝叶斯的场景中,我们是允许存在未定义组件的。
常用理论模型
定义X1……Xn为p维空间观察物。
我们定义“真群组”向量,定义为:g=(g1……gn),gk=i表示系数k由系数i的群组产生。
这样就会出现m种可能群组,并且m可能是未知数,主要的问题就是定义特殊值g。
如已知m,g和一个参数向量θ,我们假定X组是独立于密度函数Xk,设为hg(xk|θ),这里的x和θ是已知函数。这个模型在1971年由斯科特和西蒙斯提出。
我们采用先验密度的模型来定义未知数量:
PM,G,θ(m,g,θ)=pM(m)pG|M(g|m)pθ|G.M(θ|g,m)
模型两选一的特性,让我们来引入一个参数向量λ
0<λ1……λm<1,Σλi=1。在某些应用中,针对这些参数我们需要估算g,于是演变为方程:
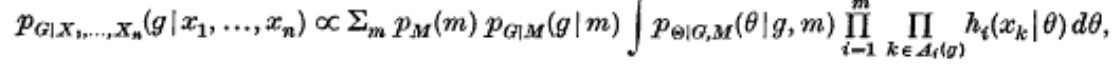
通过这类分析模型的演变,算法的递推,我们采用概率论结合分布矩阵来区分数据聚类的不同分布中心。
技术应用
贝叶斯算法主要运用于两个经典案例:由英国统计学家/生物学家Ronald Fisher在1936年所收集鸢尾花案例,以及邓肯1955年提出的大麦数据。
Iris数据集是常用的分类实验数据集,由Fisher,1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
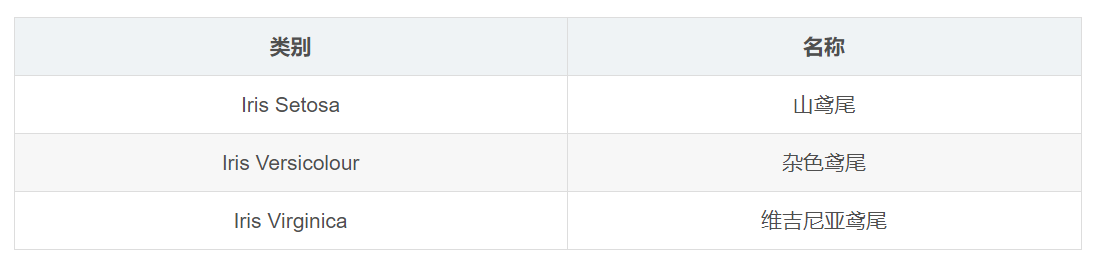
数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
数据集主要包括如下三个种类鸢尾花的数据,每种50条数据:
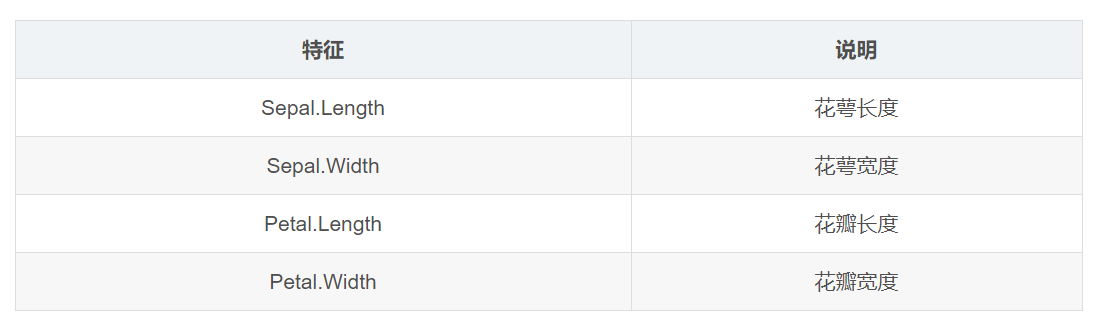
每条数据都从鸢尾花的如下四个特征进行描述:
我们使用nij矩阵来作为实例,最小值min|W|。
当协方差不同,协方差矩阵的斜率就不同,这样每个相似的节点就会形成一个聚类。
我们采用贝叶斯聚类方法进行绘图:
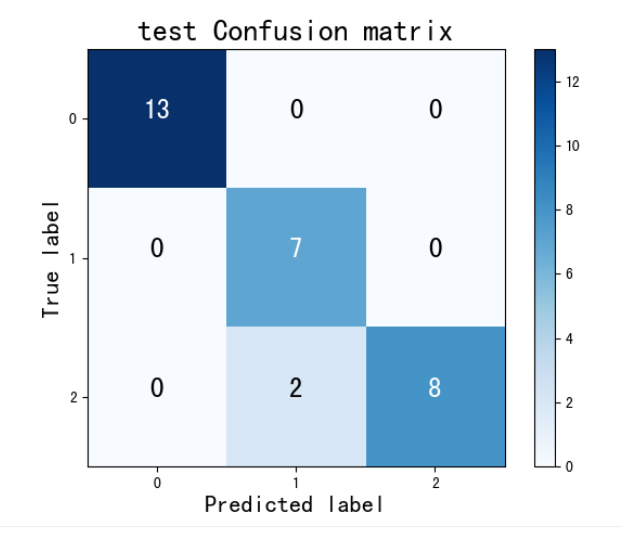
混淆矩阵
散点图
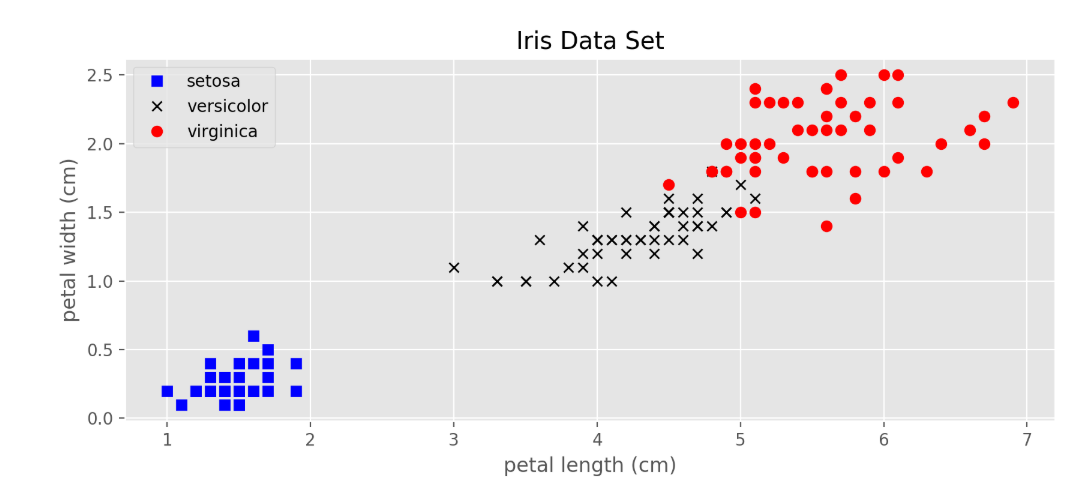
通过图谱我们可以看出,利用朴素贝叶斯算法,可以将同类中的互斥数据分解出来,形成一种聚类,这些算法可以广泛运用在生活中。例如,垃圾邮件问题中,做贝叶斯公式计算过滤方法识别出类似特性邮件并归集。
所以,了解贝叶斯算法的概念和使用贝叶斯算法正在计算机领域逐步推广成为一种应用领域。
本文由 @手心的太阳 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于CC0协议









这是算法内容吧,不属于产品工作范畴吧
做调研的时候提取关键变量的方法